Windows10+cuda11.0+Opencv3.4.0+yolov4+darknet环境下的物体检测
文章目录
- 任务分析
- 一、 下载opencv3.4.0版本
- 二、darknet安装配置
- 三、数据准备(以下主要参考gyl同学的经验)
- 四、模型准备
- 五、训练模型
-
- 1、命令行分析
- 2、遇到的妖魔鬼怪
- 3、结果
- 六、对数据集中的验证集进行检测
- 七、总结
- 其他的一些可供学习的链接
任务分析
首先让我们明确一下本次的任务:用 gun/sword 数据集训练你的物体检测模型,并对数据集中的验证集进行检测,计算出 mAP。
然后,大致了解一下需要完成的环境配置。看了一下,本次任务是由Windows10 + VS + OpenCV+yolo+darknet一起完成的,还得下载标记工具vott和目标检测指标mAP。
下面开始操作。
附:电脑已提前安装好cudu,版本为11.0,具体如下:


一、 下载opencv3.4.0版本
这个版本是恰到好处的。
Releases - OpenCV
或Release OpenCV 3.4.0 · opencv/opencv · GitHub
本来下载了exe文件,但运行不了,瞎搞一通,结果后面发现exe文件安装不了是因为电脑开了杀毒软件,拦截了。
菜鸡路过。
成功安装。
二、darknet安装配置
首先,我用的是校园网,结果,emm…进去不了githua
(4条消息) github进不去解决办法_不积跬步,无以至千里!-CSDN博客_github进不去怎么办
好吧,好像还是不行。直接连热点吧
GitHub - AlexeyAB/darknet下载链接
有两种配置方法:
- 利用cmake(操作简单,要多下载一个东西)
- 在vs2017直接配置(操作复杂一丢丢)
利用cmake编译darknet失败,版本太低,要3.18以上,重新下载,放弃这个方法了。 感兴趣可以参考这个链接https://blog.csdn.net/amusi1994/article/details/76768775?locationNum=10&fps=1
下面主要根据csm同学的经验进行了配置
darknet+yolov4 做物体识别(GPU)_andy dennis的博客-CSDN博客
1、【项目】-【项目属性】-【VC++目录】-【包含目录】”:添加
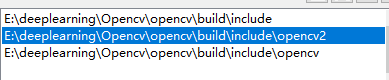
2、【项目】-【项目属性】-【VC++目录】-【库目录】:添加

3、【项目】-【项目属性】-【链接器】-【输入】-【附加依赖项】:添加opencv_world340.lib
(这是release版本的,debug版本就添加opencv_world340d.lib)

4、确认版本一致:

5、“生成-生成darknet”
MSB3721错误:这里的解决方案是去查看一些cpu的算力,然后再把算力值乘以10,结果作为“项目-项目属性-CUDA C/C+±Decice-Code Generation”的修改值。
查看算力:第一步里cd进入cuda的目录里,我一开始找不到,因为大部分人放在C盘,我因为内存容量原因放D盘了,所以不知道的可以直接搜索“demo_suite”找到所在目录。
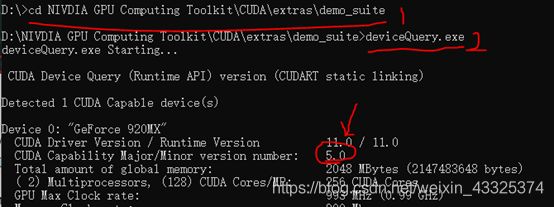
修改:原来是computer_86,cm_86

成功了哈哈哈
![]()
6、测试darknet(主要参考下面这篇文章)
windows下darknet之yolo(gpu版本)安装 - 知乎 (zhihu.com)
从https://pjreddie.com/media/files/yolov3.weights下载了yolov3.weights,把它放到darknet.exe所在文件夹里,然后在cmd中运行代码,最终结果如下:

三、数据准备(以下主要参考gyl同学的经验)
1、给数据做标记——vott
准备好数据集“gun_sword_data”,打开vott(一个标记数据的工具,这里下载 是1.7版本的vott-win.exe,下载链接
下载完直接运行exe文件,按照指引完成安装。
【file】-【Open Image Directory…】,打开的文件就是数据集图片所在的目录。
然后,加入要做的标记,这里是gun和sword
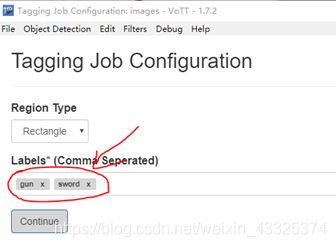
给gun和sword做标记(框框尽可能贴近)

结果导出格式为yolo,保存至自动生成的images_output中,images是原来存放图片的。
每张图片都对应了一个txt

2、把“\images_output\data”目录下的所有文件复制到”\build\darknet\x64\data“中
四、模型准备
1、下载yolov4-tiny.conv.29
https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29
把下载好的文件放到\build\darknet\x64目录下
2、在build\darknet\×64\目录下新建一个文件yolo-tiny-obj.cfg, 把这个文件里的所有内容复制到yolo-tiny-obj.cfg中.
3、对yolo-tiny-obj.cfg 文件做以下修改:
- 更改
batch为batch = 64 - 更改
subvision为subvision = 16 - 更改
max_batches为max_batches = 6000, 更改steps为steps = 4800, 5400 - 更改network size为
width = 416, height = 416 - 更改
line220和line269的classes为classes = 2 - 更改
line212和line263的filters = 255为filters = 21
五、训练模型
在build\darknet\×64目录下运行命令
darknet detector train data/obj.data yolov4-tiny.cfg yolov4-tiny.conv.29 -map
1、命令行分析
上面代码的意思是启动darknet.exe这个文件并以后面作为参数开始运行。
我们是在…\x64的目录下执行该命令的,所以对于后面的那三个文件要注意他们的目录。如:obj.data文件是在…x64/data目录下的,所有是data/obj.data,而 yolov4-tiny.cfg和yolov4-tiny.conv.29都是直接在…/x64目录下的,就直接是文件名了。
这里如果没注意,和自己的文件目录不符,是会错误的。
2、遇到的妖魔鬼怪
先是没有动静,也不报错,无从下手,
![]()
后面莫名其妙用了别人的一个命令就可以继续执行了,但报out of menory的错,然后开始寻找解决方案,去cfg文件里面修改了batch和subvision的值,怎么改问题都存在;

最后是恍然一悟,命令行里人家的cfg文件路径和我的不一样,修改好后,也就是上面这个命令,就可以执行了)

接下来就是等待了。。。。
3、结果
最终的这个图片保存在x64/chart_yolov4-tiny.png中。
特意回来说一声,这里我花了十几个小时才训练好,后面发现它每1000个epoch就会把自动把weights保存在×64\backup\中,所以如果不追求效果的话,其实不用都训练完的。当然啦,都训练完就可以选择best_weights了。

附上我电脑的【豪华待遇:散热器+风扇】,辛苦你了,我的电脑┭┮﹏┭┮

六、对数据集中的验证集进行检测
compute mAP for gun_sword object detection(based
on darknet YOLO3/4)
1、下载mAP
下载链接
解压下载好的map-master压缩包
2. 把验证集中的测试图片放到map-master\input\images-optional目录下**(原目录中的图片可以删掉)**
3. 把用vott输出的所有测试图片对应的.txt文件放到map-master\input\ground-truth目录下(原目录中的txt可以删掉)
4. 把map\scripts\extra目录下的class_list.txt里面的所有内容删除, 第一行输入gun, 第二行输入sword, 然后保存文件.
5. 把yolov-tiny-obj.cfg 文件里面的subvision和batch 改为1 (也就是修改成测试模式)
6. 把训练生成的×64\backup\文件夹下的yolov4-tiny-obj_best.weights 文件复制到×64目录下 (也可以用build\darknet\x64\backup中的其他权重)
7. 在build\darknet\×64 目录下运行**(文件名要和自己的相符)**
darknet.exe detector test data/obj.data yolov4-tiny.cfg yolov4-tiny_best.weights -dont_show -ext_output < data/test.txt > result.txt -thresh 0.25
8.运行完成之后在build\darknet\×64 目录下得到一个result.txt 文件, 把这个文件复制粘贴到map\input\detection_results 目录下
下面出现了和 这位同学差不多的问题,所以下面大部分参考了[此链接]
(https://blog.csdn.net/weixin_43850253/article/details/118220395)
(1)问题:多了不必要的东西

(2)编写脚本process.py
# mydarknet/process_result.txt
file_path = 'result.txt'
with open(file_path, 'r') as f:
data = f.readlines()
# print(data)
# 多余的话
stop_lt = ['Detection layer: 30 - type = 28', 'Detection layer: 37 - type = 28 ']
tip_word = 'Enter Image Path: '
new_data = []
for line in data:
flag = True
for stop_st in stop_lt: # 判断每一句停用词
if stop_st in line:
flag = False
if tip_word in line:
new_data.append(tip_word)
if flag:
new_data.append(line)
with open('result_process.txt', 'w') as f:
f.writelines(new_data)
(3)运行process.py,生成result_process.txt文件。
(4)把result_process.txt文件的内容替代map\input\detection_results中的“result.txt’文件
10.对map-master\scripts\extra中的convert_dr_yolo.py 代码进行替换,换成下面的代码,然后运行。
生成对每张图片的检测结果,每个图片对应一个txt,存放在map-master\input\detection-results中
import os
import re
# make sure that the cwd() in the beginning is the location of the python script (so that every path makes sense)
os.chdir(os.path.dirname(os.path.abspath(__file__)))
IN_FILE = 'result.txt'
# change directory to the one with the files to be changed
parent_path = os.path.abspath(os.path.join(os.getcwd(), os.pardir))
parent_path = os.path.abspath(os.path.join(parent_path, os.pardir))
DR_PATH = os.path.join(parent_path, 'input','detection-results')
#print(DR_PATH)
os.chdir(DR_PATH)
SEPARATOR_KEY = 'Enter Image Path:'
IMG_FORMAT = '.jpg'
result_format = '%'
# outfile = None
fo = open(os.path.join(DR_PATH, 'result.txt'), "r")
alllines = fo.readlines() #依次读取每行
# alllines = alllines.strip() #去掉每行头尾空白
# 关闭文件
fo.close()
for line in alllines:
#if SEPARATOR_KEY in line:
if IMG_FORMAT in line:
# if IMG_FORMAT not in line:
# break
# get text between two substrings (SEPARATOR_KEY and IMG_FORMAT)
#image_path = re.search(SEPARATOR_KEY + '(.*)' + IMG_FORMAT, line)
# get the image name (the final component of a image_path)
# e.g., from 'data/horses_1' to 'horses_1'
#image_name = os.path.basename(image_path.group(1))
image_path = (line.split(':', 1))[1]
image_name = (image_path.split('/',2))[2]
image_name = (image_name.split('.',1))[0]
# close the previous file
#if outfile is not None:
# outfile.close()
# open a new file
# elif outfile is not None:
elif result_format in line:
# split line on first occurrence of the character ':' and '%'
outfile = open(os.path.join(DR_PATH, image_name + '.txt'), 'w')
class_name, info = line.split(':', 1)
confidence, bbox = info.split('%', 1)
# get all the coordinates of the bounding box
bbox = bbox.replace(')','') # remove the character ')'
# go through each of the parts of the string and check if it is a digit
left, top, width, height = [int(s) for s in bbox.split() if s.lstrip('-').isdigit()]
right = left + width
bottom = top + height
outfile.write("{} {} {} {} {} {}\n".format(class_name, float(confidence)/100, left, top, right, bottom))
outfile.close()
11.把result.txt文件删掉
12.修改scripts/extra/convert_gt_yolo.py

13.运行scripts/extra/convert_gt_yolo.py, 转化一下测试集标签的格式
这里一开始直接双击运行,也没发现错误,后面用了python的idle打开运行,才发现要install ”cv2",
pip install opencv-contrib-python
之后就可以了
14.这里可以运行一遍map-master\scripts\extra\intersect-gt-and-dr.py,在步骤10那里可能会出现有几张图片没有生成对应的txt,这样就会导致步骤15出现找不到txt的报错,而我们执行这一步就是去掉没有生成txt文件的对应文件。
15.运行main.py文件
16.结果

(做这个愚蠢了一点,没有理解清楚第2、3步的测试图片,这些测试图片信息是一开始就就放到x64的了,傻傻的以为自己把原来的测试图片也去做训练了,就自己重新找了测试图片,做标记好后放map里了,结果生成出来的result.txt里的图片信息显然和map里的图片信息对应不上,傻子一只实锤了)
七、总结
整个过程在配置环境花费的时间较多,这里要感谢那几位做好了的同学的经验分享。但还是会出现一些问题,有问题去百度,百度不行去必应,必应不行去谷歌,一般都会找到解决方案了。如果还没找到,那可能是自己哪里搞错了,就像最后一步的报错,网上都没出现这个情况,这时候就要回溯一下自己的步骤,一一排查。
对于目标检测这部分也有了一点点的了解了,感觉还挺有趣的。
其他的一些可供学习的链接
vs2017运行yolov4_YOLO v4来了!各种新实现、配置、测试、训练资源汇总
linux下配置运行yolov4!亲测有效!
使用darknet(windows GPU 版本) yolov3 训练自己的第一个检测模型(皮卡丘检测)