python_pandas入门(by offical document/reference)/loc和iloc操作/dataframe插入操作/pandas读取无表头的文件/查找某一列是否有某个值
文章目录
- Pandas starter
-
- starter:学习第一步
-
- pandas数据结构概念
- 十分钟了解pandas的基本特性
-
- ten minutes to learn about the basci
- references
-
- 官方教程的数据资源
- 搜索引擎推荐/问题示例
- DataFrame&Series
-
- 构造df:dateframe构造器可以接受的参数类型
- dataFrame和serial之间的关系
- series
- 数值计算:describe()
- 闭包计算
- DataFrame Getting取数据(单轴)
-
- 取多列数据(得到子集dataframe)
- 多轴数据(dataframe的loc&iloc对象)
- 利用条件表达式来筛选dataframe的数据
-
- 检索dataframe:
-
- 查找某一列是否有某个值
- Boolean indexing
- pandas数据的读入和写出
- pandas read excel/csv file skip header
-
- 读入没有表头的csv
- 读入没有表头的excel
- 检查数据的读入情况
-
- pandas读写文件小结
- dataFrame操作
- loc与iloc 对dataFrame的筛选
- loc/iloc获取datafram子集的
-
- 类型为dataframe的子集
-
- [[]]
- bool list 截取
- 类型为series的子集
- dataframe/series扩增
-
- 对dataframe插入行
-
- 基于dataframe.append()来间接插入
- 组织python pandas 将NULL 转化为NAN(NULL 消失问题)/排序bool & str 问题
-
- 排序bool 问题
-
- pandas 按指定列值排序
Pandas starter
- UserGuide:10 minutes to pandas — pandas 1.4.2 documentation (pydata.org)
starter:学习第一步
pandas数据结构概念
- first article to read
十分钟了解pandas的基本特性
- UserGuide:10 minutes to pandas — pandas 1.4.2 documentation (pydata.org)
ten minutes to learn about the basci
references
- Getting started(入门)
- User Guide(进一步)
- api reference(专业需求)
- 搜索引擎
(使用搜索引擎来获取特定问题的解决方案,在入门篇的时候也可以穿插使用来快速解惑,然而,我还是认为,先将入门部分看完,有了基本概念在看各种解决方案才是高效的,尽管在入门时你会对某些还未介绍到的内容感兴趣)
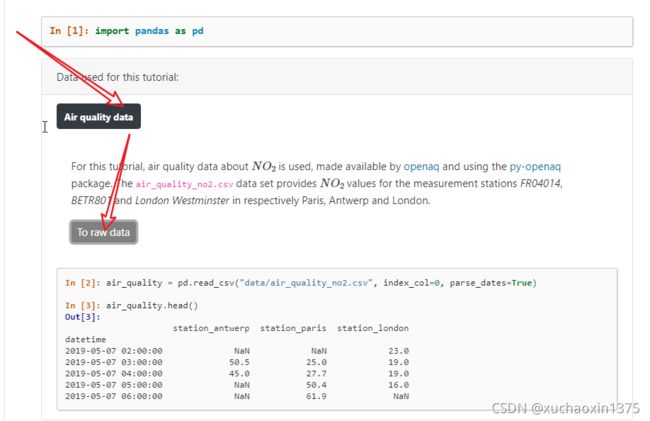
官方教程的数据资源
- 教程的案例使用的数据均被开源您可以将其clone:
- data On github
- 使用搜索引擎提问的时候,以关键词/短语(指令式文本)为主
- 最后才是句子(简短的描述有利于减少不必要的信息对搜索效果的干扰)
- 适合使用句子的场景一般是在论坛中提问,这种情况下用句子将问题描述的清楚
- 建议使用英文搜索
搜索引擎推荐/问题示例
- bing
- google
例如:
DataFrame&Series
- pandas.DataFrame — pandas 1.4.2 documentation (pydata.org)
overview:
- dataFrame是一种以列为向导的数据结构
以更加基础的Serial结构为基础的二维对象(也是一种纵向排列数据的数据类型)
构造df:dateframe构造器可以接受的参数类型
- 字典
- 列表
- numpy:ndarray
- series
[ˈsɪriz]
可以计算求值,甚至对列进行排序操作
- 接受二维数组构造对应的dataframe
- 接受字典(值为列表的字典,每个值(list)表示中的元素表示一行中的该列(key)的一行值)构造对应dataframe
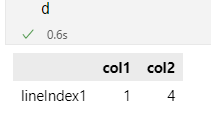
d = {'col1': [1, 2], 'col2': [3, 4]}(2行2列datafram)
df=pd.DataFrame(d)df = pd.DataFrame({'col1': [1], 'col2': [4]},index=['lineIndex1'])(单行两列dataframe)
dataFrame和serial之间的关系
-
DataFrame中的一个列就相当于是一个Series
-

series
A pandas Series has no column labels, as it is just a single column of a DataFrame. (Series没有列标签)
A Series does have row labels.
如此,当你看到某些返回的是Series类型的结果的时候可以考虑将Series转换为(单列)的dataFrame.
相关案例
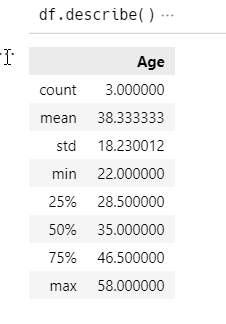
数值计算:describe()
数值计算是核心内容
DataFrame/Series均可以使用该方法
其实,两种数据结构提供了几乎一样的方法
利用describe()方法,您可以得到被计算的DataFrame对象的大致数据规律(一些常用的统计量值)
![]()
闭包计算
Many pandas operations return a DataFrame or a Series.
The describe() method is an example of a pandas operation returning a pandas Series or a pandas DataFrame.
DataFrame Getting取数据(单轴)
- 只使用单重
[]可以取得某个列或者或者切片(slides)指定的若干行数据
Selecting a single column, which yields a Series, equivalent to df.A:
In [23]: df["A"]
Out[23]:
2013-01-01 0.469112
2013-01-02 1.212112
2013-01-03 -0.861849
2013-01-04 0.721555
2013-01-05 -0.424972
2013-01-06 -0.673690
Freq: D, Name: A, dtype: float64
Selecting via [], which slices the rows:
In [24]: df[0:3]
Out[24]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
In [25]: df["20130102":"20130104"]
Out[25]:
A B C D
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
取多列数据(得到子集dataframe)
- 无论是单列还是多列,使用
[[]]得到的数据都是dataframe- 如果是
[]取得的数据如果是单列的,那么就是Series类型的
多轴数据(dataframe的loc&iloc对象)
- 后文中将介绍
利用条件表达式来筛选dataframe的数据
返回结果是dataframe的子集dataframe或者Series
检索dataframe:
查找某一列是否有某个值
## 检索某个列中满足特定条件(取值)的所有记录:df[df['column_name']=='column_value']
#例如
df[df['spelling']=='zoom']
Boolean indexing
Using a single column’s values to select data:
In [39]: df[df["A"] > 0]
Out[39]:
A B C D
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632
2013-01-02 1.212112 -0.173215 0.119209 -1.044236
2013-01-04 0.721555 -0.706771 -1.039575 0.271860
Selecting values from a DataFrame where a boolean condition is met:
In [40]: df[df > 0]
Out[40]:
A B C D
2013-01-01 0.469112 NaN NaN NaN
2013-01-02 1.212112 NaN 0.119209 NaN
2013-01-03 NaN NaN NaN 1.071804
2013-01-04 0.721555 NaN NaN 0.271860
2013-01-05 NaN 0.567020 0.276232 NaN
2013-01-06 NaN 0.113648 NaN 0.524988
Using the isin() method for filtering:
In [41]: df2 = df.copy()
In [42]: df2["E"] = ["one", "one", "two", "three", "four", "three"]
In [43]: df2
Out[43]:
A B C D E
2013-01-01 0.469112 -0.282863 -1.509059 -1.135632 one
2013-01-02 1.212112 -0.173215 0.119209 -1.044236 one
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two
2013-01-04 0.721555 -0.706771 -1.039575 0.271860 three
2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four
2013-01-06 -0.673690 0.113648 -1.478427 0.524988 three
In [44]: df2[df2["E"].isin(["two", "four"])]
Out[44]:
A B C D E
2013-01-03 -0.861849 -2.104569 -0.494929 1.071804 two
2013-01-05 -0.424972 0.567020 0.276232 -1.087401 four
pandas数据的读入和写出
- 支持二进制文件(excel等)
- 文本文件(csv等)
- pandas.read_excel()
- pandas.read_csv()
- …
pandas read excel/csv file skip header
- 关于dataFrame的标题行的若干问题的解决方案(header row)
- dataframe的数据行插入/追加操作大多基于对应的表头,如果读入数据的时候将没有表头,应当使用参数告诉pandas,否则第一行正文被当作是header,不正确的表头也使得基于表头的操作难以利用
- 总之,在读入的时候就把表头解决了(如果没有表头可用,通过传参让pandas生成默认的表头,然后表头更名可以在读入的时候,更改)
读入没有表头的csv
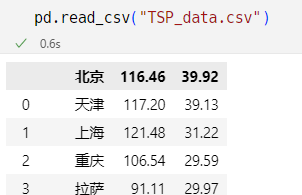
- 读入的时候指定表头:

读入没有表头的excel
-
被读取数据:(无表头(字段名),第一行(line1)数据就是正文)
-
How to read a excel file without taking its first row as header ? Pandas, Python - Stack Overflow
-
由于我们的源数据没有表头,我们设置参数
header=None,以免第一行正文被读入为表头- 处理方式和csv有所不同
- 读入完毕后,我们可以对表头进行修改,使得其具有明确的含义
-

-
截取前三列作为演示素材:

- 重新设定表头header labels
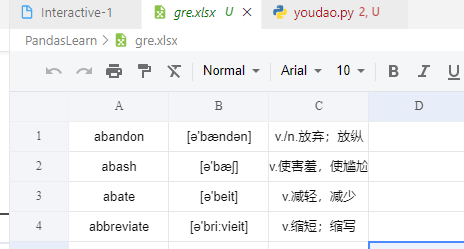

检查数据的读入情况
pandas读写文件小结

可用的方法有:
调用形式:df.info()…
- head
- tail
- info
- dtypes
当然还有DataFrame.shape来检查维度
DataFrame.shapeis an attribute (remember tutorial on reading and writing, do not use parentheses for attributes) of a pandasSeries and DataFramecontaining the number of rows and columns:(nrows, ncolumns).A pandas Series is 1-dimensional and only
the number of rows is returned.
dataFrame操作
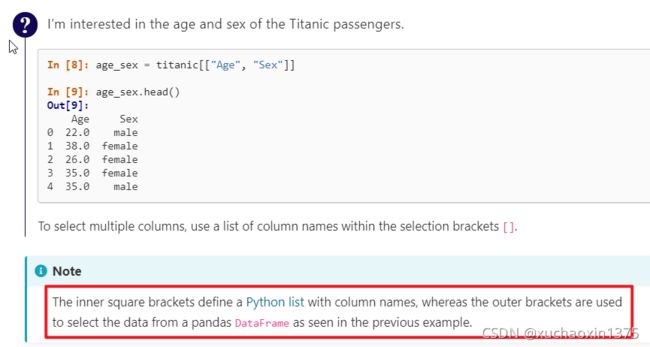
这里注意双重括号的含义
在截取dataFrame的多个列子集时,通过一个python list 来指定列
To select multiple columns, use a list of column names within the selection brackets [].
dataframe[]可以接受series关系表达式(其实该值还是series),pandas提供了一些优化的方法来代替关系表达式的符号)
例如:
- notna()
- isin()
loc与iloc 对dataFrame的筛选
- 一般地,
loc依赖于具体的标签名(或者通过传入bool序列来截取dataframe的部分(子集),不依赖于dataFrame的规格(shape) iloc不依赖于具体的标签名,但是依赖于dataFrame的规格(维度,从0开始计数)
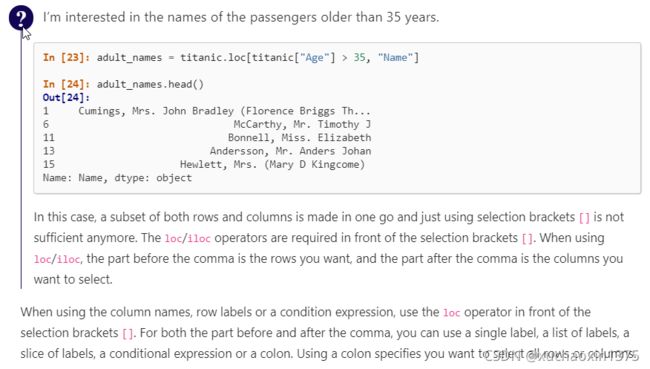

loc/iloc获取datafram子集的
df.loc/df.iloc 是访问df行的有力工具(但不仅限于对行的访问)
- pandas.DataFrame.loc — pandas 1.4.2 documentation (pydata.org)
类型为dataframe的子集
[[]]

bool list 截取
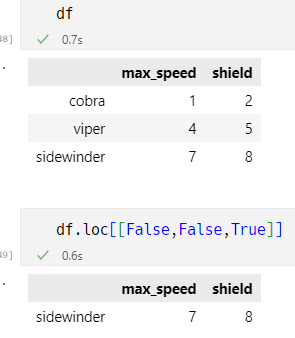
类型为series的子集
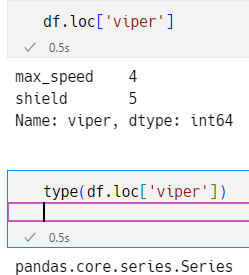

dataframe/series扩增
- Indexing and selecting data — pandas 1.4.2 documentation (pydata.org)
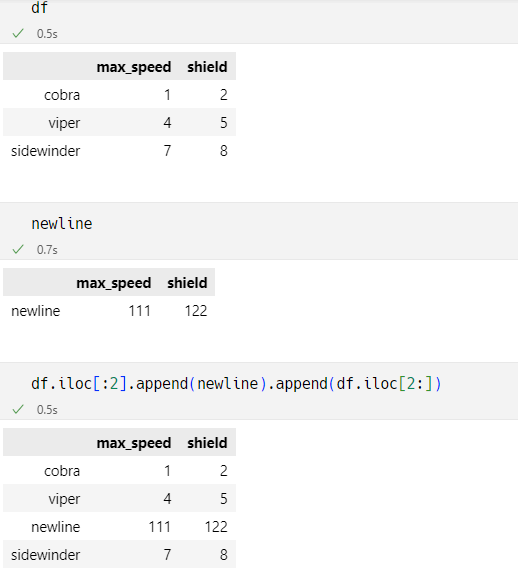
对dataframe插入行
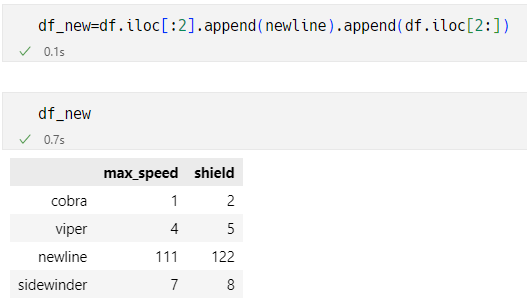
基于dataframe.append()来间接插入
- 此处被插入的行newline也是一个dataframe,该对象需要配置和插入目标dataframe有一致的表头
- newline可以是多行,也可以是单行
组织python pandas 将NULL 转化为NAN(NULL 消失问题)/排序bool & str 问题
- python - How to treat NULL as a normal string with pandas? - Stack Overflow
- python - How to take column-slices of dataframe in pandas - Stack Overflow
排序bool 问题
- 如果pandas 从文件中读取到
TRUE&FALSE,会将其转化为bool型,而导致出错,使用astype指定为str(object)也无作用 - 可以考虑使用
datafram.applymap()对元素做类型强制转化.
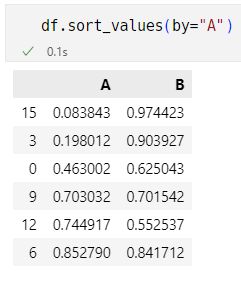
pandas 按指定列值排序
sort_value(by=columnName)df = pd.DataFrame(nprand.rand(6,2), index=range(0,18,3), columns=['A', 'B'])