2022 年牛客多校加赛场补题记录
B Bustling City
题意:给定一个 n n n 个点 n n n 条边的有向图,第 i i i 个点恰有一条出边指向 a i a_i ai。在每个点上恰有一个商人,一个时刻位于点 i i i 处的商人会走到 a i a_i ai 号节点,问每个节点第一次有 k k k 个商人同时在该点的时间。 n , k ≤ 1 × 1 0 6 n,k \leq 1\times 10^6 n,k≤1×106。
解法:将图分成若干个连通块,每个连通块由一个环和树根在环上的内向树构成。首先考虑树上的点的答案(排除树根),对于节点 u u u,可以根据它的最大子树深度 h h h 得到一个长度为 h h h 的数组 f u f_u fu,第 x x x 位表示第 x x x 时刻它现在有多少个商人。那么这个信息是可以通过子树合并得到的: f u , i = ∑ v ∈ c h i l d u f v , i − 1 \displaystyle f_{u,i}=\sum_{v \in {\rm child}_u}f_{v,i-1} fu,i=v∈childu∑fv,i−1。那么就可以进行树上启发式合并,在 O ( n log n ) \mathcal O(n \log n) O(nlogn) 的时间得到每个树上节点的答案。
对于环上的节点,考虑维护一个双向环形链表,初始时刻每个点均在环上。依次枚举时刻,再遍历链表,容易计算出该时刻下环上每个点的商人个数。若从某一时刻开始,环上节点 u u u 的子树内再也没有商人进入环中,则可将该点从链表中删除。这样看似暴力的做法复杂度其实仅为各个子树深度之和——每个环上节点只会被遍历它的子树深度层,因而可以 O ( n ) \mathcal O(n) O(n) 的计算环上节点的答案。
因而总的复杂度为 O ( n log n + n ) \mathcal O(n \log n + n) O(nlogn+n)。
#includeC Cmostp
题意:给定字符串 S S S, q q q 次询问 S S S 的全部本质不同子串中有多少个子串的右端点落入 [ l , r ] [l,r] [l,r] 中的。 ∣ S ∣ , q ≤ 5 × 1 0 5 |S|,q \leq 5\times 10^5 ∣S∣,q≤5×105。
解法:显然在 SAM 上可以将前缀 [ 1 , i ] [1,i] [1,i] 对应节点在扩展的时候找到,记该节点为 d i d_i di。同时每个节点对应了 l l l 个本质不同子串。那么问题转化为, ∀ k ∈ [ l , r ] \forall k \in [l,r] ∀k∈[l,r], d k d_k dk 到根节点的全部链的并上节点的 l l l 之和。这是由于 d k d_k dk 对应的这些串的 endpos 必然有元素 k k k,那么它所有 link 树上的父亲的 endpos 集合都必然有元素 k k k,因而都需要计入该次询问。
考虑根据 r r r 从小到大的离线询问,对 link 树进行树链剖分。依次插入第 i i i 个终止节点,首先使用树链剖分将 i i i 到根节点的链找到,并对链上的全部点染色成当前的 i i i(即进行 Access 操作),这样做的目的在于更新每个 link 树上节点 endpos 集合中小于等于 i i i 的最大值,而显然能更新的只有从 d i d_i di 节点沿 link 树上的全部祖先,因为只有这些节点的 endpos 集合中有 i i i。
该步骤可以通过树链剖分+区间合并线段树完成。对于每个线段树上节点,维护它所对应链的左侧颜色和右侧颜色,以及最靠右(对应于树上的更深侧)的颜色变化点 div(即从这里开始颜色发生变化),那么这个信息非常容易区间合并。同时同步的使用树状数组维护前面的 j j j 条链现在的长度 w j w_j wj(即颜色为 j j j 的点的 l l l 之和),那么对于固定 r r r 的全部询问 [ l , r ] [l,r] [l,r],答案就是 ∑ k = l r w k \displaystyle \sum_{k=l}^r w_k k=l∑rwk。
因而总的时间复杂度为 O ( n log 2 n ) \mathcal O(n\log^2n) O(nlog2n)。
#include E Everyone is bot
题意: n n n 个人打算复读。一次复读的过程如下,每一轮, n n n 个人按照编号从小到大依次执行以下操作:如果这个人在前几轮已经进行过复读,他不会再次复读,否则他可以选择复读。如果某一轮没有人进行复读,那么复读的过程结束。 结束后选择复读的倒数第 p p p 个人会扣分,而其他的人会得分(第 i i i 个人若为第 j j j 个复读的,则会获得 a i , j > 0 a_{i,j}>0 ai,j>0 的分数)。每个人最大化得分,问最终每个人的分数。 1 ≤ p ≤ n ≤ 1 × 1 0 3 1 \leq p \leq n \leq 1\times 10^3 1≤p≤n≤1×103。
解法:只有 n m o d p n \bmod p nmodp 个人会得分。
若最后只有 p p p 个人还没复读,剩下的人都已经复读了,那么最后的 p p p 个人谁都不会说话:若某个人选择复读,则后面每个人都因为不会被扣分而选择复读,那么谁开启了最后 p p p 个人的复读谁就会扣分,而让别人加分,因而没人会当冤大头。
那么对于 n − 2 p + 1 n-2p+1 n−2p+1 到第 n − p n-p n−p 个选择复读的人,他们同样会陷入这个困境:因为一旦最后的 p p p 个人因为上面的逻辑没人去复读为第一个开启这一段复读的人埋单(使得他不会成为倒数第 p p p 个),那么这一段也会因为同样的逻辑每个人都选择不复读,以保证自己不会被扣分。同理最后的每 p p p 个人都会因为同样的逻辑都不复读,哪怕 a i , j a_{i,j} ai,j 非常的大。因而最后只有 n m o d p n \bmod p nmodp 个人会复读。这些人因为是一定会复读的(没有人可以使得他们成为倒数第 p p p 个),所以排在前面的一定会先下手为强。所以前 n m o d p + 1 n \bmod p+1 nmodp+1 个人按顺序复读。
#include G Good red-string
题意:给定一个长度为 n n n 的串,仅由 r,e,d,?构成。问能够找到一种将全部的 ?转化为 r,e,d中的一种字符,使得最后的串由 n 3 \dfrac{n}{3} 3n 个不相交的 red子序列构成。例如 reredd符合条件而 rederd不符合条件。保证 n n n 为三的倍数, n ≤ 3 × 1 0 5 n \leq 3\times 10^5 n≤3×105。
解法:考虑对 e的约束条件:每一个 d前必须至少有一个 e;每一个 r后面至少有一个 e。因而仅针对这两条关系,可以用栈去安排出刚需的问号转化方法。对于剩下的问号,则从左到右的尽可能安排 red即可。最后检查一下是否符合条件即可。
这样做的正确性在于,所有的约束关系都集中到 e这里,也就是在单独对 r贪心的时候,也是符合 d的贪心要求的。
#include H Here is an Easy Problem of Zero-chan
题意:给定一个 n n n 个节点以 1 1 1 为根的树, q q q 次询问,每次给定 x x x,问 ∏ i = 1 n l c a ( x , i ) \displaystyle \prod_{i=1}^n {\rm lca}(x,i) i=1∏nlca(x,i) 的后缀有多少个 0 0 0。 n , q ≤ 1 × 1 0 5 n,q \leq 1\times 10^5 n,q≤1×105。
解法:可以通过换根计算出每个点的后缀 0 0 0 个数。显然 x = 1 x=1 x=1 时答案为 0 0 0。考虑从 u u u 节点走到它的一个儿子 v v v,那么 l c a ( x , i ) {\rm lca}(x,i) lca(x,i) 中 v v v 出现次数增加 s i z e v {\rm size}_v sizev 次,而 u u u 的出现次数减少 s i z e v {\rm size}_v sizev 次。因而可以通过维护 2 2 2 和 5 5 5 因子个数 O ( 1 ) O(1) O(1) 的统计答案。
#include J Jellyfish and its dream
题意:给定长度为 n n n 的环形序列 a 0 , a 1 , ⋯ , a n − 1 a_0,a_1,\cdots,a_{n-1} a0,a1,⋯,an−1,仅由 0 , 1 , 2 0,1,2 0,1,2 构成。若 a i + 1 ≡ a i m o d n + 1 ( m o d 3 ) a_i+1 \equiv a_{i \bmod n+1} \pmod 3 ai+1≡aimodn+1(mod3),则令 a i ← ( a i + 1 ) m o d 3 a_i \leftarrow (a_i+1) \bmod 3 ai←(ai+1)mod3。问能否经过若干次操作使得 a 0 = a 1 = ⋯ = a n − 1 a_0=a_1=\cdots=a_{n-1} a0=a1=⋯=an−1。 n ≤ 2 × 1 0 5 n \leq 2\times 10^5 n≤2×105。
解法:相邻加一考虑差分。设 b b b 数组为 a a a 的差分数组,最终的目标是需要让 b i = 0 b_i=0 bi=0。则对于 b b b 数组中出现了 ( 2 , 1 ) (2,1) (2,1) 的情况( b i = 2 , b i + 1 = 1 b_i=2,b_{i+1}=1 bi=2,bi+1=1),则必然可以经过该操作使得 b i = b i + 1 = 0 b_i=b_{i+1}=0 bi=bi+1=0, ( 1 , 1 ) (1,1) (1,1) 变成 ( 2 , 0 ) (2,0) (2,0),而 ( 0 , 1 ) (0,1) (0,1) 变成 ( 1 , 0 ) (1,0) (1,0)。而通过 ( 0 , 1 ) → ( 1 , 0 ) (0,1) \to (1,0) (0,1)→(1,0) 可以将 1 1 1 平移,最终为了要消掉所有的 2 2 2,只能通过 ( 2 , 1 ) → ( 0 , 0 ) (2,1) \to (0,0) (2,1)→(0,0) 来完成。因而 2 2 2 的数目不可以多于 1 1 1 的数目。
#include K Killer Sajin’s Matrix
题意:给定 n × m n\times m n×m 的矩阵,要求在其中填入 k k k 个 1 1 1 使得每行每列 1 1 1 的个数均为奇数。输出一个合法方案或者报告无解。 n , m , k ≤ 1 × 1 0 5 n,m,k \leq 1\times 10^5 n,m,k≤1×105。
解法:(感谢 Oscar 提供的做法)
显然通过不断的交换列与行可以使得所有的 1 1 1 都安放在斜对角的矩阵中,且每行每列必然至少有一个 1 1 1,如下图的形态:

设每个满 1 1 1 矩阵的长和宽分别为 x i , y i x_i,y_i xi,yi,则有 ∑ x i = n \sum x_i=n ∑xi=n, ∑ y i = m \sum y_i=m ∑yi=m,同时 ∑ x i y i = k \sum x_iy_i=k ∑xiyi=k。注意到 x i , y i x_i,y_i xi,yi 必然为奇数,则矩阵个数与 n , m , k n,m,k n,m,k 奇偶性相同,所以 n , m , k n,m,k n,m,k 的奇偶性必须完全相同。
考虑 n , m , k n,m,k n,m,k 均为奇数的情况。首先考虑一个 3 × 3 3\times 3 3×3 的基本型:
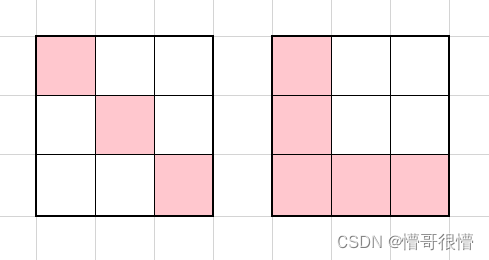
对于 3 × 3 3\times 3 3×3 的矩形,最少需要斜对角的 3 3 3 个保证每行每列都有一个 1 1 1。可以通过删除中间的一个,增补周围的 3 3 3 个变成一个 L 型,使用 5 5 5 个 1 1 1。通过这一变换使得 1 1 1 的个数增加了 2 2 2。
显然最少需要 max ( n , m ) \max(n,m) max(n,m) 个 1 1 1,此时的放置方案为斜对角的放置 min ( n , m ) \min(n,m) min(n,m) 个 1 1 1,再在最后一行放置 max ( n , m ) − min ( n , m ) \max(n,m)-\min(n,m) max(n,m)−min(n,m) 个 1 1 1,如下所示:

考虑当 1 1 1 增多的时候如何修改。显然当 k ≤ n + m − 1 k \leq n+m-1 k≤n+m−1 时,我们一直可以将一个 3 × 3 3\times 3 3×3 的斜对角通过删除中间一个 1 1 1,增加周围的 3 3 3 个 1 1 1 来增加两个 1 1 1:(该步操作可以称为 3 → 5 3\to 5 3→5)

那么当我们达成了 n + m − 1 n+m-1 n+m−1:也就是周围第一列、最后一行全都是 1 1 1 之后,对于内侧的 ( n − 1 ) × ( m − 1 ) (n-1)\times (m-1) (n−1)×(m−1),因为 n − 1 , m − 1 n-1,m-1 n−1,m−1 均为偶数,因而可以一口气放上一个 2 × 2 2\times 2 2×2 而不影响任何的奇偶性:

但是这样的操作不会改变 1 1 1 的个数对 4 4 4 的余数。因而如果 k − ( n + m − 1 ) ≡ 2 ( m o d 4 ) k-(n+m-1) \equiv 2\pmod 4 k−(n+m−1)≡2(mod4),则最后一步 3 → 5 3\to 5 3→5 操作不应当进行,以调整最后的余数。

注意到 k = ( n − 1 ) ( m − 1 ) − 2 k=(n-1)(m-1)-2 k=(n−1)(m−1)−2 是必然无解的:最后仅剩的两格必然会让所在的行或列不满足要求。
接下来考虑偶数的方案。同样基于该思想,首先构造一个 k k k 最小的答案:

然后以两行为基本单元开始不断调整(省略剩下的 4 4 4 行),其基本原理还是逐步增加 2 2 2 个格子:

最大的 k k k 为 n m − max ( n , m ) nm-\max(n,m) nm−max(n,m):即反选的答案。
可以参考 Oscar 的代码:https://ac.nowcoder.com/acm/contest/view-submission?submissionId=53401391
L Lndjy and the mex
题意:给定长度为 n n n 的序列 { a i } \{a_i\} {ai},满足 ∑ a i = n \sum a_i=n ∑ai=n。问由 a 0 a_0 a0 个 0 0 0, a 1 a_1 a1 个 1 1 1,……, a n a_n an 个 n n n 构成的全部 n ! ∏ i = 0 n a i ! \displaystyle \dfrac{n!}{\prod_{i=0}^n a_i!} ∏i=0nai!n! 个序列中,每个序列的全部连续子序列的 m e x \rm mex mex 值之和。 n ≤ 1 × 1 0 5 n \leq 1\times 10^5 n≤1×105。
解法:显然直接求 m e x \rm mex mex 是非常不好做的,尝试将其转化为方案数。设 f i f_i fi 表示连续子序列的 m e x \rm mex mex 值为 i i i 的连续子序列个数,则答案为 ∑ i = 0 + ∞ i f i \displaystyle \sum_{i=0}^{+\infty}if_i i=0∑+∞ifi,令 g i = ∑ j = i + ∞ f j \displaystyle g_i=\sum_{j=i}^{+\infty}f_j gi=j=i∑+∞fj,则有:
∑ i = 0 + ∞ i f i = ∑ i = 1 + ∞ i ( g i − g i + 1 ) = ∑ i = 1 + ∞ g i \begin{aligned} \sum_{i=0}^{+\infty}if_i=&\sum_{i=1}^{+\infty}i(g_{i}-g_{i+1})\\ =&\sum_{i=1}^{+\infty}g_i \end{aligned} i=0∑+∞ifi==i=1∑+∞i(gi−gi+1)i=1∑+∞gi
以上的化简是用到了 g + ∞ = 0 g_{+\infty}=0 g+∞=0。
注意到 g i g_i gi 的组合意义为,连续子序列 m e x \rm mex mex 值大于等于 i i i 的序列个数,等价于 0 ∼ i − 1 0 \sim i-1 0∼i−1 的数字至少出现一次,其余数字随意的方案数。考虑到每个数字选了多少个,假设第 i i i 个数字选了 b i b_i bi 个,那么有:
g i = ∑ b 0 = 1 a 0 ∑ b 1 = 1 a 1 ⋯ ∑ b i − 1 = 1 a i − 1 ∑ b i = 0 a i ∑ b i + 1 = 0 a i + 1 ⋯ ∑ b n = 0 a n ( ∑ j = 0 n b j b 0 , b 1 , ⋯ , b n ) ( n − ∑ j = 0 n b j a 0 − b 0 , a 1 − b 1 , ⋯ , a n − b n ) ( n − ∑ j = 0 n b j + 1 ) g_i=\sum_{b_0=1}^{a_0}\sum_{b_1=1}^{a_1}\cdots \sum_{b_{i-1}=1}^{a_{i-1}}\sum_{b_i=0}^{a_i}\sum_{b_{i+1}=0}^{a_{i+1}}\cdots \sum_{b_{n}=0}^{a_{n}} {\sum_{j=0}^n b_j \choose b_0,b_1,\cdots,b_n}{n-\sum_{j=0}^n b_j \choose a_0-b_0,a_1-b_1,\cdots,a_n-b_n}\left(n-\sum_{j=0}^nb_j+1\right) gi=b0=1∑a0b1=1∑a1⋯bi−1=1∑ai−1bi=0∑aibi+1=0∑ai+1⋯bn=0∑an(b0,b1,⋯,bn∑j=0nbj)(a0−b0,a1−b1,⋯,an−bnn−∑j=0nbj)(n−j=0∑nbj+1)
即首先是连续子序列内部的排列,再是外部的排列,最后再将这个连续子序列插入完整的序列。那么这个问题就可以非常容易的使用 EGF 得到解决:设 f i ( x ) f_i(x) fi(x) 表示数字 i i i 的选择方案的 EGF, f i ( x ) = ∑ j = 0 a i x j j ! ( a i − j ) ! \displaystyle f_i(x)=\sum_{j=0}^{a_i}\dfrac{x^j}{j!(a_i-j)!} fi(x)=j=0∑aij!(ai−j)!xj, g i ( x ) = f i ( x ) − 1 a i ! g_i(x)=f_i(x)-\dfrac{1}{a_i!} gi(x)=fi(x)−ai!1 表示至少选一个的方案,则最终的答案为:
∑ s = 0 n ( n − s + 1 ) ! ( s ! [ x s ] ∑ i = 0 n − 1 ∏ j = 0 i g j ( x ) ∏ j = i + 1 n f j ( x ) ) \sum_{s=0}^n(n-s+1)!\left(s![x^s]\sum_{i=0}^{n-1}\prod_{j=0}^{i}g_j(x)\prod_{j=i+1}^nf_j(x)\right) s=0∑n(n−s+1)!(s![xs]i=0∑n−1j=0∏igj(x)j=i+1∏nfj(x))
注意:此处和通常的 EGF 稍有区别。正常的 EGF 由于不考虑外侧的排列,为 f i ( x ) = ∑ j = 0 a i x j j ! \displaystyle f_i(x)=\sum_{j=0}^{a_i}\dfrac{x^j}{j!} fi(x)=j=0∑aij!xj。而当选定连续子序列中数字个数确定,外侧也随之确定,他们的排列数为 ( n − s + 1 ) ! ( a i − j ) ! \dfrac{(n-s+1)!}{(a_i-j)!} (ai−j)!(n−s+1)!,因而可以将此系数杂糅进 f i ( x ) f_i(x) fi(x)。
考虑使用分治 NTT 去计算上式:对于区间 ( l , r ) (l,r) (l,r) 维护 F 1 ( x , l , r ) = ∏ i = l r g i ( x ) , F 2 ( x , l , r ) = ∏ i = l r f i ( x ) , F 3 ( x , l , r ) = ∑ i = l r − 1 ∏ j = l i g i ( x ) ∏ j = i + 1 r f i ( x ) \displaystyle F_1(x,l,r)=\prod_{i=l}^rg_i(x),F_2(x,l,r)=\prod_{i=l}^rf_i(x),F_3(x,l,r)=\sum_{i=l}^{r-1}\prod_{j=l}^{i}g_i(x)\prod_{j=i+1}^rf_i(x) F1(x,l,r)=i=l∏rgi(x),F2(x,l,r)=i=l∏rfi(x),F3(x,l,r)=i=l∑r−1j=l∏igi(x)j=i+1∏rfi(x),则有 F 3 ( x , l , r ) = F 1 ( x , l , m ) F 3 ( x , m + 1 , r ) + F 3 ( x , l , m ) F 2 ( x , m + 1 , r ) − F 1 ( x , l , m ) F 2 ( x , m + 1 , r ) F_3(x,l,r)=F_1(x,l,m)F_3(x,m+1,r)+F_3(x,l,m)F_2(x,m+1,r)-F_1(x,l,m)F_2(x,m+1,r) F3(x,l,r)=F1(x,l,m)F3(x,m+1,r)+F3(x,l,m)F2(x,m+1,r)−F1(x,l,m)F2(x,m+1,r)。因而可以 O ( n log 2 n ) \mathcal O(n\log^2n) O(nlog2n) 的通过。
Poly f[N + 5], g[N + 5], gf[N + 5];
int a[N + 5];
void build(int place, int left, int right)
{
if (left == right)
{
f[place].resize(a[left] + 1);
for (int i = 0; i <= a[left]; i++)
f[place][i] = 1ll * ifac[i] * ifac[a[left] - i] % P;
g[place] = f[place];
g[place][0] = 0;
gf[place] = f[place] + g[place];
return;
}
int mid = (left + right) >> 1;
build(place << 1, left, mid);
build(place << 1 | 1, mid + 1, right);
f[place] = f[place << 1] * f[place << 1 | 1];
g[place] = g[place << 1] * g[place << 1 | 1];
gf[place] = g[place << 1] * gf[place << 1 | 1] + gf[place << 1] * f[place << 1 | 1] - g[place << 1] * f[place << 1 | 1];
}
int main()
{
int n;
scanf("%d", &n);
for (int i = 0; i <= n;i++)
scanf("%d", &a[i]);
build(1, 0, n);
Poly F = gf[1] - f[1];
int ans = 0;
for (int i = 1; i <= n; i++)
ans = (ans + 1ll * (n - i + 1) * fac[i] % P * fac[n - i] % P * F[i]) % P;
printf("%d", ans);
return 0;
}