AttnGAN: Fine-Grained Text to Image Generation with Attentional Generative Adversarial Networks论文解读
题目:AttnGAN:具有注意的生成对抗网络的细粒度文本到图像生成
时间:2018
作者:Tao Xu, Pengchuan Zhang, Qiuyuan Huang, Han Zhang, Zhe Gan, Xiaolei Huang, Xiaodong He
CVPR
Abstract
在本文中,我们提出了一种注意力生成对抗网络(AttnGAN),它允许对细粒度文本到图像的生成进行注意力驱动和多阶段细化。通过一种新的注意生成网络,AttnGAN可以通过关注自然语言描述中的相关单词,在图像的不同子区域合成细粒度细节。
此外,本文还提出了一个深度注意多模态相似性模型来计算细粒度图像到文本的匹配损失,以训练生成器。提出的AttnGAN显著优于之前的最新水平,在CUB数据集和更具挑战性的COCO数据集上,最佳报告的初始得分分别提高了14.14%和170.25%。通过可视化AttnGAN的注意层,也可以进行详细的分析。这是第一次表明分层注意GAN能够自动选择单词级别的条件来生成图像的不同部分。
1.Introduction
- 文本生成图像的现状:根据自然语言描述自动生成图像是许多应用中的一个基本问题,例如艺术生成和计算机辅助设计。它还推动了视觉和语言推断和多模态学习的研究进展,这是近年来最活跃的研究领域之一 。
- 之前工作的局限性:最新提出的文本到图像的合成方法基于生成性对抗网络(GAN)。一种常用的方法是将整个文本描述编码为全局句子向量,作为基于GAN的图像生成的条件。虽然已经给出了令人印象深刻的结果,条件GAN只有全局句子向量缺乏单词级的重要细粒度信息,并阻止高质量图像的生成。当生成复杂场景(如COCO数据集中的场景)时,这个问题变得更加严重。
- 本文的解决方案:为解决这个问题,我们提出了一种注意力生成对抗网络(AttnGAN),它允许注意力驱动、多阶段细化的细粒度文本到图像的生成。AttnGAN的总体架构如图2所示。

- AttnGAN由两个新组件组成:
(1)第一个组成部分是注意力生成网络,其中为生成器开发了一种注意机制,让生成器通过关注与所绘制的子区域最相关的单词来绘制图像的不同子区域(见图1)。更具体地说,除了将自然语言描述编码为一个全局句子向量外,句子中的每个单词也被编码为一个单词向量。生成网络在第一阶段利用全局句子向量生成低分辨率图像。在接下来的步骤中,它使用每个子区域中的图像向量,通过使用一个注意层来形成单词上下文向量来查询单词向量。然后,该模型将区域图像向量和相应的单词上下文向量结合起来,形成多模态上下文向量,并在此基础上在周围的子区域生成新的图像特征。这有效地产生了更高分辨率的图片,每个阶段都有更多细节。

(2)AttnGAN的另一个组成部分是深度注意多模态相似模型(DAMSM)。通过注意机制,DAMSM能够利用全局句子级信息和细粒度单词级信息计算生成的图像和句子之间的相似性。因此,DAMSM为训练生成器提供了额外的细粒度图像到文本的匹配损失。 - 本文的贡献:
(1)提出了一种注意生成对抗网络,用于从文本描述中合成图像。具体来说,AttnGAN提出了两个新的组成部分,包括注意生成网络和DAMSM。
(2)进行广泛的研究,经验性评估提出的AttnGAN。实验结果表明,AttnGAN的性能明显优于以前最先进的GAN模型。
(3)通过可视化AttnGAN的注意层进行详细分析。首次证明了分层条件GAN能够自动关注相关单词,形成图像生成的条件。 - 代码:AttnGAN代码
2.Related Work
- 从文本描述中生成高分辨率图像虽然非常具有挑战性,但对于艺术生成和计算机辅助设计等许多实际应用来说非常重要。最近,随着深层生成模型的出现,这方面取得了巨大进展。Mansimov等人建立了alignDRAW模型,扩展了深度反复注意力书写器(DRAW),在关注字幕中的相关单词的同时,反复绘制图像补丁。Nguyen等人提出了一种近似的Langevin方法来从字幕生成图像。Reed等人使用条件PixelCNN从具有多尺度模型结构的文本中合成图像。与其他深度生成模型相比,生成性对抗网络在生成更尖锐的样本方面表现出了出色的性能。Reed等人首先表明,条件GAN能够从文本描述中合成看似合理的图像。他们的后续工作还表明,GAN能够通过加入附加条件(例如,对象位置)生成更好的样本。Zhang等人将多个GAN堆叠起来进行文本到图像合成,并使用不同的GAN生成不同大小的图像。然而,他们所有的GAN都以全局句子向量为条件,缺少用于图像生成的细粒度单词级信息。
- 注意机制最近已成为序列转换模型的一个必要组成部分。它已成功地用于建模图像字幕、图像问答和机器翻译中的多级依赖关系。Vaswani等人还证明,机器翻译模型可以通过单独使用注意模型来实现最先进的结果。尽管取得了这些进展,但在GAN中,文本到图像合成的注意机制尚未被探索。值得一提的是,alignDRAW还使用LAP-GAN将图像缩放到更高的分辨率。然而,在他们的框架中,GAN只被用作后处理步骤,没有注意。据我们所知,提出的AttnGAN首次开发了一种注意力机制,使GAN能够通过多层(例如,单词级和句子级)条件作用生成细粒度的高质量图像。
3.Attentional Generative Adversarial Network
如图2所示,提出的注意生成对抗网络(AttnGAN)有两个新的组成部分:注意生成网络和深度注意多模态相似模型。我们将在本节的其余部分详细介绍其中的每一项。
3.1Attentional Generative Network
当前基于GAN的文本到图像生成模型通常将整个句子文本描述编码为单个向量,作为图像生成的条件,但缺乏细粒度的单词级信息。在本节中,我们提出了一种新的注意模型,该模型使生成网络能够根据与这些子区域最相关的单词绘制图像的不同子区域。
如图2所示,提出的注意生成网络有m个生成器(G0,G1,…,Gm−1) ,它取隐藏状态(h0,h1,…,hm−1) 作为输入并生成从小到大比例的图像(ˆx0,ˆx1,…,ˆxm-1)。具体来说,
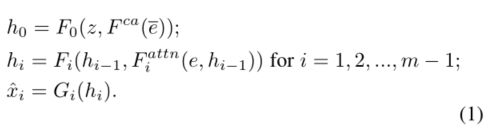


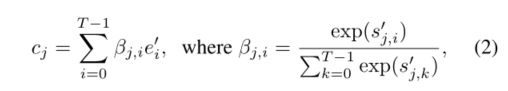

为了生成具有多个条件层次(即句子层次和单词层次)的真实图像,注意生成网络的最终目标函数被定义为 :

这里,λ是一个超参数,用于平衡等式(3)的两项。第一项是GAN损失,它联合近似于条件和无条件分布。在AttnGAN的第i级,生成器G_i具有相应的鉴别器D_i。G_i的对抗性损失定义为:

其中,无条件损失决定图像是真是假,而条件损失决定图像和句子是否匹配。
与G_i的训练交替地,每个鉴别器D_i都被训练通过最小化定义的交叉熵损失,将输入分类为真或假


等式(3)的第二项L_DAMSM是由DAMSM计算的单词级细粒度图像到文本的匹配损失,将在第3.2小节中详细说明。
3.2Deep Attentional Multimodal Similarity Model
DAMSM学习两个神经网络,将图像的子区域和句子的单词映射到一个公共语义空间,从而在单词级别测量图像-文本相似度,以计算图像生成的细粒度损失。




注意驱动的图像-文本匹配分数是根据图像和文本之间的注意模型来衡量图像-句子对的匹配程度。
我们首先计算句子中所有可能的词对和图像中的子区域的相似度矩阵:
![]()



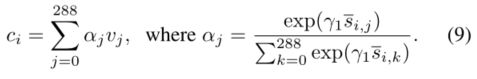







"w"代表的是单词。
对称地,我们也最小化:

句子D_i与其对应的图像Q_i匹配的后验概率为:
![]()

![]()
基于在一个持久的验证集上的实验,我们将本节中的超参数设置为:γ1=5、γ2=5、γ3=10和M=50。DAMSM被预训练通过使用真实图像-文本对最小化L_DAMSM。由于预训练DAMSM的图像大小不受可生成图像大小的限制,因此使用大小为299×299的真实图像。此外,DAMSM中的预训练文本编码器为注意力生成网络提供了从图像-文本对数据中学习的视觉鉴别词向量。相比之下,在纯文本数据上预训练的传统词向量通常在视觉上没有区分性,例如,不同颜色的词向量,例如红色、蓝色、黄色等,由于缺乏与实际视觉信号的联系,通常在向量空间中聚集在一起。
总之,我们提出了两种新的注意模型,注意生成网络和DAMSM,它们在AttnGAN中扮演着不同的角色。(1)生成网络中的注意机制(见等式2)使AttnGAN能够自动选择单词级条件来生成图像的不同子区域。(2)通过注意机制(见等式9),DAMSM能够计算细粒度文本到图像的匹配损失L_DAMSM。值得一提的是,L_DAMSM仅适用于最后一个生成器G_(m-1)的输出,因为AttnGAN的最终目标是通过最后一个生成器生成大图像。我们尝试在(G_0,G_1,…,G_(m-1))生成的所有分辨率的图像上应用L_DAMSM. 然而,性能没有得到改善,但计算成本增加。
4.Experiments
进行了大量实验来评估提出的AttnGAN。我们首先研究AttnGAN的重要组成部分,包括注意生成网络和DAMSM。然后,我们将AttnGAN与之前用于文本到图像合成的最先进的GAN模型进行比较。
数据集。与之前的文本到图像方法相同,我们的方法是在CUB和COCO数据集上评估的。我们按照[36]中的方法对CUB数据集进行预处理。表1列出了数据集的统计数据。

评价我们使用初始分数作为定量评估指标。由于初始分数不能反映生成的图像是否良好地依赖于给定的文本描述,因此我们建议使用R-精度作为文本到图像合成任务的补充评估指标,R-精度是一种对检索结果进行排名的常用评估指标。如果一个查询有R个相关文档,我们检查一个系统中排名前R的检索结果,发现r个是相关的,然后根据定义,R-精度是r/R。更具体地说,我们进行检索实验,即使用生成的图像来查询它们对应的文本描述。首先,利用预训练DAMSM中学习的图像和文本编码器提取生成图像和给定文本描述的全局特征向量。然后,我们计算全局图像向量和全局文本向量之间的余弦相似性。最后,我们对每幅图像的候选文本描述按相似性递减进行排序,并找到计算R-精度的前r个相关描述。为了计算初始分数和R精度,每个模型从随机选择的看不见的文本描述中生成30000个图像。每个查询图像的候选文本描述由一个基本事实(即R=1)和99个随机选择的不匹配描述组成。

![]()
我们通过以下方式抑制和图像子区域不太相关的单词:
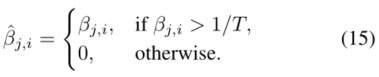

4.1 Component analysis
- 在本节中,我们首先定量评估AttnGAN及其变体。结果如表2,图3所示 。我们的“AttnGAN1”架构有一个注意力模型和两个生成器,而“AttnGAN2”架构有两个注意力模型和三个生成器(见图2)。此外,如图4、图5、图6和图7所示,我们定性地检查了AttnGAN生成的图像。


2.DAMSM损失。为了测试提出的L_DAMSM,我们调整λ的值(见等式(3))。如图3所示,在CUB和COCO数据集上,较大的λ会导致更高的R精度率。在CUB数据集上,当λ的值从0.1增加到5时,AttnGAN1的初始分数从4.19提高到4.35,相应的R精度率从16.55%提高到58.65%(见表2)。在COCO数据集上,通过将λ的值从0.1增加到50,AttnGAN1实现了较高的初始分数和R精度率(见图3)。这种比较表明,**适当增加L_DAMSM的权重有助于生成更高质量的图像,更好地适应给定的文本描述。原因是,提出的细粒度图像到文本的匹配损失L_DAMSM为生成器的训练提供了额外的监督(即单词级匹配信息)。**此外,在我们的实验中,我们没有观察到在AttnGAN生成的图像的可视化中有任何崩溃的无意义模式。这表明,在额外的监督下,细粒度图像到文本的匹配损失也有助于稳定AttnGAN的训练过程。此外,在CUB数据集上训练了一个基线模型,带有文本编码器“AttnGAN1,没有注意机制”。在不使用注意的情况下,其初始得分和R精度分别下降到3.98%和10.37%,这进一步证明了所提出的L_DAMSM的有效性。 - 注意生成网络。如表2和图3所示,在生成网络中叠加两个注意力模型不仅可以生成更高分辨率(从128×128到256×256分辨率)的图像,还可以在CUB和COCO数据集上获得更高的初始分数。为了保证图像质量,我们通过增加λ的值来找到每个数据集的λ的最佳值,直到在一个保持的验证集上的总体初始分数开始下降。建立“AttnGAN1”模型用于找到最佳λ,在此基础上建立“AttnGAN2”模型以生成更高分辨率的图像。由于GPU内存限制,我们没有尝试使用三个注意力模型的AttnGAN。因此,CUB和COCO数据集上的最终模型分别为“AttnGAN2,λ=5”和“AttnGAN2,λ=50”。COCO数据集的最终λ远大于CUB数据集的λ,这表明提出的L_DAMSM对于生成像COCO数据集中的复杂场景尤其重要。
- 为了更好地理解AttnGAN所学到的东西,我们将注意力集中在可视化它的中间结果上。如图4所示,AttnGAN(G0)的第一阶段仅绘制对象的基本形状和颜色,并生成低分辨率图像。由于这一阶段只使用全局句子向量,因此生成的图像缺乏精确单词描述的细节,例如鸟的喙和眼睛。基于单词向量,下面的阶段(G1和G2)学习纠正前一阶段结果中的缺陷,并添加更多细节以生成更高分辨率的图像。G1或G2图像的一些子区域/像素可以直接从前一阶段生成的图像中推断出来。对于这些子区域,注意力平均分配给所有单词,并在注意力图中显示为黑色(见图4)。对于其他子区域,它们通常在文本描述中表达语义,例如对象的属性,注意力被分配到和它们最相关的单词上(图4中的亮区)。因此,这些区域是从这些区域的单词上下文特征和之前的图像特征中推断出来的。如图4所示,在CUB数据集上,单词the,this,bird通常被F attn模型注意,用于定位对象。描述对象属性的单词,如颜色和鸟的部分,也用于纠正缺陷和绘制细节。在COCO数据集上,我们有类似的观察结果。由于每个COCO图像中通常有多个对象,因此更明显的是,描述不同对象的单词由图像的不同子区域表示,例如图4右下角的香蕉、猕猴桃。这些观察结果表明,AttnGAN学会了理解图像的文本描述中表达的详细语义。另一个观察结果是,我们的第二个注意模型F attn2能够注意到一些被第一个注意模型F attn1省略的新词(见图4)。它表明,为了提供更丰富的信息,以便在AttnGAN后期生成更高分辨率的图像,相应的注意模型学习恢复在前一阶段忽略的对象和属性。

- 泛化能力。我们上面的实验结果通过从看不见的文本描述生成图像,定量和定性地显示了AttnGAN的泛化能力。在这里,我们通过改变文本描述中一些最受关注的单词,进一步测试输出对输入句子变化的敏感性。图5显示了一些示例。该模型根据输入句子的变化对生成的图像进行修改,表明该模型能够捕捉文本描述中的细微语义差异。此外,如图6所示,我们的AttnGAN可以生成图像,以反映真实世界中不太可能发生的新场景描述的语义,例如,湖面上漂浮着一个停车标志。另一方面,我们也观察到,AttnGAN有时会生成清晰而详细的图像,但不太可能是真实的。如图7所示,AttnGAN创造了多个头、眼睛或尾巴的鸟,这只存在于童话中。这表明我们目前的方法在捕获全局连贯结构方面还不够完美,还有待改进。综上所述,图5、图6和图7所示的观察结果进一步证明了AttnGAN的泛化能力。

4.2Comparison with previous methods
- 我们将AttnGAN和之前在CUB和COCO测试集上进行文本到图像生成的最先进的GAN模型进行了比较。如表3所示,在CUB上,AttnGAN获得了4.36的初始分数,这显著优于之前的最佳初始分数3.82。更令人印象深刻的是,AttnGAN将COCO的最佳初始分数从9.58提高到了25.89,相对提高了170.25%。众所周知,COCO数据集比CUB数据集更具挑战性,因为它由场景更复杂的图像组成。现有方法难以在该数据集上生成逼真的高分辨率图像。图4和图6中的示例说明,AttnGAN成功地为COCO数据集上的各种场景生成了256×256的图像,尽管COCO数据集生成的图像不如CUB数据集生成的图像逼真。实验结果表明,与以前的最先进的方法相比,AttnGAN在生成复杂场景方面更有效,因为它具有新颖的注意机制,能够在文本到图像生成中捕获细粒度的单词级和子区域级信息。

- 除了StackGAN-v2,提出的注意机制也可以应用于广泛使用的DCGAN框架。在CUB数据集上,我们构建了一个ATTNDCGAN和一个vanilla DCGAN。虽然仅以句子向量为条件的vanilla DCGAN(没有提出的注意机制)无法生成合理的256×256图像,但我们的AttnDCGAN能够生成逼真的图像。ATTNDCGAN的初始得分为4.12±0.05,R精度为38.45±4.26%。由于严重的模式崩溃,vanilla DCGAN仅达到2.47±0.01初始分数和3.69±1.82%的R精度。比较结果进一步证明了所提出的注意机制的有效性。
5.Conclusions
本文提出了一种用于细粒度文本到图像合成的注意力生成对抗网络AttnGAN。我们构建了一个新的注意力生成网络,让AttnGAN通过多阶段过程生成高质量的图像。我们提出了一个深度注意多模态相似模型来计算细粒度图像-文本的匹配损失,以训练AttnGAN的生成器。我们的AttnGAN显著优于最先进的GAN模型,在CUB数据集和更具挑战性的COCO数据集上,分别将最佳初始分数提高了14.14%和170.25%。大量的实验结果证明了AttnGAN中提出的注意机制的有效性,这对于复杂场景中的文本到图像生成尤其关键。