Python的23种设计模式(完整版带源码实例)
作者:虚坏叔叔
博客:https://xuhss.com
早餐店不会开到晚上,想吃的人早就来了!
Python的23种设计模式
一 什么是设计模式
设计模式是面对各种问题进行提炼和抽象而形成的解决方案。这些设计方案是前人不断试验,考虑了封装性、复用性、效率、可修改、可移植等各种因素的高度总结。它不限于一种特定的语言,它是一种解决问题的思想和方法
二 为什么要有设计模式
公司人事会有变动,程序员也会成长。不管是哪种情况,代码非常有可能会被移交,即代码的编写者和维护者很有可能会是不同的人。那么代码的可读性就显得非常重要了。由于高级语言的出现,让机器读懂你的意图已经不是最主要的“矛盾”,而让人读懂你的意图才是最重要。按照设计模式编写的代码,其可读性也会大大提升,利于团队项目的继承和扩展
三 有那些设计模式
设计模式可以分为三个大类: 创建类设计模式、结构类设计模式、行为类设计模式
创建类设计模式(5种)
单例模式、工厂模式(简单工厂模式、抽象工厂模式)、建造者模式、原型模式
结构类设计模式(7种)
代理模式、装饰器模式、适配器模式、门面模式、组合模式、享元模式、桥梁模式
行为类设计模式(11种)
策略模式、责任链模式、命令模式、中介者模式、模板模式、迭代器模式、访问者模式、观察者模式、解释器模式、备忘录模式、状态模式
设计模式也衍生出了很多的新的种类,不局限于这23种
四 设计模式与架构,框架的关系
1 软件框架与设计模式的关系
软件框架随着软件工程的发展而出现,所谓的软件框架,是提取了特定领域的软件的共性部分所形成的软件体系,它并不是一个成熟的软件,而更像是一个“半成品”,程序员在框架之上,可以很方便地某些特定领域实现又快又可靠的二次开发。
设计模式 和 软件框架 在软件设计中是两个 不同 的研究领域:
A、设计模式如前边的定义所讲,它指的是针对一类问题的解决方法,一个设计模式可应用于不同的框架和被不同的语言所实现;而框架则是一个应用的体系结构,是一种或多种设计模式和代码的混合体;
B、设计模式相较于框架更容易移植,并且可以用各种语言实现,而软件框架则受限于领域大环境。虽然设计模式和软件框架有很多不同,但在某些方面他们二者是统一的,即重视软件复用,提高开发效率。
2 软件架构与设计模式的关系
软件架构是个比较大的概念,架构要考虑软件的整体结构、层次划分以及不同部分间的协作和交互等,架构的着眼点偏整体。
相比之下,框架和设计模式的范围则具体很多,框架着眼于领域内的解决方法,而设计模式则针对一类问题的解决方案和设计思路。
总体来说,软件架构可以由不同的框架和不同的设计模式,再加上特定的构件组合来实现;框架可以根据设计模式结合特定编程语言和环境来实现。设计模式就是解决单一问题的设计思路和解决方法。
1 单例模式
一、总线
总线是计算机各种功能部件或者设备之间传送数据、控制信号等信息的公共通信解决方案之一。
现假设有如下场景:某中央处理器(CPU)通过某种协议总线与一个信号灯相连,信号灯有64种颜色可以设置,中央处理器上运行着三个线程,都可以对这个信号灯进行控制,并且可以独立设置该信号灯的颜色。
抽象掉协议细节(用打印表示),如何实现线程对信号等的控制逻辑。
加线程锁进行控制,无疑是最先想到的方法,但各个线程对锁的控制,无疑加大了模块之间的耦合。下面,我们就用设计模式中的单例模式,来解决这个问题。
什么是单例模式?单例模式是指:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
具体到此例中,总线对象,就是一个单例,它仅有一个实例,各个线程对总线的访问只有一个全局访问点,即惟一的实例。
Python代码如下:
import threading
import time
class Singleton(object):
def __new__(cls, *args, **kw):
if not hasattr(cls, '_instance'):
orig = super(Singleton, cls)
cls._instance = orig.__new__(cls, *args, **kw)
return cls._instance
class Bus(Singleton):
lock = threading.RLock()
def sendData(self, data):
self.lock.acquire()
time.sleep(3)
print("Sending Signal Data...", data)
self.lock.release()
class VisitEntity(threading.Thread):
my_bus = ""
name = ""
def getName(self):
return self.name
def setName(self, name):
self.name = name
def run(self):
self.my_bus = Bus()
self.my_bus.sendData(self.name)
if __name__ == "__main__":
for i in range(3):
print("Entity %d begin to run..." % i)
my_entity = VisitEntity()
my_entity.setName("Entity_"+str(i))
my_entity.start()
运行结果如下:
Entity 0 begin to run...
Entity 1 begin to run...
Entity 2 begin to run...
Sending Signal Data... Entity_0
Sending Signal Data... Entity_1
Sending Signal Data... Entity_2
在程序运行过程中,三个线程同时运行(运行结果的前三行先很快打印出来),而后分别占用总线资源(后三行每隔3秒打印一行)。虽然看上去总线Bus被实例化了三次,但实际上在内存里只有一个实例。
二、单例模式
单例模式是所有设计模式中比较简单的一类,其定义如下:Ensure a class has only one instance, and provide a global point of access to it.(保证某一个类只有一个实例,而且在全局只有一个访问点)

三、单例模式的优点和应用
单例模式的优点
1、由于单例模式要求在全局内只有一个实例,因而可以节省比较多的内存空间;
2、全局只有一个接入点,可以更好地进行数据同步控制,避免多重占用;3、单例可长驻内存,减少系统开销。
单例模式的应用举例
1、生成全局惟一的序列号;
2、访问全局复用的惟一资源,如磁盘、总线等;
3、单个对象占用的资源过多,如数据库等;
4、系统全局统一管理,如Windows下的Task Manager;
5、网站计数器。
四、单例模式的缺点
1、单例模式的扩展是比较困难的;
2、赋于了单例以太多的职责,某种程度上违反单一职责原则(六大原则后面会讲到);
3、单例模式是并发协作软件模块中需要最先完成的,因而其不利于测试;4、单例模式在某种情况下会导致“资源瓶颈”。
2 工厂类相关模式(占了两种)
一、快餐点餐系统
想必大家一定见过类似于麦当劳自助点餐台一类的点餐系统吧。在一个大的触摸显示屏上,有三类可以选择的上餐品:汉堡等主餐、小食、饮料。当我们选择好自己需要的食物,支付完成后,订单就生成了。下面,我们用今天的主角–工厂模式–来生成这些食物的逻辑主体。首先,来看主餐的生成(仅以两种汉堡为例)。
class Burger():
name = ""
price = 0.0
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class cheeseBurger(Burger):
def __init__(self):
self.name = "cheese burger"
self.price = 10.0
class spicyChickenBurger(Burger):
def __init__(self):
self.name = "spicy chicken burger"
self.price = 15.0
其次,是小食。(内容基本一致)
class Snack():
name = ""
price = 0.0
type = "SNACK"
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class chips(Snack):
def __init__(self):
self.name = "chips"
self.price = 6.0
class chickenWings(Snack):
def __init__(self):
self.name = "chicken wings"
self.price = 12.0
最后,是饮料。
class Beverage():
name = ""
price = 0.0
type = "BEVERAGE"
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class coke(Beverage):
def __init__(self):
self.name = "coke"
self.price = 4.0
class milk(Beverage):
def __init__(self):
self.name = "milk"
self.price = 5.0
以上的Burger,Snack,Beverage,都可以认为是该快餐店的产品,由于只提供了抽象方法,我们把它们叫抽象产品类,而cheese burger等6个由抽象产品类衍生出的子类,叫作具体产品类。 接下来,“工厂”就要出现了。
class foodFactory():
type = ""
def createFood(self, foodClass):
print self.type, " factory produce a instance."
foodIns = foodClass()
return foodIns
class burgerFactory(foodFactory):
def __init__(self):
self.type = "BURGER"
class snackFactory(foodFactory):
def __init__(self):
self.type = "SNACK"
class beverageFactory(foodFactory):
def __init__(self):
self.type = "BEVERAGE"
同样,foodFactory为抽象的工厂类,而burgerFactory,snackFactory,beverageFactory为具体的工厂类。在业务场景中,工厂模式是如何“生产”产品的呢?
if __name__ == "__main__":
burger_factory = burgerFactory()
snack_factorry = snackFactory()
beverage_factory = beverageFactory()
cheese_burger = burger_factory.createFood(cheeseBurger)
print (cheese_burger.getName(), cheese_burger.getPrice())
chicken_wings = snack_factorry.createFood(chickenWings)
print (chicken_wings.getName(), chicken_wings.getPrice())
coke_drink = beverage_factory.createFood(coke)
print (coke_drink.getName(), coke_drink.getPrice())
可见,业务中先生成了工厂,然后用工厂中的createFood方法和对应的参数直接生成产品实例。打印结果如下:BURGER factory produce a instance.cheese burger 10.0SNACK factory produce a instance.chicken wings 12.0BEVERAGE factory produce a instance.coke 4.0
二、工厂模式、简单工厂模式、抽象工厂模式
工厂模式的定义如下:定义一个用于创建对象的接口,让子类决定实例化哪个类。工厂方法使一个类的实例化延迟到其子类。其通用类图如下。其产品类定义产品的公共属性和接口,工厂类定义产品实例化的“方式”。

)

在上述例子中,工厂在使用前必须实例化。如果,把工厂加个类方法,写成如下形式:
class simpleFoodFactory():
@classmethod
def createFood(cls,foodClass):
print "Simple factory produce a instance."
foodIns = foodClass()
return foodIns
在场景中写成如下形式:spicy_chicken_burger=simpleFoodFactory.createFood(spicyChickenBurger)这样,省去了将工厂实例化的过程。这种模式就叫做简单工厂模式。还是在上述例子中,createFood方法中必须传入foodClass才可以指定生成的food实例种类,如果,将每一个细致的产品都建立对应的工厂(如cheeseBurger建立对应一个cheeseBurgerFactory),这样,生成食物时,foodClass也不必指定。事实上,此时,burgerFactory就是具体食物工厂的一层抽象。这种模式,就是抽象工厂模式。
三、工厂模式的优点和应用
工厂模式、抽象工厂模式的优点:
1、工厂模式巨有非常好的封装性,代码结构清晰;在抽象工厂模式中,其结构还可以随着需要进行更深或者更浅的抽象层级调整,非常灵活;
2、屏蔽产品类,使产品的被使用业务场景和产品的功能细节可以分而开发进行,是比较典型的解耦框架。
工厂模式、抽象工厂模式的使用场景:
1、当系统实例要求比较灵活和可扩展时,可以考虑工厂模式或者抽象工厂模式实现。比如,在通信系统中,高层通信协议会很多样化,同时,上层协议依赖于下层协议,那么就可以对应建立对应层级的抽象工厂,根据不同的“产品需求”去生产定制的实例。
四、工厂类模式的不足
1、工厂模式相对于直接生成实例过程要复杂一些,所以,在小项目中,可以不使用工厂模式;
2、抽象工厂模式中,产品类的扩展比较麻烦。毕竟,每一个工厂对应每一类产品,产品扩展,就意味着相应的抽象工厂也要扩展
3 建造者模式
一、快餐点餐系统
今天的例子,还是上一次谈到的快餐点餐系统。只不过,今天我们从订单的角度来构造这个系统。最先还是有请上次的主角们: 主餐:
class Burger():
name=""
price=0.0
def getPrice(self):
return self.price
def setPrice(self,price):
self.price=price
def getName(self):
return self.name
class cheeseBurger(Burger):
def __init__(self):
self.name="cheese burger"
self.price=10.0
class spicyChickenBurger(Burger):
def __init__(self):
self.name="spicy chicken burger"
self.price=15.0
小食:
class Snack():
name = ""
price = 0.0
type = "SNACK"
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class chips(Snack):
def __init__(self):
self.name = "chips"
self.price = 6.0
class chickenWings(Snack):
def __init__(self):
self.name = "chicken wings"
self.price = 12.0
饮料:
class Beverage():
name = ""
price = 0.0
type = "BEVERAGE"
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class coke(Beverage):
def __init__(self):
self.name = "coke"
self.price = 4.0
class milk(Beverage):
def __init__(self):
self.name = "milk"
self.price = 5.0
最终,我们是要建造一个订单,因而,需要一个订单类。假设,一个订单,包括一份主食,一份小食,一种饮料。(省去一些异常判断)
class order():
burger=""
snack=""
beverage=""
def __init__(self,orderBuilder):
self.burger=orderBuilder.bBurger
self.snack=orderBuilder.bSnack
self.beverage=orderBuilder.bBeverage
def show(self):
print "Burger:%s"%self.burger.getName()
print "Snack:%s"%self.snack.getName()
print "Beverage:%s"%self.beverage.getName()
代码中的orderBuilder是什么鬼?这个orderBuilder就是建造者模式中所谓的“建造者”了,先不要问为什么不在order类中把所有内容都填上,而非要用builder去创建。接着往下看。 orderBuilder的实现如下 :
class orderBuilder():
bBurger=""
bSnack=""
bBeverage=""
def addBurger(self,xBurger):
self.bBurger=xBurger
def addSnack(self,xSnack):
self.bSnack=xSnack
def addBeverage(self,xBeverage):
self.bBeverage=xBeverage
def build(self):
return order(self)
在场景中如下去实现订单的生成:
if __name__=="__main__":
order_builder=orderBuilder()
order_builder.addBurger(spicyChickenBurger())
order_builder.addSnack(chips())
order_builder.addBeverage(milk())
order_1=order_builder.build()
order_1.show()
打印结果如下:Burger:spicy chicken burgerSnack:chipsBeverage:milk
二、建造者模式
建造者模式的定义如下:将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示。建造者模式的作用,就是将“构建”和“表示”分离,以达到解耦的作用。在上面订单的构建过程中,如果将order直接通过参数定义好(其构建与表示没有分离),同时在多处进行订单生成,此时需要修改订单内容,则需要一处处去修改,业务风险也就提高了不少。在建造者模式中,还可以加一个Director类,用以安排已有模块的构造步骤。对于在建造者中有比较严格的顺序要求时,该类会有比较大的用处。在上述例子中,Director实现如下:
class orderDirector():
order_builder=""
def __init__(self,order_builder):
self.order_builder=order_builder
def createOrder(self,burger,snack,beverage):
self.order_builder.addBurger(burger)
self.order_builder.addSnack(snack)
self.order_builder.addBeverage(beverage)
return self.order_builder.build()
通过createOrder直接代入参数,即可直接生成订单。

三、建造者模式的优点和使用场景
优点:
1、封装性好,用户可以不知道对象的内部构造和细节,就可以直接建造对象;2、系统扩展容易;3、建造者模式易于使用,非常灵活。在构造性的场景中很容易实现“流水线”;4、便于控制细节。
使用场景:
1、目标对象由组件构成的场景中,很适合建造者模式。例如,在一款赛车游戏中,车辆生成时,需要根据级别、环境等,选择轮胎、悬挂、骨架等部件,构造一辆“赛车”;2、在具体的场景中,对象内部接口需要根据不同的参数而调用顺序有所不同时,可以使用建造者模式。例如:一个植物养殖器系统,对于某些不同的植物,浇水、施加肥料的顺序要求可能会不同,因而可以在Director中维护一个类似于队列的结构,在实例化时作为参数代入到具体建造者中。
四、建造者模式的缺点
1、“加工工艺”对用户不透明。(封装的两面性)
4 原型模式
一、图层
大家如果用过类似于Photoshop的平面设计软件,一定都知道图层的概念。图层概念的提出,使得设计、图形修改等操作更加便利。设计师既可以修改和绘制当前图像对象,又可以保留其它图像对象,逻辑清晰,且可以及时得到反馈。本节内容,将以图层为主角,介绍原型模式。首先,设计一个图层对象。
class simpleLayer:
background=[0,0,0,0]
content="blank"
def getContent(self):
return self.content
def getBackgroud(self):
return self.background
def paint(self,painting):
self.content=painting
def setParent(self,p):
self.background[3]=p
def fillBackground(self,back):
self.background=back
在实际的实现中,图层实现会很复杂,这里仅介绍相关的设计模式,做了比较大的抽象,用background表示背景的RGBA,简单用content表示内容,除了直接绘画,还可以设置透明度。新建图层,填充蓝底并画一只狗,可以简单表示如下:
if __name__=="__main__":
dog_layer=simpleLayer()
dog_layer.paint("Dog")
dog_layer.fillBackground([0,0,255,0])
print "Background:",dog_layer.getBackgroud()
print "Painting:",dog_layer.getContent()
**打印如下:**Background: [0, 0, 255, 0]Painting: Dog
接下来,如果需要再生成一个同样的图层,再填充同样的颜色,再画一只同样狗,该如何做呢?还是按照新建图层、填充背景、画的顺序么?或许你已经发现了,这里可以用复制的方法来实现,而复制(clone)这个动作,就是原型模式的精髓了。按照此思路,在图层类中新加入两个方法:clone和deep_clone
from copy import copy, deepcopy
class simpleLayer:
background=[0,0,0,0]
content="blank"
def getContent(self):
return self.content
def getBackgroud(self):
return self.background
def paint(self,painting):
self.content=painting
def setParent(self,p):
self.background[3]=p
def fillBackground(self,back):
self.background=back
def clone(self):
return copy(self)
def deep_clone(self):
return deepcopy(self)
if __name__=="__main__":
dog_layer=simpleLayer()
dog_layer.paint("Dog")
dog_layer.fillBackground([0,0,255,0])
print "Background:",dog_layer.getBackgroud()
print "Painting:",dog_layer.getContent()
another_dog_layer=dog_layer.clone()
print "Background:", another_dog_layer.getBackgroud()
print "Painting:", another_dog_layer.getContent()
打印结果如下:Background: [0, 0, 255, 0]Painting: DogBackground: [0, 0, 255, 0]Painting: Dog
clone和deep_clone有什么区别呢?大多数编程语言中,都会涉及到深拷贝和浅拷贝的问题,一般来说,浅拷贝会拷贝对象内容及其内容的引用或者子对象的引用,但不会拷贝引用的内容和子对象本身;而深拷贝不仅拷贝了对象和内容的引用,也会拷贝引用的内容。所以,一般深拷贝比浅拷贝复制得更加完全,但也更占资源(包括时间和空间资源)。举个例子,下面的场景,可以说明深拷贝和浅拷贝的区别。
if __name__=="__main__":
dog_layer=simpleLayer()
dog_layer.paint("Dog")
dog_layer.fillBackground([0,0,255,0])
print "Original Background:",dog_layer.getBackgroud()
print "Original Painting:",dog_layer.getContent()
another_dog_layer=dog_layer.clone()
another_dog_layer.setParent(128)
another_dog_layer.paint("Puppy")
print "Original Background:", dog_layer.getBackgroud()
print "Original Painting:", dog_layer.getContent()
print "Copy Background:", another_dog_layer.getBackgroud()
print "Copy Painting:", another_dog_layer.getContent()
**打印如下:**Original Background: [0, 0, 255, 0]Original Painting: DogOriginal Background: [0, 0, 255, 128]Original Painting: DogCopy Background: [0, 0, 255, 128]Copy Painting: Puppy
浅拷贝后,直接对拷贝后引用(这里的数组)进行操作,原始对象中该引用的内容也会变动。如果将another_dog_layer=dog_layer.clone()换成another_dog_layer=dog_layer.deep_clone(),即把浅拷贝换成深拷贝,其如果如下:
Original Background: [0, 0, 255, 0]Original Painting: DogOriginal Background: [0, 0, 255, 0]Original Painting: DogCopy Background: [0, 0, 255, 128]Copy Painting: Puppy
深拷贝后,其对象内的引用内容也被进行了复制。
二、原型模式
原型模式定义如下:用原型实例指定创建对象的种类,并且通过复制这些原型创建新的对象。需要注意一点的是,进行clone操作后,新对象的构造函数没有被二次执行,新对象的内容是从内存里直接拷贝的。

三、原型模式的优点和使用场景
优点:
1、性能极佳,直接拷贝比在内存里直接新建实例节省不少的资源;2、简化对象创建,同时避免了构造函数的约束,不受构造函数的限制直接复制对象,是优点,也有隐患,这一点还是需要多留意一些。
使用场景:
1、对象在修改过后,需要复制多份的场景。如本例和其它一些涉及到复制、粘贴的场景;2、需要优化资源的情况。如,需要在内存中创建非常多的实例,可以通过原型模式来减少资源消耗。此时,原型模式与工厂模式配合起来,不管在逻辑上还是结构上,都会达到不错的效果;3、某些重复性的复杂工作不需要多次进行。如对于一个设备的访问权限,多个对象不用各申请一遍权限,由一个设备申请后,通过原型模式将权限交给可信赖的对象,既可以提升效率,又可以节约资源。
四、原型模式的缺点
1、深拷贝和浅拷贝的使用需要事先考虑周到;2、某些编程语言中,拷贝会影响到静态变量和静态函数的使用。
5 代理模式
一、网络服务器配置白名单
代理模式是一种使用频率非常高的模式,在多个著名的开源软件和当前多个著名的互联网产品后台程序中都有所应用。下面我们用一个抽象化的简单例子,来说明代理模式。首先,构造一个网络服务器:
info_struct=dict()
info_struct["addr"]=10000
info_struct["content"]=""
class Server:
content=""
def recv(self,info):
pass
def send(self,info):
pass
def show(self):
pass
class infoServer(Server):
def recv(self,info):
self.content=info
return "recv OK!"
def send(self,info):
pass
def show(self):
print "SHOW:%s"%self.content
infoServer有接收和发送的功能,发送功能由于暂时用不到,保留。另外新加一个接口show,用来展示服务器接收的内容。接收的数据格式必须如info_struct所示,服务器仅接受info_struct的content字段。那么,如何给这个服务器设置一个白名单,使得只有白名单里的地址可以访问服务器呢?修改Server结构是个方法,但这显然不符合软件设计原则中的单一职责原则。在此基础之上,使用代理,是个不错的方法。代理配置如下:
class serverProxy:
pass
class infoServerProxy(serverProxy):
server=""
def __init__(self,server):
self.server=server
def recv(self,info):
return self.server.recv(info)
def show(self):
self.server.show()
class whiteInfoServerProxy(infoServerProxy):
white_list=[]
def recv(self,info):
try:
assert type(info)==dict
except:
return "info structure is not correct"
addr=info.get("addr",0)
if not addr in self.white_list:
return "Your address is not in the white list."
else:
content=info.get("content","")
return self.server.recv(content)
def addWhite(self,addr):
self.white_list.append(addr)
def rmvWhite(self,addr):
self.white_list.remove(addr)
def clearWhite(self):
self.white_list=[]
代理中有一个server字段,控制代理的服务器对象,infoServerProxy充当Server的直接接口代理,而whiteInfoServerProxy直接继承了infoServerProxy对象,同时加入了white_list和对白名单的操作。这样,在场景中通过对白名单代理的访问,就可以实现服务器的白名单访问了。
if __name__=="__main__":
info_struct = dict()
info_struct["addr"] = 10010
info_struct["content"] = "Hello World!"
info_server = infoServer()
info_server_proxy = whiteInfoServerProxy(info_server)
print info_server_proxy.recv(info_struct)
info_server_proxy.show()
info_server_proxy.addWhite(10010)
print info_server_proxy.recv(info_struct)
info_server_proxy.show()
打印如下:
Your address is not in the white list.SHOW:recv OK!SHOW:Hello World!
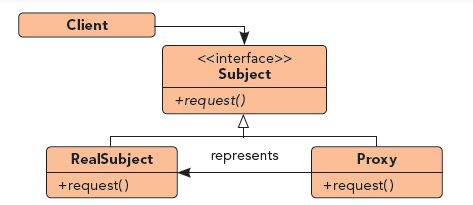
二、代理模式
代理模式定义如下:为某对象提供一个代理,以控制对此对象的访问和控制。代理模式在使用过程中,应尽量对抽象主题类进行代理,而尽量不要对加过修饰和方法的子类代理。如上例中,如果有一个xServer继承了Server,并新加了方法xMethod,xServer的代理应以Server为主题进行设计,而尽量不要以xServer为主题,以xServer为主题的代理可以从ServerProxy继承并添加对应的方法。
在JAVA中,讲到代理模式,不得不会提到动态代理。动态代理是实现AOP(面向切面编程)的重要实现手段。而在Python中,很少会提到动态代理,而AOP则会以另一种模式实现:装饰模式。有关AOP的相关内容,我们会在装饰模式这一节中进行说明。
三、代理模式的优点和应用场景
优点:
1、职责清晰:非常符合单一职责原则,主题对象实现真实业务逻辑,而非本职责的事务,交由代理完成;2、扩展性强:面对主题对象可能会有的改变,代理模式在不改变对外接口的情况下,可以实现最大程度的扩展;3、保证主题对象的处理逻辑:代理可以通过检查参数的方式,保证主题对象的处理逻辑输入在理想范围内。
应用场景:
1、针对某特定对象进行功能和增强性扩展。如IP防火墙、远程访问代理等技术的应用;2、对主题对象进行保护。如大流量代理,安全代理等;3、减轻主题对象负载。如权限代理等。
四、代理模式的缺点
1、可能会降低整体业务的处理效率和速度。
6 装饰器模式
一、快餐点餐系统
又提到了那个快餐点餐系统,不过今天我们只以其中的一个类作为主角:饮料类。首先,回忆下饮料类:
class Beverage():
name = ""
price = 0.0
type = "BEVERAGE"
def getPrice(self):
return self.price
def setPrice(self, price):
self.price = price
def getName(self):
return self.name
class coke(Beverage):
def __init__(self):
self.name = "coke"
self.price = 4.0
class milk(Beverage):
def __init__(self):
self.name = "milk"
self.price = 5.0
除了基本配置,快餐店卖可乐时,可以选择加冰,如果加冰的话,要在原价上加0.3元;卖牛奶时,可以选择加糖,如果加糖的话,要原价上加0.5元。怎么解决这样的问题?可以选择装饰器模式来解决这一类的问题。首先,定义装饰器类:
class drinkDecorator():
def getName(self):
pass
def getPrice(self):
pass
class iceDecorator(drinkDecorator):
def __init__(self,beverage):
self.beverage=beverage
def getName(self):
return self.beverage.getName()+" +ice"
def getPrice(self):
return self.beverage.getPrice()+0.3
class sugarDecorator(drinkDecorator):
def __init__(self,beverage):
self.beverage=beverage
def getName(self):
return self.beverage.getName()+" +sugar"
def getPrice(self):
return self.beverage.getPrice()+0.5
构建好装饰器后,在具体的业务场景中,就可以与饮料类进行关联。以可乐+冰为例,示例业务场景如下:
if __name__=="__main__":
coke_cola=coke()
print "Name:%s"%coke_cola.getName()
print "Price:%s"%coke_cola.getPrice()
ice_coke=iceDecorator(coke_cola)
print "Name:%s" % ice_coke.getName()
print "Price:%s" % ice_coke.getPrice()
打印结果如下:
Name:cokePrice:4.0Name:coke +icePrice:4.3
二、装饰器模式
装饰器模式定义如下:动态地给一个对象添加一些额外的职责。在增加功能方面,装饰器模式比生成子类更为灵活。
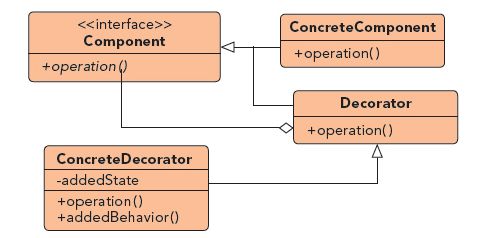
装饰器模式和上一节说到的代理模式非常相似,可以认为,装饰器模式就是代理模式的一个特殊应用,两者的共同点是都具有相同的接口,不同点是侧重对主题类的过程的控制,而装饰模式则侧重对类功能的加强或减弱。上一次说到,JAVA中的动态代理模式,是实现AOP的重要手段。而在Python中,AOP通过装饰器模式实现更为简洁和方便。先来解释一下什么是AOP。AOP即Aspect
Oriented
Programming,中文翻译为面向切面的编程,它的含义可以解释为:如果几个或更多个逻辑过程中(这类逻辑过程可能位于不同的对象,不同的接口当中),有重复的操作行为,就可以将这些行为提取出来(即形成切面),进行统一管理和维护。举例子说,系统中需要在各个地方打印日志,就可以将打印日志这一操作提取出来,作为切面进行统一维护。从编程思想的关系来看,可以认为AOP和OOP(面向对象的编程)是并列关系,二者是可以替换的,也可以结合起来用。实际上,在Python语言中,是天然支持装饰器的,如下例:
def log(func):
def wrapper(*args, **kw):
print 'call %s():' % func.__name__
return func(*args, **kw)
return wrapper
@log
def now():
print '2016-12-04'
if __name__=="__main__":
now()
打印如下:
call now():2016-12-04
log接口就是装饰器的定义,而Python的@语法部分则直接支持装饰器的使用。如果要在快餐点餐系统中打印日志,该如何进行AOP改造呢?可以借助类的静态方法或者类方法来实现:
class LogManager:
@staticmethod
def log(func):
def wrapper(*args):
print "Visit Func %s"%func.__name__
return func(*args)
return wrapper
在需要打印日志的地方直接@LogManager.log,即可打印出访问的日志信息。如,在beverage类的函数前加上@LogManager.log,场景类保持不变,则打印结果如下:
Visit Func getNameName:cokeVisit Func getPricePrice:4.0Visit Func getNameName:coke +iceVisit Func getPricePrice:4.3
三、装饰器模式的优点和应用场景
优点:
1、装饰器模式是继承方式的一个替代方案,可以轻量级的扩展被装饰对象的功能;2、Python的装饰器模式是实现AOP的一种方式,便于相同操作位于不同调用位置的统一管理。
应用场景:
1、需要扩展、增强或者减弱一个类的功能,如本例。
四、装饰器模式的缺点
1、多层装饰器的调试和维护有比较大的困难。
7 适配器模式
一、外包人员系统兼容
假设某公司A与某公司B需要合作,公司A需要访问公司B的人员信息,但公司A与公司B协议接口不同,该如何处理?先将公司A和公司B针对各自的人员信息访问系统封装了对象接口。
class ACpnStaff:
name=""
id=""
phone=""
def __init__(self,id):
self.id=id
def getName(self):
print "A protocol getName method...id:%s"%self.id
return self.name
def setName(self,name):
print "A protocol setName method...id:%s"%self.id
self.name=name
def getPhone(self):
print "A protocol getPhone method...id:%s"%self.id
return self.phone
def setPhone(self,phone):
print "A protocol setPhone method...id:%s"%self.id
self.phone=phone
class BCpnStaff:
name=""
id=""
telephone=""
def __init__(self,id):
self.id=id
def get_name(self):
print "B protocol get_name method...id:%s"%self.id
return self.name
def set_name(self,name):
print "B protocol set_name method...id:%s"%self.id
self.name=name
def get_telephone(self):
print "B protocol get_telephone method...id:%s"%self.id
return self.telephone
def set_telephone(self,telephone):
print "B protocol get_name method...id:%s"%self.id
self.telephone=telephone
为在A公司平台复用B公司接口,直接调用B公司人员接口是个办法,但会对现在业务流程造成不确定的风险。为减少耦合,规避风险,我们需要一个帮手,就像是转换电器电压的适配器一样,这个帮手就是协议和接口转换的适配器。适配器构造如下:
class CpnStaffAdapter:
b_cpn=""
def __init__(self,id):
self.b_cpn=BCpnStaff(id)
def getName(self):
return self.b_cpn.get_name()
def getPhone(self):
return self.b_cpn.get_telephone()
def setName(self,name):
self.b_cpn.set_name(name)
def setPhone(self,phone):
self.b_cpn.set_telephone(phone)
适配器将B公司人员接口封装,而对外接口形式与A公司人员接口一致,达到用A公司人员接口访问B公司人员信息的效果。业务示例如下:
if __name__=="__main__":
acpn_staff=ACpnStaff("123")
acpn_staff.setName("X-A")
acpn_staff.setPhone("10012345678")
print "A Staff Name:%s"%acpn_staff.getName()
print "A Staff Phone:%s"%acpn_staff.getPhone()
bcpn_staff=CpnStaffAdapter("456")
bcpn_staff.setName("Y-B")
bcpn_staff.setPhone("99987654321")
print "B Staff Name:%s"%bcpn_staff.getName()
print "B Staff Phone:%s"%bcpn_staff.getPhone()
打印如下:
A protocol setName method…id:123A protocol setPhone method…id:123A protocol getName method…id:123A Staff Name:X-AA protocol getPhone method…id:123A Staff Phone:10012345678B protocol set_name method…id:456B protocol get_name method…id:456B protocol get_name method…id:456B Staff Name:Y-BB protocol get_telephone method…id:456B Staff Phone:99987654321
二、适配器模式
适配器模式定义如下:将一个类的接口变换成客户端期待的另一种接口,从而使原本因接口不匹配而无法在一起工作的两个类能够在一起工作。适配器模式和装饰模式有一定的相似性,都起包装的作用,但二者本质上又是不同的,装饰模式的结果,是给一个对象增加了一些额外的职责,而适配器模式,则是将另一个对象进行了“伪装”。

适配器可以认为是对现在业务的补偿式应用,所以,尽量不要在设计阶段使用适配器模式,在两个系统需要兼容时可以考虑使用适配器模式。
三、适配器模式的优点和使用场景
优点:
1、适配器模式可以让两个接口不同,甚至关系不大的两个类一起运行;2、提高了类的复用度,经过“伪装”的类,可以充当新的角色;3、适配器可以灵活“拆卸”。
应用场景:
1、不修改现有接口,同时也要使该接口适用或兼容新场景业务中,适合使用适配器模式。例如,在一个嵌入式系统中,原本要将数据从Flash读入,现在需要将数据从磁盘读入,这种情况可以使用适配器模式,将从磁盘读入数据的接口进行“伪装”,以从Flash中读数据的接口形式,从磁盘读入数据。
四、适配器模式的缺点
1、适配器模式与原配接口相比,毕竟增加了一层调用关系,所以,在设计系统时,不要使用适配器模式。
8 门面模式
一、火警报警器(1)
假设有一组火警报警系统,由三个子元件构成:一个警报器,一个喷水器,一个自动拨打电话的装置。其抽象如下:
class AlarmSensor:
def run(self):
print "Alarm Ring..."
class WaterSprinker:
def run(self):
print "Spray Water..."
class EmergencyDialer:
def run(self):
print "Dial 119..."
在业务中如果需要将三个部件启动,例如,如果有一个烟雾传感器,检测到了烟雾。在业务环境中需要做如下操作:
if __name__=="__main__":
alarm_sensor=AlarmSensor()
water_sprinker=WaterSprinker()
emergency_dialer=EmergencyDialer()
alarm_sensor.run()
water_sprinker.run()
emergency_dialer.run()
但如果在多个业务场景中需要启动三个部件,怎么办?Ctrl+C加上Ctrl+V么?当然可以这样,但作为码农的基本修养之一,减少重复代码是应该会被很轻易想到的方法。这样,需要将其进行封装,在设计模式中,被封装成的新对象,叫做门面。门面构建如下:
class EmergencyFacade:
def __init__(self):
self.alarm_sensor=AlarmSensor()
self.water_sprinker=WaterSprinker()
self.emergency_dialer=EmergencyDialer()
def runAll(self):
self.alarm_sensor.run()
self.water_sprinker.run()
self.emergency_dialer.run()
这样,业务场景中这样写就可以了:
if __name__=="__main__":
emergency_facade=EmergencyFacade()
emergency_facade.runAll()
打印如下:
Alarm Ring…Spray Water…Dial 119…
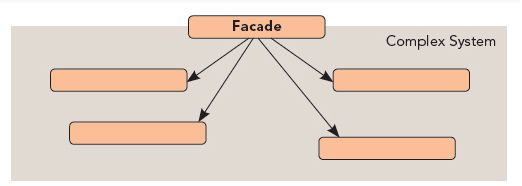
二、门面模式
门面模式也叫外观模式,定义如下:要求一个子系统的外部与其内部的通信必须通过一个统一的对象进行。门面模式提供一个高层次的接口,使得子系统更易于使用。门面模式注重“统一的对象”,也就是提供一个访问子系统的接口。门面模式与之前说过的模板模式有类似的地方,都是对一些需要重复方法的封装。但从本质上来说,是不同的。模板模式是对类本身的方法的封装,其被封装的方法也可以单独使用;而门面模式,是对子系统的封装,其被封装的接口理论上是不会被单独提出来用的。
三、门面模式的优点和使用场景
优点:
1、减少了系统之间的相互依赖,提高了系统的灵活;2、提高了整体系统的安全性:封装起的系统对外的接口才可以用,隐藏了很多内部接口细节,若方法不允许使用,则在门面中可以进行灵活控制。
使用场景:
1、为一个复杂的子系统提供一个外界访问的接口。这类例子是生活还是蛮常见的,例如电视遥控器的抽象模型,电信运营商的用户交互设备等;2、需要简化操作界面时。例如常见的扁平化系统操作界面等,在生活中和工业中都很常见。
四、门面模式的缺点
1、门面模式的缺点在于,不符合开闭原则,一旦系统成形后需要修改,几乎只能重写门面代码,这比继承或者覆写等方式,或者其它一些符合开闭原则的模式风险都会大一些。
9 组合模式
一、公司结构组织
每一个公司都有自己的组织结构,越是大型的企业,其组织结构就会越复杂。大多数情况下,公司喜欢用“树形”结构来组织复杂的公司人事关系和公司间的结构关系。一般情况下,根结点代表公司的最高行政权利单位,分支节点表示一个个部门,而叶子结点则会用来代表每一个员工。每一个结点的子树,表示该结点代表的部门所管理的单位。假设一个具有HR部门,财务部门和研发部门,同时在全国有分支公司的总公司,其公司结构,可以表示成如下逻辑:
class Company:
name = ''
def __init__(self, name):
self.name = name
def add(self, company):
pass
def remove(self, company):
pass
def display(self, depth):
pass
def listDuty(self):
pass
class ConcreteCompany(Company):
childrenCompany = None
def __init__(self, name):
Company.__init__(self,name)
self.childrenCompany = []
def add(self, company):
self.childrenCompany.append(company)
def remove(self, company):
self.childrenCompany.remove(company)
def display(self, depth):
print'-'*depth + self.name
for component in self.childrenCompany:
component.display(depth+1)
def listDuty(self):
for component in self.childrenCompany:
component.listDuty()
class HRDepartment(Company):
def __init__(self, name):
Company.__init__(self,name)
def display(self, depth):
print '-'*depth + self.name
def listDuty(self):
print '%s\t Enrolling & Transfering management.' % self.name
class FinanceDepartment(Company):
def __init__(self, name):
Company.__init__(self,name)
def display(self, depth):
print "-" * depth + self.name
def listDuty(self):
print '%s\tFinance Management.'%self.name
class RdDepartment(Company):
def __init__(self,name):
Company.__init__(self,name)
def display(self, depth):
print "-"*depth+self.name
def listDuty(self):
print "%s\tResearch & Development."% self.name
在该例中,公司结构抽象仅考虑公司(ConcreteCompany)和部门(Department),公司有子公司的可能性,公司也有自己的部门,部门是最终的叶子结点。 假设总公司下设东边的分公司一个,东边的分公司下设东北公司和东南公司,显示公司层级,并罗列这些的公司中各部门的职责,可以构建如下业务场景:
if __name__=="__main__":
root = ConcreteCompany('HeadQuarter')
root.add(HRDepartment('HQ HR'))
root.add(FinanceDepartment('HQ Finance'))
root.add(RdDepartment("HQ R&D"))
comp = ConcreteCompany('East Branch')
comp.add(HRDepartment('East.Br HR'))
comp.add(FinanceDepartment('East.Br Finance'))
comp.add(RdDepartment("East.Br R&D"))
root.add(comp)
comp1 = ConcreteCompany('Northast Branch')
comp1.add(HRDepartment('Northeast.Br HR'))
comp1.add(FinanceDepartment('Northeast.Br Finance'))
comp1.add(RdDepartment("Northeast.Br R&D"))
comp.add(comp1)
comp2 = ConcreteCompany('Southeast Branch')
comp2.add(HRDepartment('Southeast.Br HR'))
comp2.add(FinanceDepartment('Southeast.Br Finance'))
comp2.add(RdDepartment("Southeast.Br R&D"))
comp.add(comp2)
root.display(1)
root.listDuty()
打印如下:
-HeadQuarter–HQ HR–HQ Finance–HQ R&D–East Branch—East.Br HR—East.Br Finance—East.Br R&D—Northast Branch----Northeast.Br HR----Northeast.Br Finance----Northeast.Br R&D—Southeast Branch----Southeast.Br HR----Southeast.Br Finance----Southeast.Br R&DHQ HR Enrolling & Transfering management.HQ Finance Finance Management.HQ R&D Research & Development.East.Br HR Enrolling & Transfering management.East.Br Finance Finance Management.East.Br R&D Research & Development.Northeast.Br HR Enrolling & Transfering management.Northeast.Br Finance Finance Management.Northeast.Br R&D Research & Development.Southeast.Br HR Enrolling & Transfering management.Southeast.Br Finance Finance Management.Southeast.Br R&D Research & Development.
二、组合模式
组合模式也叫作部分-整体模式,其定义如下:将对象组合成树形结构以表示“部分”和“整体”的层次结构,使得用户对单个对象和组合对象的使用具有一致性。

三、组合模式的优点和使用场景
优点:
1、节点增加和减少是非常自由和方便的,这也是树形结构的一大特点;2、所有节点,不管是分支节点还是叶子结点,不管是调用一个结点,还是调用一个结点群,都是非常方便的。
使用场景:
1、维护部分与整体的逻辑关系,或者动态调用整体或部分的功能接口,可以考虑使用组合模式。例如,非常多的操作系统(如Linux)都把文件系统设计成树形结构,再比如说分布式应用中借助Zookeeper,也可以组织和调用分布式集群中的结点功能。
四、组合模式的缺点
1、由于叶子结点和分支结点直接使用了实现类,而不方便使用抽象类,这大大限制了接口的影响范围;若结点接口发生变更,对系统造成的风险会比较大。
10 享元模式
一、网上咖啡选购平台
假设有一个网上咖啡选购平台,客户可以在该平台上下订单订购咖啡,平台会根据用户位置进行线下配送。假设其咖啡对象构造如下:
class Coffee:
name = ''
price =0
def __init__(self,name):
self.name = name
self.price = len(name)
def show(self):
print "Coffee Name:%s Price:%s"%(self.name,self.price)
其对应的顾客类如下:
class Customer:
name=""
def __init__(self,name):
self.name=name
def order(self,coffee_name):
print "%s ordered a cup of coffee:%s"%(self.name,coffee_name)
return Coffee(coffee_name)
按照一般的处理流程,用户在网上预订咖啡,其代表用户的Customer类中生成一个Coffee类,直到交易流程结束。整个流程是没有问题的。如果,随着网站用户越来越多,单位时间内购买咖啡的用户也越来越多,并发量越来越大,对系统资源的消耗也会越来越大,极端情况下,会造成宕机等严重后果。此时,高效利用资源,就显得非常重要了。简单分析下业务流程,高并发下用户数量增加,而该模型下,每个用户点一杯咖啡,就会产生一个咖啡实例,如果一种咖啡在该时间内被很多用户点过,那么就会产生很多同样咖啡的实例。避免重复实例的出现,是节约系统资源的一个突破口。类似于单例模式,我们这里在咖啡实例化前,增加一个控制实例化的类:咖啡工厂。
class CoffeeFactory():
coffee_dict = {}
def getCoffee(self, name):
if self.coffee_dict.has_key(name) == False:
self.coffee_dict[name] = Coffee(name)
return self.coffee_dict[name]
def getCoffeeCount(self):
return len(self.coffee_dict)
咖啡工厂中,getCoffeeCount直接返回当前实例个数。Customer类可以重写下,如下:
class Customer:
coffee_factory=""
name=""
def __init__(self,name,coffee_factory):
self.name=name
self.coffee_factory=coffee_factory
def order(self,coffee_name):
print "%s ordered a cup of coffee:%s"%(self.name,coffee_name)
return self.coffee_factory.getCoffee(coffee_name)
假设业务中短时间内有多人订了咖啡,业务模拟如下:
if __name__=="__main__":
coffee_factory=CoffeeFactory()
customer_1=Customer("A Client",coffee_factory)
customer_2=Customer("B Client",coffee_factory)
customer_3=Customer("C Client",coffee_factory)
c1_capp=customer_1.order("cappuccino")
c1_capp.show()
c2_mocha=customer_2.order("mocha")
c2_mocha.show()
c3_capp=customer_3.order("cappuccino")
c3_capp.show()
print "Num of Coffee Instance:%s"%coffee_factory.getCoffeeCount()
打印如下:
A Client ordered a cup of coffee:cappuccinoCoffee Name:cappuccino Price:10B Client ordered a cup of coffee:mochaCoffee Name:mocha Price:5C Client ordered a cup of coffee:cappuccinoCoffee Name:cappuccino Price:10Num of Coffee Instance:2
根据结果可以得知,该模式下三个用户点了两种咖啡,最终的咖啡实例为2,而不是3。
二、享元模式
享元模式定义如下:使用共享对象支持大量细粒度对象。大量细粒度的对象的支持共享,可能会涉及这些对象的两类信息:内部状态信息和外部状态信息。内部状态信息就是可共享出来的信息,它们存储在享元对象内部,不会随着特定环境的改变而改变;外部状态信息就不可共享的信息了。享元模式中只包含内部状态信息,而不应该包含外部状态信息。这点在设计业务架构时,应该有所考虑。
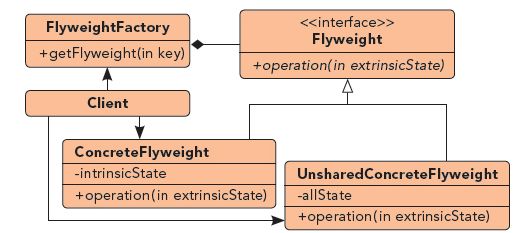
三、享元模式的优点和使用场景
优点:
1、减少重复对象,大大节约了系统资源。
使用场景:
1、系统中存在大量的相似对象时,可以选择享元模式提高资源利用率。咖啡订购平台比较小,若假设一个电商平台,每个买家和卖家建立起买卖关系后,买家对象和卖家对象都是占用资源的。如果一个卖家同时与多个买家建立起买卖关系呢?此时享元模式的优势就体现出来了;2、需要缓冲池的场景中,可以使用享元模式。如进程池,线程池等技术,就可以使用享元模式(事实上,很多的池技术中已经使得了享元模式)。
四、享元模式的缺点
1、享元模式虽然节约了系统资源,但同时也提高了系统的复杂性,尤其当遇到外部状态和内部状态混在一起时,需要先将其进行分离,才可以使用享元模式。否则,会引起逻辑混乱或业务风险;2、享元模式中需要额外注意线程安全问题。
11 桥梁模式
一、画笔与形状
在介绍原型模式的一节中,我们举了个图层的例子,这一小节内容,我们同样以类似画图的例子,说明一种结构类设计模式:桥梁模式。在一个画图程序中,常会见到这样的情况:有一些预设的图形,如矩形、圆形等,还有一个对象-画笔,调节画笔的类型(如画笔还是画刷,还是毛笔效果等)并设定参数(如颜色、线宽等),选定图形,就可以在画布上画出想要的图形了。要实现以上需求,先从最抽象的元素开始设计,即形状和画笔(暂时忽略画布,同时忽略画笔参数,只考虑画笔类型)。
class Shape:
name=""
param=""
def __init__(self,*param):
pass
def getName(self):
return self.name
def getParam(self):
return self.name,self.param
class Pen:
shape=""
type=""
def __init__(self,shape):
self.shape=shape
def draw(self):
pass
形状对象和画笔对象是最为抽象的形式。接下来,构造多个形状,如矩形和圆形:
class Rectangle(Shape):
def __init__(self,long,width):
self.name="Rectangle"
self.param="Long:%s Width:%s"%(long,width)
print "Create a rectangle:%s"%self.param
class Circle(Shape):
def __init__(self,radius):
self.name="Circle"
self.param="Radius:%s"%radius
print "Create a circle:%s"%self.param
紧接着是构造多种画笔,如普通画笔和画刷:
class NormalPen(Pen):
def __init__(self,shape):
Pen.__init__(self,shape)
self.type="Normal Line"
def draw(self):
print "DRAWING %s:%s----PARAMS:%s"%(self.type,self.shape.getName(),self.shape.getParam())
class BrushPen(Pen):
def __init__(self,shape):
Pen.__init__(self,shape)
self.type="Brush Line"
def draw(self):
print "DRAWING %s:%s----PARAMS:%s" % (self.type,self.shape.getName(), self.shape.getParam())
业务中的逻辑如下:
if __name__=="__main__":
normal_pen=NormalPen(Rectangle("20cm","10cm"))
brush_pen=BrushPen(Circle("15cm"))
normal_pen.draw()
brush_pen.draw()
打印如下:
Create a rectangle:Long:20cm Width:10cmCreate a circle:Radius:15cmDRAWING Normal Line:Rectangle----PARAMS:(‘Rectangle’, ‘Long:20cm Width10cm’)DRAWING Brush Line:Circle----PARAMS:(‘Circle’, ‘Radius:15cm’)
二、桥梁模式
桥梁模式又叫桥接模式,定义如下:将抽象与实现解耦(注意此处的抽象和实现,并非抽象类和实现类的那种关系,而是一种角色的关系,这里需要好好区分一下),可以使其独立变化。在形如上例中,Pen只负责画,但没有形状,它终究是不知道要画什么的,所以我们把它叫做抽象化角色;而Shape是具体的形状,我们把它叫做实现化角色。抽象化角色和实现化角色是解耦的,这也就意味着,所谓的桥,就是抽象化角色的抽象类和实现化角色的抽象类之间的引用关系。

三、桥梁模式的优点和应用场景
优点:
1、抽象角色与实现角色相分离,二者可以独立设计,不受约束;2、扩展性强:抽象角色和实现角色可以非常灵活地扩展。
应用场景:
1、不适用继承或者原继承关系中抽象类可能频繁变动的情况,可以将原类进行拆分,拆成实现化角色和抽象化角色。例如本例中,若将形状、粗细、绘画样式等属于汇集在一个类中,一旦抽象类中有所变动,将造成巨大的风险;2、重用性比较大的场景。比如开关控制逻辑的程序,开关就是抽象化角色,开关的形式有很多种,操作的实现化角色也有很多种,采用桥梁模式,(如当前例子)开关即可进行复用,整体会将设计的粒度减小。
四、桥梁模式的缺点
1、增加对系统理解的难度。
12 策略模式
一、客户消息通知
假设某司维护着一些客户资料,需要在该司有新产品上市或者举行新活动时通知客户。现通知客户的方式有两种:短信通知、邮件通知。应如何设计该系统的客户通知部分?为解决该问题,我们先构造客户类,包括客户常用的联系方式和基本信息,同时也包括要发送的内容。
class customer:
customer_name=""
snd_way=""
info=""
phone=""
email=""
def setPhone(self,phone):
self.phone=phone
def setEmail(self,mail):
self.email=mail
def getPhone(self):
return self.phone
def getEmail(self):
return self.email
def setInfo(self,info):
self.info=info
def setName(self,name):
self.customer_name=name
def setBrdWay(self,snd_way):
self.snd_way=snd_way
def sndMsg(self):
self.snd_way.send(self.info)
snd_way向客户发送信息的方式,该方式置为可设,即可根据业务来进行策略的选择。发送方式构建如下:
class msgSender:
dst_code=""
def setCode(self,code):
self.dst_code=code
def send(self,info):
pass
class emailSender(msgSender):
def send(self,info):
print "EMAIL_ADDRESS:%s EMAIL:%s"%(self.dst_code,info)
class textSender(msgSender):
def send(self,info):
print "TEXT_CODE:%s EMAIL:%s"%(self.dst_code,info)
在业务场景中将发送方式作为策略,根据需求进行发送。
if __name__=="__main__":
customer_x=customer()
customer_x.setName("CUSTOMER_X")
customer_x.setPhone("10023456789")
customer_x.setEmail("[email protected]")
customer_x.setInfo("Welcome to our new party!")
text_sender=textSender()
text_sender.setCode(customer_x.getPhone())
customer_x.setBrdWay(text_sender)
customer_x.sndMsg()
mail_sender=emailSender()
mail_sender.setCode(customer_x.getEmail())
customer_x.setBrdWay(mail_sender)
customer_x.sndMsg()
结果打印如下:
PHONE_NUMBER:10023456789 TEXT:Welcome to our new party!EMAIL_ADDRESS:[email protected][1] EMAIL:Welcome to our new party!
二、策略模式
策略模式定义如下:定义一组算法,将每个算法都封装起来,并使他们之间可互换。以上述例子为例,customer类扮演的角色(Context)直接依赖抽象策略的接口,在具体策略实现类中即可定义个性化的策略方式,且可以方便替换。
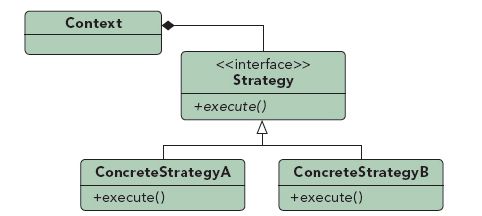
上一节中我们介绍了桥接模式,仔细比较一下桥接模式和策略模式,如果把策略模式的Context设计成抽象类和实现类的方式,那么策略模式和桥接模式就可以划等号了。从类图看上去,桥接模式比策略模式多了对一种角色(抽象角色)的抽象。二者结构的高度同构,也只能让我们从使用意图上去区分两种模式:桥接模式解决抽象角色和实现角色都可以扩展的问题;而策略模式解决算法切换和扩展的问题。
三、策略模式的优点和应用场景
优点:
1、各个策略可以自由切换:这也是依赖抽象类设计接口的好处之一;2、减少代码冗余;3、扩展性优秀,移植方便,使用灵活。
应用场景:
1、算法策略比较经常地需要被替换时,可以使用策略模式。如现在超市前台,会常遇到刷卡、某宝支付、某信支付等方式,就可以参考策略模式。
四、策略模式的缺点
1、项目比较庞大时,策略可能比较多,不便于维护;2、策略的使用方必须知道有哪些策略,才能决定使用哪一个策略,这与迪米特法则是相违背的。
13 责任链模式
一、请假系统
假设有这么一个请假系统:员工若想要请3天以内(包括3天的假),只需要直属经理批准就可以了;如果想请3-7天,不仅需要直属经理批准,部门经理需要最终批准;如果请假大于7天,不光要前两个经理批准,也需要总经理最终批准。类似的系统相信大家都遇到过,那么该如何实现呢?首先想到的当然是if…else…,但一旦遇到需求变动,其臃肿的代码和复杂的耦合缺点都显现出来。简单分析下需求,“假条”在三个经理间是单向传递关系,像一条链条一样,因而,我们可以用一条“链”把他们进行有序连接。构造抽象经理类和各个层级的经理类:
class manager():
successor = None
name = ''
def __init__(self, name):
self.name = name
def setSuccessor(self, successor):
self.successor = successor
def handleRequest(self, request):
pass
class lineManager(manager):
def handleRequest(self, request):
if request.requestType == 'DaysOff' and request.number <= 3:
print '%s:%s Num:%d Accepted OVER' % (self.name, request.requestContent, request.number)
else:
print '%s:%s Num:%d Accepted CONTINUE' % (self.name, request.requestContent, request.number)
if self.successor != None:
self.successor.handleRequest(request)
class departmentManager(manager):
def handleRequest(self, request):
if request.requestType == 'DaysOff' and request.number <= 7:
print '%s:%s Num:%d Accepted OVER' % (self.name, request.requestContent, request.number)
else:
print '%s:%s Num:%d Accepted CONTINUE' % (self.name, request.requestContent, request.number)
if self.successor != None:
self.successor.handleRequest(request)
class generalManager(manager):
def handleRequest(self, request):
if request.requestType == 'DaysOff':
print '%s:%s Num:%d Accepted OVER' % (self.name, request.requestContent, request.number)
class request():
requestType = ''
requestContent = ''
number = 0
request类封装了假期请求。在具体的经理类中,可以通过setSuccessor接口来构建“责任链”,并在handleRequest接口中实现逻辑。场景类中实现如下:
if __name__=="__main__":
line_manager = lineManager('LINE MANAGER')
department_manager = departmentManager('DEPARTMENT MANAGER')
general_manager = generalManager('GENERAL MANAGER')
line_manager.setSuccessor(department_manager)
department_manager.setSuccessor(general_manager)
req = request()
req.requestType = 'DaysOff'
req.requestContent = 'Ask 1 day off'
req.number = 1
line_manager.handleRequest(req)
req.requestType = 'DaysOff'
req.requestContent = 'Ask 5 days off'
req.number = 5
line_manager.handleRequest(req)
req.requestType = 'DaysOff'
req.requestContent = 'Ask 10 days off'
req.number = 10
line_manager.handleRequest(req)
打印如下:
LINE MANAGER:Ask 1 day off Num:1 Accepted OVERLINE MANAGER:Ask 5 days off Num:5 Accepted CONTINUEDEPARTMENT MANAGER:Ask 5 days off Num:5 Accepted OVERLINE MANAGER:Ask 10 days off Num:10 Accepted CONTINUEDEPARTMENT MANAGER:Ask 10 days off Num:10 Accepted CONTINUEGENERAL MANAGER:Ask 10 days off Num:10 Accepted OVER
二、责任链模式
责任链模式的定义如下:使多个对象都有机会处理请求,从而避免了请求的发送者和接收者之间的耦合关系。将这些对象连成一条链,并沿着这条链传递该请求,直到有对象处理它为止。

需要说明的是,责任链模式中的应该只有一个处理者,也就是说,本例中的“最终批准”为该对象所谓的“请求处理”。
三、责任链模式的优点和应用场景
优点:
1、将请求者与处理者分离,请求者并不知道请求是被哪个处理者所处理,易于扩展。
应用场景:
1、若一个请求可能由一个对请求有链式优先级的处理群所处理时,可以考虑责任链模式。除本例外,银行的客户请求处理系统也可以用责任链模式实现(VIP客户和普通用户处理方式当然会有不同)。
四、责任链模式的缺点
1、如果责任链比较长,会有比较大的性能问题;2、如果责任链比较长,若业务出现问题,比较难定位是哪个处理者的问题。
14 命令模式
一、饭店点餐系统
又是一个点餐系统(原谅作者的吃货属性)。不过这次的点餐系统是个饭店的点餐系统。饭店的点餐系统有什么不同嘛?大伙想想看,在大多数饭店中,当服务员已经接到顾客的点单,录入到系统中后,根据不同的菜品,会有不同的后台反应。比如,饭店有凉菜间、热菜间、主食间,那当服务员将菜品录入到系统中后,凉菜间会打印出顾客所点的凉菜条目,热菜间会打印出顾客所点的热菜条目,主食间会打印出主食条目。那这个系统的后台模式该如何设计?当然,直接在场景代码中加if…else…语句判断是个方法,可这样做又一次加重了系统耦合,违反了单一职责原则,遇到系统需求变动时,又会轻易违反开闭原则。所以,我们需要重新组织一下结构。可以将该系统设计成前台服务员系统和后台系统,后台系统进一步细分成主食子系统,凉菜子系统,热菜子系统。后台三个子系统设计如下:
class backSys():
def cook(self,dish):
pass
class mainFoodSys(backSys):
def cook(self,dish):
print "MAINFOOD:Cook %s"%dish
class coolDishSys(backSys):
def cook(self,dish):
print "COOLDISH:Cook %s"%dish
class hotDishSys(backSys):
def cook(self,dish):
print "HOTDISH:Cook %s"%dish
前台服务员系统与后台系统的交互,我们可以通过命令的模式来实现,服务员将顾客的点单内容封装成命令,直接对后台下达命令,后台完成命令要求的事,即可。前台系统构建如下:
class waiterSys():
menu_map=dict()
commandList=[]
def setOrder(self,command):
print "WAITER:Add dish"
self.commandList.append(command)
def cancelOrder(self,command):
print "WAITER:Cancel order..."
self.commandList.remove(command)
def notify(self):
print "WAITER:Nofify..."
for command in self.commandList:
command.execute()
前台系统中的notify接口直接调用命令中的execute接口,执行命令。命令类构建如下:
class Command():
receiver = None
def __init__(self, receiver):
self.receiver = receiver
def execute(self):
pass
class foodCommand(Command):
dish=""
def __init__(self,receiver,dish):
self.receiver=receiver
self.dish=dish
def execute(self):
self.receiver.cook(self.dish)
class mainFoodCommand(foodCommand):
pass
class coolDishCommand(foodCommand):
pass
class hotDishCommand(foodCommand):
pass
Command类是个比较通过的类,foodCommand类是本例中涉及的类,相比于Command类进行了一定的改造。由于后台系统中的执行函数都是cook,因而在foodCommand类中直接将execute接口实现,如果后台系统执行函数不同,需要在三个子命令系统中实现execute接口。这样,后台三个命令类就可以直接继承,不用进行修改了。(这里子系统没有变动,可以将三个子系统的命令废弃不用,直接用foodCommand吗?当然可以,各有利蔽。请读者结合自身开发经验,进行思考相对于自己业务场景的使用,哪种方式更好。)为使场景业务精简一些,我们再加一个菜单类来辅助业务,菜单类在本例中直接写死。
class menuAll:
menu_map=dict()
def loadMenu(self):
self.menu_map["hot"] = ["Yu-Shiang Shredded Pork", "Sauteed Tofu, Home Style", "Sauteed Snow Peas"]
self.menu_map["cool"] = ["Cucumber", "Preserved egg"]
self.menu_map["main"] = ["Rice", "Pie"]
def isHot(self,dish):
if dish in self.menu_map["hot"]:
return True
return False
def isCool(self,dish):
if dish in self.menu_map["cool"]:
return True
return False
def isMain(self,dish):
if dish in self.menu_map["main"]:
return True
return False
业务场景如下:
if __name__=="__main__":
dish_list=["Yu-Shiang Shredded Pork","Sauteed Tofu, Home Style","Cucumber","Rice"]
waiter_sys=waiterSys()
main_food_sys=mainFoodSys()
cool_dish_sys=coolDishSys()
hot_dish_sys=hotDishSys()
menu=menuAll()
menu.loadMenu()
for dish in dish_list:
if menu.isCool(dish):
cmd=coolDishCommand(cool_dish_sys,dish)
elif menu.isHot(dish):
cmd=hotDishCommand(hot_dish_sys,dish)
elif menu.isMain(dish):
cmd=mainFoodCommand(main_food_sys,dish)
else:
continue
waiter_sys.setOrder(cmd)
waiter_sys.notify()
打印如下:
WAITER:Add dishWAITER:Add dishWAITER:Add dishWAITER:Add dishWAITER:Nofify…HOTDISH:Cook Yu-Shiang Shredded PorkHOTDISH:Cook Sauteed Tofu, Home StyleCOOLDISH:Cook CucumberMAINFOOD:Cook Rice
二、命令模式
命令模式的定义为:将一个请求封装成一个对象,从而可以使用不同的请求将客户端参数化,对请求排队或者记录请求日志,可以提供命令的撤销和恢复功能。命令模式中通常涉及三类对象的抽象:Receiver,Command,Invoker(本例中的waiterSys)。

只有一个Invoker的命令模式也可以抽象成一个类似的“星形网络”,但与之前介绍的中介者模式不同,单纯的命令模式更像是一个辐射状的结构,由Invoker直接对Receiver传递命令,而一般不反向传递,中介者模式“星形网络”的中心,是个协调者,抽象结节间的信息流全部或者部分是双向的。另外,命令模式的定义中提到了“撤销和恢复功能”,也给了各位开发人员一个命令模式使用过程中的建议:各个Receiver中可以设计一个回滚接口,支持命令的“撤销”。
三、命令模式的优点和应用场景
优点:
1、低耦合:调用者和接收者之间没有什么直接关系,二者通过命令中的execute接口联系;2、扩展性好:新命令很容易加入,也很容易拼出“组合命令”。
应用场景:
1、触发-反馈机制的系统,都可以使用命令模式思想。如基于管道结构的命令系统(如SHELL),可以直接套用命令模式;此外,GUI系统中的操作反馈(如点击、键入等),也可以使用命令模式思想。
四、命令模式的缺点
1、如果业务场景中命令比较多,那么对应命令类和命令对象的数量也会增加,这样系统会膨胀得很大。
15 中介者模式
一、仓储管理系统
有一个手机仓储管理系统,使用者有三方:销售、仓库管理员、采购。需求是:销售一旦达成订单,销售人员会通过系统的销售子系统部分通知仓储子系统,仓储子系统会将可出仓手机数量减少,同时通知采购管理子系统当前销售订单;仓储子系统的库存到达阈值以下,会通知销售子系统和采购子系统,并督促采购子系统采购;采购完成后,采购人员会把采购信息填入采购子系统,采购子系统会通知销售子系统采购完成,并通知仓库子系统增加库存。从需求描述来看,每个子系统都和其它子系统有所交流,在设计系统时,如果直接在一个子系统中集成对另两个子系统的操作,一是耦合太大,二是不易扩展。为解决这类问题,我们需要引入一个新的角色-中介者-来将“网状结构”精简为“星形结构”。(为充分说明设计模式,某些系统细节暂时不考虑,例如:仓库满了怎么办该怎么设计。类似业务性的内容暂时不考虑)首先构造三个子系统,即三个类(在中介者模式中,这些类叫做同事些):
class colleague():
mediator = None
def __init__(self,mediator):
self.mediator = mediator
class purchaseColleague(colleague):
def buyStuff(self,num):
print "PURCHASE:Bought %s"%num
self.mediator.execute("buy",num)
def getNotice(self,content):
print "PURCHASE:Get Notice--%s"%content
class warehouseColleague(colleague):
total=0
threshold=100
def setThreshold(self,threshold):
self.threshold=threshold
def isEnough(self):
if self.totalself.total:
print "WAREHOUSE:Error...Stock is not enough"
else:
self.total-=num
print "WAREHOUSE:Decrease %s"%num
self.mediator.execute("decrease",num)
self.isEnough()
class salesColleague(colleague):
def sellStuff(self,num):
print "SALES:Sell %s"%num
self.mediator.execute("sell",num)
def getNotice(self, content):
print "SALES:Get Notice--%s" % content
当各个类在初始时都会指定一个中介者,而各个类在有变动时,也会通知中介者,由中介者协调各个类的操作。 中介者实现如下:
class abstractMediator():
purchase=""
sales=""
warehouse=""
def setPurchase(self,purchase):
self.purchase=purchase
def setWarehouse(self,warehouse):
self.warehouse=warehouse
def setSales(self,sales):
self.sales=sales
def execute(self,content,num):
pass
class stockMediator(abstractMediator):
def execute(self,content,num):
print "MEDIATOR:Get Info--%s"%content
if content=="buy":
self.warehouse.inc(num)
self.sales.getNotice("Bought %s"%num)
elif content=="increase":
self.sales.getNotice("Inc %s"%num)
self.purchase.getNotice("Inc %s"%num)
elif content=="decrease":
self.sales.getNotice("Dec %s"%num)
self.purchase.getNotice("Dec %s"%num)
elif content=="warning":
self.sales.getNotice("Stock is low.%s Left."%num)
self.purchase.getNotice("Stock is low. Please Buy More!!! %s Left"%num)
elif content=="sell":
self.warehouse.dec(num)
self.purchase.getNotice("Sold %s"%num)
else:
pass
中介者模式中的execute是最重要的方法,它根据同事类传递的信息,直接协调各个同事的工作。 在场景类中,设置仓储阈值为200,先采购300,再卖出120,实现如下:
if __name__=="__main__":
mobile_mediator=stockMediator()
mobile_purchase=purchaseColleague(mobile_mediator)
mobile_warehouse=warehouseColleague(mobile_mediator)
mobile_sales=salesColleague(mobile_mediator)
mobile_mediator.setPurchase(mobile_purchase)
mobile_mediator.setWarehouse(mobile_warehouse)
mobile_mediator.setSales(mobile_sales)
mobile_warehouse.setThreshold(200)
mobile_purchase.buyStuff(300)
mobile_sales.sellStuff(120)
打印结果如下:
PURCHASE:Bought 300MEDIATOR:Get Info–buyWAREHOUSE:Increase 300MEDIATOR:Get Info–increaseSALES:Get Notice–Inc 300PURCHASE:Get Notice–Inc 300SALES:Get Notice–Bought 300SALES:Sell 120MEDIATOR:Get Info–sellWAREHOUSE:Decrease 120MEDIATOR:Get Info–decreaseSALES:Get Notice–Dec 120PURCHASE:Get Notice–Dec 120WAREHOUSE:Warning…Stock is low… MEDIATOR:Get Info–warningSALES:Get Notice–Stock is low.180 Left.PURCHASE:Get Notice–Stock is low. Please Buy More!!! 180 LeftPURCHASE:Get Notice–Sold 120
二、中介者模式
中介者模式的定义为:用一个中介对象封装一系列的对象交互。中介者使各对象不需要显式地互相作用,从而使其耦合松散,并可以独立地改变它们之间的交互。
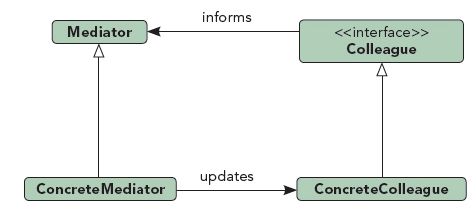
三、中介者模式的优点和应用场景
优点:
1、减少类与类的依赖,降低了类和类之间的耦合;2、容易扩展规模。
应用场景:
1、设计类图时,出现了网状结构时,可以考虑将类图设计成星型结构,这样就可以使用中介者模式了。如机场调度系统(多个跑道、飞机、指挥塔之间的调度)、路由系统;著名的MVC框架中,其中的C(Controller)就是M(Model)和V(View)的中介者。
四、中介者模式的缺点
1、中介者本身的复杂性可能会很大,例如,同事类的方法如果很多的话,本例中的execute逻辑会很复杂。
16 模板模式
一、股票查询客户端
投资股票是种常见的理财方式,我国股民越来越多,实时查询股票的需求也越来越大。今天,我们通过一个简单的股票查询客户端来认识一种简单的设计模式:模板模式。根据股票代码来查询股价分为如下几个步骤:登录、设置股票代码、查询、展示。构造如下的虚拟股票查询器:
class StockQueryDevice():
stock_code="0"
stock_price=0.0
def login(self,usr,pwd):
pass
def setCode(self,code):
self.stock_code=code
def queryPrice(self):
pass
def showPrice(self):
pass
现在查询机构很多,我们可以根据不同的查询机构和查询方式,来通过继承的方式实现其对应的股票查询器类。例如,WebA和WebB的查询器类可以构造如下:
class WebAStockQueryDevice(StockQueryDevice):
def login(self,usr,pwd):
if usr=="myStockA" and pwd=="myPwdA":
print "Web A:Login OK... user:%s pwd:%s"%(usr,pwd)
return True
else:
print "Web A:Login ERROR... user:%s pwd:%s"%(usr,pwd)
return False
def queryPrice(self):
print "Web A Querying...code:%s "%self.stock_code
self.stock_price=20.00
def showPrice(self):
print "Web A Stock Price...code:%s price:%s"%(self.stock_code,self.stock_price)
class WebBStockQueryDevice(StockQueryDevice):
def login(self,usr,pwd):
if usr=="myStockB" and pwd=="myPwdB":
print "Web B:Login OK... user:%s pwd:%s"%(usr,pwd)
return True
else:
print "Web B:Login ERROR... user:%s pwd:%s"%(usr,pwd)
return False
def queryPrice(self):
print "Web B Querying...code:%s "%self.stock_code
self.stock_price=30.00
def showPrice(self):
print "Web B Stock Price...code:%s price:%s"%(self.stock_code,self.stock_price)
在场景中,想要在网站A上查询股票,需要进行如下操作:
if __name__=="__main__":
web_a_query_dev=WebAStockQueryDevice()
web_a_query_dev.login("myStockA","myPwdA")
web_a_query_dev.setCode("12345")
web_a_query_dev.queryPrice()
web_a_query_dev.showPrice()
打印结果如下:
Web A:Login OK… user:myStockA pwd:myPwdAWeb A Querying…code:12345 Web A Stock Price…code:12345 price:20.0
每次操作,都会调用登录,设置代码,查询,展示这几步,是不是有些繁琐?既然有些繁琐,何不将这几步过程封装成一个接口。由于各个子类中的操作过程基本满足这个流程,所以这个方法可以写在父类中:
class StockQueryDevice():
stock_code="0"
stock_price=0.0
def login(self,usr,pwd):
pass
def setCode(self,code):
self.stock_code=code
def queryPrice(self):
pass
def showPrice(self):
pass
def operateQuery(self,usr,pwd,code):
self.login(usr,pwd)
self.setCode(code)
self.queryPrice()
self.showPrice()
return True
这样,在业务场景中,就可以通过operateQuery一气呵成了。
if __name__=="__main__":
web_a_query_dev=WebAStockQueryDevice()
web_a_query_dev.operateQuery("myStockA","myPwdA","12345")
这种基本每个程序员都会想到的解决方案,就是模板模式。很简单吧。但也许你会问,登录并不一定每次都会成功呀?是的,所以在operateQuery接口中需要做一重判断,写成:
def operateQuery(self,usr,pwd,code):
if not self.login(usr,pwd):
return False
self.setCode(code)
self.queryPrice()
self.showPrice()
return True
在模板模式中,像这样类似于login等根据特定情况,定制某些特定动作的函数,被称作钩子函数。此例中,如果登录失败(user:myStock B,pwd:myPwdA),会打印如下结果:Web A:Login ERROR… user:myStockB pwd:myPwdA
二、模板模式
模板模式定义如下:定义一个操作中的算法的框架,而将一些步骤延迟到子类中,使得子类可以不改变一个算法的结构即可重新定义该算法的某些特定的步骤。子类实现的具体方法叫作基本方法,实现对基本方法高度的框架方法,叫作模板方法。
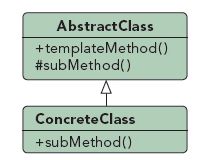
三、模板模式的优点和应用
优点:
1、可变的部分可以充分扩展,不变的步骤可以充分封装;2、提取公共代码,减少冗余代码,便于维护;3、具体过程可以定制,总体流程方便掌控。
使用场景:
1、某超类的子类中有公有的方法,并且逻辑基本相同,可以使用模板模式。必要时可以使用钩子方法约束其行为。具体如本节例子;2、比较复杂的算法,可以把核心算法提取出来,周边功能在子类中实现。例如,机器学习中的监督学习算法有很多,如决策树、KNN、SVM等,但机器学习的流程大致相同,都包含输入样本、拟合(fit)、预测等过程,这样就可以把这些过程提取出来,构造模板方法,并通过钩子方法控制流程。
四、模板模式的缺点
1、模板模式在抽象类中定义了子类的方法,即子类对父类产生了影响,部分影响了代码的可读性。
17 迭代器模式
一、迭代器与生成器
今天的主角是迭代器模式。在python中,迭代器并不用举太多的例子,因为python中的迭代器应用实在太多了(不管是python还是其它很多的编程语言中,实际上迭代器都已经纳入到了常用的库或者包中)。而且在当前,也几乎没有人专门去开发一个迭代器,而是直接去使用list、string、set、dict等python可迭代对象,或者直接使用iter和next函数来实现迭代器。如下例:
if __name__=="__main__":
lst=["hello Alice","hello Bob","hello Eve"]
lst_iter=iter(lst)
print lst_iter
print lst_iter.next()
print lst_iter.next()
print lst_iter.next()
print lst_iter.next()
打印如下:
hello Alicehello Bobhello EveTraceback (most recent call last):File “D:/WorkSpace/Project/PyDesignMode/example.py”, line 719, in print lst_iter.next()StopIteration
在这种迭代器的使用过程中,如果next超过了迭代范围,会抛出异常。在python对象的方法中,也可以轻易使用迭代器模式构造可迭代对象,如下例:
class MyIter(object):
def __init__(self, n):
self.index = 0
self.n = n
def __iter__(self):
return self
def next(self):
if self.index < self.n:
value = self.index**2
self.index += 1
return value
else:
raise StopIteration()
iter和next实现了迭代器最基本的方法。如下方式进行调用:
if __name__=="__main__":
x_square=MyIter(10)
for x in x_square:
print x
打印如下:
0149162536496481
**注意*iter*方法中的返回值,由于直接返回了self,因而该迭代器是无法重复迭代的,如以下业务场景:
if __name__=="__main__":
x_square=MyIter(10)
for x in x_square:
print x
for x in x_square:
print x
**只能打印一遍平方值。解决办法是,在*iter*中不返回实例,而再返回一个对象,写成:
def __iter__(self):
return MyIter(self.n)
这样,在每次迭代时都可以将迭代器“初始化”,就可以多次迭代了。另外,在python中,使用生成器可以很方便的支持迭代器协议。生成器通过生成器函数产生,生成器函数可以通过常规的def语句来定义,但是不用return返回,而是用yield一次返回一个结果,在每个结果之间挂起和继续它们的状态,来自动实现迭代协议。如下例:
def MyGenerater(n):
index=0
while index注意,这是个函数。在每次调用生成器,得到返回结果后,现场得以保留,下次再调用该生 成器时,返回保留的现场从yield后继续执行程序。
if __name__=="__main__":
x_square=MyGenerater(10)
for x in x_square:
print x
打印结果与上面一致。
二、迭代器模式
迭代器模式的定义如下:它提供一种方法,访问一个容器对象中各个元素,而又不需要暴露对象的内部细节。
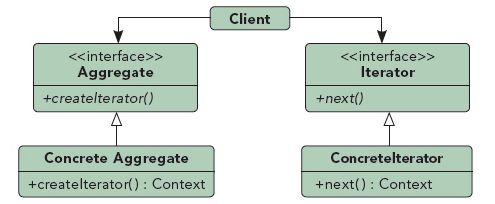
18 访问者模式
一、药房业务系统
假设一个药房,有一些大夫,一个药品划价员和一个药房管理员,它们通过一个药房管理系统组织工作流程。大夫开出药方后,药品划价员确定药品是否正常,价格是否正确;通过后药房管理员进行开药处理。该系统可以如何实现?最简单的想法,是分别用一个一个if…else…把划价员处理流程和药房管理流程实现,这样做的问题在于,扩展性不强,而且单一性不强,一旦有新药的加入或者划价流程、开药流程有些变动,会牵扯比较多的改动。今天介绍一种解决这类问题的模式:访问者模式。首先,构造药品类和工作人员类:
class Medicine:
name=""
price=0.0
def __init__(self,name,price):
self.name=name
self.price=price
def getName(self):
return self.name
def setName(self,name):
self.name=name
def getPrice(self):
return self.price
def setPrice(self,price):
self.price=price
def accept(self,visitor):
pass
class Antibiotic(Medicine):
def accept(self,visitor):
visitor.visit(self)
class Coldrex(Medicine):
def accept(self,visitor):
visitor.visit(self)
药品类中有两个子类,抗生素和感冒药;
class Visitor:
name=""
def setName(self,name):
self.name=name
def visit(self,medicine):
pass
class Charger(Visitor):
def visit(self,medicine):
print "CHARGE: %s lists the Medicine %s. Price:%s " % (self.name,medicine.getName(),medicine.getPrice())
class Pharmacy(Visitor):
def visit(self,medicine):
print "PHARMACY:%s offers the Medicine %s. Price:%s" % (self.name,medicine.getName(),medicine.getPrice())
工作人员分为划价员和药房管理员。 在药品类中,有一个accept方法,其参数是个visitor;而工作人员就是从Visitor类中继承而来的,也就是说,他们就是Visitor,都包含一个visit方法,其参数又恰是medicine。药品作为处理元素,依次允许(Accept)Visitor对其进行操作,这就好比是一条流水线上的一个个工人,对产品进行一次次的加工。整个业务流程还差一步,即药方类的构建(流水线大机器)。
class ObjectStructure:
pass
class Prescription(ObjectStructure):
medicines=[]
def addMedicine(self,medicine):
self.medicines.append(medicine)
def rmvMedicine(self,medicine):
self.medicines.append(medicine)
def visit(self,visitor):
for medc in self.medicines:
medc.accept(visitor)
药方类将待处理药品进行整理,并组织Visitor依次处理。 业务代码如下:
if __name__=="__main__":
yinqiao_pill=Coldrex("Yinqiao Pill",2.0)
penicillin=Antibiotic("Penicillin",3.0)
doctor_prsrp=Prescription()
doctor_prsrp.addMedicine(yinqiao_pill)
doctor_prsrp.addMedicine(penicillin)
charger=Charger()
charger.setName("Doctor Strange")
pharmacy=Pharmacy()
pharmacy.setName("Doctor Wei")
doctor_prsrp.visit(charger)
doctor_prsrp.visit(pharmacy)
打印如下:
CHARGE: Doctor Strange lists the Medicine Yinqiao Pill. Price:2.0CHARGE: Doctor Strange lists the Medicine Penicillin. Price:3.0PHARMACY:Doctor Wei offers the Medicine Yinqiao Pill. Price:2.0PHARMACY:Doctor Wei offers the Medicine Penicillin. Price:3.0
二、访问者模式
访问者模式的定义如下:封装一些作用于某种数据结构中的各元素的操作,它可以在不改变数据结构的前提下定义于作用于这些元素的新操作。

提到访问者模式,就不得不提一下双分派。分派分为静态分派和动态分派。首先解释下静态分派,静态分派即根据请求者的名称和接收到的参数,决定多态时处理的操作。比如在Java或者C++中,定义名称相同但参数不同的函数时,会根据最终输入的参数来决定调用哪个函数。双分派顾名思义,即最终的操作决定于两个接收者的类型,在本例中,药品和工作人员互相调用了对方(药品的accept和工作人员的visit中,对方都是参数),就是双分派的一种应用。那么Python支持静态分派么?先看下面的一个例子。
def max_num(x,y,z):
return max(max(x,y),z)
def max_num(x,y):
return max(x,y)
if __name__=="__main__":
print max_num(1,2,4)
打印如下:
Traceback (most recent call last): File “D:/WorkSpace/Project/PyDesignMode/example.py”, line 786, in
print max_num(1,2,4)
TypeError: max_num() takes exactly 2 arguments (3 given)
可见,Python原生是不支持静态分派的,因而也不直接支持更高层次的分派。访问者模式实现的分派,是一种动态双分派。但这并不妨碍Python通过访问者模式实现一种基于类的“双分派效果”。Python多分派可以参考David
Mertz 博士的一篇文章:可爱的Python:多分派—用多元法泛化多样性。
三、访问者模式的优点和应用场景
优点:
1、将不同的职责非常明确地分离开来,符合单一职责原则;2、职责的分开也直接导致扩展非常优良,灵活性非常高,加减元素和访问者都非常容易。
应用场景:
1、要遍历不同的对象,根据对象进行不同的操作的场景;或者一个对象被多个不同对象顺次处理的情况,可以考虑使用访问者模式。除本例外,报表生成器也可以使用访问者模式实现,报表的数据源由多个不同的对象提供,每个对象都是Visitor,报表这个Element顺次Accept各访问者完善并生成对象。
四、访问者模式的缺点
1、访问者得知了元素细节,与最小隔离原则相悖;2、元素变更依旧可能引起Visitor的修改。
19 观察者模式
一、火警报警器
在门面模式中,我们提到过火警报警器。在当时,我们关注的是通过封装减少代码重复。而今天,我们将从业务流程的实现角度,来再次实现该火警报警器。
class AlarmSensor:
def run(self):
print "Alarm Ring..."
class WaterSprinker:
def run(self):
print "Spray Water..."
class EmergencyDialer:
def run(self):
print "Dial 119..."
以上是门面模式中的三个传感器类的结构。仔细分析业务,报警器、洒水器、拨号器都是“观察”烟雾传感器的情况来做反应的。因而,他们三个都是观察者,而烟雾传感器则是被观察对象了。根据分析,将三个类提取共性,泛化出“观察者”类,并构造被观察者。 观察者如下:
class Observer:
def update(self):
pass
class AlarmSensor(Observer):
def update(self,action):
print "Alarm Got: %s" % action
self.runAlarm()
def runAlarm(self):
print "Alarm Ring..."
class WaterSprinker(Observer):
def update(self,action):
print "Sprinker Got: %s" % action
self.runSprinker()
def runSprinker(self):
print "Spray Water..."
class EmergencyDialer(Observer):
def update(self,action):
print "Dialer Got: %s"%action
self.runDialer()
def runDialer(self):
print "Dial 119..."
观察者中定义了update接口,如果被观察者状态比较多,或者每个具体的观察者方法比较多,可以通过update传参数进行更丰富的控制。 下面构造被观察者。
class Observed:
observers=[]
action=""
def addObserver(self,observer):
self.observers.append(observer)
def notifyAll(self):
for obs in self.observers:
obs.update(self.action)
class smokeSensor(Observed):
def setAction(self,action):
self.action=action
def isFire(self):
return True
被观察者中首先将观察对象加入到观察者数组中,若发生情况,则通过notifyAll通知各观察者。 业务代码如下:
if __name__=="__main__":
alarm=AlarmSensor()
sprinker=WaterSprinker()
dialer=EmergencyDialer()
smoke_sensor=smokeSensor()
smoke_sensor.addObserver(alarm)
smoke_sensor.addObserver(sprinker)
smoke_sensor.addObserver(dialer)
if smoke_sensor.isFire():
smoke_sensor.setAction("On Fire!")
smoke_sensor.notifyAll()
打印如下:
Alarm Got: On Fire!Alarm Ring…Sprinker Got: On Fire!Spray Water…Dialer Got: On Fire!Dial 119…
二、观察者模式
观察者模式也叫发布-订阅模式,其定义如下:定义对象间一种一对多的依赖关系,使得当该对象状态改变时,所有依赖于它的对象都会得到通知,并被自动更新。观察者模式的通知方式可以通过直接调用等同步方式实现(如函数调用,HTTP接口调用等),也可以通过消息队列异步调用(同步调用指被观察者发布消息后,必须等所有观察者响应结束后才可以进行接下来的操作;异步调用指被观察者发布消息后,即可进行接下来的操作。)。事实上,许多开源的消息队列就直接支持发布-订阅模式,如Zero
MQ等。
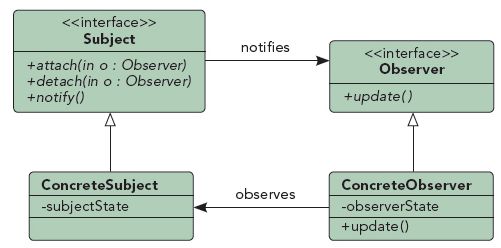
三、观察者模式的优点和应用场景
优点:
1、观察者与被观察者之间是抽象耦合的;2、可以将许多符合单一职责原则的模块进行触发,也可以很方便地实现广播。
应用场景:
1、消息交换场景。如上述说到的消息队列等;2、多级触发场景。比如支持中断模式的场景中,一个中断即会引发一连串反应,就可以使用观察者模式。
四、观察者模式的缺点
1、观察者模式可能会带来整体系统效率的浪费;2、如果被观察者之间有依赖关系,其逻辑关系的梳理需要费些心思。
20 解释器模式
一、模拟吉他
要开发一个自动识别谱子的吉他模拟器,达到录入谱即可按照谱发声的效果。除了发声设备外(假设已完成),最重要的就是读谱和译谱能力了。分析其需求,整个过程大致上分可以分为两部分:根据规则翻译谱的内容;根据翻译的内容演奏。我们用一个解释器模型来完成这个功能。
class PlayContext():
play_text = None
class Expression():
def interpret(self, context):
if len(context.play_text) == 0:
return
else:
play_segs=context.play_text.split(" ")
for play_seg in play_segs:
pos=0
for ele in play_seg:
if ele.isalpha():
pos+=1
continue
break
play_chord = play_seg[0:pos]
play_value = play_seg[pos:]
self.execute(play_chord,play_value)
def execute(self,play_key,play_value):
pass
class NormGuitar(Expression):
def execute(self, key, value):
print "Normal Guitar Playing--Chord:%s Play Tune:%s"%(key,value)
PlayContext类为谱的内容,这里仅含一个字段,没有方法。Expression即表达式,里面仅含两个方法,interpret负责转译谱,execute则负责演奏;NormGuitar类覆写execute,以吉他 的方式演奏。 业务场景如下:
if __name__=="__main__":
context = PlayContext()
context.play_text = "C53231323 Em43231323 F43231323 G63231323"
guitar=NormGuitar()
guitar.interpret(context)
打印如下:
Normal Guitar Playing–Chord:C Play Tune:53231323Normal Guitar Playing–Chord:Em Play Tune:43231323Normal Guitar Playing–Chord:F Play Tune:43231323Normal Guitar Playing–Chord:G Play Tune:63231323
二、解释器模式
解释器模式定义如下:给定一种语言,定义它的文法表示,并定义一个解释器,该解释器使用该表示来解释语言中的句子。典型的解释器模式中会有终结符和非终结符之说,语法也根据两种终结符,决定语句最终含义。上例中,非终结符就是空格,终结符就是整个句尾。

三、解释器模式的优点和应用场景
优点:
1、在语法分析的场景中,具有比较好的扩展性。规则修改和制订比较灵活。
应用场景:
1、若一个问题重复发生,可以考虑使用解释器模式。这点在数据处理和日志处理过程中使用较多,当数据的需求方需要将数据纳为己用时,必须将数据“翻译”成本系统的数据规格;同样的道理,日志分析平台也需要根据不同的日志格式翻译成统一的“语言”。2、特定语法解释器。如各种解释型语言的解释器,再比如自然语言中基于语法的文本分析等。
四、解释器模式的缺点
1、解释规则多样化会导致解释器的爆炸;2、解释器目标比较单一,行为模式比较固定,因而重要的模块中尽量不要使用解释器模式。
21 备忘录模式
一、游戏进度保存
打过游戏的朋友一定知道,大多数游戏都有保存进度的功能,如果一局游戏下来,忘保存了进度,那么下次只能从上次进度点开始重新打了。一般情况下,保存进度是要存在可持久化存储器上,本例中先以保存在内存中来模拟实现该场景的情形。以模拟一个战斗角色为例。首先,创建游戏角色。
class GameCharacter():
vitality = 0
attack = 0
defense = 0
def displayState(self):
print 'Current Values:'
print 'Life:%d' % self.vitality
print 'Attack:%d' % self.attack
print 'Defence:%d' % self.defense
def initState(self,vitality,attack,defense):
self.vitality = vitality
self.attack = attack
self.defense = defense
def saveState(self):
return Memento(self.vitality, self.attack, self.defense)
def recoverState(self, memento):
self.vitality = memento.vitality
self.attack = memento.attack
self.defense = memento.defense
class FightCharactor(GameCharacter):
def fight(self):
self.vitality -= random.randint(1,10)
GameCharacter定义了基本的生命值、攻击值、防御值以及实现角色状态控制的方法,FightCharactor实现具体的“战斗”接口。为实现保存进度的细节,还需要一个备忘录,来保存进度。
class Memento:
vitality = 0
attack = 0
defense = 0
def __init__(self, vitality, attack, defense):
self.vitality = vitality
self.attack = attack
self.defense = defense
万事俱备,在业务逻辑中可以进行类的调度了。
if __name__=="__main__":
game_chrctr = FightCharactor()
game_chrctr.initState(100,79,60)
game_chrctr.displayState()
memento = game_chrctr.saveState()
game_chrctr.fight()
game_chrctr.displayState()
game_chrctr.recoverState(memento)
game_chrctr.displayState()
打印如下:
Current Values:Life:100Attack:79Defence:60Current Values:Life:91Attack:79Defence:60Current Values:Life:100Attack:79Defence:60
由生命值变化可知,先保存状态值,经过一轮打斗后,生命值由100变为91,而后恢复状态值,生命值又恢复成100。
二、备忘录模式
备忘录模式定义如下:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态。这样以后就可以将该对象恢复到原来保存的状态。在备忘录模式中,如果要保存的状态多,可以创造一个备忘录管理者角色来管理备忘录。

三、备忘录模式应用场景
1、需要保存和恢复数据的相关状态场景。如保存游戏状态的场景;撤销场景,如Ctrl-Z操作;事务回滚的应用。一般情况下事务回滚有两种方式:一是把从恢复点开始的操作都反向执行一遍;二是直接恢复到恢复点的各种状态。两种方式各有优缺点,要结合业务场景,决定使用哪种模式;2、副本监控场景。备忘录可以当作一个临时的副本监控,实现非实时和准实时的监控。
22 状态模式
一、电梯控制器
电梯在我们周边随处可见,电梯的控制逻辑中心是由电梯控制器实现的。电梯的控制逻辑,即使简单点设计,把状态分成开门状态,停止状态和运行状态,操作分成开门、关门、运行、停止,那流程也是很复杂的。首先,开门状态不能开门、运行、停止;停止状态不能关门,停止;运行状态不能开门、关门、运行。要用一个一个if…else…实现,首先代码混乱,不易维护;二是不易扩展。至于各种设计原则什么的……那该如何实现?在上边的逻辑中,每个操作仅仅是一个操作,状态切换与操作是分离的,这也造成后来操作和状态“相互配合”的“手忙脚乱”。如果把状态抽象成一个类,每个状态为一个子类,每个状态实现什么操作,不实现什么操作,仅仅在这个类中具体实现就可以了。下面我们实现这个逻辑。先实现抽象的状态类:
class LiftState:
def open(self):
pass
def close(self):
pass
def run(self):
pass
def stop(self):
pass
而后实现各个具体的状态类:
class OpenState(LiftState):
def open(self):
print "OPEN:The door is opened..."
return self
def close(self):
print "OPEN:The door start to close..."
print "OPEN:The door is closed"
return StopState()
def run(self):
print "OPEN:Run Forbidden."
return self
def stop(self):
print "OPEN:Stop Forbidden."
return self
class RunState(LiftState):
def open(self):
print "RUN:Open Forbidden."
return self
def close(self):
print "RUN:Close Forbidden."
return self
def run(self):
print "RUN:The lift is running..."
return self
def stop(self):
print "RUN:The lift start to stop..."
print "RUN:The lift stopped..."
return StopState()
class StopState(LiftState):
def open(self):
print "STOP:The door is opening..."
print "STOP:The door is opened..."
return OpenState()
def close(self):
print "STOP:Close Forbidden"
return self
def run(self):
print "STOP:The lift start to run..."
return RunState()
def stop(self):
print "STOP:The lift is stopped."
return self
为在业务中调度状态转移,还需要将上下文进行记录,需要一个上下文的类。
class Context:
lift_state=""
def getState(self):
return self.lift_state
def setState(self,lift_state):
self.lift_state=lift_state
def open(self):
self.setState(self.lift_state.open())
def close(self):
self.setState(self.lift_state.close())
def run(self):
self.setState(self.lift_state.run())
def stop(self):
self.setState(self.lift_state.stop())
这样,在进行电梯的调度时,只需要调度Context就可以了。业务逻辑中如下所示:
if __name__=="__main__":
ctx = Context()
ctx.setState(StopState())
ctx.open()
ctx.run()
ctx.close()
ctx.run()
ctx.stop()
打印如下:
STOP:The door is opening…STOP:The door is opened…OPEN:Run Forbidden.OPEN:The door start to close…OPEN:The dorr is closedSTOP:The lift start to run…RUN:The lift start to stop…RUN:The lift stopped…
由逻辑中可知,电梯先在STOP状态,然后开门,开门时运行Run,被禁止,然后,关门、运行、停止。
二、状态模式
状态模式的定义如下:当一个对象内在状态改变时允许其改变行为,这个对象看起来像改变了其类。
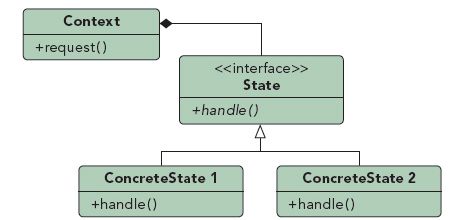
三、状态模式的优点和应用场景
优点:
1、状态模式的优点是结构清晰,相比于if…else…简约了不少;2、封装性好,外部调用不必知道内部实现细节。
应用场景:
1、行为状态改变的场景。这点在各种控制器中非常常见,同时,逻辑结构为状态转移图的场景中都非常适用。
四、状态模式的缺点
1、在状态比较多时,子类也会非常多,不便于管理。
23 设计原则
一 六大设计原则
在法理学中,法律规则与法律原则都是法律规范的重要构成。但二者也会有些不同:法律规则是指采取一定的结构形式具体规定人们的法律权利、法律义务以及相应的法律后果的行为规范,内容比较明确,比如,交通法规中规定,禁止闯红灯;法律原则是指在一定法律体系中作为法律规则的指导思想,基本或本原的、综合的、稳定的原理和准则,内容上只包含“大方针”,而并未有具体规则,比如,如果车上有马上临产的孕妇,闯红灯不会被处罚,这是符合重视生命的原则。设计模式与设计原则,基本符合规则与原则的关系,设计模式是一个个具体问题的解决方案,设计原则则反映了这些设计模式的指导思想;同时,设计原则可衍生出的设计模式也不仅限于上述介绍到了23种设计模式,任何一种针对特定业务场景中的解决方法,虽然找不到对应的设计模式与之匹配,但若符合设计原则,也可以认为是一种全新的设计模式。从这个意义上来说,设计模式是程序设计方法的形,而设计原则是程序设计方法的神。
1、单一职责原则
单一职责原则英文原名为Single Responsibility Principle,简称SRP原则。其含义为:应该有且仅有一个原因引起类的变更。举个例子来说明单一职责原则:一个视频播放系统,一个客户端类有两个功能接口,即视频播放接口和音频播放接口。虽然这样的设计很常见,但却不满足单一职责原则的。原因是,如果对视频播放有变更需求或者对音频播放有修改需求,都会变更视频客户端的类结构。符合单一原则的设计是,将视频播放单元和音频播放单元各建一个类,播放客户端继承两个类,构成客户端。单一职责原则的最大难点在于职责的划分,试想,以上划分是否是符合单一职责了?既是,也不是。试想,如果将视频传输和音频传输的协议信息和数据信息区分开,为符合这种粒度的单一职责原则就必须要有协议传输类和数据传输类的划分。如果接着细分,可能一个简单的小模块,都要设计非常多的类。因此,单一职责原则粒度的选择,应该根据业务流程和人员分工来进行考虑。一些基本的划分,似乎已经成了行业规范性的内容,比如,业务逻辑与用户信息管理的划分等。
2、里氏替换原则
里氏替换原则英文原名为Liskov Substitution Principle,简称LSP原则。它是面向对象设计的最为基本原则之一。
里氏替换原则的含义为:任何基类可以出现的地方,子类一定可以出现。
LSP是继承复用的基石,只有当子类可以替换掉基类,软件单位的功能不受到影响时,基类才能真正被复用,子类也能够在基类的基础上增加新的行为。举例说明:对于一个鸟类,可以衍生出麻雀、喜鹊、布谷等子类,这些子类都可继承鸟类的鸣叫、飞行、吃食等接口。而对于一个鸡类,虽然它在生物学上属于鸟类,但它不会飞,那么符合LSP设计原则的情况下,鸡就不应该是鸟的一个子类:在鸟类调用飞行接口的地方,鸡类并不能出现。如果鸡类要使用鸟类的接口,应该使用关联关系,而不是继承关系。
3、依赖倒置原则
依赖倒置原则英文原名为Dependence Inversion
Principle,简称DIP原则。它的含义为:高层模块不应该依赖于低层模块,两者都应该依赖其抽象。抽象不应该依赖于细节,细节应该依赖于抽象。我们将每个不可细分的逻辑叫作原子逻辑,原子逻辑组装,形成低层模块,低层模块组装形成高层模块。依赖倒置原则的含义为,高层模块和低层模块都应该由各自的抽象模块派生而来,同时接口设计应该依赖于抽象,而非具体模块。举个例子:司机与汽车是依赖的关系,司机可以有实习司机类、老司机类等派生;汽车可以有轿车、SUV、卡车等派生类。如果司机中设计一个接口drive,汽车是其参数,符合DIP设计原则的参数,应该是在基类司机类中,将基类汽车类作为参数,而司机的派生类中,drive的参数同样应该为基类汽车类,而不应该是汽车类的任一个派生类。如果规定实习司机只能开轿车等业务逻辑,应该在其接口中进行判断,而不应该将参数替换成子类轿车。
4、接口隔离原则
接口隔离原则英文原名为Interface Segregation
Principle,简称ISP原则。其含义为:类间的依赖关系不应该建立一个大的接口,而应该建立其最小的接口,即客户端不应该依赖那些它不需要的接口。这里的接口的概念是非常重要的。从逻辑上来讲,这里的接口可以指一些属性和方法的集合;从业务上来讲,接口就可以指特定业务下的接口(如函数,URL调用等)。接口应该尽量小,同时仅留给客户端必要的接口,弃用没有必要的接口。举例说明:如果要根据具体的数据,生成饼图、直方图、表格,这个类该如何设计?如果将生成饼图、直方图、表格等“接口”(这里的接口就是“操作”的集合的概念),写在一个类中,是不符合接口隔离原则的。符合ISP原则的设计应该是设计三个类,每个类分别实现饼图、直方图、表格的绘制。接口隔离原则和单一职责原则一样,涉及到粒度的问题,解决粒度大小,同样依赖于具体的业务场景,需要读者根据实践去权衡。
5、迪米特法则(最少知识原则)
迪米特法则(Law of Demeter)也叫最少知识原则,英文Least Knowledge
Principle,简称LKP原则。其含义为:一个对象应该对其它对象有最少的了解。举例说明:一个公司有多个部门,每个部门有多个员工,如果公司CEO要下发通知给每个员工,是调用接口直接通知所有员工么?其实不然,CEO只需和它的“朋友”类部门Leader交流就好,部门Leader再下发通知信息即可。而CEO类不需要与员工进行“交流”。迪米特法则要求对象应该仅对自己的朋友类交流,而不应该对非朋友类交流。那什么才是朋友类呢?一般来说,朋友类具有以下特征:1)当前对象本身(self);2)以参量形式传入到当前对象方法中的对象;3)当前对象的实例变量直接引用的对象;4)当前对象的实例变量如果是一个聚集,那么聚集中的元素也都是朋友;5)当前对象所创建的对象。
6、开闭原则
开闭原则英文原名为Open ClosedPrinciple,简称OCP原则。其含义为:一个软件实体,如类、模块、函数等,应该对扩展开放,对修改关闭。开闭原则是非常基础的一个原则,也有人把开闭原则称为“原则的原则”。前面讲到过,模块分原子模块,低层模块,高层模块,业务层可以认为是最高层次的模块。对扩展开放,意味着模块的行为是可以扩展的,当高层模块需求改变时,我们可以对低层模块进行扩展,使其具有满足高层模块的新功能;对修改关闭,即对低层模块行为进行扩展时,不必改动模块的源代码。最理想的情况是,业务变动时,仅修改业务代码,不修改依赖的模块(类、函数等)代码,通过扩展依赖的模块单元来实现业务变化。举例说明:假设一个原始基类水果类,苹果类是它的派生类,苹果中包含水果的各种属性,如形状、颜色等;另有两个类,农民类和花园类,最高层次(业务层次)为农民在花园种苹果。如果此时,农民决定不种苹果了,改种梨,符合OCP原则的设计应该为基于水果类构建一个新的类,即梨类(对扩展开放),而并不应该去修改苹果类,使它成为一个梨类(对修改关闭)。修改应仅在最高层,即业务层中进行。
二 遵循设计原则的好处
由于设计原则是设计模式的提炼,因而设计原则的好处与设计模式是一致的,即:代码易于理解;更适于团体合作;适应需求变化等。
三、设计原则与设计模式
1、创建类设计模式与设计原则
工厂模式:工厂方法模式是一种解耦结构,工厂类只需要知道抽象产品类,符合最少知识原则(迪米特法则);同时符合依赖倒置原则和里氏替换原则;抽象工厂模式:抽象工厂模式具有工厂模式的优点,但同时,如果产品族要扩展,工厂类也要修改,违反了开闭原则;模板模式:优秀的扩展能力符合开闭原则。
2、结构类设计模式与设计原则
代理模式:代理模式在业务逻辑中将对主体对象的操作进行封装,合适的应用会符合开闭原则和单一职责原则;事实上,几乎带有解耦作用的结构类设计模式都多少符合些开闭原则;门面模式:门面模式不符合开闭原则,有时不符合单一职责原则,如若不注意,也会触碰接口隔离原则;组合模式:符合开闭原则,但由于一般在拼接树时使用实现类,故不符合依赖倒置原则;桥梁模式:桥梁模式堪称依赖倒置原则的典范,同时也符合开闭原则。
3、行为类设计模式与设计原则
策略模式:符合开闭原则,但高层模块调用时,不符合迪米特法则。行为类设计模式多少会符合些单一职责原则,典型的如观察者模式、中介者模式、访问者模式等;责任链模式:符合单一职责原则和迪米特法则;命令模式:符合开闭原则。
在不同的业务逻辑中,不同的设计模式也会显示出不同的设计原则特点,从这个意义上来说,设计模式是设计原则的体现,但体现不是固定的,是根据业务而有所不同的。
总结
最后的最后
由本人水平所限,难免有错误以及不足之处, 屏幕前的靓仔靓女们 如有发现,恳请指出!
最后,谢谢你看到这里,谢谢你认真对待我的努力,希望这篇博客对你有所帮助!
你轻轻地点了个赞,那将在我的心里世界增添一颗明亮而耀眼的星!
往期优质文章分享
- C++ QT结合FFmpeg实战开发视频播放器-01环境的安装和项目部署
- 解决QT问题:运行qmake:Project ERROR: Cannot run compiler ‘cl‘. Output:
- 解决安装QT后MSVC2015 64bit配置无编译器和调试器问题
- Qt中的套件提示no complier set in kit和no debugger,出现黄色感叹号问题解决(MSVC2017)
- Python+selenium 自动化 - 实现自动导入、上传外部文件(不弹出windows窗口)
优质教程分享
- 如果感觉文章看完了不过瘾,可以来我的其他 专栏 看一下哦~
- 比如以下几个专栏:Python实战微信订餐小程序、Python量化交易实战、C++ QT实战类项目 和 算法学习专栏
- 可以学习更多的关于C++/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| Python实战微信订餐小程序 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
| Python量化交易实战 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| ❤️ C++ QT结合FFmpeg实战开发视频播放器❤️ | 难度偏高 | 分享学习QT成品的视频播放器源码,需要有扎实的C++知识! |
| 游戏爱好者九万人社区 | 互助/吹水 | 九万人游戏爱好者社区,聊天互助,白嫖奖品 |
| Python零基础到入门 | Python初学者 | 针对没有经过系统学习的小伙伴,核心目的就是让我们能够快速学习Python的知识以达到入门 |
资料白嫖,温馨提示
关注下面卡片即刻获取更多编程知识,包括各种语言学习资料,上千套PPT模板和各种游戏源码素材等等资料。更多内容可自行查看哦!
