Classification
MNIST
这是一个包含了70000个手写阿拉伯数字的图片样例,
GetTheData
ML教材上的代码样例会报错,可能是某个模块版本升级后的问题,查询github得到以下替代代码。
from shutil import copyfileobj
from six.moves import urllib
from sklearn.datasets.base import get_data_home
import os
def fetch_mnist(data_home=None):
mnist_alternative_url = "https://github.com/amplab/datascience-sp14/raw/master/lab7/mldata/mnist-original.mat"
data_home = get_data_home(data_home=data_home)
data_home = os.path.join(data_home, 'mldata')
if not os.path.exists(data_home):
os.makedirs(data_home)
mnist_save_path = os.path.join(data_home, "mnist-original.mat")
if not os.path.exists(mnist_save_path): # save at ~/scikit-learn/mldata/..
mnist_url = urllib.request.urlopen(mnist_alternative_url)
with open(mnist_save_path, "wb") as matlab_file:
copyfileobj(mnist_url, matlab_file)文件储存在~/scikit-learn/mldata/..目录下,调用fetch_mnist()获取数据。该数据以字典序降序排列(实际上是多组0-9组成),每行其实是28*28个像素点的灰度值,一共784列。以下代码将数据读入内存。
from sklearn.datasets import fetch_mldata
mnist = fetch_mldata('MNIST original')
X, y = mnist["data"], mnist["target"]
mnist查看其中一个样例。
%matplotlib inline
import matplotlib
import matplotlib.pyplot as plt
some_digit = X[36000]
some_digit_image = some_digit.reshape(28, 28)
plt.imshow(some_digit_image, cmap = matplotlib.cm.binary,
interpolation="nearest")
plt.axis("on")
plt.show()SplitTheSet
划分测试集和训练集。以前6w个为训练集,后1w个为测试集。
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[60000:]不希望在交叉验证时分fold缺少某个数字,有些算法对样例顺序比较敏感(如果训练连续类似的样例,则会影响准确性),故打乱训练集顺序。
import numpy as np
shuffle_index = np.random.permutation(60000)
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index]Binary Classifier
训练二分类算法,算法只回答true和false,以数字是不是5为例。
y_train_5 = (y_train == 5) # True for all 5s, False for all other digits.
y_test_5 = (y_test == 5)SGD
Stochastic Gradient Descent(SGD),就是独立地为所有样例打分,排成线性,去某一阈值,高之为真,低之为假。该算法也适用于在线学习。
from sklearn.linear_model import SGDClassifier
sgd_clf = SGDClassifier(random_state=42)
sgd_clf.fit(X_train, y_train_5)
sgd_clf.predict([some_digit])Performance Measures
要制定标准来评定算法的表现。手动写一个方法,利用分层划分进行算比例。
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
skfolds = StratifiedKFold(n_splits=3, random_state=42) #分层划分,每组都有相同比例的数字。
for train_index, test_index in skfolds.split(X_train, y_train_5):
clone_clf = clone(sgd_clf)
X_train_folds = X_train[train_index]
y_train_folds = (y_train_5[train_index])
X_test_fold = X_train[test_index]
y_test_fold = (y_train_5[test_index])
clone_clf.fit(X_train_folds, y_train_folds)
y_pred = clone_clf.predict(X_test_fold)
n_correct = sum(y_pred == y_test_fold)
print(n_correct / len(y_pred)) # prints 0.9502, 0.96565 and 0.96495也可以利用交叉验证算比例。
from sklearn.model_selection import cross_val_score
cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring="accuracy")但是要注意,如果你写一个选判断当前数字不是5的算法,只返回true,因为有90%的样例确实不是5,所以这个算法也能有90%的正确率,这就很哲学了。所以要有更好的评判标准。
Confusion Matrix
这个矩阵,应有n*n,n是分类数量。
(a,b)表示,在类型为a的样例中,被误认为是类型b。行是真实分类,列是预测分类。
from sklearn.model_selection import cross_val_predict
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)
print(y_train_pred)
from sklearn.metrics import confusion_matrix
confusion_matrix(y_train_5, y_train_pred)
查准率: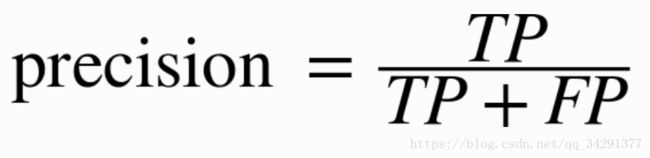
一味的追求查准率,算法可能会只正确判断出一个真值,然后剩下的全判定为假,则TP=1,FP=0,这显然Precision=100%,但是是个非常糟糕的结果。
查全率: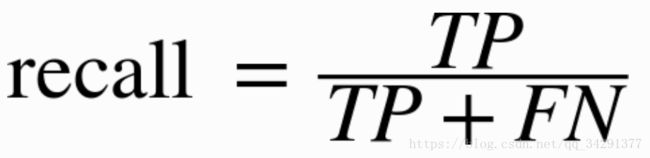
查全率使用的更多,又称sensitivity,true positive rate。
from sklearn.metrics import precision_score, recall_score
precision_score(y_train_5, y_train_pred) # == 4344 / (4344 + 1307)
recall_score(y_train_5, y_train_pred) 调和平均数:F1
F1对数值小的值以更大的权重,所以只有p和r都比较高时,才能比较高。
from sklearn.metrics import f1_score
f1_score(y_train_5, y_train_pred)P/R Tradeoff
查全率和查准率的平衡。以SGD的分类算法为例,它为每个样例打分,基于一个decision function的函数,分数高于一定阈值,则为真,反之为假。
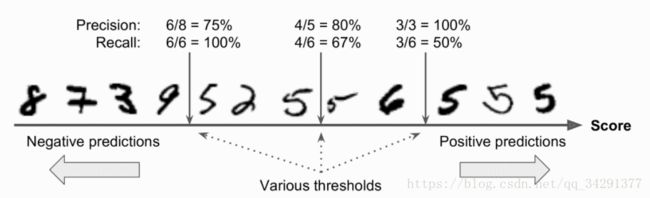
用以下代码查看分数,手动模拟阈值。
阈值设为0:
y_scores = sgd_clf.decision_function([some_digit])
print(y_scores)
threshold = 0
y_some_digit_pred = (y_scores > threshold)
print(y_some_digit_pred)阈值设为20000:
threshold = 200000
y_some_digit_pred = (y_scores > threshold)
y_some_digit_pred将P/R和阈值做图来理解所谓的Tradeoff:
y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method="decision_function")
from sklearn.metrics import precision_recall_curve
precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], "b--", label="Precision")
plt.plot(thresholds, recalls[:-1], "g-", label="Recall")
plt.xlabel("Threshold")
plt.legend(loc="upper left")
plt.ylim([0, 1])
plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
plt.show()P/R做图:
def plot_precision_vs_recall(precisions, recalls):
plt.plot(recalls[:-1], precisions[:-1], "g-")
plt.xlabel("Recall")
plt.ylabel("Precisions")
plt.xlim([0,1])
plt.ylim([0,1])
plot_precision_vs_recall(precisions, recalls)
plt.show()ROC Curve
受试者工作特征:Receiver Operating Characteristic,横轴是真正率true positive rate(TPR),纵轴是假正率false positive rate(FPR)。
TPR = TP / (TP + FN) = Recall
FPR = FP / (TN + FP)
def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plot_roc_curve(fpr, tpr)
plt.show()其中虚线表示随机分类的理想结果,好的算法,应该尽可能的远离对角线。
AUC:area under the curve,最好的算法AUC应为1。
from sklearn.metrics import roc_auc_score
roc_auc_score(y_train_5, y_scores)TIPS
PR:真集规模小,或关心误认为真比误认为假更多。
ROC:真集规模大,或关心误认为假比误认为真更多
RandomForestClassifier
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3,
method="predict_proba")
y_scores_forest = y_probas_forest[:, 1] # score = proba of positive class
fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5,y_scores_forest)
plt.plot(fpr, tpr, "b:", label="SGD")
plot_roc_curve(fpr_forest, tpr_forest, "Random Forest")
plt.legend(loc="lower right")
plt.show()
roc_auc_score(y_train_5, y_scores_forest)
Multiclass Classfication
有些算法比如,Random Forest classifiers or naive Bayes classifiers可以直接处理多个类的分类问题。
有些只能处理二分类问题,Support Vector Machine classifiers or Linear classifiers。
OvA
one versus all,如需要分成10类,则给某个样例以10个类的打分,最高者为预测。
OvO
one versus one,n个类,则训练n*(n-1)/2的分类算法,以MNIST为例,训练45个分类器,看那个数值类获胜次数最多。
训练集大小和算法关系不大的情况下使用OVO,大部分二分分类算法用OvA。
多分类样例
用SGD训练一个多类分类算法。当Scikit-learn检测到你用一个二分类算法去训练多分类任务,则会自动使用OvA策略,除了SVM分类算法是用OvO策略的。
sgd_clf.fit(X_train, y_train) # y_train, not y_train_5
sgd_clf.predict([some_digit])
some_digit_scores = sgd_clf.decision_function([some_digit])
print(some_digit_scores)
print(sgd_clf.classes_)
print(np.argmax(some_digit_scores))
cross_val_score(sgd_clf, X_train, y_train, cv=3, scoring="accuracy")指定策略
制定使用ova或者ovo。OneVsOneClassifier or OneVsRestClassifier
from sklearn.multiclass import OneVsOneClassifier
ovo_clf = OneVsOneClassifier(SGDClassifier(random_state=42))
ovo_clf.fit(X_train, y_train)
print(ovo_clf.predict([some_digit]))
print(len(ovo_clf.estimators_))多分类算法
比如随机森林算法,本身就能分成多个类,所以不用ova和ovo策略。
forest_clf.fit(X_train, y_train)
print(forest_clf.predict([some_digit]))
print(forest_clf.predict_proba([some_digit]))
错误分析
y_train_pred = cross_val_predict(sgd_clf, X_train_scaled, y_train, cv=3)
conf_mx = confusion_matrix(y_train, y_train_pred)
conf_mx错误分析可视化
plt.matshow(conf_mx, cmap=plt.cm.gray)
plt.show()移除真确的,只聚焦错误。
row_sums = conf_mx.sum(axis=1, keepdims=True)
norm_conf_mx = conf_mx / row_sums
np.fill_diagonal(norm_conf_mx, 0)
plt.matshow(norm_conf_mx, cmap=plt.cm.gray)
plt.show() 具体错误分析
例如3,5的分类,一共有4中状态,3-3,3-5,5-3,5-5.
cl_a, cl_b = 3, 5
X_aa = X_train[(y_train == cl_a) & (y_train_pred == cl_a)]
X_ab = X_train[(y_train == cl_a) & (y_train_pred == cl_b)]
X_ba = X_train[(y_train == cl_b) & (y_train_pred == cl_a)]
X_bb = X_train[(y_train == cl_b) & (y_train_pred == cl_b)]
def plot_digits(images,images_per_row):
lenth = len(images)
for i in range(lenth):
plt.subplot(images_per_row,images_per_row,i+1)
plt.imshow(images[i].reshape(28, 28), cmap = matplotlib.cm.binary)
plt.show()
plot_digits(X_aa[:25], images_per_row=5)
plot_digits(X_ab[:25], images_per_row=5)
plot_digits(X_ba[:25], images_per_row=5)
plot_digits(X_bb[:25], images_per_row=5)解决办法则需要自己去想了,比如数圈圈数目啊,找特征啊。
Multilabel Classfication
多标签分类,比如一个人脸识别的样例,照片中有3个人,则有3个标签。MNIST为例,算一个大于等于7和基数的标签,这明显有两个标签:大于等于7,基数。用 KNeighborsClassifier算法。
from sklearn.neighbors import KNeighborsClassifier
y_train_large = (y_train >= 7)
y_train_odd = (y_train % 2 == 1)
y_multilabel = np.c_[y_train_large, y_train_odd]
print(y_multilabel)
knn_clf = KNeighborsClassifier()
knn_clf.fit(X_train, y_multilabel)
knn_clf.predict([some_digit])
y_train_knn_pred = cross_val_predict(knn_clf, X_train, y_multilabel, cv=3)
f1_score(y_multilabel, y_train_knn_pred, average="macro")Multioutput Classification
多分类多标签的。就是么某个样例,有多个标签(比如,颜色,大小),每个标签多个分类(颜色有红黄蓝,大小有SML)。模拟这个任务,将噪声加入训练集中,训练一个算法,将加入的噪声去除。
MNIST中,每行784列是0-255的像素灰度值,这个任务中,有784个标签(像素值),每个标签有0-255个分类。
from numpy import random as rnd
noise_train = rnd.randint(0, 100, (len(X_train), 784)) # min max row col
noise_test = rnd.randint(0, 100, (len(X_test), 784))
X_train_mod = X_train + noise_train
X_test_mod = X_test + noise_test
y_train_mod = X_train
y_test_mod = X_test
print(len(X_train_mod))
print(len(X_train))使用KNN算法
knn_clf.fit(X_train_mod, y_train_mod)查看结果
X_train_mod[36000]
clean_digit = knn_clf.predict([X_train_mod[36000]])
plt.imshow(clean_digit.reshape(28,28), cmap = matplotlib.cm.binary)
plt.show()