离线强化学习(Offline RL)系列4:(数据集)Offline数据集特征及对离线强化学习算法的影响
 [更新信息]
[更新信息]
文章信息:Kajetan Schweighofer, Markus Hofmarcher, Marius-Constantin Dinu, Philipp Renz, Angela Bitto-Nemling, Vihang Patil, Sepp Hochreiter: “Understanding the Effects of Dataset Characteristics on Offline Reinforcement Learning”, 2021; arXiv:2111.04714.
本文由ELLIS Unit Linz&LIT AI 实验室的Kajetan Schweighofer以第一作者提出,并发表在NeurIPS 2021的Workshop on Ecological Theory of RL顶会上。这是一篇挺有意思的文章,推荐给大家。
摘要:作者首先提出了5种不同方式的数据集组成方式,并提出了 轨迹质量(Trajectory Quality, TQ) 和 状态-动作对覆盖率(Relative State-Action Coverage, SACo)两种指标,通过实验验证了不同的意义,随后提出了p performace(和百分比性能区分)进行了实验。
1. 问题及背景
Offline RL是一种在fixed数据集上学习的技术,在学习过程中存在诸多的问题,比如unseen state-action pair以及分布distribution shift等。因此也产生了一大堆解决这些问题的算法,诸如BCQ、BEAR、BRAC、REM、CQL、CRR、TD3+BC、IQL、Onestep、AWR、AWAC、R-BVE、BVE、QRDQN、MCE等,然而这些算法主要应用在最经典的Offline RL数据集上,主要包括由伯克利公开的D4RL、DeepMind公开的Unplugged,在离散和连续动作方面的组成不一样,衡量指标也不一样,造成了一千个研究者一千个评价指标。
在之前的博文中曾提过,不同的数据集的特性不同,组成不同,数据集的覆盖范围不同等造成了即使同一种算法其性能也天壤之别。本文作者提出了数据集的构成方式,主要包括 Random Dataset、Expert Dataset、Mixed Dataset、Noisy Dataset、Replay Dataset,同时提出了衡量数据的两个指标(evaluation metric): TQ和SACo, 并对相关内容进行了实验。
2. 数据制作与对比
2.1 数据集制作方法与对比
本文作者提出了5种数据集组成,有的以前有,有的是新添的。
2.1.1 Random Dataset
这个数据集是使用一个选择随机的固定策略生成,主要用于CQL算法中的评估。可以理解为它是数据收集的一个最简单的基线。
2.1.2 Expert Dataset
训练一个在线(online)策略直到收敛,并使用该策略生成所有样本,无需探索。
2.1.3 Mixed Dataset
混合数据集是使用随机数据集(20%)和专家(Pre-Policy data)数据集(80%)的混合数据集生成的。(此处的2:8比例估计是经验比例)
2.1.4 Noisy Dataset
噪声数据集是由专家策略生成,且该策略选择 ϵ − g r e e d y \epsilon-greedy ϵ−greedy ( ϵ = 0.2 \epsilon=0.2 ϵ=0.2 )贪婪操作
2.1.5 Replay Dataset
该数据集是在线(online)策略在训练期间生成的所有样本的集合,因此有多个策略生成了数据。
2.2 与其他算法使用数据的区别
2.2.1 与BCQ熟用数据集的区别
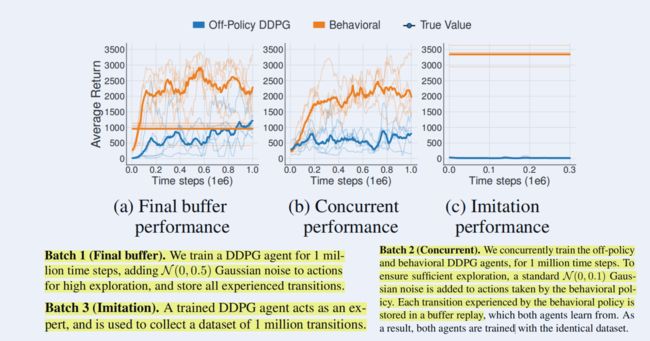
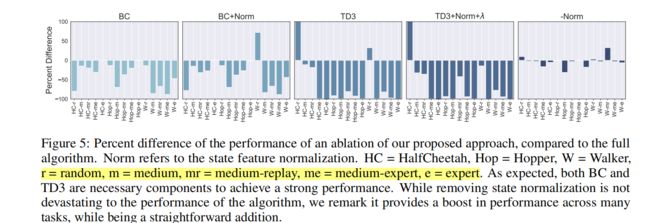
2.2.2 与TD3+BC使用数据集的区别
(TD3+BC中使用了也是5种,如下图所示)
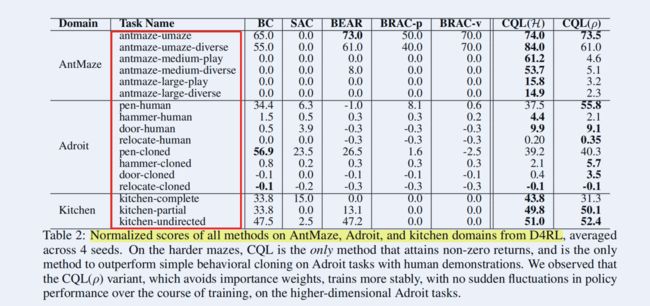
2.2.3 与CQL使用数据集的区别
CQL主要使用了D4RL的数据集格式
3 评价指标: TQ & SACo
3.1 两种指标
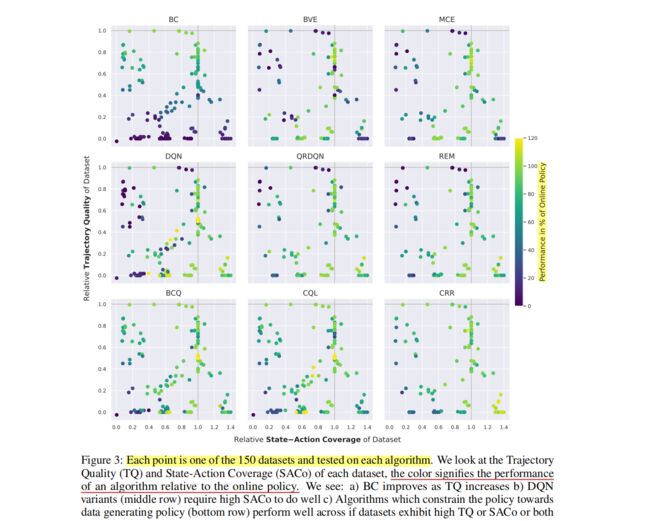
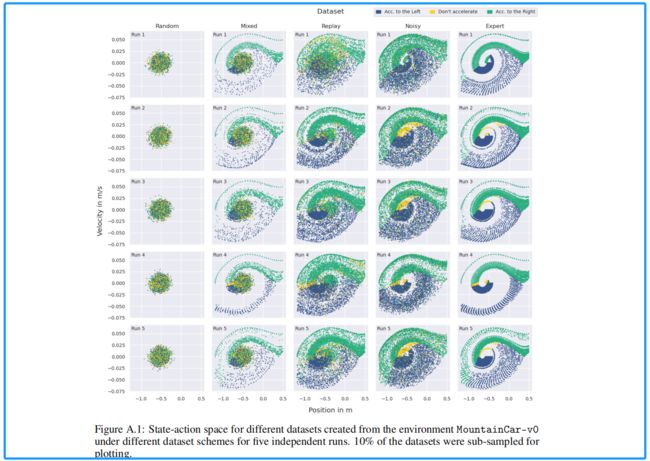
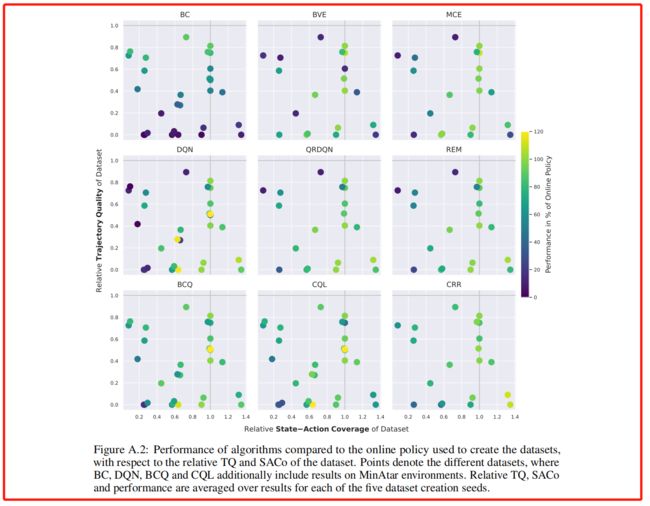
其实上述数据与其他本质不同在于,利用不同的策略(随机、专家等)尽可能全的生成覆盖状态空间和状态分布的数据集。这里作者提出了两个新的概念:轨迹质量和状态-动作对覆盖范围, 并用图进行了解释。
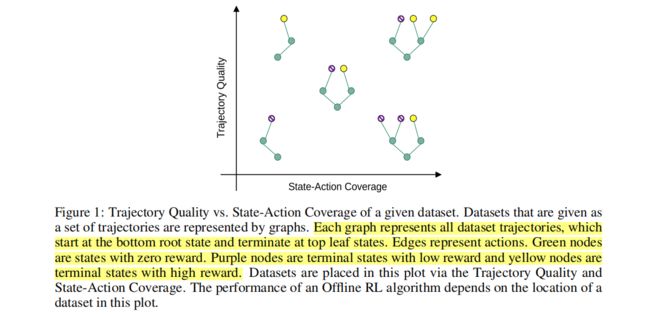
个人理解: 高奖励的长轨迹,多状态空间的pair
作者是这样定义的:
轨迹质量(Trajectory Quality,TQ): 为数据集中包含的轨迹与最大可能返回相比的平均返回。
状态-动作对覆盖范围(State-Action Coverage, SACo): 为每个数据集中唯一的状态-动作对的数量与所有状态-动作对的数量的比值。
3.1.1 TQ(Relative Trajectory Quality,轨迹质量)
g D norm = g D − g m i n g max − g min g_{\mathcal{D}_{\text {norm }}}=\frac{g_{\mathcal{D}}-g_{\mathrm{min}}}{g_{\max }-g_{\min }} gDnorm =gmax−gmingD−gmin
其中
\begin{align}
g_{D} = \text{is the average return of the dataset} \
g_{\min }=\operatorname{minimum}\left(g_{\text {online }}, g_{\text {random }}\right) \
g_{\max }=\operatorname{maximum}\left(g_{\mathrm{online}}, g_{\text {random }}\right)
\end{align}
这里作者给出了具体数据集的 g max g_{\max } gmax 和 g min g_{\min } gmin 的计算数据:
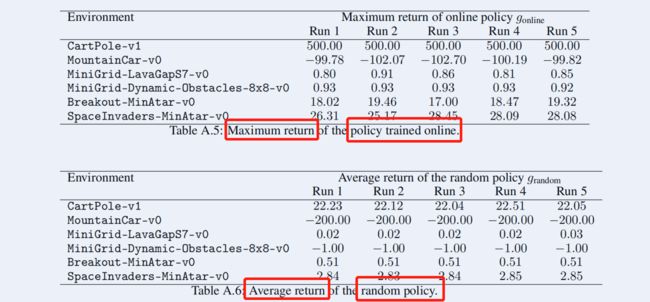
同时也给出了运行中的 g D g_{D} gD
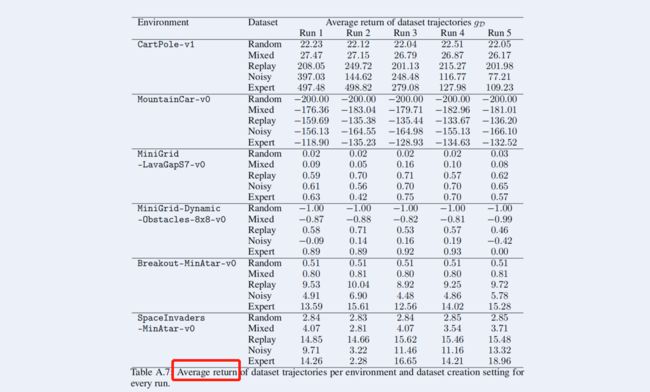
3.1.2 SACo(Relative State-Action Coverage, 状态-动作对覆盖范围)
u D nom = u D u replay u_{\mathcal{D}_{\text {nom }}}=\frac{u_{\mathcal{D}}}{u_{\text {replay }}} uDnom =ureplay uD
由于数据集特别大,不可能直接去hash方式去计算,于是作者直接用了HyperLogLog的概率计算方法

这里给出了 u D u_{\mathcal{D}} uD 的参数,然而 u replay u_{\text {replay }} ureplay 在论文了我没找到,不知道作者咋整的。
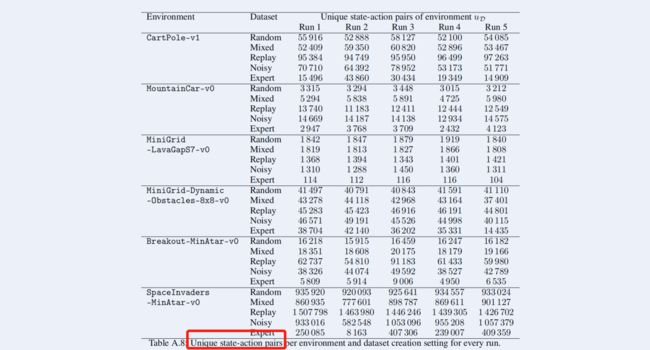
3.1.3 总结
这条结论很好理解:


上述是作者描述的指标,本图是使用不同算法来显示的TQ和SACo之,并得到了3条结论。
3.2 P指标(performance)
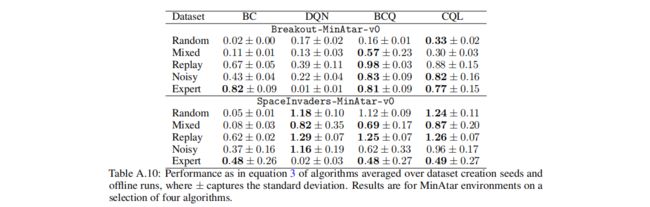
本文作者总共使用了9种算法进行实验,并通过以下计算过程衡量效果:
p = g offline − g min g max − g min p=\frac{g_{\text {offline }}-g_{\min }}{g_{\max }-g_{\min }} p=gmax−gmingoffline −gmin

其中的 g offline g_{\text {offline }} goffline 如下所示:
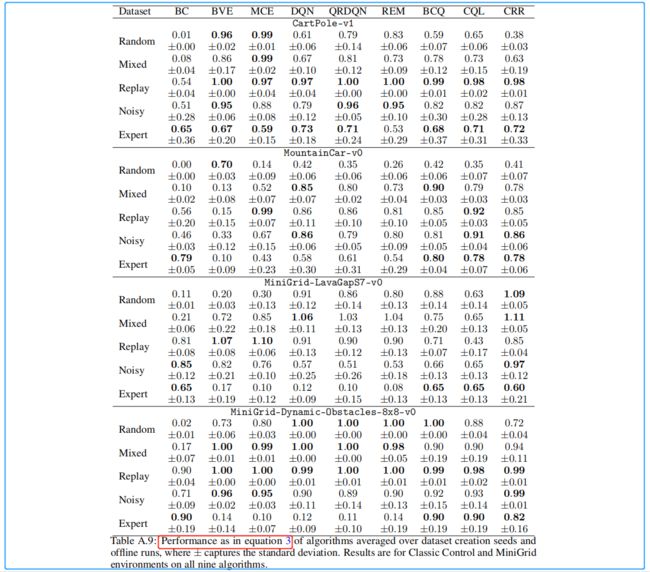
3.3 补充(百分比性能)

【参考】 离线强化学习(Offline RL)系列3: (算法篇) TD3+BC 算法详解与实现(经验篇)
4. 实验与分析总结

参考文献
[1]. Kajetan Schweighofer, Markus Hofmarcher, Marius-Constantin Dinu, Philipp Renz, Angela Bitto-Nemling, Vihang Patil, Sepp Hochreiter: “Understanding the Effects of Dataset Characteristics on Offline Reinforcement Learning”, 2021; arXiv:2111.04714.
[2]. Understanding the Effects of Dataset Characteristics
on Offline Reinforcement Learning.Code
OfflineRL推荐阅读
离线强化学习(Offline RL)系列3: (算法篇) AWR(Advantage-Weighted Regression)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) Onestep 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) IQL(Implicit Q-learning)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) CQL 算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇) TD3+BC 算法详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇) REM(Random Ensemble Mixture)算法详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BRAC算法原理详解与实现(经验篇)
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BEAR算法原理详解与实现
离线强化学习(Offline RL)系列3: (算法篇)策略约束 - BCQ算法详解与实现
离线强化学习(Offline RL)系列2: (环境篇)D4RL数据集简介、安装及错误解决
离线强化学习(Offline RL)系列1:离线强化学习原理入门