【论文笔记:Progressive Feature Alignment for Unsupervised Domain Adaptation 2019 CVPR】
Progressive Feature Alignment for Unsupervised Domain Adaptation
- 概览
-
- 动机
- PFAN结构图
- 理论分析插图
- 实验结果
- 1. Introduction
- 2. Related Work
- 3. Progressive Feature Alignment Network
-
- 3.1. Task Formulation
- 3.2.Easy-to-Hard Transfer Strategy
- 3.3. Adaptive Prototype Alignment
- 3.4. Training Losses
- 3.5. Theoretical Analysis
- 4. Experiments
-
- 4.1. Datasets and Baselines
- 4.2. Implementation Details
- 5. Conclusion
用于无监督领域自适应的渐进式特征对齐
Published in: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
论文链接
概览
UDA: 标签丰富的源域到一个完全未标记的目标域。
Recent Approaches: 伪标签进行判别性域迁移,以强制跨源域和目标域的类级(class-level)分布对齐。
Existing Problem: 因为伪标签的准确性没有得到明确的保证,这些方法容易受到误差积累的影响,因此无法保持跨域类别的一致性。
Proposed Method: Progressive Feature Alignment Network (PFAN) 渐进式特征对齐网络(PFAN),通过利用目标域的类内变化,逐步有效地对齐跨域的判别性的特征。具体来说,首先,开发了一个由易到难的迁移策略(EHTS)和一个自适应原型对齐(APA)步骤来迭代和交替地训练模型。此外,在观察到一个良好的域自适应通常需要一个非饱和的源分类器后,考虑了一种简单而有效的方法,通过进一步将==温度变化(temperature variate)==纳入soft-max函数来延迟源分类损失的收敛速度。
动机
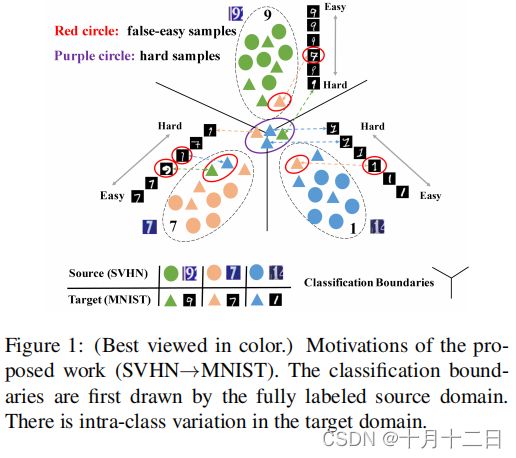
分类边界首先由完全标记的源域绘制,在目标域中存在类内的变异。
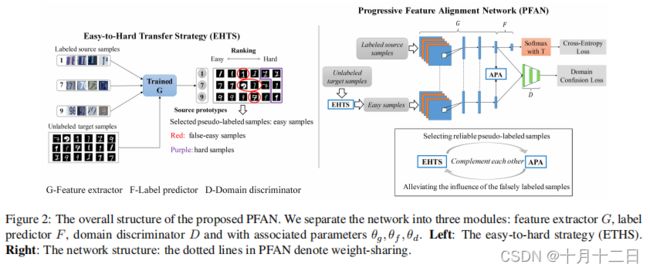
PFAN结构图
将网络分为三个模块:特征提取器 G G G、标签预测器 F F F、域鉴别器 D D D和相关参数 θ g 、 θ f 、 θ d θ_g、θ_f、θ_d θg、θf、θd。==左图:==由易到难的策略(ETHS)。==右图:==网络结构:PFAN中的虚线表示权重共享。
complement:补充 alleviate:减轻
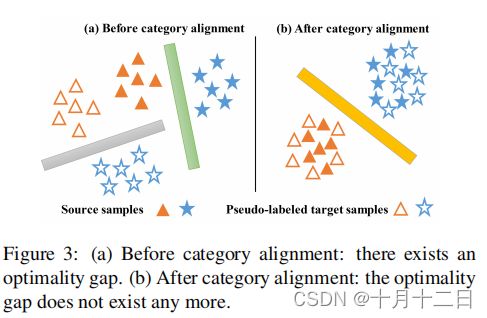
理论分析插图
(a)假设在没有实现类别对齐的情况下,即在类别对齐之前:源域标记函数 f S f_S fS和伪标签函数 f T ^ f_{\hat \mathcal{T} } fT^存在一个最优性差距。(b)类别对齐后:最优性差距不再存在。
实验结果
A.
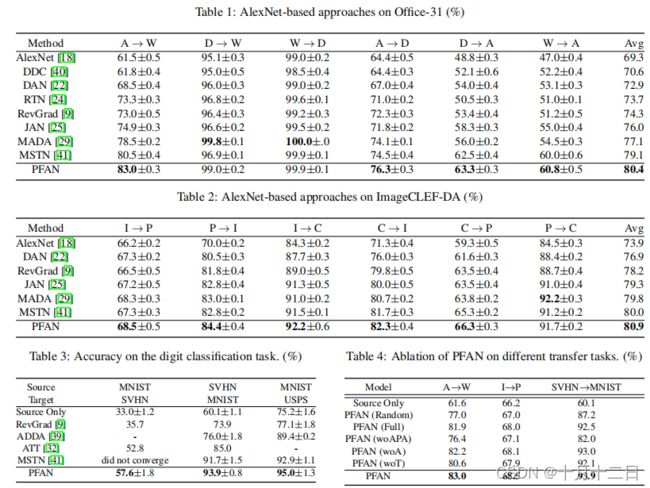
B.

(a)不同温度设置下源分类损失的收敛速度。(b)分布的差异。©-(d)由RevGrad和PFAN生成的目标域 W 上的网络激活的t-SNE可视化。(之前很多方法会画出具有源域和目标域的t-SNE)
C.

迁移任务A→W的伪标记精度和测试精度的比较。伪标记精度使用(正确标记样本的数量)/(标记样本的数量)计算。
1. Introduction
拥有大规模标记数据集是深度卷积神经网络(CNNs)最近取得成功的原因之一。然而,在不同的领域中收集和注释大量的样本是一个极其昂贵和耗时的过程。同时,在一个大数据集上训练的传统CNNs也显示出由于数据偏差或漂移产生的较低的水平泛化能力。无监督域自适应(UDA) 方法通过将知识从一个标签丰富的源域迁移到一个完全未标记的目标域来解决上述问题。深度UDA方法,通常寻求共同实现小的源泛化误差和跨域分布差异,取得了显著的性能。
之前的大多数工作都集中在匹配全局源数据分布和目标数据分布,以学习领域不变的表示。然而,学习到的表示不仅使源和目标域更接近,而且将不同类标签的样本混合在一起。在最近的研究中,开始考虑学习目标领域的区别性表征。具体来说,其中一些提出使用伪标签来学习目标判别表示,这鼓励了目标域中类之间的低密度分离。
这些方法面临着两个关键的限制。
- 首先,他们需要一个很强的预先假设,即正确的伪标记样本可以减少错误伪标记样本引起的偏差。然而,满足这个假设是非常具有挑战的,特别是当域差异很大时。学习到的分类器可能无法自信地区分目标样本,或者无法用预期的精度要求对其精确地伪标记它们。
- 其次,他们基于伪标记样本对目标样本的类别损失进行反向传播,使目标性能容易受到误差积累的影响。
在探索过程中,本文通过经验观察了目标领域的不同数据模式。其动机如图1所示。 类内分布变化(variance)存在于目标域中。一些目标样本,称之为简单样本(easy samples),由于它们与源域足够接近,所以很有可能被正确分类,可以直接给它们分配伪标签,而不需要任何适应。一些目标样本,称之为困难样本(hard samples),离源域很远,它们的分类边界是模糊的。此外,一些容易的样本,称之为假容易的样本(false-easy samples),位于非对应的源类别的支持范围内,很容易被高置信度的伪标签所误导。这些虚假标记的样本在类别排列中引入了错误的信息,并有可能导致错误的累积。因此,在UDA的背景下,减轻它们的负面影响是先决条件。
本文工作
在本文中,提出了一个渐进的特征对齐网络(PFAN),它通过显式地强制执行类别对齐,在很大程度上扩展了先验的基于判别性表示的方法的能力。首先,采用==由易到难的迁移策略(EHTS)根据跨域相似度量逐步选择可靠的伪标记目标样本。但是,所选的样本可能包含一些分类错误的目标样本。然后,为了抑制错误标记样本的负面影响,提出了一种自适应原型对齐(APA)==来对齐每个类别的源原型和目标原型。本文的工作不是基于伪标记样本反向传播目标样本的类别损失,而是基于源样本和所选择的伪标记目标样本的跨域类别分布。EHTS和APA不断迭代更新,其中EHTS通过提供可靠的伪标记样本,提高了APA的鲁棒性,而APA学习到的跨域类别对齐可以有效缓解EHTS引入的错误标记样本 。此外,在观察到一个良好的自适应模型通常需要一个非饱和的源分类器后,考虑了一种简单而有效的方法,通过进一步将温度变化纳入软最大函数来延迟源分类损失的收敛速度。实验结果表明,所提出的PFAN在三个UDA数据集上超过了最先进的性能。
2. Related Work
受生成对抗网络(GAN)最近成功的启发,深度对抗域适应在学习域不变表示方面受到越来越多的关注,以减少域差异并提供了显著的结果。这些方法试图找到一个特征空间,使该空间中源分布和目标分布之间的混淆最大。例如,提出了一个梯度反转层来训练一个特征提取器,该特征提取器产生最大限度的域二值分类器损失,同时最小化标签预测器损失。
许多方法利用距离度量来度量源域和目标域之间的域差异,如最大平均差异(MMD)、KL散度或瓦瑟斯坦距离。大多数之前的努力都是为了通过匹配 P ( X s ) P(X_s) P(Xs)和 P ( X t ) P(X_t) P(Xt)来实现域对齐。然而,精确的域级对齐并不意味着细粒度的类间重叠。因此,在没有目标真实标签的情况下,追求类别级(category-level)对齐是很重要的。
利用伪标签来弥补目标域中分类信息的缺失。使用修正后的MMD联合匹配了边际分布和条件分布。利用非对称 tri-training策略来学习目标域的判别表示。基于前一个训练时期的分类器,迭代选择伪标记的目标样本,并利用扩大的训练集对模型进行重新训练。提出了为所有目标样本分配伪标签,并利用它们来实现跨域的语义对齐。然而,这些方法高度依赖于正确的伪标记样本可以减少错误的伪标记样本所引起的偏差的假设。它们并没有明确地减轻那些错误的伪标记样本。当错误的伪标记样本处于突出的位置时,其性能将受到限制。
3. Progressive Feature Alignment Network
本节中,首先提供所提出的PFAN的细节,然后从理论上研究方法的有效性。
PFAN的整体架构如图2所示,它由EHTS、APA和随温度变化的soft-max函数三个组件组成。EHTS为从容易到困难的迭代提供了可靠的伪标签样本和APA明确地强制执行跨域类别对齐。

3.1. Task Formulation

3.2.Easy-to-Hard Transfer Strategy
EHTS偏向于更容易的样本,这种偏差有助于避免包括更有可能被给予错误的伪标签的困难样本(hard samples)。在本文的方法中,简单的样本正在逐渐增加。因此,“硬”样本可能会在进一步的步骤中被选择。EHTS所选择的伪标记样本可以与相应的源类别对齐,如第3.3节所述。
EHTS首先计算源域中每个类的 D D D维原型 c k S {c_k}^S ckS ∈ R D ∈R^D ∈RD。源原型是嵌入每类源样本的平均向量,通过嵌入函数G(即图2中的特征提取器)的平均向量,源原型是通过具有可训练参数 θ g θ_g θg的嵌入函数 G G G(即图2中的特征提取器)在每个源样本类别中嵌入的平均向量,

其中, D s k {D_s}^k Dsk为源域中标记为 k k k类的样本集, N s k {N_s}^k Nsk为对应的样本数。然后,得到一组原型集合 { c k S } C k = 1 {\{{c_k}^S\}^C}_{k=1} {ckS}Ck=1。嵌入的目标样本应该聚集在潜在特征空间中的源原型周围。因此,使用相似度度量 ψ ψ ψ将第 j j j个未标记的目标样本 x t j {x_t}^j xtj聚类到相应的源原型中,其中 ψ ψ ψ计算如下:
![]()
其中 C S ( . , . ) CS(.,.) CS(.,.)表示两个向量之间的余弦相似度函数。 x t j {x_t}^j xtj通过一个伪标签 y ^ j t = k ′ {{\hat y}_j}^{t}=k' y^jt=k′添加到类 D t k ′ {D_t}^{k'} Dtk′的目标域中,其中 k ′ = arg max k ψ k ( x j t ) k'=\arg \max _{k} \psi_{k}\left(x_{j}^{t}\right) k′=argmaxkψk(xjt)。然后,将未标记的目标样本 D t D_t Dt划分为 C C C类(i.e. D t = { D t k } k = 1 C = { x j t , y ^ j t } j = 1 n t ) \left.D_{t}=\left\{D_{t}^{k}\right\}_{k=1}^{C}=\left\{x_{j}^{t}, \hat{y}_{j}^{t}\right\}_{j=1}^{n_{t}}\right) Dt={Dtk}k=1C={xjt,y^jt}j=1nt)),每个样本都根据其相似性进行评分。为了获得“简单”的样本,限制相似度得分应该高于一定的阈值 τ τ τ。在训练过程中,随着训练的进行,由于源样本和目标样本在隐藏空间中的距离越来越近,相似度 ψ ψ ψ的值不断增加。早期阶段的“硬”样本在后期阶段可能被选择为“容易”。然而,恒定的阈值会在每个步骤中将太多的“硬”样本变成“容易”的样本。为了控制“简单”样本的生长速率,逐步逐步调整阈值如下:
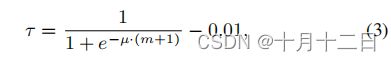
其中, µ µ µ为一个常数, m ( m = 0 , 1 , 2 , … … ) m(m={0,1,2,……}) m(m=0,1,2,……)表示训练步骤。因此,样本选择函数的表述如下,
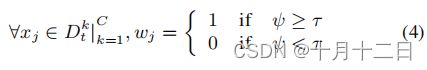
其中 w j = 1 w_j=1 wj=1表示选择 x j x_j xj,否则 w j = 0 w_j=0 wj=0表示不选择 x j x_j xj。最后,得到一个选定的伪标记目标域 D ^ t = { x j t , y ^ j t } j = 1 n t ) \left.{\hat D}_{t}=\left\{x_{j}^{t}, \hat{y}_{j}^{t}\right\}_{j=1}^{n_{t}}\right) D^t={xjt,y^jt}j=1nt),其中 n ^ t {\hat n}_t n^t表示所选择的样本数量。
3.3. Adaptive Prototype Alignment
在本节中,将介绍所提出的APA,它考虑了跨域的成对语义相似性以明确地减轻那些假容易样本(false-easy samples)的负面影响,并加强跨域类别的一致性。它可以通过对齐每个类别的源样本的原型和选择的目标样本来实现。测量两个原型之间的距离如下:

c k S {c_k}^S ckS和 c k T {c_k}^T ckT分别表示源原型和目标原型。选择平方欧氏距离作为距离度量函数。证明是,当使用布雷格曼散度(例如,平方欧氏距离和马氏距离)时,聚类均值产生最优的聚类代表。原型对齐的一种可选方法是基于在每次迭代中从 D s D_s Ds和 D ^ t {\hat D}_t D^t中采样的小批量来计算和对齐局部原型。然而,这种方法处于一个弱点,因为每个小批中的分类信息预计不足,即使是目标小批中的一个错误标记的样本也可能会导致计算原型和真实原型之间的巨大偏差。
为了克服上述问题,我们建议自适应地对齐全局原型。APA首先根据所选的伪标记目标样本 D ^ t {\hat D}_t D^t计算初始全局原型,如下:

在每次迭代中,我们使用小批样本计算一组本地原型 { c k t } k = 1 C \left\{c_{k}^{t}\right\}_{k=1}^{C} {ckt}k=1C。累积的原型被计算为每次迭代中所有之前的局部原型的平均值,

其中, I I I表示当前训练步骤中的迭代次数。然后,将新的 c k T {c_k}^T ckT更新如下:

其中, C S ( . , . ) CS(.,.) CS(.,.)表示等式(2)中定义的余弦距离, ρ ρ ρ是权衡参数。让 c k ( I ) S {c_{k(I)}}^S ck(I)S对源域进行类似的更新。为此,APA损失的公式如下:
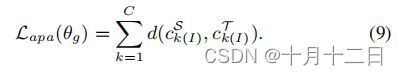
APA的动机是直观的:1)引入累积的原型来估计错误标记样本引起的累积漂移,然后利用它们与之前的全局原型的相似性来决定新的全局原型 c k T {c_{k}}^T ckT;2)统计对齐跨域类别分布,这可以减轻伪标签的误差积累。
3.4. Training Losses
在这项工作中,通过经验发现,一个好的适配器需要一个非饱和的源分类器。这一实证结果得到了第3.5节中描述的理论分析的支持。理由是,自适应模型偏向于最小化源分类损失,由于源真标签可用,这通常收敛迅速。然而,这种偏差可能会导致对源样本的过拟合,并导致有限的目标性能。受[15]的启发,我们建议在源分类器中添加一个高温变量 T ( T > 1 ) T(T>1) T(T>1)(如图2所示)。这样就可以延缓源分类损失的收敛速度,有效地引导适配器获得更好的自适应性能。我们通过以下的softmax功能来实现这个行为,

其中 q i q_i qi表示源样本的类概率, z z z为源分类器产生的 l o g i t logit logit。对 T T T使用较高的值会产生较软的输出,并自然地阻碍收敛速度。
通过提取域不变特征,将对抗学习成功地引入UDA,以实现域对齐。然而,学习到的表示并不能确保类别对齐,这也是性能下降的主要来源。因此,本文的工作同时考虑了领域级和类别级的对齐。
在PFAN中,输入 x x x首先由 G G G嵌入到一个二维特征向量 f ∈ R D f∈{R^D} f∈RD中,即 f = G ( x ; θ g ) f=G(x;θ_g) f=G(x;θg) 。为了使 f f f是域不变的,特征提取器 G G G的参数 θ g θ_g θg期望通过最大化域鉴别器D的损失来进行优化,而域鉴别器D的参数 θ d θ_d θd训练通过最小化域鉴别器损失,,该鉴别器根据标准的分类损失进行了优化:
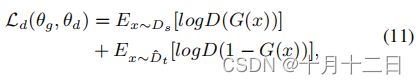
此外,还需要同时最小化有标记源样本的标签预测器 F F F的损失和APA的损失。
在形式上,我们的最终目标是优化以下极大极小目标:
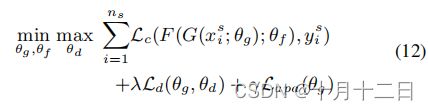
其中 L c L_c Lc为标准交叉熵损失, λ λ λ和 γ γ γ为控制源分类损失、域混淆损失和APA损失之间相互作用的权重。训练PFAN的伪代码算法1所示,EHTS和APA交替迭代工作。

3.5. Theoretical Analysis
在本节中,从理论上证明了本文的方法改进了目标样本上的期望误差的边界。形式上,假设 H \mathcal{H} H为假设类,并给定两个域 S \mathcal{S} S 和 T \mathcal{T} T,将假设 h h h在目标域上的误差的概率界定义为:

其中,目标样本上的期望误差 R T ( h ) R_{\mathcal{T}}(h) RT(h)由三项限定:(1)为源域上的期望误差 R S ( h ) R_{\mathcal{S}}(h) RS(h);(2) d H ∆ H ( S , T ) dH∆H(\mathcal{S},\mathcal{T}) dH∆H(S,T)是由两个分布 S \mathcal{S} S 和 T \mathcal{T} T w . r . t . w.r.t. w.r.t.之间的差异距离测量的域散度假设集 H \mathcal{H} H;(3)理想联合假设的共同误差 C C C。
在不等式(13)中, R S ( h ) R_{\mathcal{S}}(h) RS(h)被认为是很小的,并且容易通过深度网络进行优化,因为有源标签。另一方面,之前的努力是试图通过基于域分类器的对抗性学习来最小化 d H ∆ H ( S , T ) dH∆H(\mathcal{S},\mathcal{T}) dH∆H(S,T)。然而,一个小的 d H ∆ H ( S , T ) dH∆H(\mathcal{S},\mathcal{T}) dH∆H(S,T)和一个小的 R S ( h ) R_{\mathcal{S}}(h) RS(h)并不能保证小的 R T ( h ) R_{\mathcal{T}}(h) RT(h)。当跨域类别对齐没有被明确地强制执行(即边际分布排列得很好,但类条件分布没有得到保证)时,理想联合假设的共同误差 C C C可能趋于较大。因此, C C C也需要是有界的。不幸的是,不能直接测量 C C C,因为没有目标上的真实标签。因此,利用伪标签来给出近似的求值和最小化。

为了约束理想假设的组合误差,以下不等式成立:

在补充材料中展示了定理1的推导。由于有源标签和目标伪标签,所以很容易在 H \mathcal{H} H中分别找到一个合适的 h h h来近似源域标记函数 f S f_S fS和伪标签函数 f T ^ f_{\hat \mathcal{T} } fT^。然而,我们假设在没有实现类别对齐的时候,源域标记函数 f S f_S fS和伪标签函数 f T ^ f_{\hat \mathcal{T} } fT^之间存在一个最优性差距(图3(a))。而现有的方法没有考虑这种现象,直接最小化 R S ( h , f S ) R_S(h,fS) RS(h,fS),导致对源样本的过拟合。

回想一下,标记函数 f f f可以分解为特征提取器 G G G和标签分类器 F F F。通过考虑 R T ′ R_{T'} RT′的0-1损失函数 σ σ σ,有
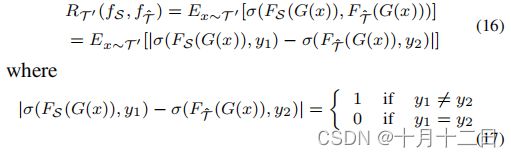

4. Experiments
4.1. Datasets and Baselines

4.2. Implementation Details

5. Conclusion
在本文中,提出了一种新的渐进特征对齐网络方法,利用目标域类内变化和跨域类别一致性来解决UDA问题。所提出的EHTS和APA在选择可靠的伪标记样本方面相互补充,减轻了错误标记样本造成的偏差。通过降低源分类损失的收敛速度,进一步提高了该性能。
[15] Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015.