机器学习-线性回归方法之最小二乘法和梯度下降法
最近刚开始学机器学习里面的线性回归~也是第一次接触python 参考了网上的一些内容和自己的理解做了以下整理~希望可以帮助到你
1线性回归(Linear Regression):
拟合出一个线性组合关系的函数,尽可能拟合所有数据点。
 x+b,找到一条直线,所有样本点到直线的距离之和最小。
1x1+
2x2+
3x3...+
0,找到一个超平面来拟合样本点。
+
x+b,找到一条直线,所有样本点到直线的距离之和最小。
1x1+
2x2+
3x3...+
0,找到一个超平面来拟合样本点。
+

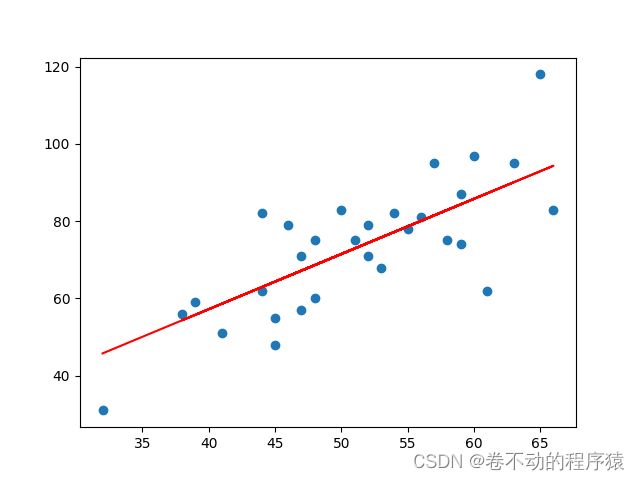
如何判断模型与观测点是最佳拟合呢?“误差的平方和最小”估计出来的模型是最接近真实情形的。
2求解方法:
1最小二乘法(least square method)
(4条消息) 一文让你彻底搞懂最小二乘法(超详细推导)_胤风的博客-CSDN博客_最小二乘法 https://blog.csdn.net/MoreAction_/article/details/106443383
https://blog.csdn.net/MoreAction_/article/details/106443383

例1:通过公式计算出(y=wx+b)w和b,再由误差函数(平方损失函数平均值)计算出误差
import numpy as np
import matplotlib.pyplot as plt
# ---------------1. 准备数据----------
data = np.array([[32,31],[53,68],[61,62],[47,71],[59,87],[55,78],[52,79],[39,59],[48,75],[52,71],
[45,55],[54,82],[44,62],[58,75],[56,81],[48,60],[44,82],[60,97],[45, 48],[38,56],
[66,83],[65,118],[47,57],[41,51],[51,75],[59,74],[57,95],[63,95],[46,79],[50,83]])
# 提取data中的两列数据,分别作为x,y
x = data[:, 0]
y = data[:, 1]
# 用plt画出散点图
#plt.scatter(x, y)
#plt.show()
# -----------2. 定义损失函数------------------
# 损失函数是系数的函数,另外还要传入数据的x,y
def compute_cost(w, b, points):
total_cost = 0
M = len(points)
# 逐点计算平方损失误差,然后求平均数
for i in range(M):
x = points[i, 0]
y = points[i, 1]
total_cost += (y - w * x - b) ** 2
return total_cost / M
# ------------3.定义算法拟合函数-----------------
# 先定义一个求均值的函数
def average(data):
sum = 0
num = len(data)
for i in range(num):
sum += data[i]
return sum / num
# 定义核心拟合函数
def fit(points):
M = len(points)
x_bar = average(points[:, 0])
sum_yx = 0
sum_x2 = 0
sum_delta = 0
for i in range(M):
x = points[i, 0]
y = points[i, 1]
sum_yx += y * (x - x_bar)
sum_x2 += x ** 2
# 根据公式计算w
w = sum_yx / (sum_x2 - M * (x_bar ** 2))
for i in range(M):
x = points[i, 0]
y = points[i, 1]
sum_delta += (y - w * x)
b = sum_delta / M
return w, b
# ------------4. 测试------------------
w, b = fit(data)
print("w is: ", w)
print("b is: ", b)
cost = compute_cost(w, b, data)
print("cost is: ", cost)
# ---------5. 画出拟合曲线------------
plt.scatter(x, y)
# 针对每一个x,计算出预测的y值
pred_y = w * x + b
plt.plot(x, pred_y, c='r')
plt.show()2梯度下降法(gradient descent)
主要有三种梯度下降方法
1Batch Gradient Descent 批量梯度下降
2Stochastic Gradient Descent 随机梯度下降
3Mini-batch Gradient Descent 小批量梯度下降(BGD和SGD的折中)
2.1对比最小二乘法和梯度下降法
| 方法 | 最小二乘法 | 梯度下降法 |
| 损失函数 | 平方损失函数 | 可以选取其他损失函数 |
| 实现方法 | 直接求导找出全局最小值 | 迭代 |
| 结果 | 能求解则为全局最小值;但计算繁琐,复杂情况下不一定有解 | 找到一般为局部最小,目标函数凸函数时为全局最小,迭代计算简单,但对初始点选择敏感 |
import numpy as np
import matplotlib.pyplot as plt
# 准备数据
data = np.array([[32, 31], [53, 68], [61, 62], [47, 71], [59, 87], [55, 78], [52, 79], [39, 59], [48, 75], [52, 71],
[45, 55], [54, 82], [44, 62], [58, 75], [56, 81], [48, 60], [44, 82], [60, 97], [45, 48], [38, 56],
[66, 83], [65, 118], [47, 57], [41, 51], [51, 75], [59, 74], [57, 95], [63, 95], [46, 79],
[50, 83]])
x = data[:, 0]
y = data[:, 1]
# --------------2. 定义损失函数--------------
def compute_cost(w, b, data):
total_cost = 0
M = len(data)
# 逐点计算平方损失误差,然后求平均数
for i in range(M):
x = data[i, 0]
y = data[i, 1]
total_cost += (y - w * x - b) ** 2
return total_cost / M
# --------------3. 定义模型的超参数------------
alpha = 0.0001
initial_w = 0
initial_b = 0
num_iter = 10
# --------------4. 定义核心梯度下降算法函数-----
def grad_desc(data, initial_w, initial_b, alpha, num_iter):
w = initial_w
b = initial_b
# 定义一个list保存所有的损失函数值,用来显示下降的过程
cost_list = []
for i in range(num_iter):
cost_list.append(compute_cost(w, b, data))
w, b = step_grad_desc(w, b, alpha, data)
return [w, b, cost_list]
def step_grad_desc(current_w, current_b, alpha, data):
sum_grad_w = 0
sum_grad_b = 0
M = len(data)
# 对每个点,代入公式求和
for i in range(M):
x = data[i, 0]
y = data[i, 1]
sum_grad_w += (current_w * x + current_b - y) * x
sum_grad_b += current_w * x + current_b - y
# 用公式求当前梯度
grad_w = 2 / M * sum_grad_w
grad_b = 2 / M * sum_grad_b
# 梯度下降,更新当前的w和b
updated_w = current_w - alpha * grad_w
updated_b = current_b - alpha * grad_b
return updated_w, updated_b
# ------------5. 测试:运行梯度下降算法计算最优的w和b-------
w, b, cost_list = grad_desc( data, initial_w, initial_b, alpha, num_iter )
print("w is: ", w)
print("b is: ", b)
cost = compute_cost(w, b, data)
print("cost is: ", cost)
#plt.plot(cost_list)
#plt.show()
# ------------6. 画出拟合曲线-------------------------
plt.scatter(x, y)
# 针对每一个x,计算出预测的y值
pred_y = w * x + b
plt.plot(x, pred_y, c='r')
plt.show()2.2对比BGD和SGD:
(文字版更详细|表格版简略)
①梯度计算:
BGD每次迭代需计算整个数据集,每次计算所有样本的(成本函数梯度)的和,迭代缓慢。
SGD每次迭代只随机选择样本中某个数据,每次计算一个样本(成本函数的梯度),迭代快速。
②计算成本:
BGD计算缓慢,计算成本高。SGD计算复杂度低(computationally much less expensive),假设数据集中有1亿个样本,BGD每次迭代计算需要使用1亿个样本,而SGD只使用1个样本来计算。
③过程process update:
BGD每步选择较平滑;SGD由于每次选择梯度的随机性(randomness in its descent),需要更高次数的迭代( higher number of iterations)来取得最优值,且收敛路径会更曲折(noisier)见下图。
|
|
|
| 使用BGD的路径 | 使用SGD的路径 |
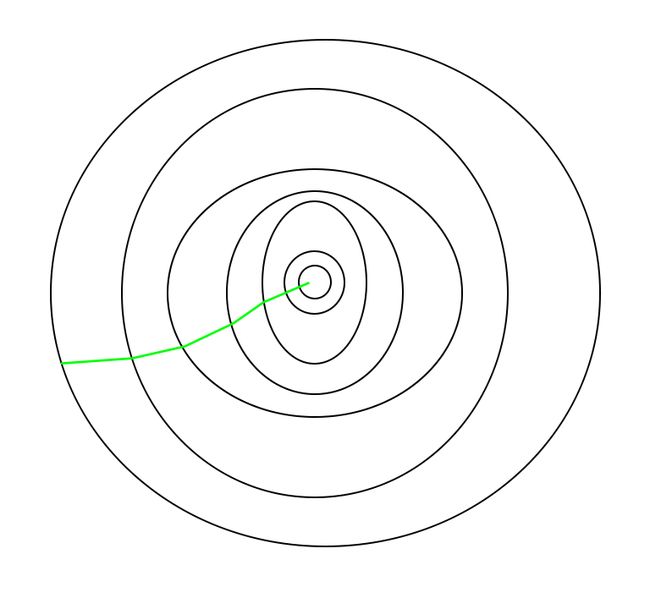

④适用场合:
BGD适合训练样本小时,且不需要数据集样本顺序随机;SGD适合训练样本较大时,需要样本顺序随机。
但是BGD对于凸/相对平滑的误差流形效果很好(convex or relatively smooth error manifolds),且能随着特征数量的增加而扩展。
⑤结果solution:
BGD在收敛时间充足时能够给出最优解;而SGD一旦接近最小值会四处反弹而不安顿下来,因此会给一个模型的较好值而不是最优值,可以通过降低每一步的学习率来尽量解决。
BGD容易陷入局部最小值,SGD不容易陷入局部最小值。
| 类别 | BGD | SGD |
| 1Computes gradient |
用整个样本集计算梯度,迭代缓慢。(whole Training sample) | 用单个样本计算梯度,迭代快速。 (single Training sample) |
| 2computation | 计算缓慢且成本高(slow&expensive ) | 计算快速且成本低 (Faster&less expensive) |
| 3process | 每一步较平滑 | 每一步较随机,波动大 |
| 4suggested occation | 训练样本小;训练集数据无需随机;适用凸/相对平滑的误差流形情况 |
训练样本大(Large training samples);训练集数据样本顺序需随机(in a random order) |
| 5solution | 时间充足可得到最优解 (sufficient time to converge→optimal solution);但容易陷入局部最小值(local minima) |
得到较好解但不是最优解, 不易陷入局部最小值 |
3综合代码示例
3.1:线性回归 BGD SGD
Created on Sun Oct 16 11:23:55 2022
@author: imagine
"""
%matplotlib inline
# import packages
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import time
import warnings
warnings.filterwarnings("ignore")
num_features = 2
theta_ = np.array([1, 1])#2行1列
num_samples = 100
###第一步产生数据X,y##########################X为100*2,y为100*1
def generate_data(num_samples, num_features, scale, function):
# range of x: [-0.5, 0.5]
X = np.random.rand(num_samples, num_features)-0.5#X为100行*2列的矩阵,里面的数据都在-0.5到0.5之间
# X@y is equivalent to np.matmul(X, y)
y = function(X) + np.random.normal(scale=scale, size=(num_samples))#y是100行1列的矩阵,
return X, y
def func1(X):
return X @ theta_ #x为100*2,theta_为2*1,得到return为100*1
X, y = generate_data(num_samples, num_features, 0.2, func1)
###第二步计算 三种方法示例 正态方程法;批量梯度下降法BGD;随机梯度下降法SGD
###################方法一#########################正态方程法方法
def linear_regression(X, y):
return np.linalg.inv((X.transpose()@X))@X.transpose()@y #用梯度求导为0的公式计算出theta
theta_linear_regression = linear_regression(X, y)
print('the estimated parameter using normal equation is {}'.format(theta_linear_regression))
##################方法二##############################BGD方法
theta_linear_regression_2 = np.zeros(num_features) #2行1列
theta_linear_regression_2
max_epoch = 50
alpha = 0.01
# function to compute the error
def LSError(X, y, theta):
return np.linalg.norm(np.matmul(X, theta)-y)
# implementation of batch gradient descent
def BGD(X, y, max_epoch, alpha, theta_linear_regression):
for epoch in range(max_epoch):
# if the least square error is small enough, we can stop the iterative update
if LSError(X, y, theta_linear_regression) <= 1e-5:
break
# each epoch we use whole data to compute the gradient and update the parameter
deriv = np.matmul(np.matmul(X.T, X), theta_linear_regression_2) - np.matmul(X.T, y)
# update the parameter
theta_linear_regression -= alpha* deriv
return theta_linear_regression
BGD(X, y, max_epoch, alpha, theta_linear_regression_2)
theta_linear_regression_2
print('the estimated parameter using BGD is {}'.format(theta_linear_regression_2))
##################方法三##############################SGD方法
theta_linear_regression_3 = np.zeros(num_features) #2行1列
theta_linear_regression_3 = theta_linear_regression_3.reshape(-1,1)
max_epoch = 50
alpha = 0.01
def LSError(X, y, theta):
return np.linalg.norm(np.matmul(X, theta)-y)
def SGD(X, y, max_epoch, alpha, theta_linear_regression):
for epoch in range(max_epoch):
if LSError(X, y, theta_linear_regression) <= 1e-5:
break
# each epoch we use one data to compute the gradient and update the parameter
data1= np.hstack((X, y.reshape((-1, 1))))#水平堆叠 若x为一列,y为一列,则组合起来为两列
np.random.shuffle(data1)#将数据按行进行打乱,一行为一组数据
X_mini=data1[:,:-1]#两列
y_mini=data1[:,-1].reshape(-1,1)#1列
for i in range(X.shape[0]):
x_temp = X_mini[i,:].reshape(1,-1)
y_temp = y_mini[i,:].reshape(1,-1)
deriv = x_temp.T@x_temp@theta_linear_regression_3-x_temp.T@y_temp
# update the parameter
theta_linear_regression -= alpha* deriv
return theta_linear_regression
SGD(X, y, max_epoch, alpha, theta_linear_regression_3)
theta_linear_regression_3
print('the estimated parameter using SGD is {}'.format(theta_linear_regression_3))3.2 MGD 的python代码
# -*- coding: utf-8 -*-
"""
Created on Sat Oct 15 15:04:14 2022
@author: imagine
"""
# 1第一步importing dependencies 导入依赖关系,为线性回归生成数据并将数据可视化
import numpy as np
import matplotlib.pyplot as plt
# 1.1creating data
mean = np.array([5.0, 6.0])
cov = np.array([[1.0, 0.95], [0.95, 1.2]])
data = np.random.multivariate_normal(mean, cov, 8000) #8000个数据例子,每个例子有两个属性
# 1.2visualising data
plt.scatter(data[:500, 0], data[:500, 1], marker='.')
plt.show()
# 1.3train-test-split,训练集数据拆分,进一步分为训练集(X_train,y_train)7200个和测试集(X_test,y_test)800个
data = np.hstack((np.ones((data.shape[0], 1)), data))
split_factor = 0.90
split = int(split_factor * data.shape[0])
X_train = data[:split, :-1]
y_train = data[:split, -1].reshape((-1, 1))
X_test = data[split:, :-1]
y_test = data[split:, -1].reshape((-1, 1))
print('Number of examples in training set= ' ,(X_train.shape[0]))
print('Number of examples in testing set=' , (X_test.shape[0]))
# linear regression using "mini-batch" gradient descent
# function to compute hypothesis / predictions
def hypothesis(X, theta):
return np.dot(X, theta)
# function to compute gradient of error function w.r.t. theta
def gradient(X, y, theta):
h = hypothesis(X, theta)
grad = np.dot(X.transpose(), (h - y))
return grad
# function to compute the error for current values of theta
def cost(X, y, theta):
h = hypothesis(X, theta)
J = np.dot((h - y).transpose(), (h - y))
J /= 2
return J[0]
# function to create a list containing mini-batches
def create_mini_batches(X, y, batch_size):
mini_batches = []
data = np.hstack((X, y))#水平堆叠 若x为一列,y为一列,则组合起来为两列
np.random.shuffle(data)#将数据按行进行打乱,一行为一组数据
n_minibatches = data.shape[0] // batch_size #data.shape[0]行数 data.shape[1]是列数.//表示返回商的整数部分,小的那个
i = 0
for i in range(n_minibatches + 1): #range(3)即将0-3赋值给i 不包含3
mini_batch = data[i * batch_size:(i + 1)*batch_size, :]
X_mini = mini_batch[:, :-1]
Y_mini = mini_batch[:, -1].reshape((-1, 1))#reshape将Y_mini变成一列,行数由系统自动计算生成,-1为模糊变量
mini_batches.append((X_mini, Y_mini))#append表示向mini_batches末尾追加元素
if data.shape[0] % batch_size != 0:
mini_batch = data[i * batch_size:data.shape[0]]
X_mini = mini_batch[:, :-1]
Y_mini = mini_batch[:, -1].reshape((-1, 1))
mini_batches.append((X_mini, Y_mini))
return mini_batches #某些x y的值选中
# function to perform mini-batch gradient descent
def gradientDescent(X, y, learning_rate=0.001, batch_size=32):
theta = np.zeros((X.shape[1], 1))
error_list = []
max_iters = 3
for itr in range(max_iters):
mini_batches = create_mini_batches(X, y, batch_size)
for mini_batch in mini_batches:
X_mini, y_mini = mini_batch
theta = theta - learning_rate * gradient(X_mini, y_mini, theta)
error_list.append(cost(X_mini, y_mini, theta))
return theta, error_list
theta, error_list = gradientDescent(X_train, y_train)
print("Bias = ", theta[0])
print("Coefficients = ", theta[1:])
# visualising gradient descent
plt.plot(error_list)
plt.xlabel("Number of iterations")
plt.ylabel("Cost")
plt.show()
# predicting output for X_test
y_pred = hypothesis(X_test, theta)
plt.scatter(X_test[:, 1], y_test[:, ], marker='.')
plt.plot(X_test[:, 1], y_pred, color='orange')
plt.show()
# calculating error in predictions
error = np.sum(np.abs(y_test - y_pred) / y_test.shape[0])
print('Mean absolute error =', error)资料参考来源:
1.ML | Stochastic Gradient Descent (SGD) - GeeksforGeeks
2.Difference between Batch Gradient Descent and Stochastic Gradient Descent - GeeksforGeeks
3.
机器学习之线性回归算法Linear Regression(python代码实现)_卷不动的程序猿的博客-CSDN博客_linearregression函数https://blog.csdn.net/qq_41750911/article/details/124883520
4.
(4条消息) 一文让你彻底搞懂最小二乘法(超详细推导)_胤风的博客-CSDN博客_最小二乘法https://blog.csdn.net/MoreAction_/article/details/106443383