【可解释性机器学习】可解释机器学习简介与特征选择方法
特征选择:Feature Importance、Permutation Importance、SHAP
- 1. Introduction
-
- 什么是可解释机器学习(Explainable ML)?
- 为什么需要Explainable ML?
- 直接使用一些可以interpretable的模型不好吗?
- 2. Local Explanation
-
- 方法案例1:基于滑动窗口
- 方法案例2:基于梯度
- 3. Global Explanation
-
- 方法案例1:Activation Maximization
- 方法案例2:利用Generator
- 4. 用另一个explainable的模型来explanation
-
- 方法案例1:Local Interpretable Model agnostic-Explanation (LIME)
- 方法案例2:决策树正则化
- 5. 建模之后的可解释性方法
-
- Feature Importance
- Permutation Importance
- SHAP(SHapley Additive exPlanation)
- 参考资料
1. Introduction
什么是可解释机器学习(Explainable ML)?
Explainable ML要求模型不但要给出结果,还要对结果背后的原因做出解释。这种解释可以分为Local Explanation、Global Explanation、用另一种Explainable的模型来Explanation等方法。
- Local Explanation: 为什么觉得这个图片是一只猫?(单一解释某个输入)需要对输入图像进行分析,以了解模型是根据对输入图像的哪个部分判断它是一只猫?输入图像的哪些区域改变会对判断结果产生较大的影响?(解释整个模型)
- Global Explanation:你觉得一只猫应该看起来是什么样子?需要对模型进行反推,来解释学到的知识,比如模型通过生成算法输出一只猫应该具有的样子。
- 用另一种Explainable的模型来explanation:复杂的AI模型,如神经网络,表征能力强,但其是一个black box,难以解释;而简单的线性模型是white box,表征能力强,但易解释。因此这种方法的思想就是利用线性模型来逼近AI模型的局部进行解释。
为什么需要Explainable ML?
比如利用ML模型帮助筛选简历、判断犯人能否获得假释、是否要给某人提供贷款…,在很多领域中,不能直接草率的利用ML模型给出的结果,还需要了解它是出于什么样的动机预测出这样的结果。如果能做到这点,我们才能更信任我们的模型,甚至可以针对同一件事对不同领域的人做出personalized的解释。
直接使用一些可以interpretable的模型不好吗?
- 一些可以被很好解释的模型,如线性模型,决策树等,对于很复杂的任务可能表现并不好;
- 利用一些集成学习的方法,如XGBoost等,可以提升模型的能力,但是又让这些原本很好解释的模型不那么好解释了;
- 神经网络具有更为强大的表现能力,所以我们重点就过渡到如何让神经网络变得可解释。
2. Local Explanation
思想: o b j e c t x → c o m p o n e n t s { x 1 , x 2 , . . . , x n } object x \rightarrow components \{x_1, x_2,...,x_n\} objectx→components{x1,x2,...,xn}
将模型输入的object拆分为components,去除或者调整某个component的值,如果这个component的改变能导致模型发生很大的决策改变,这个component就是重要的。
方法案例1:基于滑动窗口
参考论文:
Zeiler, M.D., Fergus, R. (2014). Visualizing and Understanding Convolutional Networks. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds) Computer Vision – ECCV 2014. ECCV 2014. Lecture Notes in Computer Science, vol 8689. Springer, Cham. https://doi.org/10.1007/978-3-319-10590-1_53
思想:在输入图像上滑动一个灰色方块进行局部区域的遮挡,观察哪些位置被灰色方块遮挡后能导致模型错误判断。
如下图所示:红色和蓝色分别代表低错误率和高错误率,当灰色方块挡住博美犬脸部、轮胎、狗的身体时,明显可以看到模型的错误率很高,那么我们可以认为这些部分是模型进行判断时的主要依据。

那么问题来了,我们该如何选择方块的大小,以及如何选择方块的颜色?
方法案例2:基于梯度
参考论文:
Simonyan, Karen, Andrea Vedaldi and Andrew Zisserman. “Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps.” CoRR abs/1312.6034 (2013): n. pag.
思路: { x 1 , . . . , x n , . . . , x N } → { x 1 , . . . , x n + Δ x , . . . , x N } \{x_1, ..., x_n,...,x_N\}\rightarrow \{x_1, ...,x_n+\Delta x,...,x_N\} {x1,...,xn,...,xN}→{x1,...,xn+Δx,...,xN} y k → y k + Δ y y_k\rightarrow y_k+ \Delta y yk→yk+Δy
对每个输入像素增加一个扰动 Δ x \Delta x Δx,对应输入类型概率 y k y_k yk会产生一个 Δ y \Delta y Δy的改变。可以计算输入扰动 Δ x \Delta x Δx对输出扰动 Δ y \Delta y Δy产生的影响。
∣ Δ y Δ x ∣ ⇒ ∣ ∂ y k ∂ x n ∣ |\frac{\Delta y}{\Delta x}|\Rightarrow |\frac{\partial y_k}{\partial x_n} | ∣ΔxΔy∣⇒∣∂xn∂yk∣
其实就是计算每个像素的偏导数,可以以此画一个saliency map。如下图所示,其中亮度高(白)的值代表偏导数值高的地方,亮度低(黑)的值代表偏导数值低的地方,根据saliency map来观察哪些像素值是模型觉得比较重要的部分。

那么问题来了:
- 该方法存在梯度饱和的情况。比如判断一张图片是不是大象,大象的鼻子长度可能是个关键因素,即如果图片中鼻子长度超过一个阈值后,就会被判为大象了,那么这时求输出对鼻子长度的偏导数,结果就很小。若用这种方法进行判断,得到的结果可能是鼻子长度对于判断图片是否为大象没有很大影响。这显然不是合理的解释。可能的解决办法参考下列论文:
Sundararajan, M., Taly, A., & Yan, Q. (2016). Gradients of Counterfactuals. ArXiv, abs/1611.02639.
Shrikumar, A., Greenside, P., & Kundaje, A. (2017). Learning Important Features Through Propagating Activation Differences. International Conference on Machine Learning.
- 该方法可能被恶意攻击。如下边上图所示,我们得到的saliency map能够解释模型是根据火车的部分来进行判断的,但这下图中加上某些noise之后,模型就完全注意到云彩的部分了。具体可以参考这篇论文:

Ghorbani, A., Abid, A., & Zou, J.Y. (2017). Interpretation of Neural Networks is Fragile. AAAI Conference on Artificial Intelligence.
3. Global Explanation
思想: x ∗ = a r g m a x x y i x*=arg max_x y_i x∗=argmaxxyi
就是让模型告诉我们,针对某一类别最大可能的概率值,输入应该是什么样子的。
方法案例1:Activation Maximization
思路:利用这个思想我们对于手写数字的任务,画出对于每个数字类别,模型认为最可能的输入是什么样子的。但是从下面左图可以看到,画出的理想输入图像类似于噪声。
于是,对模型增加一个约束,要求生成的图片不仅要使 y i y_i yi最大,还要像一个数字。即
x ∗ = a r g m a x x y i + R ( x ) x*=arg max_x y_i + R(x) x∗=argmaxxyi+R(x)
针对手写图像识别的任务,可以设计 R ( x ) = − ∑ i , j ∣ x i j ∣ R(x)=-\sum_{i,j}|x_{ij}| R(x)=−∑i,j∣xij∣,得到的结果如下右图所示。

那么问题来了,这里的 R ( x ) R(x) R(x)针对不同的任务需要被精心设计和调参,可以参考下面论文:
Yosinski, J., Clune, J., Nguyen, A.M., Fuchs, T.J., & Lipson, H. (2015). Understanding Neural Networks Through Deep Visualization. ArXiv, abs/1506.06579.
方法案例2:利用Generator
思路如下图所示:
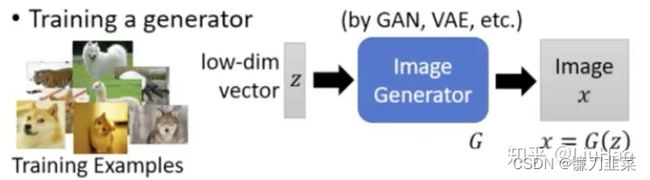
利用一些生成算法,如VAE、GAN等,训练好一个图像生成器。因为对于生成器来说,能够输入一个随机向量 z z z生成图片 x = G ( z ) x=G(z) x=G(z),再利用方法1的思想,那么问题就变为: x ∗ = a r g m a x x y i → z ∗ = a r g m a x z y i x* = argmax_x y_i \rightarrow z*=arg max_z y_i x∗=argmaxxyi→z∗=argmaxzyi
整体思想其实就是把方法1的约束 R ( x ) R(x) R(x)用一个生成器进行替代。至于如何调整输入,得到一个比较好的结果,可以参考下面论文:
Nguyen, A.M., Clune, J., Bengio, Y., Dosovitskiy, A., & Yosinski, J. (2016). Plug & Play Generative Networks: Conditional Iterative Generation of Images in Latent Space. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3510-3520.
那么问题来了,该方法需要花费大量时间训练和调试GAN模型。
4. 用另一个explainable的模型来explanation
思想如下图所示:
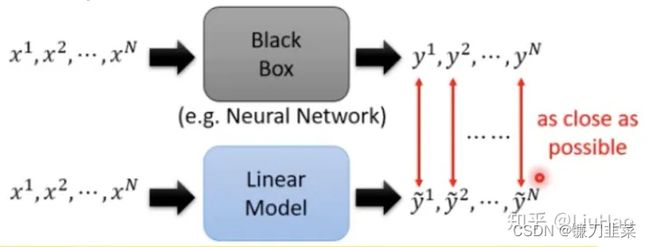
用一些容易解释的模型(如Linear Model, Decision Tree等)去模拟复杂的模型(如神经网络),从而进行解释。但是简单的模型往往表征能力有限,并不足以完全模拟高度非线性的模型,只能去模拟复杂模型的局部特性。因此这种方法其实也是属于Local Explanation。
方法案例1:Local Interpretable Model agnostic-Explanation (LIME)
Ribeiro, M., Singh, S., & Guestrin, C. (2016). “Why Should I Trust You?”: Explaining the Predictions of Any Classifier. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.
思路如下图所示:
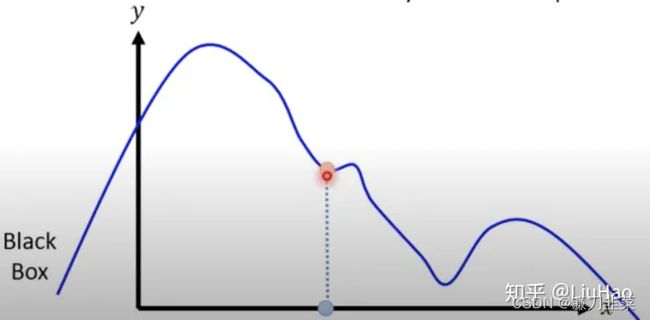
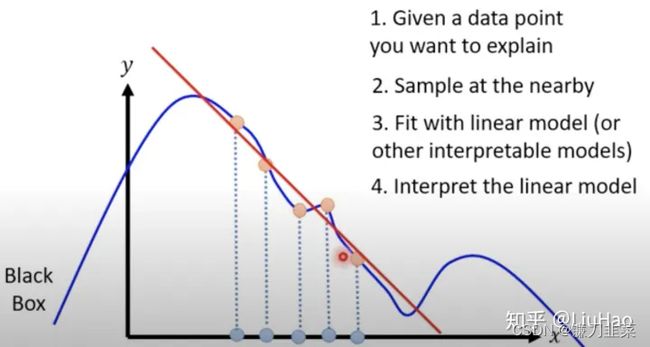
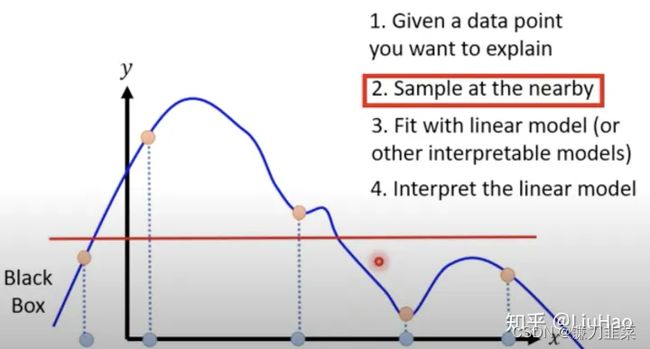
利用局部线性化的思想,以上图最简单的一维情况为例,假设要对样本 x 0 x_0 x0进行解释,那就在它的附近采样一些样本,再用一个线性的模型去拟合这些样本在待解释模型中的输出。
那么问题是:
- 如何定义“附近”?——比如下图1中,“附近”的定义就比较好,下图2中“附近”的定义就太大了。
LIME应用在图像中的例子:
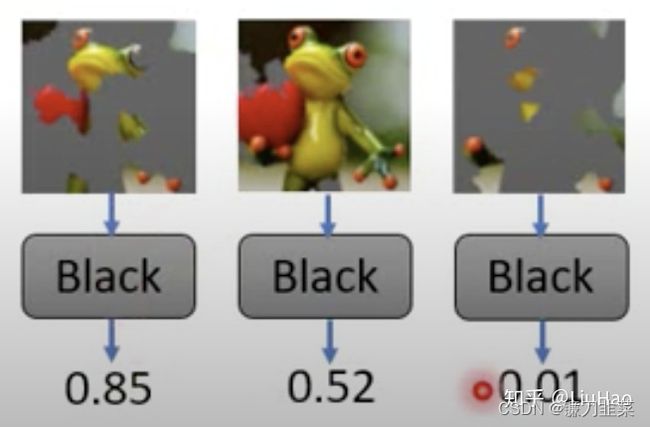
- 比如,想解释模型为什么会把这张图片判断成青蛙?
- 利用一些方法把对这个图像进行segmentation——也就是说不关心某个像素点的解释性,而是关心某个区域的解释性。

然后把随机丢掉一些segments的图像输入我们到待测模型,得到相应的输出结果。
- 得到一组输入输出后,用其训练一个线性模型——这里要注意的是:如果直接用线性模型去拟合的话,参数量会太多(可以联想下用一个全连接而不用CNN去做图像分类的例子)。因此,可以先用一些方法从图像中提取出一个低维度的向量,再输入到线性模型中。
如果我们的segmentation的数量是M,那么这个低维向量的大小就是 x 1 , . . . , x m , . . . , x M x_1, ..., x_m,...,x_M x1,...,xm,...,xM,其中:
x m = { 0 Segment m is deleted 1 Segment m exists x_m=\begin{cases}0 & \text{ Segment } m \text{ is deleted } \\1 & \text{ Segment } m \text{ exists } \end{cases} xm={01 Segment m is deleted Segment m exists - 根据线性模型的权重做出解释:
y = w 1 x 1 + . . . + w m x m + . . . + w M x M + b y=w_1x_1+...+w_mx_m+...+w_Mx_M+b y=w1x1+...+wmxm+...+wMxM+b
如果 w m ≈ 0 w_m\approx 0 wm≈0,对应的segment与青蛙没有关系;
如果 w m > 0 w_m >0 wm>0, 对应的segment表明这是青蛙;
如果 w m < 0 w_m <0 wm<0,对应的segment表明这不是青蛙。
方法案例2:决策树正则化
Wu, M., Hughes, M.C., Parbhoo, S., Zazzi, M., Roth, V., & Doshi-Velez, F. (2017). Beyond Sparsity: Tree Regularization of Deep Models for Interpretability. AAAI Conference on Artificial Intelligence.
思路:LIME的思想是利用一个linear model去解释,那么我们也可以采取non-linear、interpretable的决策树来解释。如下图所示:
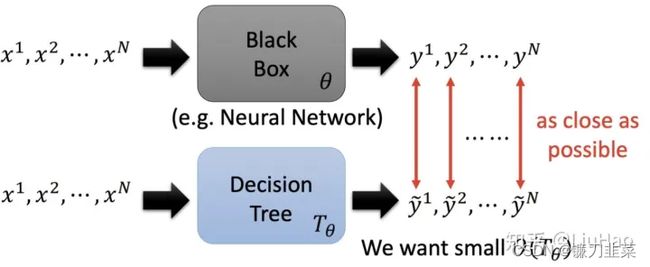
先来考虑决策树,如果一个决策树很深、很复杂,它也可以拟合很复杂的关系(可以想想一下单个决策树不加任何限制也是能够过拟合的),但是这样以来这个决策树就会变得很难解释。因此,需要限制决策树的复杂程度 O ( T θ ) O(T_\theta) O(Tθ),比如树的平均深度。
5. 建模之后的可解释性方法
首先,根据上文所描述的内容可知,模型通常会考虑以下问题:
- 哪些特征在模型看来是最重要的?
- 从大量的记录整体来考虑,每一个特征如何影响模型的预测?
- 关于某一条记录的预测,每一个特征是如何影响到最终的预测结果的?
所以,选择一个可解释的机器学习模型必须能够满足可靠性、易于调试、能够启发特征工程思路、并可以指导后续数据采集的方向,同时指导人为决策,最终建立模型和人之间的新人。
因此,这里介绍三种可解释的特征选择方法,分别是:
- 特征重要性,也就是模型自带的feature importance评分
- Permutation Importance
- SHAP
当然,还有很多其他方法,部分依赖图(PDP)和个体条件期望图(ICE)、局部可解释不可知模型(LIME)、RETAIN、逐层相关性传播(LRP)。这里主要介绍特征选择过程中的可解释方法。
Feature Importance
特征重要性的作用,顾名思义,就是快速的知道哪些因素是比较重要的,但是不能得到这个因素对模型结果的正负向影响,同时传统方法对交互效应的考量会有些欠缺。
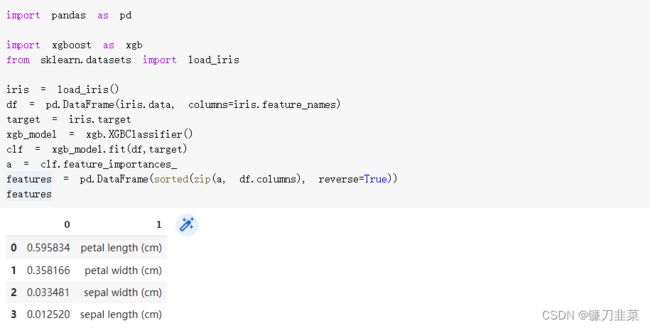
如果想要知道哪些变量比较重要的话。可以通过模型的feature_importances_方法来获取特征重要性。例如XGBoost的feature_importances_可以通过特征的分裂次数或利用该特征分裂后的增益来衡量。
计算方法是:Mean Decrease Impurity。思想:一个特征的意义在于降低预测目标的不确定性,能够更多的降低这种不确定性的特征就更重要。即特征重要性计算依据某个特征进行决策树分裂时,分裂前后的信息增益(基尼系数).
示例如下:使用XGBoost对iris鸢尾花数据集进行分类
Permutation Importance
容易想到,在训练模型的时候可以直接输出特征重要性,但这个特征对整体的预测效果有多大影响?可以用Permutation Importance(排列重要性)进行计算。
Permutation Importance的思想:基于“置换检验”的思想对特征重要性进行检测,一定是在model训练完成后,才可以计算的。简单来说,就是改变数据表格中某一列的数据的排列,保持其余特征不动,看其对预测精度的影响有多大。
计算步骤:
①用上全部的特征,训练一个模型;
②验证集预测得到得分(score);
③验证集的一个特征列的值进行随机打乱,预测得到得分;
④将上述得分做差即可得到该特征列对预测的影响;
⑤依次将每一列特征按照上述方法执行,得到每一列特征对预测的影响程度。
使用ELI5库可以进行Permutation Importance的计算。ELI5是一个可以对各类机器学习模型进行可视化和调试Python库,并且针对各类模型都有统一的调用接口。ELI5中原生支持了多种机器学习框架,并且也提供了解释黑盒模型的方式。

结果分析:
- 靠近上方的绿色特征,表示对模型预测较为重要的特征;
- 为了排除随机性,每一次 shuffle 都会进行多次,然后取结果的均值和标准差;
- ±后面的数字表示多次随机重排之间的差异值。
可以根据自定义的阈值选择Weight较大的特征。
SHAP(SHapley Additive exPlanation)
以上都是全局可解释性方法,那局部可解释性,即单个样本来看,模型给出的预测值和某些特征可能的关系,这就可以用到SHAP。当然shap也有全局可解释性。
SHAP 属于模型事后解释的方法,它的核心思想是计算特征对模型输出的边际贡献,再从全局和局部两个层面对“黑盒模型”进行解释。SHAP构建一个加性的解释模型,所有的特征都视为“贡献者”。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。基本思想:计算一个特征加入到模型时的边际贡献,然后考虑到该特征在所有的特征序列的情况下不同的边际贡献,取均值,即某该特征的SHAPbaseline value
SHAP(SHapley Additive exPlanation)是Python开发的一个"模型解释"包,可以解释任何机器学习模型的输出。
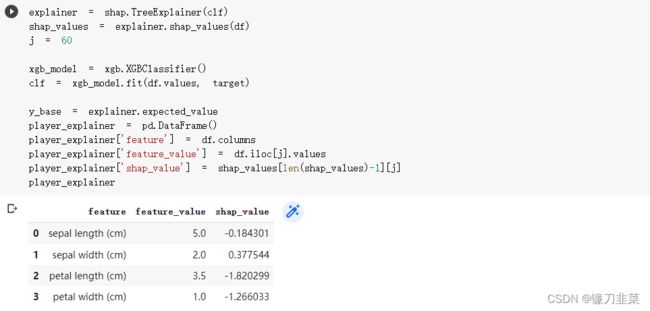
注意:在SHAP中进行模型解释需要先创建一个explainer。其中SHAP支持很多类型的explainer,例如deep、gradient、kernel、linear、tree、sampling等,上述代码中以tree为例,因为它支持常用的XGB、LGB、CatBoost等树集成算法。
(1)可视化一个prediction解释,如果不想用JS,则传入matplotlib=True:
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1][j], df.iloc[j,:])

结果分析:
①base value:全体样本Shap平均值,模型在数据集上的输出均值0.5671;
②f(x):当前样本的Shap输出值,模型在单个样本的输出值1.76;
③正向作用的特征:petal length (cm)取值为3.5,petal length(cm)取值为1,具有正向影响;长度表示特征影响的程度。
④反向作用的特征:sepal length (cm)取值为5,sepal width (cm) 取值为2,具有有负向影响。
⑤引起预测降低的特征值是蓝色的,最大的影响源自 sepal length (cm)=5 的时候,但 petal length (cm)= 3.5 的值则对提高预测的值具有比较有意义的影响;所有特征共同作用下预测结果为1.76,计算公式为: 0.5670767 + 3.51.423280 + 0.790364 − 50.906990 − 2.0 ∗ 0.116189 0.5670767+3.51.423280+0.790364-50.906990-2.0*0.116189 0.5670767+3.51.423280+0.790364−50.906990−2.0∗0.116189。
(2)可视化全局解释,即多个预测的解释:
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1], df) #鼠标可以放图上面显示具体数值
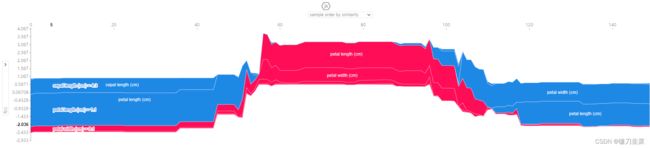
解释Output value(单个样本)和Base value(全体样本Shap平均值)的差异,以及差异是由哪些特征造成的。红色是起正向作用的特征,蓝色是起负向作用的特征。
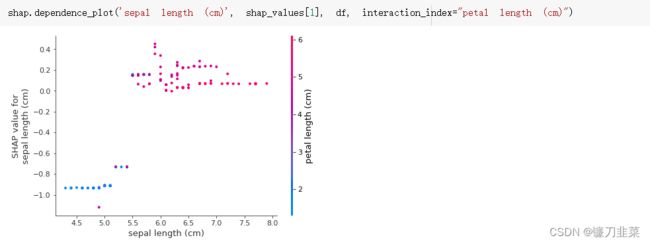
(3)为每个样本绘制其每个特征的SHAP值。这可以更好地理解整体模式,并允许发现预测异常值。下图中描述的就是整体特征重要性。

下图描述shap_values取值为1的情况,每一行代表一个特征,横坐标为SHAP值,一个点代表一个样本,颜色表示特征值(红色为高,蓝色为低)。

- 每个点是一个样本(人),图片中包含所有样本
- X轴:样本按Shap值排序
- Y轴:特征按Shap值排序
- 颜色:特征的数值越大,越红
(4)排除所有特征的影响,描述age和capital_gain的关系
至于后续更详细的用法,请详见接下来的博客!
参考资料
[1] 可解释机器学习(Explainable ML)总结
[2] Visualizing and Understanding Convolutional Networks
[3] Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps
[4] 可解释性机器学习_Feature Importance、Permutation Importance、SHAP