常用AI/机器学习模型可解释技术与工具
【编者按:随着AI模型日益复杂,模型可解释的重要性和挑战日益凸显。通过模型可解释,可以指导特征工程的优化、检测偏差、增强模型使用者对模型的可信度。
Anaconda资深数据科学家Sophia Yang总结了8种模型可解释常用技术和工具,对其主要特征进行了概述。
以下是译文,Enjoy!】
作者 | Sophia Yang
编译 | 岳扬
目录
01. SHAP
02. Lime
03. Explainable Boosting Machine
04. Saliency maps(显著图)
05. TCAV
06. Distillation(蒸馏技术)
07. Counterfactual(反事实分析)
08. lnterpretML
现在ML/AI模型变得越来越复杂,对模型的解释和说明也变得越来越具有挑战性。一个简单的、容易解释的回归或决策树模型已经不能完全满足技术和商业需求。越来越多的人使用集合方法(ensemble methods) 和深度神经网络来获得更好的预测和更高的准确性。然而,那些复杂的模型很难解释、调试和理解。因此,很多人称这些模型为黑箱模型。
当我们训练一个ML/AI模型时,我们经常关注技术细节,如 step size, layers, early stopping, dropout, dilation 等等。我们并不真正知道为什么我们的模型会有某种行为。
例如对于一个信用风险模型,为什么我们的模型会给每个人分配一个特定的分数?我们的模型依赖哪些特征?我们的模型是否严重依赖一个不正确的特征?即使我们的模型不把种族和性别作为输入特征,我们的模型是否从其他特征中推断出这些属性并引入对某些群体的偏见?利益相关者能理解和信任模型的行为吗?该模型能否为人们提供如何提高信用分数的指导?
模型的解释和说明可以提供这些问题的答案,帮助我们调试模型,减少偏差,并建立对模型的信任。
大家对机器学习模型的可理解性和可解释性越来越感兴趣。研究人员和机器学习从业者已经设计了许多模型解释技术。在这篇文章中,我们将对八种流行的模型解释技术和工具进行高阶概述,包括SHAP(以一种统一的方法来解释任何机器学习模型的输出)、LIME(用于解释机器学习模型的个别预测)、Explainable Boosting Machine(可解释增强机)、Saliency maps(显著图)、TCAV(一种新型线性可解释性方法)、Distillation(蒸馏技术)、Counterfactual(反事实)和lnterpretML(能为开发人员提供多种方式来实验AI模型和系统,并进一步解释模型)。
01. SHAP

图1. SHAP解释了机器学习模型的输出(来源:https://shap.readthedocs.io/,MIT license)
“SHAP(SHapley Additive exPlanations)[1]是一种博弈论的方法,可用于解释任何机器学习模型的输出。它利用博弈论中的经典Shapley值及其相关扩展,将最优信用分配与局部解释联系起来。”
图1显示了SHAP的工作原理。假设基本率(Base rate),即预测值E[f(x)]的先验背景期望值为0.1。现在我们有一个新的观察对象,其特征是年龄=65,性别=F,血压=180,BMI=40。这个新观察对象的预测值是0.4。我们如何解释0.4的输出值和0.1的基本率之间的差异?这就是Shapley值产生作用的地方。
- 让我们从基本率0.1开始。
- 加上BMI Shapely值为0.1,我们得到0.2。
- 加上BP Shapely值为0.1,我们得到0.3。
- 加上性别Shapely值为-0.3,我们得到0。
- 加上年龄Shapely值0.4,我们得到0.4。
基于Shapely值的相加性,对于这个新的观察对象,模型预测值为0.4。SHAP值提供每个特征的重要性的解释,并解释了模型预测的运作方式。
我们如何计算Shapley值?SHAP绘制了线性模型的部分依赖图(Partial Dependence Plot),其中X轴代表特征,Y轴代表给定特征的输出预期值(见图2)。一个特征的Shapley值是预期模型输出与该特征给定值时的部分依赖图之间的差值,即图中红线的长度。
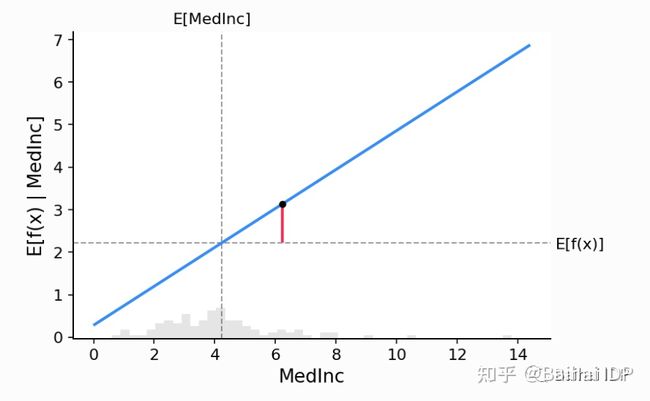
图2. 部分依赖图(来源:https://shap.readthedocs.io/,MIT license)
Shapley值的计算可能很复杂,因为它需要所有的联合排列的平均值。shap库使用抽样和优化技术来处理所有的计算,并对表格数据、文本数据、甚至图像数据返回直接的结果(见图3)。可以通过conda install -c conda-forge shap来安装SHAP,然后我们看一个例子。
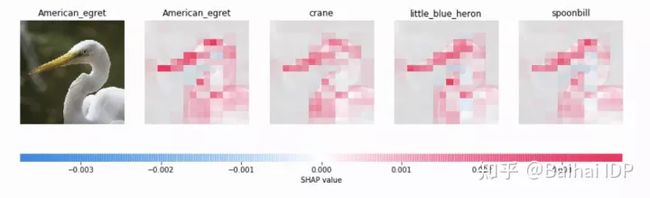
图3. SHAP解释图像分类(来源:https://shap.readthedocs.io/,MIT license)
02. Lime
模型在全局上可能是复杂的。Lime(Local Interpretable Model-Agnostic Explanations)不关注整体复杂的模型行为,而是关注局部区域,用线性近似来反映被预测实例周围的行为。
图4说明了Lime是如何工作的。蓝色/粉红色的背景代表原始模型的决策函数。红叉(我们称之为X)是我们想要预测和解释的实例/新观察对象。
- 获取X周围的采样点
- 使用原始模型来预测每个采样点
- 根据样本与X的接近程度对其进行加权(加权较大的点在图中对应于较大的尺寸)。
- 在加权的样本上拟合一个线性模型(虚线)。
- 用这个线性模型来解释X周围的行为。
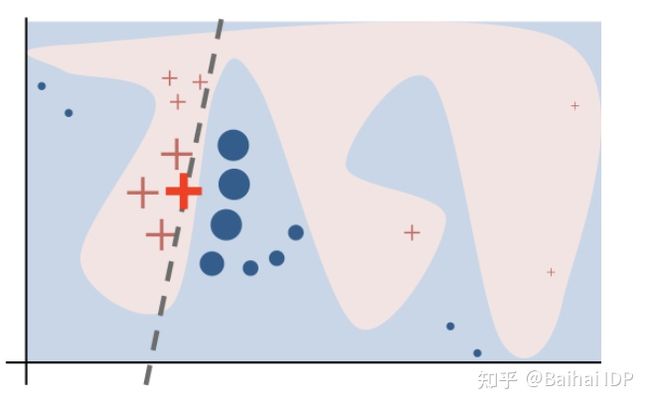
图4. Lime 预测图(来源:https://github.com/marcotcr/lime,BSD license)
通过Lime,我们可以在局部解释表格数据、文本数据和图像数据的模型行为。下面是一个使用Lime来解释文本分类器的例子。我们可以看到,这个分类器对实例的预测是正确的,但理由是错误的。

图5. Lime解释文本分类器的例子(来源:https://github.com/marcotcr/lime, BSD license)
要了解更多关于Lime的信息,请查看https://github.com/marcotcr/lime,并通过 pip install lime进行安装。
03. Explainable Boosting Machine
“可解释增强机(EBM)[2]是一种基于树的、循环梯度提升的广义加成模型,具有自动互动检测功能。EBM一般情况下和最先进的黑箱模型一样准确,同时还能够保持完全可解释。”
EBM的工作方式如下:
- 在每次迭代中,我们轮流对特征进行套袋法(bagging,即bootstrap aggregating的缩写)和梯度提升树的训练。我们先对第一个特征进行训练,然后更新残差并对第二个特征进行训练,一直到完成对所有特征的训练。
- 然后我们多次重复这个过程。
- 由于EBM是一个一个地循环处理特征,它可以显示每个特征在最终预测中的重要性。
EBM是在interpret.ml[3]中实现的,我们将在下文介绍它。
04. Saliency maps(显著图)
显著图方法被广泛用于解释神经网络图像分类任务。它衡量每个像素的重要性,并强调哪些像素对预测有影响的。显著性图取每个类相对于每个图像输入像素的梯度或导数,并将梯度可视化(见图6)。

图6. 显著图(来源:https://pair-code.github.io/saliency/#guided-ig,Apache license)
PAIR Saliency项目提供了 “framework-agnostic implementation for state-of-the-art saliency methods(最先进的显著性方法的框架无关的实现)”,包括Guided Integrated Gradients, XRAI, SmoothGrad, Vanilla Gradients, Guided, Backpropagation, Integrated Gradients, Occlusion, Grad-CAM, Blur IG。
要了解更多关于Saliency的内容,请查看https://github.com/PAIR-code/saliency,并通过 pip install saliency进行安装。
05. TCAV
TCAV(一种新型线性可解释性方法)是指用概念激活向量(CAVs)进行定量测试。TCAV “量化了用户定义的概念对于分类结果的重要程度--例如,对斑马对条纹的存在有多敏感的预测”[4](Kim,2018)。

图7. 用概念激活向量进行测试 (来源:Kim, 2018)
TCAV执行以下步骤来确定一个概念是否重要。
- 定义概念激活向量(图7步骤a-d):TCAV使用概念图像(有条纹物体的图像)和随机图像的例子作为输入,并检索出层的激活函数。然后,训练一个线性分类器来分离激活函数,并取与超平面决策边界正交的向量(CAV)。CAV代表图像中的条纹程度。
- 计算TCAV得分(图7步骤e):TCAV得分是通过与CAV的方向性导数来计算的。它代表了模型对一个特定概念的敏感性,如条纹。
- CAV验证:测试一个概念是否有静态意义。同样的过程也可以用随机与随机图像。我们可以将概念对随机图像的TCAV得分分布与随机与随机图像的TCAV得分分布进行比较。可以进行双侧t检验来测试TCAV得分分布的差异。
要了解更多关于TCAV的信息,请查看GitHub - tensorflow/tcav: Code for the TCAV ML interpretability project并通过pip install tcav进行安装。
06. Distillation(蒸馏技术)
“在机器学习中,知识蒸馏是将知识从一个大模型转移到一个小模型的过程。”
在模型解释的背景下,大模型是黑箱模型,也是教师模型。较小的模型是解释者,即学生模型。学生模型试图模仿教师模型的行为,并且是可解释的。
例如,人们可以构建一个决策树来接近原始的复杂模型[5](Bastani,2019)。Bastani的论文 “提出了一种学习决策树的模型提取算法--为了避免过度拟合,该算法通过主动采样新的输入并使用复杂模型对其进行标记来生成新的训练数据。”
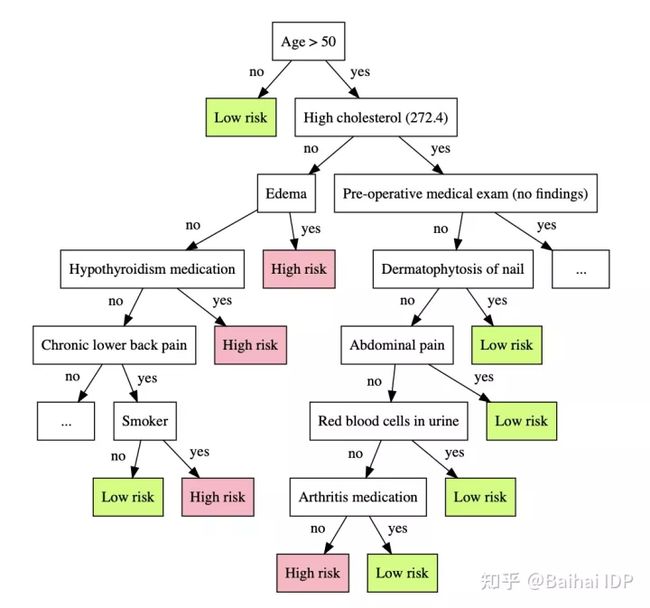
图8. 用决策树解释黑箱模型。(来源: Interpreting Blackbox Models via Model Extraction. Osbert Bastani, Carolyn Kim, Hamsa Bastani. 2019)
07. Counterfactual(反事实分析)
反事实分析描述的是为改变模型预测所需的最小的输入特征变化。这里我们提出了很多 "如果 "问题。如果我们增加这个特征或减少那个特征呢?例如,根据一个黑盒模型,约翰有很高的心脏病风险。如果约翰每周锻炼5天呢?如果约翰是个素食主义者呢?如果约翰不吸烟呢?这些变化会导致模型预测的改变吗?这些反事实分析提供了易于理解的解释。
关于生成反事实分析的研究有很多,方法也很多。例如,DiCE(多样化的反事实解释)为同一个人生成了一组多样化的特征干扰选项,这个人的贷款被拒绝了,但如果收入增加1万美元或收入增加5000美元,并有1年以上的信用记录,就会得到批准。DiCE在支持用户特定要求的情况下,对输入的多样性和原始输入进行了优化。
要了解更多关于interpretML的信息,请查看文档[6],并通过conda install -c conda-forge dice-ml进行安装。
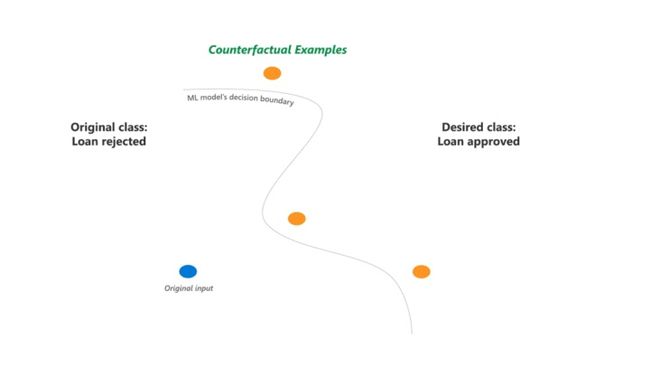
图9. DiCE (来源: https://github.com/interpretml/DiCE, MIT license)
08. lnterpretML
“InterpretML(能为开发人员提供多种方式来实验AI模型和系统,并进一步解释模型)是一个开源的软件包,它将最先进的机器学习解释技术整合在一起。”
interpretML为可解释模型(glassbox model)提供解释性,包括:
- 可解释增强机
- 线性模型
- 决策树
- 决策规则
它还提供了对黑箱模型的解释,使用了:
- SHAP 解释模型
- LIME 解释器
- 部分依赖图
- 莫里斯敏感性分析
interpretML的结果可以在其Plotly dashboard上显示。
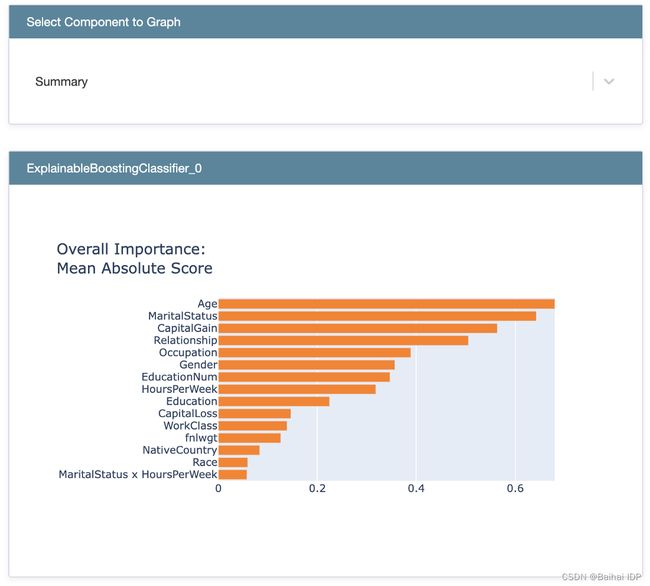 图10. interpretML dashboard (来源: https://interpret.ml/docs/getting-started.html, MIT license)
图10. interpretML dashboard (来源: https://interpret.ml/docs/getting-started.html, MIT license)
要了解更多关于 interpretML 的信息,请查看文档[7]并通过 conda install -c interpretml interpret 进行安装。
END
参考资料
[1] Welcome to the SHAP documentation — SHAP latest documentation. https://shap.readthedocs.io/
[2] Explainable Boosting Machine. https://interpret.ml/docs/ebm.html
[3] InterpretML. http://interpret.ml/
[4] Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). Been Kim, Martin Wattenberg, Justin Gilmer, Carrie Cai, James Wexler, Fernanda Viegas, Rory Sayres. 2018.
[5] Interpreting Blackbox Models via Model Extraction. Osbert Bastani, Carolyn Kim, Hamsa Bastani. 2019
[6] Diverse Counterfactual Explanations (DiCE) for ML — DiCE 0.9 documentationhttp://interpret.ml/DiCE/
[7] https://interpret.ml/docs/getti