CLIP2TV:用CLIP和动量蒸馏来做视频文本检索!腾讯提出CLIP2TV,性能SOTA,涨点4.1%!...
关注公众号,发现CV技术之美
▊ 写在前面
现代视频文本检索框架主要由视频编码器 、文本编码器 和相似度head 三个部分组成。随着视觉表示学习和文本表示学习的成功,基于Transformer的编码器和融合方法也被应用于视频-文本检索领域。
在本文中,作者提出了CLIP2TV ,旨在探索基于Transformer的方法中关键元素的位置。为了实现这一点,作者首先回顾了多模态学习的一些研究,然后将一些技术引入视频文本检索中,最后通过不同配置下的大量实验进行评估。
实验表明,CLIP2TV在MSR-VTT数据集上达到了52.9@R1,比之前的SOTA结果高出4.1%。
▊ 1. 论文和代码地址

CLIP2TV: An Empirical Study on Transformer-based Methods for Video-Text Retrieval
论文地址:https://arxiv.org/abs/2111.05610
代码地址:未开源
▊ 2. Motivation
近年来,视频文本检索工作采用基于Transformer的方法引入视频和文本编码器 以及相似度head 。在CLIP4Clip中,视频和文本编码器均采用CLIP编码器。具体来说,ViT用于编码原始视频,一个类似BERT的Transformer用于编码文本。
在CLIP4Clip中也探索和评估了各种相似性head,其中一个顺序Transformer已经显示出了取代传统的平均池化方法的潜力。在图像-文本检索领域类似,ALBEF在早期采用了较重的Transformer相似度head来融合两种模态。
此外,还利用了自监督学习的动量蒸馏。为了修正相似度head的输出相似度矩阵,最近的工作通过 dual-softmax操作对其进行了修正。
在本文中,作者从CLIP4Clip的框架开始,然后在推理阶段引入动量蒸馏、具有匹配头的多模态Transformer和修正的 dual-softmax。通过这种方式,作者在MSR-VTT数据集上得到了52.9@R1的结果。
▊ 3. 方法
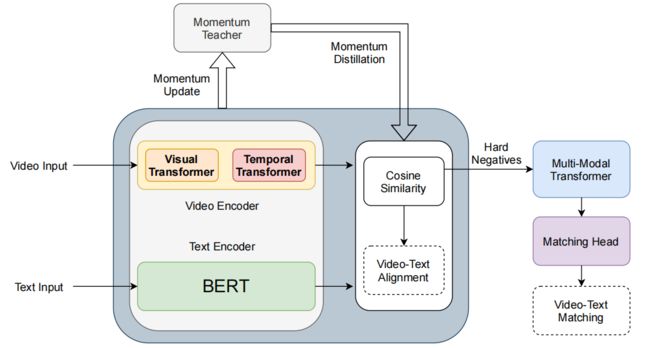
给定一组标题和一组视频,视频-文本检索任务的目的是寻找一个计算标题和视频之间相似性的匹配函数。最近的研究已经显示了图像-文本检索预训练的好处和端到端训练对视频-文本检索任务的优势。
受此启发,作者采用CLIP模型作为多模态编码器,并遵循CLIP4Clip作为基本框架。上图展示了本文的模型结构。
3.1. Framework
Video Encoder
给定一个以一系列帧组成的视频,首先随机提取具有固定长度的连续帧作为视频片段,其中为帧数。基于Transformer的视频编码器,即在CLIP中使用的ViT,将其编码为帧嵌入,其中是帧嵌入的维度。
然后,将具有位置嵌入和残差连接的时间Transformer应用于帧嵌入,以增强时间信息。然后,projector将上下文化的帧嵌入投射到一个多模态的子空间中。为了简单起见,重新使用作为增强的时间嵌入,其中D是维数。最终的视频表示计算为。
Text Encoder
本文采用CLIP中使用的 bert-like transformer作为文本编码器。标题为被输入编码器,以获取token嵌入,其中和是token嵌入的数量和维数。与视频编码过程相同,文本projector将token嵌入投影到一个维度为d的公共子空间中。最后,[EOS] token的将作为整个标题的表示。
Contrastive learning
由于帧表示v和标题表示w都被投影到了多模态共享空间中,作者试图结合余弦相似性和对比性损失,计算标准化帧表示和标准化标题表示之间的余弦相似度。给定具有B个视频文本对的mini-batch,交叉熵损失作为对比损失来训练两个模态编码器:
其中为余弦相似度,τ为可学习温度参数,为ground truth,其中正样本对和负样本对分别为1,0,为交叉熵公式。同时,的计算结果也是一样。然后,将对比损失表示为:
3.2. Momentum Distillation
由于字幕长度和视频帧提取策略的限制,视频-文本对很难在语义层次上相互完全对应。标题可能不能完全描述视频内容,而视频片段可能不包括文本描述。 受ALBEF中使用的动量蒸馏处理图像文本对之间的弱相关性的启发,作者将其植入到视频文本检索任务中。
作者维护了两个队列和来存储最近由教师模型提取的的视频表示和标题表示。与学生结构相同的教师模型由学生模型进行初始化,并采用指数移动平均(ema)策略进行更新。
具体来说,在训练过程中,相似性和对比性损失不仅在mini-batch中计算,而且在队列中计算。在计算损失函数时,作者同时结合了伪标签和ground truth标签:
其中,α为蒸馏系数。新的损失函数可以表示为:
3.3. Multi-Modal Fusion
为了充分利用两种模态之间的丰富信息,增强跨模态交互,作者利用多模态Transformer来预测视频-文本对是匹配的还是不匹配的。与TACo和ALBEF相同,本文的多模态编码器由自注意层组成。
它采用视频帧嵌入和标题token嵌入作为输入和输出融合嵌入。
作者将[EOS] token的表示作为视频-文本对的融合特征,即。,由LN-FC-ReLU-FC组成的匹配head 计算匹配分数。多模态融合的训练目标是InfoNCE Loss:
其中为视频-文本对集,和分别为对集中正对和负对的融合特征。
为了提高效率和降低计算成本,作者只选择mini-batch内hard negative样本进行多模态融合。具体地说,对于每个视频,作者在训练中根据相似度矩阵选择前k个负文本样本,反之亦然。
最后,将B×(2K+1)对进行多模态融合。通过这种细粒度的交互方法,模型学习了捕捉和区分具有相似特征但语义不同的视频和标题之间的细微差异。
3.4. Dual Softmax at Inference
最新的工作CAMoE提出了一种新的相似度计算方法,并取得了显著的性能提升。具体来说,在交叉方向上计算的先验概率可以作为修正原始相似性矩阵的修正器,这有利于训练和推理。作者进一步修改了它,使其对称:
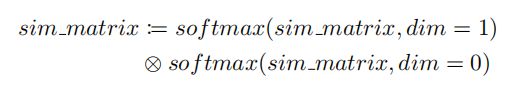
其中,表示按元素相乘。注意,作者只在推理时对视频-文本相似度矩阵施加dual softmax。
▊ 4.实验
4.1. Comparison with SOTA
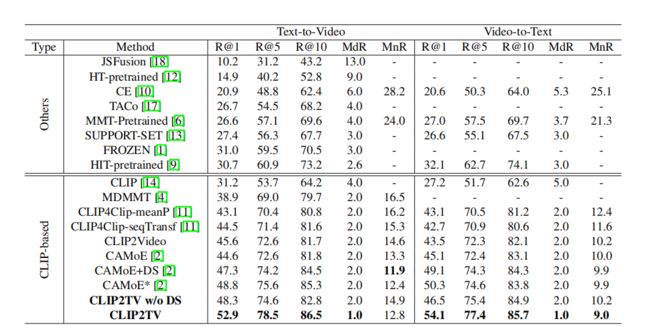
上表展示了MSR-VTT数据集上,本文方法和其他方法对比结果。
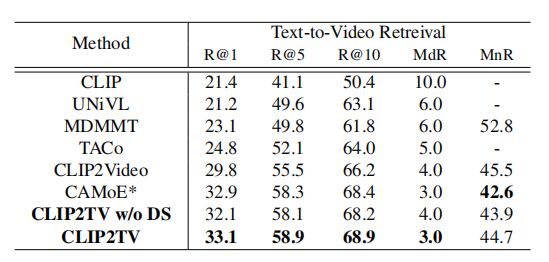
上表展示了MSR-VTT数据集full split上,本文方法和其他方法对比结果。
4.2. Ablation Studies
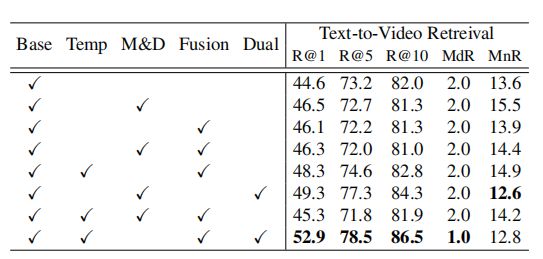
上表展示了本文方法中不同模块的消融结果。
▊ 5. 总结
在本文中,作者回顾了一些最近关于多模态学习的工作,并试图将这些知识运用到视频-文本检索。最终,作者在MSR-VTT数据集上取得了SOTA的性能,并远远超过了其他方法。
实验结果表明,基于CLIP这样的大规模图像文本Transformer模型为视频文本检索任务提供了一个强大的工具。在未来,作者将进一步研究基于Transformer的方法与其他多模态学习技术在其他视频-文本检索数据集上的能力。
▊ 作者简介
研究领域:FightingCV公众号运营者,研究方向为多模态内容理解,专注于解决视觉模态和语言模态相结合的任务,促进Vision-Language模型的实地应用。
知乎/公众号:FightingCV

END
欢迎加入「视频检索」交流群备注:检索
