分享本周所学——使用Flask实现Python程序服务化
大家好,欢迎来到《分享本周所学》第四期。本人是一名人工智能初学者,最近一周学习了如何用Flask将一个AI模型实现服务化,觉得非常有收获,就想把学到的东西分享给大家。不管你是像我一样想做AI的服务化,还是做其他程序的服务化,还是单纯想学一下Flask,相信这篇文章都会对你有所帮助。然后因为我也只是一名小白,所以有错误的地方还希望大佬们多多指正。
目录
Flask咋用啊
1. Flask安装与flask.Flask基本用法
2. 客户端使用requests.post向服务端发送请求
3. 服务端使用flask.request接收请求
4. 实现AI模型服务化
上期文章链接:《分享本周所学——Linux(Ubuntu)CUDA环境搭建以及借助PaddleSpeech实现实时录音的流式语音识别》 https://blog.csdn.net/weixin_48978134/article/details/125686296?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_48978134/article/details/125686296?spm=1001.2014.3001.5501
本期封面:
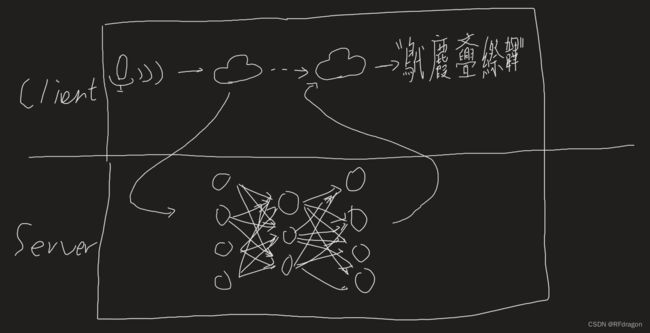
Flask咋用啊
这里先说点闲话,不想看的朋友们可以直接跳到第1节正文。
说到Flask,就不得不提到Python中的三大web框架:Django、Tornado和Flask。那有朋友可能就要问了,这三个框架有什么区别啊?应该说是各有优势。Django的特点是大,就像Photoshop一样,各种各样的功能一应俱全,你用得到的功能Django都有,你用不到的Django也有;著名的社交平台Instagram就使用了Django。而Tornado的特点是自带异步处理,而且性能极强,就像它的名字一样,如飓风般潇洒而流畅;著名的学习平台知乎就使用了Tornado。相比之下,Flask既没有强大的功能,也没有出色的性能,但这些缺点也正是它的优点。Flask最大的特点就是轻量而灵活,既可以独自胜任简单的任务,也可以通过与其他模块的结合做出大工程,如果运用得当,就能轻松通过Flask达到优于另外两个框架的效果。
不过显然啊,我用Flask和它的灵活性只能说是毫不相干,仅仅是因为它轻量而且好上手,毕竟我之前从来没有搞过服务化嘛。
1. Flask安装与flask.Flask基本用法
看完本节,相信你以后找工作的时候就能自豪的在简历上写上:“精通Flask框架的安装与卸载,能够熟练使用键盘拼写Flask这一单词。”
Flask的安装很简单啊,就一句命令行代码:
python -m pip install flask -U -i https://pypi.tuna.tsinghua.edu.cn/simple然后我们用几行最简单的Python代码就可以搭建一个服务:
from flask import Flask
app = Flask(__name__)
app.run()第一句从flask里面导入一个叫Flask的类,我们基本上所有的操作都会用到这个类。第二句是实例化,里面的参数大概就是作为服务端的程序的文件名,我们填__name__就好了。最后一句运行服务。就这么简单。运行之后大概会是这样一个结果:

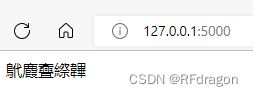
这时候,我们的服务就运行起来了!我们在浏览器里打开输出结果中最下面那行的地址,就可以看到我们刚刚搭建好的服务。默认应该是http://127.0.0.1:5000/。

对,就是这个样子。然后我们可以看到服务端那边喜提一串404:

那为什么会这样呢?大概是因为我们虽然搭建好了一个服务,但并没有告诉程序应该做点什么。那我们不妨让程序在网页上输出一句至理名言。
from flask import Flask
app = Flask(__name__)
@app.route('/')
def djwcb():
return '鴏麚斖縩韠'
app.run() 至于为什么这几个字是至理名言,可以参考萌娘百科,进到下面的链接之后Ctrl+F搜一下“鴏麚斖縩韠”。看完之后估计你也就能理解我前几期的封面都是什么意思了。异灵术 - 萌娘百科 万物皆可萌的百科全书 (moegirl.org.cn)https://zh.moegirl.org.cn/%E5%BC%82%E7%81%B5%E6%9C%AF 运行程序之后再重新打开刚才的网页,就可以看到至理名言了。
我来解释一下我加的这几行代码啊。首先是@这句话,对@有了解的朋友们可以直接看下一段。@在Python中被称作“装饰器”,这名字听着还挺高端的,但是其实就是一种传参数的方法。众所周知啊,Python中是可以把函数当作参数传给别的函数的,那@其实就是把下面的函数作为参数传给@后面跟的函数。比如在我这段代码里面就是:app.route是一个函数,它可以接收一个函数作为参数,那我们就把djwcb这个函数作为参数传给app.route。
装饰器下面的函数只能返回一些特定类型的值,比如我们返回的“鴏麚斖縩韠”是字符串,返回的字符串在打开网页之后会原封不动地显示在网页上。除了字符串之外还可以是字典、元组或者一些特殊的类型,但不能是int、float这种看着就不够高级的类型。这次我们用到的返回值类型只有字符串,所以关于其他返回值的用法我就不赘述了,感兴趣的朋友们可以自己去查一下。
我们还可以看到@app.route后面有一个参数'/'。这个'/'有什么用处呢?举个例子,假设我们在浏览器地址栏里输入https://blog.csdn.net/,就会看到CSDN博客首页;而如果输入https://blog.csdn.net/weixin_48978134,就能看到一个超级厉害的博主的首页。这段代码里的'/'其实跟blog.csdn.net后面的那个“/”都是起到路由的作用,可以根据“/”后面的内容引导到不同的网页。如果我们把代码中的'/'改成'/djwcb',那我们在浏览器的地址栏里输入的内容也必须从http://127.0.0.1:5000/换成http://127.0.0.1:5000/djwcb,不然就会像之前一样显示“Not Found”。我们也可以同时启用'/'和'/djwcb',让它们实现不同的功能,如下:
from flask import Flask
app = Flask(__name__)
@app.route('/')
def func1():
# When 127.0.0.1:5000/ is opened, the following string will be displayed.
return "There is an aphorism in 127.0.0.1:5000/djwcb"
@app.route('/djwcb')
def func2():
# When 127.0.0.1:5000/djwcb is opened, the following string will be
# displayed.
return "鴏麚斖縩韠"
app.run()其实我们这次需要用到的关于flask.Flask的内容就只有这么点东西。因为不想让篇幅太长,我这里就不说其他的功能了。
2. 客户端使用requests.post向服务端发送请求
现在另一个问题来了,我们的服务不可能只有输出没有输入,我们必须要接受用户的输入,把输入进行处理之后再输出给用户。因为我们写的程序是一个服务,服务这么高端的东西是不可能让用户在程序内部进行输入的,必须要让用户在另外一个程序远程对服务端进行输入才能显得我们的服务很高级。这个用户用来远程输入的程序就叫做客户端。那怎么实现这个过程呢?我们需要用到一个叫Requests的库。
首先要安装requests。也是一句命令啊,非常简单。
python -m pip install requests -U -i https://pypi.tuna.tsinghua.edu.cn/simple假设现在我们要做一个在线计算器,用户端内输入两个数发送给服务端,服务端计算两个数的和然后输出。客户端内的输入环节非常简单,使用input函数就行了,但是要怎么把它们发给服务端呢?其实也是很简单啊,(不算导入requests和input的话)只有一句话:
import requests
a = input()
b = input()
r = requests.post("http://127.0.0.1:5000/", data=a + ',' + b)
print(r.text)只用requests.post这一个函数就搞定了。这个函数主要有两个参数,第一个是服务端的地址,也就是之前那个http://127.0.0.1:5000/;第二个是我们要给服务端发送的数据,注意这里的数据类型需要是bytes。至于bytes是什么,可以理解成数据经过编码之后编出来的码。举个例子,这里我给data这个参数传的数据是a + ',' + b,其中a、b是数值类型,在和字符串做加法的时候会自动被转换成字符串,所以我们这里本质上是把一个字符串传给了data这个参数。但是因为requests.post只能发送bytes,所以字符串在这里会被自动转换成bytes类型,那这个过程在默认情况下就是用UTF-8对字符串进行编码,编出来的码就是bytes类型,然后这个编码会被发到服务端,服务端处理之后把运算结果发送回来。这里requests.post的返回值就是服务端处理之后回传的结果。
但是先别急着运行啊,因为我们还没有在服务端写接收数据的代码,现在运行肯定出不来结果。
3. 服务端使用flask.request接收请求
客户端给服务端发送请求之后,请求的内容会自动被flask.request接收到。至于flask.request到底是怎么用的,我这里直接对着代码解释吧。
from flask import Flask, request
app = Flask(__name__)
@app.route('/', methods=['GET', 'POST'])
def func1():
if request.method == 'POST':
nums = request.stream.read()
nums = nums.decode(encoding='utf-8')
a = eval(nums[:nums.index(',')])
b = eval(nums[nums.index(',') + 1:])
return str(a + b)
app.run()首先啊,我们在装饰器里加一个参数method。method这个参数代表服务端能够处理的请求的类型,默认是['GET']。我们之前直接从浏览器里看至理名言的时候是给服务端发送了一个'GET'请求,但是现在我们是要用requests.post给服务端发请求,这属于'POST'。
接下来我们用一个if判断服务端是不是收到了'POST'请求。如果收到了,我们就要开始处理这个请求。我们先要把请求里面的数据拿出来,这时候要用到request.stream.read。读出来的数据是用UTF-8编码的bytes格式,所以还得用decode函数给它作一下解码。因为我们刚才传数据的时候用的是“a,b”的形式,也就是两个数用一个逗号隔开,所以我们现在要把这两个数提取出来,然后作加法再返回。这个过程其实并不难,我就不解释了,大家看代码应该也能看懂。提醒一下,返回的时候要把数值转换成字符串再返回,因为数值型的返回值是不被支持的。
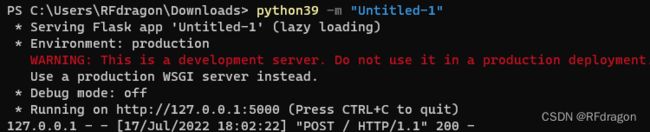
那这次所有和Flask有关的内容就说到这了,大家可以试着运行一下看看,先运行服务端再运行客户端,然后在客户端里随便输两个数试试,应该能看得到服务端返回它们的和。运行结果大概应该长这样。服务端:
客户端:
那接下来我们就要把Flask的这些功能应用到AI模型上,不需要实现这个功能的朋友们看到这就可以退出了。
4. 实现AI模型服务化
理论存在,实践开始。这次我们要用的模型还是上期文章里我在Windows上用的那个PaddleSpeech的流式语音识别模型。感兴趣的朋友可以去看一眼上期的文章,链接我放在这了。不过不看也行啊,因为上次的代码已经被我改的面目全非了,这次也不会用到上次的代码。《分享本周所学——Linux(Ubuntu)CUDA环境搭建以及借助PaddleSpeech实现实时……》https://blog.csdn.net/weixin_48978134/article/details/125686296?spm=1001.2014.3001.5501 看过我上期文章的朋友们可能要问了:“之前你的那个程序不是已经自带服务化了吗?你干嘛还要自己做一遍呢?”主要有两个原因啊,第一是因为我想练一下给AI做服务化的这个过程,第二是因为PaddleSpeech原本的代码实在是太冗余了,有一大堆各种各样对音频文件的检测什么的,咱也用不到。我想的是先不管服务化这一块,先把我需要的代码捡出来,把不要的删掉。于是,在我研究他们的代码研究了好几个小时之后,终于写出来一个超级简化版。
import logging
import pyaudio
from paddlespeech.server.utils.config import get_config
from paddlespeech.server.engine.asr.online.asr_engine import PaddleASRConnectionHanddler
from paddlespeech.server.engine.engine_pool import get_engine_pool, init_engine_pool
config_path = r'ws_conformer_wenetspeech_application.yaml'
config = get_config(config_path)
init_engine_pool(config)
asr_engine = get_engine_pool()['asr']
handler = PaddleASRConnectionHanddler(asr_engine)
pa = pyaudio.PyAudio()
stream = pa.open(16000,
1,
pyaudio.paInt16,
input=True,
frames_per_buffer=32000)
print('Start recording...')
logging.disable()
while True:
wav = stream.read(32000)
handler.extract_feat(wav)
handler.decode()
text = handler.get_result()
print(text) 这个程序可以调用麦克风录音,然后实时进行流式语音识别。代码和里面的ws_conformer_wenetspeech_application.yaml那个配置文件我都放在Gitee上了,大家可以到我的Gitee仓库下载一下。CSDN/4 · RFdragon/Blog Code - 码云 - 开源中国 (gitee.com)https://gitee.com/rfdragon/blog-code/tree/master/CSDN/4 运行之前得先装一下必要的库。首先是CUDA,在NVIDIA的官网上可以下载。随便选一个你喜欢的版本,我发这篇文章的时候最高版本应该是11.7。安装CUDA比较简单,因为是.exe的程序嘛,直接运行就可以了。CUDA Toolkit Archive | NVIDIA Developerhttps://developer.nvidia.com/cuda-toolkit-archive 然后是CUDNN。根据你刚才装的CUDA版本安装对应版本的CUDNN。cuDNN Download | NVIDIA Developerhttps://developer.nvidia.cn/rdp/cudnn-download
这个下载完是一个zip文件。我们给它解压缩,然后打开解压好的文件,里面应该有三个文件夹,分别是bin、include和lib。我们把这三个文件夹复制到刚刚装CUDA的地方。
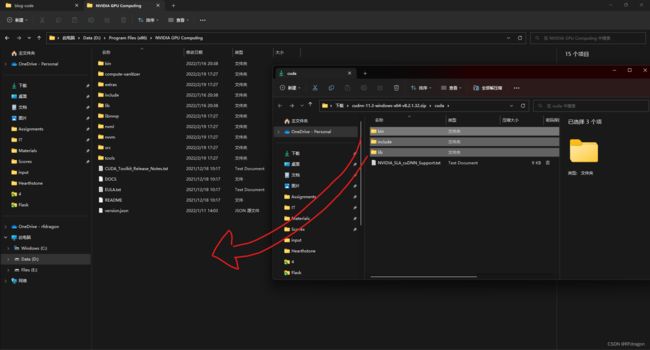
之后装PaddlePaddle。在下面的网页里,找到“快速安装”然后选择你的CUDA版本,把它给出的命令粘到命令行里运行。
飞桨PaddlePaddle-源于产业实践的开源深度学习平台https://www.paddlepaddle.org.cn/
接下来是PyAudio。在这个网页上根据你的Python版本下载对应的whl文件。比如我是用的Python3.9,电脑是64位Windows,就选文件名里带cp39和win_amd64的那个。cp后面的数字代表了Python版本号。
Archived: Python Extension Packages for Windows - Christoph Gohlke (uci.edu)https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyaudio 下载完了之后,命令行运行以下命令:
python -m pip install "xxx.whl" paddlespeech -U -i https://pypi.tuna.tsinghua.edu.cn/simple把xxx.whl改成你下载的文件名,文件名前面记得把文件所在的路径也加上。我这里顺手把装PaddleSpeech的命令也融进来了,这样就不用单独再装PaddleSpeech了。全都安装完了之后重启一下电脑,应该就可以运行那个代码了。
为了方便阅读,我在这里重新放一下代码:
import logging
import pyaudio
from paddlespeech.server.utils.config import get_config
from paddlespeech.server.engine.asr.online.asr_engine import PaddleASRConnectionHanddler
from paddlespeech.server.engine.engine_pool import get_engine_pool, init_engine_pool
config_path = r'ws_conformer_wenetspeech_application.yaml'
config = get_config(config_path)
init_engine_pool(config)
asr_engine = get_engine_pool()['asr']
handler = PaddleASRConnectionHanddler(asr_engine)
pa = pyaudio.PyAudio()
stream = pa.open(16000,
1,
pyaudio.paInt16,
input=True,
frames_per_buffer=32000)
print('Start recording...')
logging.disable()
while True:
wav = stream.read(32000)
handler.extract_feat(wav)
handler.decode()
text = handler.get_result()
print(text)我来用通俗的语言稍微解释一下这个代码啊。首先前5行导包。7~11行是初始化一下语音识别的模型,告诉程序语音识别要用哪个模型,模型参数存在哪了,然后让程序去加载一下模型,这些都是PaddleSpeech里面封装好的,不用我们太操心。12~18行是加载PyAudio这个库,让它去启用麦克风给录音做准备。20行是禁用日志输出,这句话可有可无,我加上这句就是觉得程序打印一大堆日志太烦了。然后20~25行进入循环,每次循环录2秒的音,然后交给模型做一次流式识别,模型返回结果。这个实时录音的版本其实还有简化的余地,如果改成从文件读音频,再把代码可读性稍微降低一点,还可以写出来一个终极无敌简化版:
import soundfile
from paddlespeech.server.utils.config import get_config
from paddlespeech.server.engine.asr.online.asr_engine import PaddleASRConnectionHanddler
from paddlespeech.server.engine.engine_pool import get_engine_pool, init_engine_pool
init_engine_pool(get_config('ws_conformer_wenetspeech_application.yaml'))
handler = PaddleASRConnectionHanddler(get_engine_pool()['asr'])
handler.extract_feat(soundfile.read('1.wav')[0].tobytes())
handler.decode()
print(handler.get_result())很难想象从头到尾只有9行的代码就能解决流式语音识别,连我都佩服自己的代码理解能力和简化能力(狗头)。不过我们待会服务化的时候用的还是上面那个实时录音的代码啊,这段代码大家就当我开个玩笑。
那接下来就要进入服务化环节了。我这里就直接贴代码了,这些代码都能在我上面给的Gitee仓库的链接里找到。先是服务端:
from flask import Flask, request
from paddlespeech.server.utils.config import get_config
from paddlespeech.server.engine.asr.online.asr_engine import PaddleASRConnectionHanddler
from paddlespeech.server.engine.engine_pool import get_engine_pool, init_engine_pool
class Server(PaddleASRConnectionHanddler):
def __init__(self, path):
config = get_config(path)
init_engine_pool(config)
engine = get_engine_pool()['asr']
super(Server, self).__init__(engine)
def execute(self, wav):
self.extract_feat(wav)
self.decode()
text = self.get_result()
return text
path = r'.\ws_conformer_wenetspeech_application.yaml'
server = Server(path)
app = Flask(__name__)
@app.route('/asr', methods=['GET', 'POST'])
def asr():
if request.method == 'POST':
wav = request.stream.read()
text = server.execute(wav)
return text
if __name__ == "__main__":
app.run()这个代码其实没有太多难以理解的地方。大概就是,我把之前代码调用模型的部分封装成了一个类,其中类的初始化对应上面代码的7~11行,然后execute那个函数是用来进行单次的流式识别,对应到上面22~25行。然后是客户端:
import pyaudio
import requests
pa = pyaudio.PyAudio()
stream = pa.open(16000,
1,
pyaudio.paInt16,
input=True,
frames_per_buffer=32000)
while True:
wav = stream.read(32000)
r = requests.post('http://127.0.0.1:5000/asr', data=wav)
print(r.text)这里的stream.read表示一次录音,每次录音的时长是两秒。录音出来得到的数据刚好就是bytes类型,我们甚至都不需要用decode函数解码。如果你能够把前面几节看下来,那理解这两段代码应该不成问题。