Tenstorrent芯片架构浅谈
1. 背景
近些年,市场上的AI芯片层出不穷,无论是初创公司还是科技巨头,都在积极推出AI芯片,从最常见的CPU、GPU到各类Processing Unit(TPU、NPU、APU、DPU等),可谓是百花齐放。究其根源,由于深度学习相关的算法、模型和应用场景均处于高速迭代发展阶段,还未完全收敛,因此对应的计算硬件底座为适配上层应用自然也需要不断更新。其中芯片公司Tenstorrent的芯片架构别具一格,本文尝试一探究竟。
Tenstorrent成立于2016年,是一家总部位于加拿大多伦多的AI芯片公司,公司成立早期业界对其关注很少,自2021年传奇芯片设计大神Jim Keller以CTO身份加入后,公司逐渐公布其独特的芯片架构设计理念,并受到业界越来越多关注。本文结合部分公开演讲和相关paper对其芯片架构进行解读。
2. 产品
Tenstorrent共设计出3款芯片,其中Jawbridge是一款小型测试芯片,Grayskull和Wormhole则是对外商用芯片,可覆盖训练和推理场景。
| Products | Jawbridge | Grayskull | Wormhole |
|---|---|---|---|
| Manufactured | 2019 | 2020 | 2021 |
| IC Process | GF 14nm | GF 12nm | GF 12nm |
| Peak Performance | 1TFLOPS at FP16, 4TOPS at INT8 | 92TFLOPS at FP16, 368TOPS at INT8 | 110TFLOPS at FP16, 430TOPS at INT8 |
| Compute cores | 6 | 120 | 80 |
| SRAM | 6MB total - 1MB/core | 120MB total - 1MB/core | 120MB total - 1.5MB/core |
| DRAM Capacity | unknown | 8GB | 12GB |
| DRAM Bandwidth | unknown | 100GB/s | 384GB/s |
| I/O Interface | 1ch. LPDDR4, PCIe Gen4x4 | 8ch. LPDDR4, PCIe Gen4x16 | 16 ports of 100G Ethernet, 6ch. GDDR6, PCIe Gen4x16 |
| Scale-out Bandwidth | unknown | 192GB/s for NoC | 400GB/s for Ethernet |
| Board Power(TDP) | 1.5W | 65W / 75W | 150W |

以最新的Wormhole芯片为例,其主要包含:
计算核心Tensix core:
5个标量RISC-V CPU:用于运行时发射调度指令和数据
SRAM:作为private memory,用于保存本地计算结果
Packet Manager数据包管理器:包含Tensor形状变换、数据传输和数据路由功能
Packet Compute Engine数据包计算引擎:INT8算力3TOPS,FP16算力0.75TFLOPS
DRAM:片上存储,可被Tensix全局访问
Ethernet接口:用于芯片间互联,便于scale out
PCIE接口:连接Host,与Host进行数据传输
Network on Chip(NoC):数据互联接口,在Ethernet中也含有NoC
System Manager系统管理单元:4个RISC-V CPU,负责中断、时钟、温控等基础功能,及数据路由功能
3. 技术特点
Tenstorrent的芯片架构设计目标是解决模型在训练或推理时无法高效灵活扩展(scale out)的问题,提出2个核心技术点:
3.1 摒弃传统的核间共享式内存架构,采用Multicore Private Memory Model
这样核间及芯片间的数据通信模式在软件栈上是一致的,极大降低了模型分布式训练或推理的开发难度。在用户角度看使用的硬件是一个Device。由于多核间的数据通信不依赖于共享内存,因此芯片重点在硬件层面和软件层面分别加强了数据通信能力。在硬件层自研片上互联Network on Chip(NoC), NoC是2D双向环路结构,支持片内所有核心和片外芯片间通信。在最新的Wormhole架构芯片中,又新增了Ethernet接口专用于芯片间互联。为了实现芯片内和芯片间软件层面通信接口的一致性,Tenstorrent在软件层设计了基于Pipe的数据路由方式,由Graph Compiler生成当前模型下最优的数据路由策略。对比各大AI芯片公司官宣都会大篇幅介绍计算部件,比如各类DSA架构,Tenstorrent的芯片架构介绍文章中更多是在描述非计算硬件部件。从这里也可以看出,数据通信是一等公民(This communication oriented architecture realizes our vision of converged networking and accelerated AI compute on a single device.),片内和片间高效的数据通信能力是Tenstorrent一直强调的重点。
3.2 动态执行
运行时数据压缩:Tenstorrent芯片内有专门用于数据压缩和解压缩的硬件部件,称为Packet Manager Engine,个人认为Packet Manager Engine的引入是该芯片的重要特色。为最大化利用计算资源且最小化使用内存,在计算单元之外,数据都是以压缩方式存储和流动的,这样就可以设计较小容量的private memory,在芯片内多核间及芯片间的数据通信量也随之降低,进而从整体上可以获得更高的性能功耗比。另外,Packet Manager还可以处理reshape/flatten等tensor形状变换操作,且该操作可以与Compute Engine并行执行,时间上可以overlap。
条件执行:该特性尤其在稀疏门控专家混合模型(Sparsely-Gated Mixture of Experts)中应用效果显著。这类模型通过门口网络实现只激活模型的部分结构,因此是一种显著增加模型容量和能力而不必成比例增加计算量的方法。复杂的逻辑控制对CPU而言可以轻松应对,但是对AI芯片而言,大量资源都用于计算部件,逻辑控制相关的部件功能较弱,因此在编程时一般是需要尽量避免出现大量逻辑控制语句。在Tenstorrent芯片架构中,片上的逻辑控制单元和计算单元均可以高效运行,避免了CPU fallback的问题,此处也是该芯片的重要特色。
稀疏计算:除了支持常规的对权重进行稀疏化之外,还支持对激活值进行分块稀疏,进而降低计算量。
动态混合精度:可以在运行时或AOT阶段设置每个算子的计算精度。该技术在主流深度学习框架中都有实现,因此个人认为这项技术并无特色。
Tenstorrent通过软硬协同设计方式,将数据并行和模型并行的部分功能实现下沉到硬件层,有效解决了横向扩展问题,这样就可以替代当前主流深度学习框架在分布式实现方面的大量编码工作,进而降低了深度学习框架的开发和使用门槛。同时,硬件的变化并没有降低软件栈的通用性,其软件栈支持PyTorch等主流框架。另一方面,芯片具有高度模块化,多个芯片可通过标准以太网端口连接在一起,进而扩展成大型AI网络。由于芯片内已集成NoC,因此这种扩展并不需要额外的交换机,因此扩展灵活度很高。
对比GPU,Tenstorrent官网提到其芯片编程更友好、扩展性更好和更擅长处理稀疏计算和控制流计算场景。(Compared to GPUs, our processors are easier to program, scale better, and excel at handling run-time sparsity and conditional computation.)
4. Tenstorrent官网示例分析
由于无法拿到芯片进行实际测试,网上也几乎没有第三方对Tenstorrent芯片的评测数据。因此我们只能查看Tenstorrent官网示例了解具体如何使用其芯片。Tenstorrent官网示例包含Grayskull板卡、Turnkey工作站/服务器和DevCloud云资源三种,Grayskull板卡的使用说明相对详细。
Grayskull板卡:基于Ubuntu20.04,按常规流程插入该板卡,并加电,然后下载并安装驱动,不过目前驱动下载链接尚未开放,只好先跳过该步骤。官方提供了Dockerfile用于构建编译运行环境。在/tenstorrent/releases/tests下有三个文件:
hello_tt.yaml:配置文件,包括硬件架构信息、编译器配置信息、运行时配置信息等hello_tt.py:模型定义文件,利用 Torch 定义一个模型,并设置该模型的并行策略set_scalar_input.py:生成模型输入数据
hello_tt.yaml文件内容如下:
test:
activations-config:
arguments:
input-shapes: &input-shapes [[1, 1]]
file-name: releases/tests/activations/set_scalar_input.py # 生成输入数据
arch-config: releases/tests/config/grayskull_arch.yaml # Grayskull 芯片架构配置文件
comparison-config: releases/tests/config/grayskull_comparison.yaml
compiler-config:
- releases/tests/config/grayskull_compiler.yaml # 编译器配置文件
- num-fidelity-phases-default: 4
graph-config:
file-name: releases/models/pytorch/hello-tt.py # 模型定义文件
onnx: false
runtime-config:
- releases/tests/config/grayskull_runtime.yaml # 运行时配置文件
- l1-format: FP16 # 运行时精度hello_tt.py文件内容如下,主要是定义了一个2层网络,计算过程为 (((0.8 * 1.58) - 0.14) * 2.45) - 0.11 = 2.6438。

# hello world inspired from
# https://nestedsoftware.com/2019/08/15/pytorch-hello-world-37mo.156165.html
# just one step of the forward pass
# one input, one hidden, and one output
import torch
import torch.nn as nn
import torch.nn.functional as F
import sage.api as tt_api # Import Tenstorrent Sage compiler's public API
def get_model(par_strategy="RowParallel", core_count=4,):
# 1. 指定计算核分区方式,此处指定为行并行,即模型中的算子会在行方向的 tensix cores上执行
# 2. 指定使用 4 个 tensix cores
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 设置隐含层数据
self.hidden_layer = nn.Linear(1, 1)
self.hidden_layer.weight = torch.nn.Parameter(torch.tensor([[1.58]]))
self.hidden_layer.bias = torch.nn.Parameter(torch.tensor([-0.14]))
# 设置输出层数据
self.output_layer = nn.Linear(1, 1)
self.output_layer.weight = torch.nn.Parameter(torch.tensor([[2.45]]))
self.output_layer.bias = torch.nn.Parameter(torch.tensor([-0.11]))
def forward(self, x):
# 构建前向计算图
x = F.relu(self.hidden_layer(x))
x = F.relu(self.output_layer(x))
print('output', x)
return x
model = Net().eval()
# Set parallelization strategy
# 指定模型运行在哪些 tensix cores上,此处为在(0,0)到(3,0)这 4 个行方向的 tensix cores 上执行计算,假定一个 core 计算一层
tt_api.set_parallelization_strat(model, cores=((0, 0), (core_count - 1, 0)), strategy=par_strategy)
return model从如上代码中可以看出,用户可以灵活设定整个模型使用的计算核数以及并行方式。示例模型共4个节点,分配了芯片中列方向上的4个连续计算核心来执行(如下图所示),剩余计算核心可以并发执行其他模型的计算任务。

我们可以分析更常见的模型结构,如下图,左侧是多层级联结构,右侧是多分支结构。由于其在定义每个算子时,除了定义算法实现外,还需要提供算子的性能信息,如内存占用、计算资源占用、与临近节点的连接关系等信息。通过这些信息,编译器就可以生成一个当前最优的算子到硬件的映射图。例如,下图(a)中每个pipeline对应的计算核心是不同的;下图(b)中,由于模型中的4个分支是无数据依赖关系的,因此这4个节点可以并行执行。

tether run -d grayskull -i hello_tt.yaml tether 是一个运行集成工具,可以用来编译和运行模型。 更多细节可以查阅 /tenstorrent/releases/UserGuide.md
5. 疑惑
受限于当前有限公开的技术资料,我们暂时无法深层次剖析Tenstorrent芯片架构。目前关于该芯片的设计架构,笔者还存在一些疑惑:
在Tenstorrent芯片构成的网络中,存在4种拓扑结构,比如芯片内多核间、芯片间、服务器间和机架间。这4种拓扑结构对应的通信带宽和网络延迟肯定各不相同。因此需要软件栈中的Graph Compiler生成一个多种约束条件下的cost model,基于该cost model生成一个在当前运行环境下最优的算子与硬件的映射关系图。笔者认为Graph Compiler的实现颇为重要,但鲜有公开资料介绍这方面信息。官方表示会开源其软件栈,但未给出具体时间点。
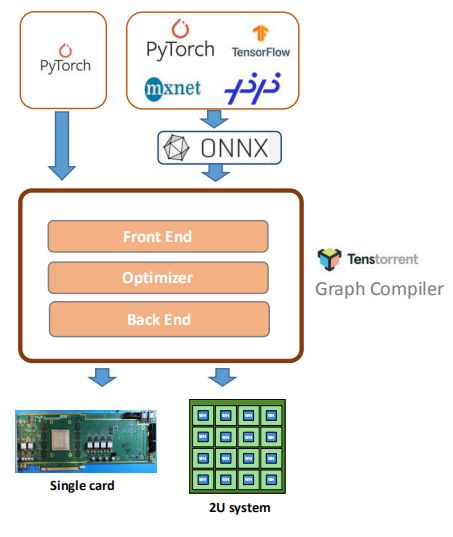
关于开发者生态,当前深度学习相关软件大都是将NV GPU作为第一优先级进行适配支持。Tenstorrent芯片的软件栈相对独立,虽然可以支持PyTorch、TensorFlow等框架,但如何推动这些深度学习框架在Tenstorrent芯片上适配开发,并针对性优化,路途漫漫。
6. 总结
深度学习AI芯片设计需要兼顾性能、功耗、可编程性、可扩展性和成本等多方面的因素,因此如果对比单点指标,无法科学评价芯片的整体水平。我们分析了Tenstorrent芯片产品和技术特点,并尝试从官网示例教程中寻找更多细节信息,最后给出三个关心且存疑的问题,希望与各位业界同仁一同探讨。
最后,依然期待大家支持和关注Adlik的Github仓库哦。

Adlik Github仓库
参考
[1] L. Bajić and J. Vasiljević, “Compute Substrate for Software 2.0”, Hot Chips 32, 2020.
[2] D. Ignjatović, Daniel W. Bailey, Ljubisa Bajić, “The Wormhole AI Training Processor”, ISSCC 2022 Session 21: Highlighted Chip Releases: Digital/ML
[3] L. Bajić, “Finding the Right Compute Substrate for Software 2.0”, Linley Spring Processor Conference, 2020.
[4] D. Ignjatović and D. Capalija, “Scale-out First Microarchitecture for Efficient AI Training”, Linley Spring Processor Conference, 2021.
[5] Dylan Patel, https://semianalysis.substack.com/p/tenstorrent-wormhole-analysis-a-scale?s=r
[6] OneFlow, Tenstorrent虫洞分析:挑战英伟达的新玩家?