运用Pandas对客户数据RFM分析应用
RFM模型是衡量客户价值和客户创利能力的重要工具和手段。该模型通过一个客户的近期购买行为、购买的总体频率以及花了多少钱三项指标来描述该客户的价值状况。
Recency:最近一次消费,即上一次交易距今多少天,反应了客户是否流失;
Frequency:消费频率,一段时间内客户的消费频率,反应了客户的消费活跃度;
Monetary:消费金额,一段时间内客户消费总金额,反应了客户价值
根据 RFM 这 3个 Dimension,可以分为8种客户类型,如下图

对于RFM 客户分析模型来说,只要数据中有客户名,消费日期和消费金额即可。
计算RFM值
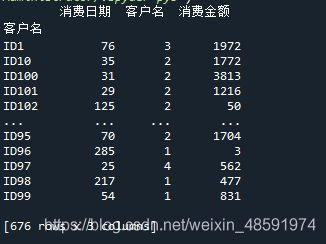
以下为某餐饮集团其中部分客户数据源,客户名用 ID X 代替真实名字。

import pandas as pd
pd.set_option(‘display.unicode.ambiguous_as_wide’,True)
pd.set_option(‘display.unicode.east_asian_width’,True)
df = pd.read_excel(‘xxx.xlsx’) # xxx 为实际导入的文件名
print(df)
通过 Pandas 快速读取数据源文件,得出如下数据结构,如下图所示,共有1692 行,3列的 array

还可以调用 info() 和 describe() 方法,查看数据源的大致信息。
调用info() 方法,同样可以看到有多少行多少列,列名,有没有数据缺失,如下图1
调用describe()方法, 可以快速统计数据源各种统计的结果,如下图2
count: 数据源总数
mean : 平均值
std : 标准差值
min : 最小值
25% 50% 75% 位置的值
max : 最大值


R(最近一次消费)需要日期间的计算,所以需要对数据进行一些处理,调用 to_datetime() 方法将消费日期这一列从字符串格式转成日期格式。
df[‘消费日期’] = pd.to_datetime(df[‘消费日期’])
例如计算 2020-12-31 和 2020-12-01 相差多少天,可以写成
(pd.to_datetime(‘2019-12-31’) - pd.to_datetime(‘2019-12-01’)).days
计算之后得到的是一个日期对象,然后通过访问里面的 days 属性就可以得到天数了。
调用groupby()方法 按用客户名分组,然后再调用 agg() 方法一次性计算出 RFM 的值。agg() 方法是 pandas 中的聚合方法,可以针对多列同时进行操作。
给 agg() 方法传入一个dict,dict 的 Key是要进行操作的列名,Value为一个函数。函数的 param 是每一列中的数据,函数的返回值将替换原来的值。 agg() 方法也就是同时针对多列进行不同操作的 apply() 方法。
数据源中是 2020 年的消费数据,不包含 2021年的数据,因此在计算 R(最近一次消费)时应该用 2019-12-31 减去用户的最近一次消费日期。日期越往后越大,调用 max() 方法可以找到该客户最近一次消费日期,最终得到的天数就是 R 的值。
由于时间跨度一样,都是一年,所以 F (消费频率)可以直接用每个客户的消费数量表示。按客户名分组后,客户名的个数就是该客户的订单数,所以调用 len() 函数可以直接得到 F 的值。
最后的 M(消费金额),分组后直接调用 sum() 方法求和即可得到每个客户这一年的消费金额。
为了尽量简洁代码,直接采用 匿名函数 lambda,具体方法如下:
df_rfm = df.groupby(‘用户名’).agg({
‘订单日期’: lambda x: (pd.to_datetime(‘2019-12-31’) - x.max()).days, # 计算 R
‘用户名’: lambda x: len(x),
‘订单金额’: lambda x: x.sum()
})
最终得到的新数据如下图 :
调用 rename() 方法更改列名,使数据源能更加直观看到 R,F,M 值,加param inplace = True, 直接修改原数据。
columns param 传入一个dict , dict 的 Key 是原列表名,对应的Value是修改后的列名。
df_rfm.rename(columns={‘消费日期’: ‘R’, ‘客户名’: ‘F’, ‘消费金额’: ‘M’}, inplace=True)
得出更改后的新数据,如下图:

RFM 打分
根据 RFM 的值进行打分,按照数据的分位数来进行分值的划分。
首先调用 describe() 观察数据统计的信息,如下图:

我们根据图中的分位数来进行分值的划分。以 R 为例,将分为 0 到 28、28 到 58、58 到 118 和 118 到 364 四个区间。因为 R(最近一次消费)越小,说明用户越活跃,打分就越高。因此 R 的打分规则如下:
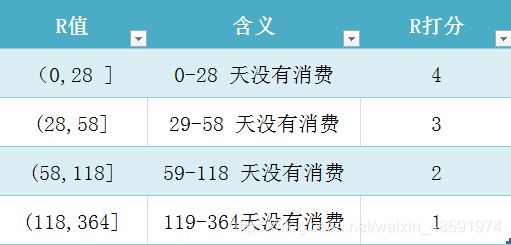
注意:以上R值采取的是左开右闭法则
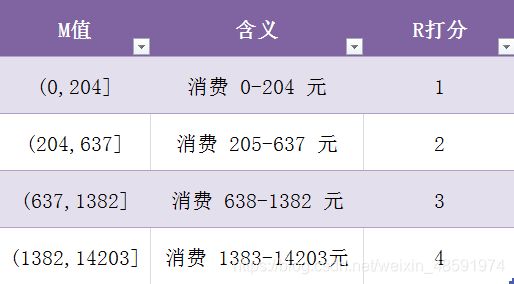
同理,F 和 M 的打分规则如下2个图 :

调用 apply() 方法,定义一个名为 r_score 的函数,然后将 R 值打分的规则写到函数里,最后传给 apply() 方法应用到 R 列上。
def r_score(x):
if x <= 28:
return 4
elif x <= 58:
return 3
elif x <= 118:
return 2
else:
return 1
df_rfm[‘r_score’] = df_rfm[‘R’].apply(r_score)
同理,对 F, M 定义函数
def f_score(x):
if x <= 1:
return 1
elif x <= 2:
return 2
elif x <= 3:
return 3
else:
return 4
df_rfm[‘f_score’] = df_rfm[‘F’].apply(f_score)
def m_score(x):
if x <= 204:
return 1
elif x <= 637:
return 2
elif x <= 1382:
return 3
else:
return 4
df_rfm[‘m_score’] = df_rfm[‘M’].apply(m_score)
执行代码后,
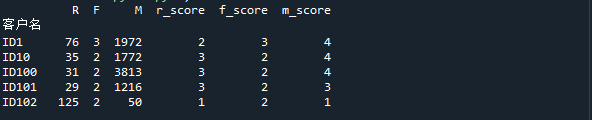
将大于平均值的定义为高,小于等于平均值的定义为低, 调用 apply() 方法,用 lambda 函数实现,最后得出如下图。
df_rfm[‘R高低’] = df_rfm[‘r_score’].apply(lambda x: ‘高’ if x > df_rfm[‘r_score’].mean() else ‘低’)
df_rfm[‘F高低’] = df_rfm[‘f_score’].apply(lambda x: ‘高’ if x > df_rfm[‘f_score’].mean() else ‘低’)
df_rfm[‘M高低’] = df_rfm[‘m_score’].apply(lambda x: ‘高’ if x > df_rfm[‘m_score’].mean() else ‘低’)
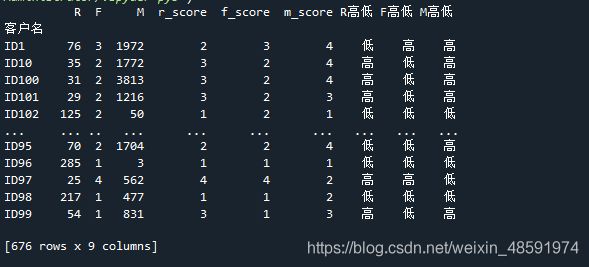
先将 R 高低、F 高低 和 M 高低 加起来,也就是拼接成 高低高 这种字符串,结果得出如下图。
df_rfm[‘RFM’] = df_rfm[‘R高低’] + df_rfm[‘F高低’] + df_rfm[‘M高低’]
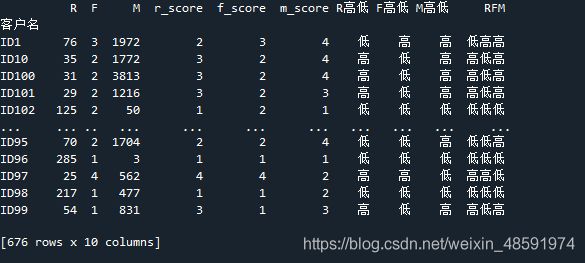
直接分析 RFM 这列的字符串排列就能知道该用户是哪种类型的,加上类型标签的代码如下:
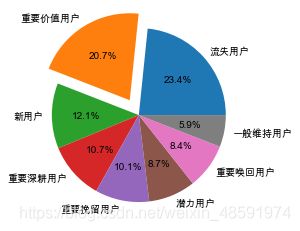
def rfm_type(x):
if x == ‘高高高’:
return ‘重要价值用户’
elif x == ‘低高高’:
return ‘重要唤回用户’
elif x == ‘高低高’:
return ‘重要深耕用户’
elif x == ‘低低高’:
return ‘重要挽留用户’
elif x == ‘高高低’:
return ‘潜力用户’
elif x == ‘高低低’:
return ‘新用户’
elif x == ‘低高低’:
return ‘一般维持用户’
elif x == ‘低低低’:
return ‘流失用户’
df_rfm[‘用户类型’] = df_rfm[‘RFM’].apply(rfm_type)
最终的 RFM 模型如下图:

RFM 模型结果分析
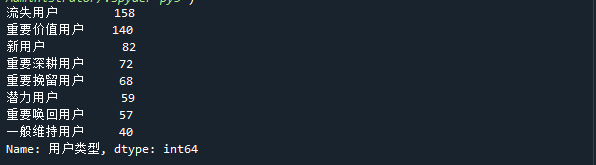
首先观察每种类型的用户分别有多少人,调用value_counts() 方法
df_rfm[‘用户类型’].value_counts()
得出如下图的统计数据,
value_counts() 方法返回的数据类型是 一个一维数据的Series,左边是数据标签(index),右边是对应的数据。我们可以使用 reset_index() 方法将现有的数据标签(index)变成数据,并使用默认的数字索引(从 0 开始)作为新的索引。也就是 reset_index() 方法将 Series 变成了 二维的数据DataFrame,如下图:
df_count = df_rfm[‘用户类型’].value_counts().reset_index()
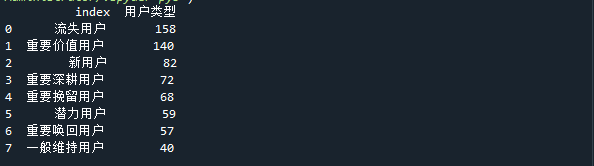
还要调用 rename() 方法把列明更改,如下图
df_count.rename(columns={‘index’: ‘用户类型’, ‘用户类型’: ‘人数’}, inplace=True)
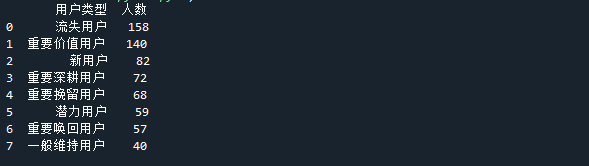
最后给数据再加一列,计算出每种类型的用户的占比分别是多少,如下图:
df_count[‘占比’] = df_count[‘人数’] / df_count[‘人数’].sum()
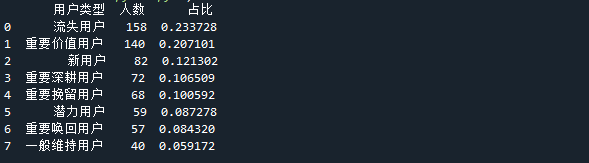
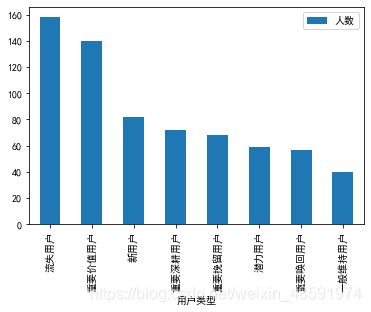
最后,用数据可视化的方式展示出来就更直观了。pandas 本身也提供了绘图功能(本质上还是调用了 matplotlib),得出最后柱形图。
import matplotlib.pyplot as plt
df_count.plot(kind=‘bar’, x=‘用户类型’, y=[‘人数’])
plt.show()
也可以通过绘制饼形图,如下
data = df_count[‘人数’]
labels = df_count[‘用户类型’]
explode = (0,0.2,0,0,0,0,0,0)
plt.pie(data,labels=labels,explode=explode,autopct=’%0.1f%%’)
plt.show()