应用层——Web和HTTP
目录
1. HTTP概况
1.1 Web页面简介
1.2 URL-统一资源定位器
1.3 HTTP协议
2. HTTP连接的两种类型
2.1 HTTP非持久性连接(Non-persistent HTTP)
2.2 HTTP持久性连接(Persistent HTTP)
2.2.1 无流水(pipelining)的持久性连接
2.2.2 带有流水机制的持久性连接
3. HTTP报文格式
3.1 HTTP请求报文
3.2 HTTP响应报文
4. Cookie技术
5. Web缓存/代理服务器技术
前言:20世纪90年代以前,因特网的主要使用者还是研究人员、学者和大学生,并不为大多数人所知。到了20世纪90年代初期,一个主要的新型应用万维网(World Wide Web)登上了舞台,极大改变了人们与工作环境内外交流的方式,Web不同于无线电广播和电视,它能够按需操作,轻松满足人们的搜索需求、视听需求等,为人们提供便捷的应用层服务
1. HTTP概况
1.1 Web页面简介
Web的应用层协议是超文本传输协议(HyperText Transfer Protocol , HTTP),它是Web的核心,在[RFC 1945] 和 [RFC 2616]中进行定义
Web页面(Web page)也叫做文档,是由对象(object)构成的,一个Web页面通常包含多个对象,这里有必要解释一下对象的概念
对象:就是一个文件,可以通过URL地址寻址,例如
- HTML文件、JPEG图片、视频文件、动态脚本等
多数的Web页面还包含一个HTML基本文件(base HTML file)
基本HTML文件:包含对其他对象引用的链接
因此,多数的Web页面会含有一个HTML基本文件和多个引用的对象 。例如:如果一个Web页面包含HTML文本和5个JPEG图形,那么这个Web页面有6个对象——一个HTML基本文件加5个JPEG图形
1.2 URL - 统一资源定位器
我们知道,通过IP地址+端口号可以唯一确定一个进程,但无法确定一个资源,这些所谓的网络资源都是存在于网络中的一台主机上,以文件方式保存的
HTML基本文件通过对象的URL(Uniform Resoure Locator) (定义在[RFC 1738]中)来引用页面中的其他对象,每个URL能唯一标识一个因特网上的文件,URL也就是我们平常所说的“网址”
每个URL地址由两部分构成:存放对象的服务器主机名 + 对象的路径名
例如:对于这样一个URL:www.someschool.com/someDept/pic.gif

更具体的来说,一个URL可细分为多个部分

- 协议方案名:请求该资源所使用的协议,这里的就是HTTP协议。除此之外,还有ftp、mailto、telnet、file等
- 登录信息(认证):指定用户名或密码作为从服务器端获取资源时必要的登录信息,现在很少使用
- 服务器地址:也叫域名,可解析为ip地址,找到资源所在的服务器
- 服务器端口号:指定服务器连接的网络端口号。是可选的,若用户省略则自动使用默认端口号,http服务器默认端口是80
- 带层次的文件路径:指定服务器上的文件路径来定位指定的资源
- 查询字符串:针对已指定的文件路径内的资源,可以使用查询字符串传入任意参数,此项可选
- 片段标识符:可以标记出已获取资源中的子资源。是可选项
https://blog.csdn.net/weixin_58165485/article/details/128599605?spm=1001.2014.3001.5501
协议 域名 文件路径 urlencode(url转码)
像 / ? : 等这样的字符,已经被url当做特殊意义理解了,也就是说这些符号在URL中是有自己特殊的意义的,因此这些字符不能随意出现。比如,某个参数中需要带有这些特殊字符,就必须先对特殊字符进行转义
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY格式
例如在百度中搜索C++, 得到的URL中 "wd="后面跟的是搜索的关键字,可以看到关键字变成了 C%2B%2B,这是因为,"+" 被转义成了 "%2B"

‘+’ 的ascii码为43,转为16进制是 2B,因此被编码为 %2B
1.3 HTTP协议
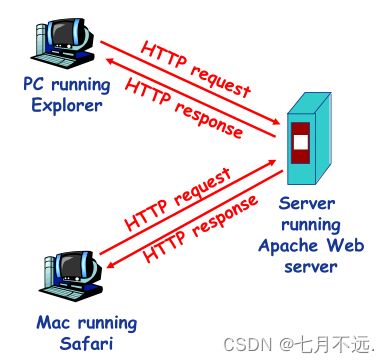
HTTP协议是基于客户-服务器结构(C/S)的
- 客户 — Browser:请求、接收、展示Web对象
- 服务器 — Web Server:响应客户的请求,发送对象
HTTP协议分为两个版本(区别后面介绍):
- HTTP1.0(RFC 1945)
- HTTP1.1(RFC 2068)
HTTP协议使用TCP传输服务
- 服务器在80端口等待客户的请求
- 浏览器发起到服务器的TCP连接(创建套接字Socket)
- 服务器接受来自浏览器的TCP连接
- 浏览器(HTTP客户端)与Web服务器(HTTP服务器)交换HTTP消息
- 关闭TCP连接
HTTP协议是无状态的
- 服务器不维护任何有关客户端过去所发请求的信息
HTTP协议是无连接的
- 虽然HTTP使用了TCP协议,但通信的双方在交换HTTP报文前不需要事先建立HTTP连接
2. HTTP连接的两种类型
在一个客户-服务器结构中,通常采用TCP进行,客户端对服务器发出一系列请求,而服务器会对这一系列请求逐个进行响应,这种响应有两种方式
- 每个请求/响应都花费一个TCP连接 —— 非持续连接
- 所有的请求/响应共用一个TCP连接 —— 持续连接
2.1 HTTP非持久性连接(Non-persistent HTTP)
采用非持久性连接的HTTP的特点是
- 每个TCP连接最多允许传输一个对象
- 每个对象的传输都需要单独建立一个TCP连接
- HTTP/1.0版本使用非持久性连接
假定用户在浏览器中输入URL——www.someSchool.edu/someDepartment/home.index,包含文本和指向10个 jpeg 图片的链接

在这个例子中,由于采用非持久连接,每个TCP连接在服务器发送一个对象后关闭,即该连接并不为其他的对象而持续下来,因此每个jpeg对象都必须重新建立和断开一个TCP连接,总共需要11个TCP连接
接下来估算一个TCP连接的时间,这个时间包括从客户端请求HTML基本文件起到该客户收到整个文件为止所花费的时间
往返时间RTT(Round Trip Time):从客户端发送一个很小的数据包到服务器并返回所经历的时间
RTT包括分组的传播时延、排队时延以及分组处理时延等
响应时间(Response time)
- 发起、建立TCP连接:1个RTT
- 发送HTTP请求消息到HTTP响应消息的前几个字节到达:1个RTT
- 响应消息中所含的文件/对象传输时间

因此响应的总时间为:2RTT + 文件发送时间
非持久连接存在着一些问题需要改进
- 每个对象需要2个RTT,效率很低
- 操作系统需要为每个TCP连接开销资源(overhead)
2.2 HTTP持久性连接(Persistent HTTP)
采用持久性连接的特点是
- 每个TCP连接允许传输多个对象
- 服务器在发送响应后仍保持这条连接,后续报文可以在这条连接上传送
- HTTP 1.1版本默认使用持久性连接
2.2.1 无流水(pipelining)的持久性连接
对于非流水的持久性连接,客户在收到前一个响应后才能发出下一个请求,也就是说虽然后续的请求和响应报文能够使用一条TCP连接,但是必须按照如下规则通信
- 客户端发出一个请求
- 服务器发出一个响应
- 客户端接收响应,并发出下一个请求

由于不需要重新建立TCP连接,因此每个被引用的对象耗时1个RTT
2.2.2 带有流水机制的持久性连接
HTTP/1.1的默认模式是使用带流水线的持久连接,这种情况下,客户每遇到一个对象引用就立即发出一个请求,因而客户可以逐个地连续发出对各个引用对象的请求。
如果所有的请求和响应都是连续发送的,那么所有引用的对象共计经历一个RTT延迟,而不是像非流水线那样,每个引用都必须有一个RTT延迟
也就是说,假设客户端请求有10个jpeg图形,服务器端收到请求后,无需等客户端确认,一次性将10个文件流水线式地传送给客户端,花费一个RTT
习题
假设你在浏览某网页时点击了一个超链接,URL为“https://www.kicker.com.cn/index.html”,且该URL对应的IP地址在你的计算机上没有缓存;文件index.html引用了8个小图像。域名解析过程中,无等待的一次DNS解析请求与响应时间记为RTTd,HTTP请求传输Web对象过程的一次往返时间记为RTTh。请回答下列问题:
1)你的浏览器解析到URL对应的IP地址的最短时间是多少?最长时间是多少?
2)若浏览器没有配置并行TCP连接,则基于HTTP1.0获取URL链接Web页完整内容(包括引用的图像,下同)需要多长时间(不包括域名解析时间,下同)?
3) 若浏览器配置5个并行TCP连接,则基于HTTP1.0获取URL链接Web页完整内容需要多长时间?
4) 若浏览器没有配置并行TCP连接,则基于非流水模式的HTTP1.1获取URL链接Web页完整内容需要多长时间?基于流水模式的HTTP1.1获取URL链接Web页完整内容需要多长时间?
1. DNS域名解析在以后会涉及,由于URL中有一个顶级域名(com),一个二级域名(com)和一个三级域名(kicker)和一个四级域名(www),因此最短时间是本地域名服务器内有缓存:时间为RTTd,最长时间为主机向本地域名服务器发起请求,本地域名服务器再发起四次域名解析:时间为5RTTd
2. 基于HTTP1.0,则使用非持久性连接,一个对象有2RTT延迟,共有一个html+8个图像=9个对象,因此时间为18RTTh
3. 基于HTTP1.0,且设有五个并行TCP连接,也就是说一次可以传输5个对象,获得html需要两个RTT,8个对象需要两次传输,需要4RTT,因此为6RTTh
4. 基于非流水的HTTP1.1,发起、建立TCP连接1个RTT,之后每个对象花费1个RTT,共10RTTh
基于流水的HTTP1.1,发起、建立TCP1个RTT,传送html花费一个RTT,剩下的所有图像共花费一个RTT,共3RTTh
(注意,对于html的请求是TCP第三次握手时携带的,只有服务器收到html请求才能给客户端发送图像,因此html不能和图像一起发送)
3. HTTP报文格式
HTTP规范 [RFC 1945; RFC 2616; RFC7540]包含了对HTTP报文的格式的定义。HTTP报文格式有两种:请求报文和响应报文
无论是请求还是响应,HTTP基本上都是以行(\n)为单位进行报文构建的
3.1 HTTP请求报文
HTTP请求报文由三部分组成,一个简单的请求报文如下
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
User-agent: Mozilla/5.0
Connection: close
Accept-language: fr
该报文是由普通ASCII文本所写的,因此人直接可读,每行最后的cr和lf分别代表回车和换行
HTTP请求报文的格式如下

请求行(request line)
第一行叫做请求行,有3个字段——方法(method)字段、URL字段和HTTP版本(version)字段,每个字段之间以空格(sp)隔开
- 方法字段可以取几种不同的值,这些值代表对所请求对象的操作,包括:GET、POST、HEAD、PUT和DELETE(HTTP/1.0只有前三种)
| 方法(操作) | 意 义 |
| GET | 请求读取由URL标识的信息,URL字段带有请求对象的标识,实体部分为空 |
| POST | 给服务器添加信息(如注释),在请求消息的实体中上传客户端的输入 |
| HEAD | 获得文件首部,请Server不要将所请求的对象放入响应消息中 |
| PUT | 允许用户或应用程序将实体部分的对象上传到服务器指定路径 |
| DELETE | 允许用户或应用程序删除URL字段指定的Web服务器上的对象 |
- URL字段,一般是对象的URL去掉域名之后的内容
- HTTP版本字段,说明使用的HTTP版本,一般为HTTP/1.1
首部行(header lines)
第一行后面跟着的几行称为首部行,也叫用来说明浏览器、服务器或报文主题的一些信息。首部可以有几行,也可以不使用,首部行的格式为
key:value \n
对于给出的示例
- Host: www.someschool.edu 指明了要请求的对象所在的主机
- User-agent: Mozilla/5.0 指明用户代理,即向服务器发送请求的浏览器类型,这里是(Firefox浏览器)
- Connection: close 告诉服务器不要麻烦地使用持续连接,发送完被请求的对象后就关闭连接
- Accept-language: fr 标识用户想得到该对象的法语版本
空行(blank line)
将首部行和实体主体分隔开,在报文解包时,客户端或服务器读到这个空行就代表首部行已经结束,下面读的是实体部分
实体主体(entity body)
这部分也称为请求正文,在请求报文中一般不使用这个字段,例如使用GET方法时实体主体为空,而仅在使用POST方法时才使用该实体主体
当用户提交表单时,HTTP客户常使用POST方法,比如在搜索引擎中搜索某个关键字并且使用POST方法发出HTTP请求,那么这个关键字就出现在请求报文的实体部分
当然,用表单生成的请求报文不是必须使用POST方法,相反,HTML表单更多使用的是GET方法,并在(表单字段中)所请求的URL中包括输入的数据
3.2 HTTP响应报文
和请求报文类似,HTTP响应报文也由三部分组成,其中实体部分是报文的主要部分,一个简单的响应报文如下(作为上述请求报文的响应)
HTTP/1.1 200 OK
Connection: closeDate: Tue, 09 Aug 2011 15:44:04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT
Content-Length: 6821
Content-Type: text/html
(data data data data data ...)
HTTP响应报文的格式如下

状态行( status line)
响应报文的第一行称为状态行 ,有3个字段——协议版本字段、状态码和相应状态信息,每个字段之间以空格(sp)隔开
- 协议版本字段指明了使用的HTTP协议类型
- 状态码及状态信息指示了请求的结果,常见的有如下几种状态
| 状态码 | 请求结果 |
| 200 OK | 请求成功,信息在返回的相应报文中 |
| 301 Moved Permanently | 请求的对象已经被永久转移了,新的URL定义在响应报文的Location首部行中,客户软件将自动获取新的URL |
| 400 Bad Request | 一个通用的差错代码,指示该请求不能被服务器理解 |
| 404 Not Found | 被请求的文档不在服务器上 |
| 505 HTTP Version | 服务器不支持请求报文所使用的HTTP协议版本 |

首部行(header lines)
响应报文的首部行格式和请求报文相同,区别是首部行内容略有差异
对于给出的示例
- Connection: close 告诉客户,发送完报文后将关闭该TCP连接
- Date: Tue, 09 Aug 2011 15:44:04 GMT 指示服务器产生并发送该响应报文的日期和时间
- Server: Apache/2.2.3 (CentOS) 指示该报文由一台Apache Web服务器产生
- Last-Modified: Tue, 09 Aug 2011 15:11:03 GMT 指示对象创建或最后修改的日期
- Content-Length: 6821 指示被发送对象中的字节数
- Content-Type: text/html 指示实体部分中的对象是HTML文本
空行(blank line)
和请求报文相同
实体主体(entity body)
这部分也称为响应正文,服务器响应给客户的主要内容在实体中,例如html、css、js、音/视频和图片等,当然响应报文中也可能没有实体主体
4. Cookie技术
由于HTTP是无状态的,服务器端并不会记录与客户有关的信息,但往往服务器希望能够识别用户,掌握客户端的状态如网上购物等,这就需要用到cookie技术,在[RFC 6265]中定义
Cookie:某些网站为了辨别用户身份、进行session跟踪而储存在用户本地终端上的数据(通常经过加密)
Cookie的组件
- HTTP响应消息的cookie头部行
- HTTP请求消息的cookie头部行
- 保存在客户端主机上的cookie文件,由浏览器管理
- Web服务器端的后台数据库
下面给出一个cookie工作的例子
在客户端的主机上会有一个cookie文件,假设A曾经访问过ebay站点,那么在器本地的cookie文件中就会有一个cookie表项,其格式是 站点:识别码
现在假设A第一次访问Amazon.com,cookie会进行如下工作
- A的主机向Amazon.com服务器发送请求报文,当报文到达服务器时,服务器为其产生一个唯一的识别码,比如说是1678,并将这个用户与识别码关联起来放入后台数据库
- 接下来服务器用一个包含Set-cookie首部的HTTP响应报文对A的浏览器进行响应,Set-cookie首部中含有该识别码,该首部行可能是(Set-cookie:1678)
- A的浏览器收到这个响应报文后会看到Set-cookie首部,并在本地的cookie文件中增加一行——包括服务器的主机名和Set-cookie中的识别码1678
- 之后A继续浏览Amazon网站,本地的浏览器会先检查本地的cookie文件,如果有这个网站,那么就会在所有的请求报文中添加一个首部行cookie:1678
- 这样,服务器通过请求报文中的识别码,就能追踪A所有的访问记录和维护购物车列表

Cookie能够用于:身份认证、购物车、推荐、Web e-mail等,但就隐私问题仍存在争议
5. Web缓存/代理服务器技术
Web缓存器(Web cache)也叫代理服务器(proxy server),它是能够代表初始Web服务器来满足HTTP请求的网络实体。Web缓存器有自己的磁盘存储空间,并在存储空间中保存最近请求过的对象的实体
Web缓存可以类比于计算机体系中的缓存——作为下层存储器的备份,在访存时先在缓存中查找,如果cache命中,便能够大大加快访存效率。Web缓存能够缓存一部分原始Web上的内容,当用户需要访问Web时,如果恰好在Web缓存中,能够提高请求速度
功能:在不访问服务器的前提下满足客户端的HTTP请求

来看一个Web缓存器工作的例子
假设A访问 http://www.someschool.edu/campus.gif,将会发生下面的情况
- 浏览器创建一个到Web缓存的TCP连接(不和原始的Web建立连接),并向Web缓存器中的对象发送一个HTTP请求
- Web缓存器进行检查,如果本地有该对象的副本,则在响应报文中返回该对象
- 如果没有该对象,它就打开一个与该对象的初始服务器的TCP连接,由Web缓存器发送一个HTTP请求报文来请求该对象
- 收到对象后,Web缓存器先在本地缓存一份该对象的副本,并将该对象返回给浏览器
Web缓存器既是服务器(对于浏览器而言),又是客户(对于原始Web而言)
Web缓存器通常由ISP(Internet服务提供商)购买并安装。例如,一所大学可能在它的校园网上安装一台缓存器,并且将所有校园网上的用户浏览器配置为指向它
使用Web缓存的好处是
- 缩短客户请求的响应时间
- 减少机构/组织的流量
- 在大范围内(Internet)实现有效的内容分发
接下来展示一个Web缓存提高效率的例子
- 对象的平均大小=100,000比特
- 机构网络中的浏览器平均每秒有15个到原始服务器的请求
- 从机构路由器到原始服务器的往返延迟=2秒

网络性能分析
- 局域网(LAN)的利用率=15% (15×100000 / 10Mbps)
- 接入互联网的链路的利用率=100% (15×100000/1.5Mbps)
- 总的延迟=互联网上的延迟+访问延迟+局域网延迟=2秒+几分钟+几微秒
解决方案1:提升互联网接入带宽=10Mbps

网络性能分析
- 局域网(LAN)的利用率=15% (15×100000 / 10Mbps)
- 接入互联网的链路的利用率=15% (15×100000/10Mbps)
- 总的延迟=互联网上的延迟+访问延迟+局域网
- 延迟=2秒+几微秒+几微秒
问题是成本太高
解决方案2:安装Web缓存,假定缓存命中率是0.4

- 40%的请求立刻得到满足
- 60%的请求通过原始服务器满足
- 接入互联网的链路的利用率下降到60%,从而其延迟可以忽略不计,例如10微秒
- 总的平均延迟=互联网上的延迟+访问延迟+局域网延迟=0.6×2.01秒+0.4×n微秒<1.4秒
条件性GET方法
缓存在Web缓存器中的对象副本可能不是最新版本,HTTP协议中有一种机制,允许缓存器证实它的对象是最新的,能够很好的解决这一问题,我们把这种机制称为条件GET(conditional GET)
下面介绍条件GET的使用方法
假设A向代理服务器发起一个HTTP请求,代理服务器(无缓存)会去原始Web将A请求的对象保存到本地,并将该对象返回给A,值得注意的是,缓存器同时也保存了这个对象最后被修改的日期
一个星期后A再此请求这个对象,此时缓存器
- 向原始Web发送一个条件GET,并在首部中包含Last-Modified首部行(其值就是缓存器中的对象的最后修改日期),来检查这个对象是否在这一星期内被修改过
- 原始Web收到这个报文后,检查报文中的日期和自己保存的这个对象的最后修改日期,如果相同,只需要响应一个报文即可,不需要在实体部分带上对象,节约了网络带宽
- 如果原始Web发现我们的日期不同,就把新的对象响应给缓存器

上图中,server返回给cache的响应报文中的状态行中包含 304 NOT Modified,说明cache中保存的对象是最新版本的,无需修改