【论文简述】Separable Flow:Learning Motion Cost Volumes for Optical Flow Estimation(ICCV 2021)
一、论文简述
1. 第一作者:Feihu Zhang
2. 发表年份:2021
3. 发表期刊:ICCV
4. 关键词:光流、可分离3D代价体、注意力、学习的半全局聚合
5. 探索动机:内存,病态区域。
First, the cost volume size is exponential in the dimensionality of the search space. Therefore memory and computation requirements for optical flow, with its 2D search space,grow quadratically with the range of motion. In contrast, such costs for the 1D stereo matching task grow only lin early with the range of disparity. Secondly, resolving ambiguities caused by occlusion, lack of texture, or other such issues requires a more global, rather than local, understanding of the scene, as well as prior knowledge. Cost volumes generally do not encapsulate such information, leaving the job of resolving such ambiguities to the second stage of each method.
6. 工作目标:提出一种更好的代价体表示方式。
7. 核心思想:提出了可分离卷积。
This work proposes a new separable cost volume computation module, which plugs into existing cost-volume-based optical flow frameworks, with two key innovations that address these challenges.
- The first is to separate the 2D motion of optical flow into two independent 1D problems, horizontal and vertical motion, compressing the 4D cost volume into two smaller 3D volumes using a self-adaptive separation layer. This factored representation significantly reduces the memory and computing resources required to infer (and thus also learn) the cost volumes, making them linear in the range of motion, without loss in accuracy.
- Moreover, it enables the second innovation: the use of non-local aggregation layers to learn a refined cost volume. Such layers have previously been used for 1D stereo problems, where they improve both accuracy in ambiguous regions, and cross-domain generalization. We apply them here to optical flow for the first time, learning cost volumes with non-local, prior knowledge via a one-step motion regression that is able to predict a low-resolution (i.e. 1/8), but high-quality motion. This prediction also serves as a better input to the interpolation and refinement module.
8. 实验结果:SOTA
We train and evaluate our Separable Flow module on the standard Sintel and KITTI optical flow datasets. We achieve the current best accuracy among all published optical flow methods on both these benchmarks. Moreover, in the cross-domain case of training on synthetic and testing on real data (i.e. KITTI), our results improve the previous state of the art by a greater margin, even outperforming some DNN models (e.g. FlowNet2 and PWC-Net) finetuned on the target KITTI scenes. We reiterate that any optical flow framework that computes a cost volume can benefit from these improvements.
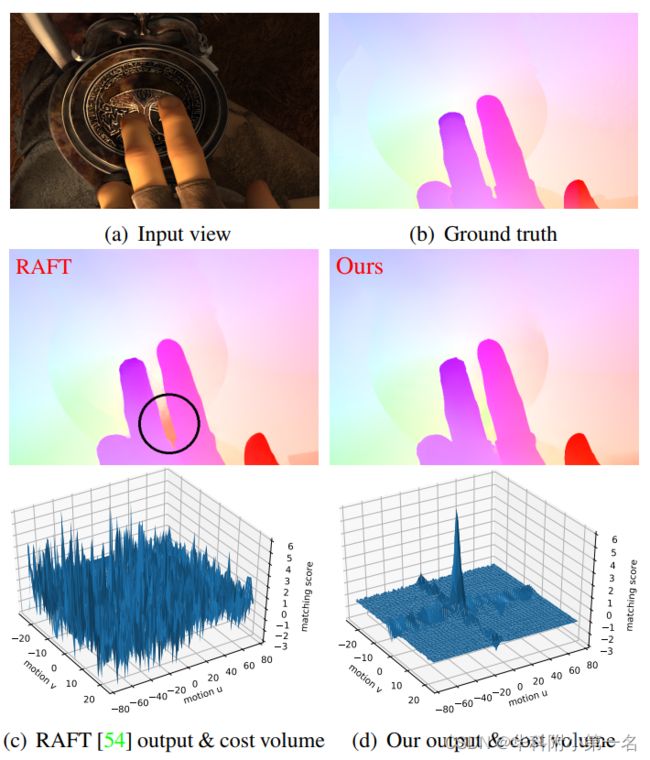
RAFT does not predict motion accurately in the ambiguous regions, such as occlusions (highlighted by the circle). Indeed, there are many false peaks in the cost volume for this region. In contrast, Separable Flow predicts accurate flow results in these challenging regions, by integrating separable, non-local matching cost aggregations. The resulting learned cost volume has one large peak, that correctly matches the ground truth.
9. 论文&代码下载:
https://openaccess.thecvf.com/content/ICCV2021/papers/Zhang_Separable_Flow_Learning_Motion_Cost_Volumes_for_Optical_Flow_Estimation_ICCV_2021_paper.pdf
http:// https://github.com/feihuzhang/SeparableFlow
二、实现过程
1. 基于代价体的经典光流框架
论文先介绍了首先Separable Flow模块可以应用的光流框架。通常包括1)图像特征提取;2)代价体计算;3)运动改进。
图像特征提取。卷积网络(如:ResNet)从图像中提取像素局部特征F∈H×W×D,其中F(i, j)是位置i, j像素在D维的特征。
代价体计算。给定两幅光流图像的特征张量F1和F2,代价体C∈H×W×|U|×|V|,其中U = {umin,..,0,..,umax} ,V = {vmin,..,0,..,vmax}是每个像素考虑的离散水平和垂直运动的集合。4D体中的每个值通常通过特征向量的点积:

使用这种方法,更高的“代价”表示更高的相似性。
运动改进。通常通过从粗到细的结构迭代更新运动估计。更新层将当前运动估计、代价体和上下文特征作为输入,输出累积的运动更新,运动通常初始化为零。
2. Separable Flow
Separable Flow中由三个部分组成:1)特征提取网络,2)由代价体分离、聚合网络和运动回归组成的Separable Flow模块,3)改进模块。顶层是一个上下文网络,学习权重和上下文信息,用于代价聚合、改进和上采样(一些模型没有这个)。Separable Flow模块由特征生成的4D代价体分离为两个独立的3D位移代价体。这些体经过几个非局部聚合层。经过改进的体,加上从它们回归的初始光流估计,输入到改进网络中,进行进一步的从粗到细的改进和插值。

2.1. 自适应代价分离
为了提高内存和计算效率,并在学习的代价体中实现非局部聚合,将4D代价体C分离压缩为两个3D的k维特征张量,Cu∈H×W×|U|×K和Cv∈H×W×|V|×K,其中K≪|U|,|V|,分别代表水平运动和垂直运动。Cu的前两个通道(上标索引)计算为:
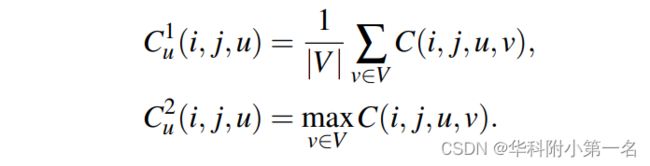
由于均值和最大值选择代价体的预定值,我们建议在剩余K−2通道学习一个自适应选择,并使用注意力模块。为了效率使用压缩Cv的前两个通道,这种自适应压缩是由

其中φu是一个单一的3D卷积层,σ(·)表示softmax运算。注意,Cu可以在不存储中间的4D代价体C
的情况下计算。相似的方法用于计算Cv。K为4。
这种自适应压缩相比平均压缩、最大压缩或卷积压缩有几个优点。例如,卷积需要|U|和|V|的固定范围,而该方法可以处理变化的搜索空间。更重要的是,卷积在平移上是不变的,但运动在空间上是变化的。我们的注意力模块输出平移变化的权重,允许它适应不同的运动,学习更好的代价体表示。
2.2. 学习的代价聚合
代价聚合模块使用编码器-解码器结构,该结构由GANet的四个非局部半全局聚合(SGA)层和八个3D卷积层组成,Cu从H ×W ×|U|×K特征张量变为H ×W × |U|代价体CAu。同样训练一个类似的网络来计算CAv。
2.3. 运动回归
使用类似的方法来学习光流回归,f0 = {u,v},对每个像素i, j:

然后,将初始光流预测f0和学习的代价体CAu、CAv输入至改进模块,计算最终的运动预测。其中运动改进之前使用相关代价C(i, j,u,v),取而代之的是连接的的聚合代价[CAu(i, j,u),CAv(i, j,v)]。
这种运动回归学习较低的分辨率(例如1/8,如RAFT[54]中使用的),但考虑到以前的方法初始化为零运动,高质量的运动预测可以作为改进模块的更好输入。用这种回归估计初始化运动是提高预测质量的关键。标准的(即非分离的)2D运动回归是自然可分离的:

σ(CAu)与∑vC'(:,v)作用相似。考虑到它在立体领域的有效性,以及2D运动回归的可分离性,这让我们对为什么运动回归可以用于有效地学习两个可分离的3D代价体有了一些直观的了解,这些代价体也包含丰富先验的上下文和几何信息。
3. 损失函数
使用L1计算回归光流f0和序列{f1,…,fN}的预测光流和真实光流之间损失。λ = 0.8,损失因此被定义为:

4. 实验
4.1. 数据集
FlyingThings、Sintel、KITTI-2015、HD1K
4.2. 实现
通过PyTorch实现,延续RAFT,在FlyingChairs上训练网络100k次迭代(批大小为12),然后FlyingThings[进行100k迭代(批大小为6),最后在FlyingThings、Sintel、KITTI-2015和HD1K的数据组合进行微调100k迭代(批大小为6)。所有其他设置(包括数据增强)与RAFT相同。
4.3. 基准结果及泛化性
泛化性好的原因:We thus find that Separable Flow provides even greater performance gains when applied to cross-domain scenarios. We attribute these generalization abilities to our separable non-local aggregations, which capture more robust, nonlocal geometry and contextual information, instead of local, domain-sensitive features.
处理病态区域好的原因:The non-local aggregations in our Separable Flow allow it to recognise and capture long-range contextual information, generating more accurate motion estimates in these regions. This rich contextual information also preserves object boundaries very well.

4.4. 消融实验
该模块通用性很好,可以嵌入很多光流结构中,并且由于其独特性,很多立体匹配网络的聚合模块也可以用于此。
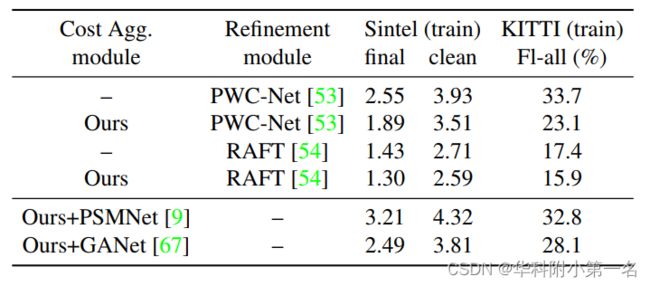
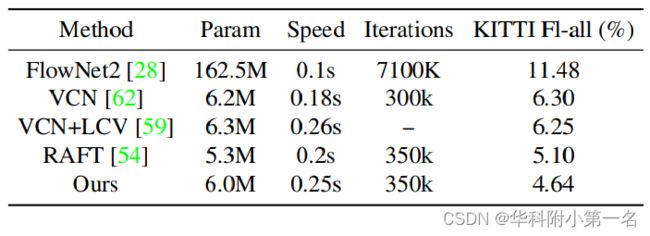
4.5. 时长,参数和精度
变慢变大了。
4,6. 限制
我们的模型只在少数情况下失败,其中物体(例如,汽车)在遮挡地区移动。这是光流方法的一种常见限制:当一个运动的物体只在一张图像中可见时,网络预测该物体是静止的,因为这是最合理的运动(至少是对于KITTI中的汽车而言)。为了解决这个问题,可以使用多视图或视频输入。