人工智能学习笔记
1 人工智能知识体系学习心得
1.1 概述
人工智能(Artificial Intelligence)最初在1956年达特茅斯会议上提出,之后研究者们发展了众多理论和原理,人工智能的概念也随之拓展,人工智能通常是指研究与开发用于模拟、延伸和拓展人的智能的理论、方法、技术及系统的一门新兴的交叉学科。经过半个多世纪的经验积累和计算机算力的提高,现今人工智能的发展正处于第三次浪潮,人工智能的理论和技术日趋成熟,应用领域也不断扩大,包括问题求解、语音识别、图像识别、自然语言处理等。

1.2 人工智能四要素
当前的人工智能可以认为是由大数据、算力、算法、场景四个要素组成。
- 大数据
人工智能的智能蕴含在大数据中。大数据是互联网和物联网发展的必然产物,在这个信息时代,世界无时无刻不在产生大数据,这些数据形式各异,大部分都是非结构化数据,如果需要为人工智能算法所用,就需要进行大量的预处理过程。当前,人工智能模型的训练往往需要大量数据,数据的多少好坏关系到训练的效果,大数据技术可以完成数据的采集、清洗和结构化,为人工智能提供信息支撑。 - 算力
算力即计算机的运算能力。目前人工智能由计算机程序实现,其运作需要计算机作为来承载,所以计算机是人工智能的硬件基础,其算力支撑着人工智能的运转。人工智能的构建和应用往往需要面对大量数据,处理这些数据需要强大的算力。 - 算法
人工智能的根本问题就是算法问题。相关算法的进步可以直接导致人工智能的进步。而算法需要专业的人来研究和编写,所以换种说法,人工智能的发展需要有相关人才的支持,需要有人才能研究、发展和使用人工智能算法。 - 场景:
大数据、算力、算法作为输入,只有在实际的场景中进行输出,才能体现出实际的价值。没有实际场景空谈人工智能意义不大。必须有应用场景的支持,人工智能才有实际价值,才能长久发展。
1.3 人工智能领域划分
人工智能领域划分方法有很多种,
按目前主流技术热点可分为:深度学习、自然语言处理、计算机视觉、智能机器人、自动程序设计、数据挖掘等;
按主要研究领域可分为:数据驱动的智能(大数据智能),知识驱动的智能(知识计算引擎与知识服务技术/知识和数据驱动的智能),跨媒体感知与计算(跨媒体智能),混合增强智能/人机共融,群体智能,自主协同控制与优化决策(自主智能),学习理论,类脑智能/脑与认知/生物启发的智能;
按三大流派可分为:符号主义,行为主义,联结主义;
按智能层级可分为:弱人工智能、强人工智能、超人工智能。
1.4 人工智能三大流派
人工智能:行为主义 - 简书 (jianshu.com)
基于对智能理解和实现原理的不同,人工智能分为符号主义(symbolicism)、联结主义(connectionism)、行为主义(actionism)三大流派。
符号主义又称逻辑主义、心理学派。符号主义认为人类所特有的认知是建立在思考之上,而思考则是建立在知识的基础之上,所以知识是智能的基础;知识和问题的符号化是符号主义的核心思想,将知识、问题以符号化表示,然后通过符号化的逻辑推演的方式解决问题。概念是构成人类知识世界的基本要素之一,所以符号主义的主要研究内容包括概念的表示、学习和应用,对此符号主义学派提出了许多方案,一个广为接受的方案就是知识图谱。符号主义善于模拟逻辑思维,但难于模拟形象思维。
联结主义又被称为仿生学派。联结主义认为用计算机可以模拟人脑。通过研究大脑神经系统并将研究结果运用到人工智能的分析中,模仿人脑在计算机上构建起一个人工神经网络;神经网络是大脑的简化模型,该模型认为大脑由大量带有权重的单元(模拟神经元)一起组成,这些权重度量了单元之间连接的强度。这些权重对连接这个神经元与另一个的突触的效果做了建模。对这类模型的试验解释阐明了学习诸如人脸识别、阅读、以及简单语法结构的检测等技能的能力。连接主义可以处理输入输出之间复杂的非线性关系,非常适合模拟形象思维过程,且具有无法显式描述知识,不善于模拟逻辑思维。
行为主义又称进化主义,主要源于控制论及其感知动作型控制系统,控制论把神经系统的工作原理与信息理论、控制理论、逻辑以及计算机联系起来。行为主义早期的研究工作重点是模拟人在控制过程中的智能行为和作用,如对自寻优、自适应、自镇定、自组织和自学习等控制论系统的研究。后来这些研究取得了一定的发展,随着一些新理论的加入,在20世纪末以人工智能行为主义学派的形式兴起。比起符号主义和联结主义,行为主义更加关注智能行为、群体智能、硬件基础等方面。
下表反映了人工智能三大流派之间的一些差别:
| 符号主义 | 联结主义 | 行为主义 | |
|---|---|---|---|
| 样本量 | 小 | 大 | 小 |
| 计算量 | 小 | 大 | 大 |
| 相关学科 | 心理学,数理逻辑 | 生理学 | 控制论、行为学 |
| 模拟方式 | 模拟功能 | 模拟结构 | 模拟行为 |
| 训练犯错 | 很少犯错 | 偶尔犯错 | 经常犯错 |
| 特点 | 知其然知其所以然 | 知其然不知其所以然 | 不知其然不知其所以然 |
| 经典系统 | 专家系统 | 神经网络 | 控制论动物 |
1.5 弱人工智能、强人工智能与超人工智能
人工智能科普15:弱人工智能、强人工智能、超人工智能 - 知乎 (zhihu.com)
弱人工智能也称限制领域人工智能或者应用型人工智能,指的是专注于且只能解决特定领域问题的人工智能,很显然人类至今所创造的所有人工智能算法和应用都属于弱人工智能的范畴,AlphaGo是弱人工智能的一个最好实例。AlphaGo虽然在围棋领域超越了人类最顶尖选手,但它的能力也仅止于围棋。一般而言,限于弱人工智能在功能上的局限性,人们更愿意将弱人工智能看成是人类的工具,而不会将弱人工智能视成威胁。
强人工智能又称通用人工智能或者完全人工智能,指可以胜任人类所有工作,与人类智能水平差不多的人工智能,一般认为一个可以称得上强人工智能的程序应大概需要具备以下几个方面的能力:
- 存在不确定因素时进行推理,使用策略,解决问题,制定决策的能力;
- 知识表示的能力,包括常识性知识的表示能力;
- 规划能力;
- 学习能力;
- 有使用自然语言进行交流沟通的能力;
- 将上述能力整合起来,实现既定目标的能力;
尽管如此,目前仍然缺乏一个量化的标准来评估什么样的计算机程序才是强人工智能,目前最广为接受的标准是图灵测试,但即便是图灵测试本身,也只是关注与计算机的行为和人类之间的行为。在强人工智能的定义里存在一个关键的的专业性问题:强人工智能是否有必要具备人类的意识?一旦牵涉“意识”,强人工智能的定义和评估标准就会变得异常复杂,除此以外,对于强人工智能是否可以真正实现,目前也还有较大争议。
假设人工智能通过不断发展,可以比世界上最聪明的人类还聪明,那么由此产生的超越人类智能的人工智能系统就可以被称为超人工智能。
1.6 机器学习
(7 条消息) 能否介绍一下强化学习(Reinforcement Learning),以及与监督学习的不同? - 知乎 (zhihu.com)
1.6.1 监督学习、无监督学习和半监督学习
监督学习是从标记的训练数据来推断一个功能的机器学习任务。在监督学习中,每个实例都是由一个输入对象(通常为矢量)和一个期望的输出值(也称为监督信号)组成。在学习过程中需要使用训练数据,而训练数据往往是人为给出的。在这个训练集中,系统的预期输出(即标签信息)也已经事先给定,如果模型的实际输出与预期不符(二者有差距),那么模型就有责任“监督”学习系统重新调整模型参数,直至二者的误差在可容忍的范围之内。由其学习过程可知,监督学习需要大量的样本标记前期工作。监督学习算法的本质是分析训练数据,并产生一个由输入到输出的映射,该映射用模型表示,学习的目的就是找到一个最好的映射以用于预测。
无监督学习与监督学习的区别在于没有监督信号,即从未经标记或分类的测试数据中学习。它本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构,无监督学习主要工作包括聚类和降维。与监督学习有明确的预期结果不同,无监督学习没有明确预期结果,也没有确定的标准评判结果正确与否。
半监督学习是将监督学习和无监督学习融合的学习方式,例如训练数据中可能部分有标签而另一部分无标签,为了利用起所有数据,就可采用半监督学习。
1.6.2 强化学习
强化学习基于环境的反馈而行动,通过与环境交互、试错,最终完成特定目的或使整体行动收益最大化。
强化学习和无监督学习与有监督学习有一定的相似之处,与无监督学习一样使用训练数据采用未标记的数据,而与监督学习一样有反馈。监督学习使用的监督信号具有两个功能,一方面是“监督”——判断输出值好坏,另一方面是“引导”——告诉学习系统最佳输出应该是什么;但是强化学习的反馈信号只有“监督”功能,对于每一步行动环境会给出可量化的反馈信号,以评判该步行动的好坏,但并不会告诉学习系统这一步或下一步应该如何行动,需要学习系统通过自行决策,通过不断试错来学习。
时间是强化学习的一个重要因素。强化学习的一系列环境状态的变化和环境反馈等都是和时间强挂钩,整个强化学习的训练过程是一个随着时间变化的变化的过程,不像监督学习,强化学习的反馈信号可能会有延迟;当前状态以及采取的行动会影响下一步接收到的状态,训练数据之间存在一定因果关联。
1. 7 神经网络
1.7.1 MP模型
MP模型由美国心理学家麦卡洛克(McCulloch, W.)和数学家匹兹 (Pitts,W.)于1943年共同提出,MP模型名字来源于其提出者名字首字母组合。
MP模型模仿生物神经元,生物神经元主要由树突、细胞体、轴突三部分组成,分别对应信号输入,处理,输出;可把神经元看作一个多输入单输出的信息处理单元,基于此建立MP模型。
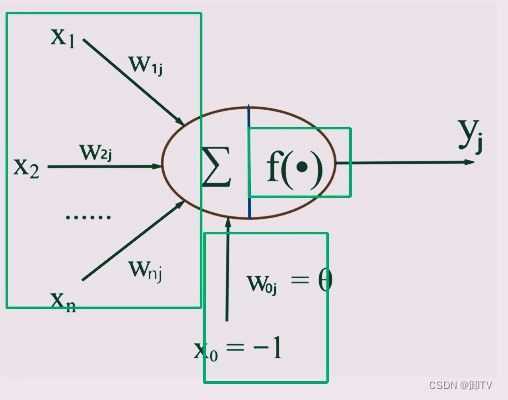
如图,将输入信号 ∑ i = 1 n x i w i j \sum_{i=1}^{n}x_{i}w_{ij} i=1∑nxiwij和阈值 θ j = x 0 w 0 j \theta_{j}=x_{0}w_{0j} θj=x0w0j组成的输入矩阵按权重矩阵加权 ∑ i = 0 n x i w i j \sum_{i=0}^{n}x_{i}w_{ij} i=0∑nxiwij作为输入信号,信号输入激活函数 f 得到结果y输出,综上可得单个MP模型神经元的数学表达式为
y j = f ( ∑ i = 1 n ( x i w i j + θ j ) ) = f ( ∑ i = 0 n x i w i j ) , ( 其中 f ( ∗ ) 为激活函数 ) y_{j}=f(\sum_{i=1}^{n}(x_{i}w_{ij}+\theta_{j}))=f(\sum_{i=0}^{n}x_{i}w_{ij}),(其中f(*)为激活函数) yj=f(i=1∑n(xiwij+θj))=f(i=0∑nxiwij),(其中f(∗)为激活函数)
激活函数f可使用step、sigmoid、tanh、Relu等函数;早期感知器模型中激活函数f一般为step函数,这对结果过早地做了二值化操作使学习能力弱化。
1.7.2 感知器模型
感知器模型在MP模型基础上增加学习的特性:不同于MP模型预先设置权重,感知器模型的权向量不需要预先设定,而是通过学习得到的。感知器将产生的结果与预期结果进行比较,将误差经处理进行反馈更新权值实现学习的功能。为了得到可接受的权向量,感知器法则从随机的权值开始,反复地对每一个训练样例应用这个感知器,并在出现误分类样例时按照一定法则修改感知器的权值,重复这个过程,直到感知器可以正确分类所有的训练样例。权重修改法则是在原权值w的基础上加上修正值Δw,修正值是学习率η、误差e、输入值xi三者之积,计算公式如下
w n e w = w o l d + Δ w i Δ w i = η ∗ e ∗ x i e = t − o \begin{align*} w_{new} &= w_{old}+\Delta w_{i} \\ \Delta w_{i}&=\eta *e*x_{i} \\ e&=t-o \end{align*} wnewΔwie=wold+Δwi=η∗e∗xi=t−o
其中t表示目标输出值;o表示当前输出值。在这里,学习率是人为规定的一个定值,是模型的一个重要参数,误差e取残差。
单个感知器模型无法直接处理线性不可分问题如异或问题,该问题可以通过多个感知器组网形成感知器网络解决,但感知器网路在组成多隐层网络时,无法实现完全的误差传播,即无法完全更新所有权重,导致学习能力受限。
1.7.3 BP网络
BP网络的单个神经元和感知器模型没有太大区别,BP神经网网络解决了感知器网络误差传递的问题,其基本思想之一是梯度下降法,利用梯度搜索算法,使网络的实际输出值和期望输出值的误差均方差为最小。基本BP算法包括信号的前向传播和误差的反向传播两个过程。即计算误差输出时按从输入到输出的方向进行,而调整权值和阈值则从输出到输入的方向进行。正向传播时,输入信号通过隐含层作用于输出节点,经过非线性变换,产生输出信号,若实际输出与期望输出不相符,则转入误差的反向传播过程。误差反传是将输出误差通过隐含层向输入层逐层反传,并将误差分摊给各层所有单元,以从各层获得的误差信号作为调整各单元权值的依据。通过调整输入节点与隐层节点的联接强度和隐层节点与输出节点的联接强度以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。基于梯度下降法,BP网络单个神经元的权重更新方法为:
w n e w = w o l d + Δ w = w o l d − η ∇ E ( w ) w_{new}=w_{old}+\Delta w=w_{old}-\eta\nabla E(w) wnew=wold+Δw=wold−η∇E(w)
2 经典模型的实验过程
2.1 遗传算法求最值
遗传算法(Genetic Algorithm,GA)最早是由美国的 John holland于20世纪70年代提出,该算法是根据大自然中生物体进化规律而设计提出的。是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。该算法通过数学的方式,利用计算机仿真运算,将问题的求解过程转换成类似生物进化中的染色体基因的交叉、变异等过程。在求解较为复杂的组合优化问题时,相对一些常规的优化算法,通常能够较快地获得较好的优化结果。遗传算法已被人们广泛地应用于组合优化、机器学习、信号处理、自适应控制和人工生命等领域。
2.1.1 实验说明
- 实验目的:通过实验掌握遗传算法的基本原理和编程实现方法。
- 问题描述:设
x 1 ∈ { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 } ; x 2 ∈ { 0 , 1 , 2 , 3 , 4 , 5 , 6 , 7 } ; f ( x 1 , x 2 ) = x 1 2 + x 2 3 ; \begin{align*} &x_{1} \in \left \{0,1,2,3,4,5,6,7 \right \}; \\&x_{2} \in \left \{0,1,2,3,4,5,6,7 \right \};\\ &f(x_{1},x_{2})=x_{1}^{2}+x_{2}^{3}; \end{align*} x1∈{0,1,2,3,4,5,6,7};x2∈{0,1,2,3,4,5,6,7};f(x1,x2)=x12+x23;
用遗传算法求$ f(x_{1},x_{2})$最大值。
2.1.2 实验原理
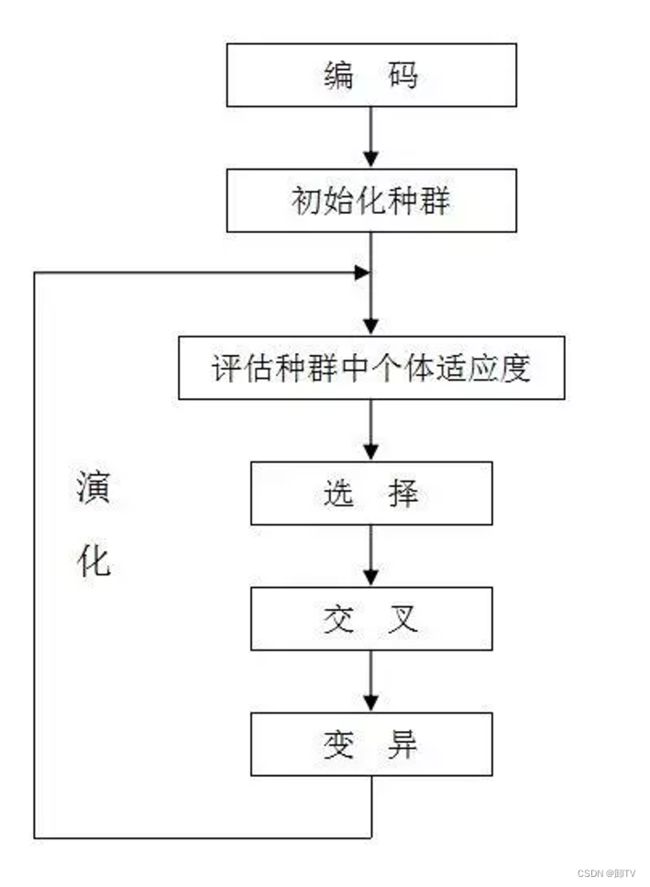
遗传算法的一般步骤如图,通过不断迭代进化,可以求出最优解或较优解
-
个体编码
x1,x2是0到7之间的整数,所以分别可以三位二进制整数表示,可将两个三位二进制数拼接在一起形成的6位二进制数做为个体编码基因,即一个可行解,例如基因型X = [100101] 所对应的表现型即为 [x1,x2]=[4,5]。 -
初始群体产生
遗传算法是对群体进行进化操作,需要准备初始群体数据,对于本题可通过随机数程序产生若干个属于 [0,63] 的十进制整数(对应二进制整数000000~111111),作为初始群体的基因。 -
适应度计算
适应度用于评定个体优劣程度,本实验中由于目标函数f值域在非负区间,可直接函数值作为适应度 -
选择算法
个体参与繁殖复制到下一代的概率与其适应度成正比。用python具体实现如下:
# 选择运算:group为种群所有个体,fitness为对应的适应度,next_generation为选择出的个体数
def select(group:list,fitness:list,next_num:int):
# 根据每个个体适应度分配区间,区间总长等于适应度总和
span=[]
vernier=0
for e in fitness:
vernier+=e
span.append(vernier)
# 在span区间上取随机数,随机数落在哪个个体对应的区间则该个体进入下一代
next_gen=[]
temp=0
for i in range(next_num):
temp=random.randrange(0,vernier)
for j in range(len(span)):
if span[j]>temp:
next_gen.append(group[j])
# 返回选择出来的个体
return next_gen
-
交叉运算
类似于生物学中的染色体交叉,遗传算法通过交叉把父代个体的基因序列进行组合传给子代,本实验采用的交叉的算法是先将群体进行随机两两配对,再选择交叉点,进行序列的交换。 -
变异运算
在随机交叉产生的个体中随机选出一定数量的个体,再随机对基因序列的部分片段取反,实现子代变异,具体是通过移位和异或实现的。 -
循环迭代:主函数如下,全部代码见附录程序清单。
# 初始化种群,种群个体个数为8
group=initialPopulation(8)
# 迭代5次
for i in range(6):
# 计算适应度,即每个个体对应的函数值
fitness=fun(group)
print("第%d代对应函数值:"%(i),fitness)
# 从种群中可重复地选出8个个体
selected=select(group,fitness,8)
# 个体间基因序列交叉
next_group=cross(selected)
# 部分个体变异
group=variation(next_group)
2.1.3 实验结果分析
测试结果如下:
第0代对应函数值: [217, 392, 50, 161, 9, 89, 1, 1]
第1代对应函数值: [57, 125, 392, 161, 64, 241, 129, 33]
第2代对应函数值: [216, 161, 161, 352, 33, 241, 392, 392]
第3代对应函数值: [392, 100, 352, 392, 125, 252, 352, 392]
第4代对应函数值: [352, 347, 392, 225, 392, 392, 352, 392]
第5代对应函数值: [352, 392, 265, 352, 392, 392, 265, 392]
可见,随着迭代次数的增加,得到的函数值越来越接近最大值,且达到最大值392的个体越来越多,但在最后一次迭代出现
了平均值下降的情况,类似于生物种群的返祖现象,原因是多方面的,主要原因是遗传算法本身就具有一定的随机性,为减少这种情况的产生,可以修改选择和变异算法,例如可采用非线性的选择运算函数,加大优势个体参与繁殖的概率;但是这么做可能会增大陷入局部最优的可能,所以需要权衡好。

2.2 蚁群算法解决TSP问题
蚁群算法 - 简书 (jianshu.com)
蚁群算法_三名狂客的博客-CSDN博客_
蚁群系统(Ant System或Ant Colony System)是由意大利学者Dorigo、Maniezzo等人于20世纪90年代首先提出来的。他们发现单个蚂蚁的行为比较简单,但是蚁群整体却可以体现一些智能的行为。例如蚁群可以在不同的环境下,找到到达食物源的最短路径。研究发现,蚂蚁会在其经过的路径上释放一种可以称之为“信息素”的物质,蚁群内的蚂蚁对“信息素”具有感知能力,它们会沿着“信息素”浓度较高路径行走,而每只路过的蚂蚁都会在路上留下“信息素”,这就形成一种类似正反馈的机制,这样经过一段时间后,整个蚁群就会沿着最短路径到达食物源。
蚁群算法是利用蚁群系统的原理编写的算法,具有分布计算、信息正反馈和启发式搜索的特征,本质上是进化算法中的一种启发式全局优化算法。
2.2.1 实验说明
- 实验目的:通过运行分析蚁群算法实例解决旅行商问题(TSP问题),理解蚁群算法原理,熟悉蚁群算法的实现和应用。
- 问题描述:旅行家要旅行n个城市,要求各个城市都经过一次,然后回到出发城市,并要求所走的路程最短。问题的抽象表达为:求解遍历图G=(V,E,C),经过所有的节点一次并且回到起始节点的路径,使得连接这些节点的路径成本最低。
2.2.2 实验原理
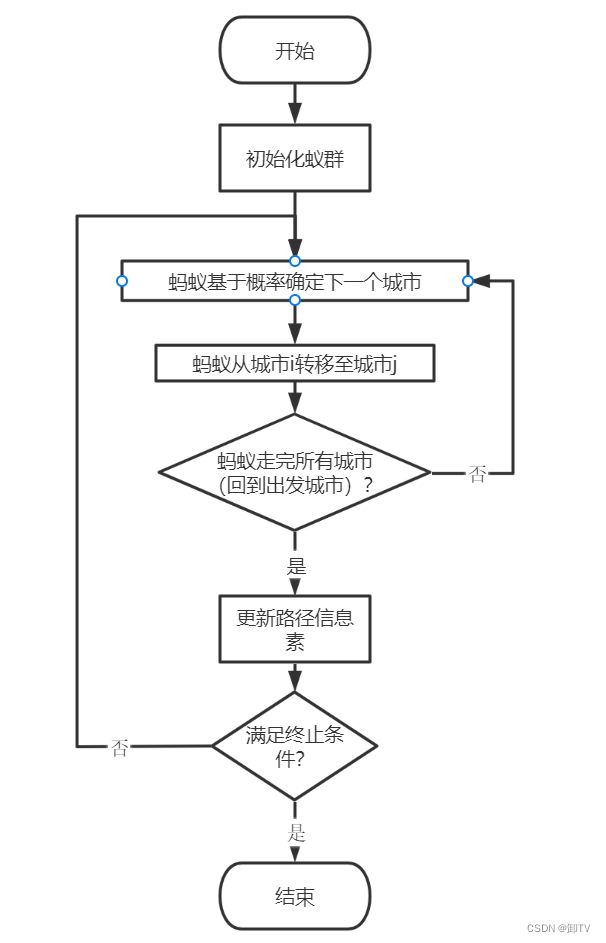
蚁群算法的基本规则为
- 蚂蚁在路径上释放信息素。
- 碰到还没走过的路口,就随机挑选一条路走。同时,释放与路径长度有关的信息素。
- 信息素浓度与路径长度成反比。后来的蚂蚁再次碰到该路口时,就选择信息素浓度较高路径。
- 最优路径上的信息素浓度越来越大。
- 最终蚁群找到最优寻食路径。
故将蚁群算法应用于解决优化问题的基本思路为,用蚂蚁的行走路径表示待优化问题的可行解,整个蚂蚁群体的所有路径构成待优化问题的解空间。路径较短的蚂蚁释放的信息素量较多,随着时间的推进,较短的路径上累积的信息素浓度逐渐增高,选择该路径的蚂蚁个数也愈来愈多。最终,整个蚂蚁会在正反馈的作用下集中到最佳的路径上,以此得到最优解。
在一次迭代中,每只蚂蚁只会经过除出发城市以外的城市一次,可创建几个列表以记录一只蚂蚁走过的城市和未走过的城市,蚂蚁每步行动在未走过的城市中按概率随机选择下一个城市,选择每个城市的概率由其路径长短和信息素浓度综合决定,概率与两者的关系为
p i j k ∝ τ i j α η i j β , j ∈ a l l o w e d k , i p_{ij}^{k}\propto \tau _{ij}^{\alpha}\eta _{ij}^{\beta},j\in allowed_{k,i} pijk∝τijαηijβ,j∈allowedk,i
其中 τ i j \tau_{ij} τij表示从城市i到城市j的信息素浓度, η i j \eta_{ij} ηij为 i、j 两城市距离的倒数,α和β分别为τ和η的权重。α称为信息启发因子,其值越大蚂蚁选择之前走过的路径可能性就越大,搜索路径的随机性减弱,值越小则蚁群搜索范围减小,容易陷入局部最优。β称为期望启发因子,其值越大,蚁群越容易选择局部较短路径,算法收敛加快,随机性减弱,易得到局部相对最优。结合之前的分析可知,对于任意一个城市,选择该城市的概率为:
p i j k = { τ i j α η i j β ∑ s ∈ a l l o w e d k , i τ i s α η i s β j ∈ a l l o w e d k , i 0 j ∉ a l l o w e d k , i p_{ij}^{k}= \left\{\begin{matrix} \frac{\tau _{ij}^{\alpha}\eta _{ij}^{\beta}}{ {\textstyle \sum_{s\in allowed_{k,i}}\tau _{is}^{\alpha}\eta _{is}^{\beta}} } & j\in allowed_{k,i} \\ 0 & j\notin allowed_{k,i} \end{matrix}\right. pijk=⎩ ⎨ ⎧∑s∈allowedk,iτisαηisβτijαηijβ0j∈allowedk,ij∈/allowedk,i
信息素会随着迭代而挥发,如果没有新的信息素补充,信息素浓度会逐渐降低,设挥发系数为ρ,故本次迭代后某两城市之间的信息素浓度为上次迭代后信息素浓度乘上挥发系数再加上本次信息素浓度增量Δτ:
τ i j ( t + 1 ) = ρ τ i j ( t ) + Δ τ \tau_{ij}(t+1)=\rho\tau_{ij}(t)+\Delta\tau τij(t+1)=ρτij(t)+Δτ
Δτ在不同的蚁群算法模型中不尽相同,本实验采用蚁周模型(Ant-Cycle模型),其他模型还有蚁量模型(Ant-Quantity模型)、蚁密模型(Ant-Density模型)。蚁周模型中Δτ为每次迭代释放信息素总量Q与此次迭代路径总长度之比为 Δ τ = Q L k \Delta\tau=\frac{Q}{L_{k}} Δτ=LkQ 。故按概率选择下一城市的具体实现为:
# 获取去下一个城市的概率
for i in range(city_num):
# 如果该城市未走过
if self.open_table_city[i]:
# 计算概率:与信息素浓度成正比,与距离成反比
select_citys_prob[i] = pow(pheromone_graph[self.current_city][i], ALPHA) * pow(
(1.0/distance_graph[self.current_city][i]), BETA)
# 计算总信息素浓度
total_prob += select_citys_prob[i]
# 轮盘选择城市
if total_prob > 0.0:
# 产生一个随机概率,0.0-total_prob
temp_prob = random.uniform(0.0, total_prob)
for i in range(city_num):
if self.open_table_city[i]:
# 轮次相减
temp_prob -= select_citys_prob[i]
if temp_prob < 0.0:
next_city = i
break
蚁群算法的流程如图,程序完整代码见程序清单。
2.2.3 实验结果分析
经过近140次迭代,结果稳定在全局最优解3687,由下图可见,蚁群算法前期可以较快速度收敛,只花了大约20次迭代就找到了较优解,但要找到全局最优解,难度就大大提高,为找到全局最优花费的迭代次数是寻找局部最优所需次数的3倍。

2.3 决策树
2.3.1 决策树的遍历
决策树是一个类似于流程图的树状结构。其中,每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每一个树叶结点代表类或类分布。树的最顶层是根结点。决策树根据一些数据属性进行分类,每个节点是一个判断,通过判断进行分类,这些判断是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的判断问题,逐层细分,最终将数据划分到合适的叶子节点,实现决策,用决策树决策可以看作是一系列switch/case控制语句的组合使用。决策树的构建方法根据初度判断规则的不同有ID3、C45、CART等算法。
现假设西瓜分为好瓜和坏瓜,由“色泽”、“根蒂”、 “敲声”、 “纹理”、 “脐部”、 “触感”六个因素决定,利用已有的数据集D构建出决策树后即可利用该决策树进行预测(决策),决策树的构建算法有ID3算法和C45算法等。构建树所用的数据集和测试数据集见程序清单。
2.3.2 ID3算法构建决策树
为了提高分类的准确性,减小相对性,应该把对分类结果影响大的属性放在靠近决策树根节点的位置,即让决策树上层的分裂属性尽量纯,让分裂子集中待分类项属于同一类别,ID3算法基于某属性的信息增量确定纯度,某属性信息增益越大就认为该属性信息纯度越高,则该属性对应的节点应放在更靠近根节点的位置。某一属性的信息增量是样本集合信息熵和该属性条件熵的差值。信息熵代表随机变量的不确定度,这里样本集合的信息熵是指待判断属性的不确定度,其定义为
E n t ( D ) = − ∑ k = 1 n p k l o g 2 p k Ent(D)=-\sum_{k=1}^{n}p_{k}log_{2}p_{k} Ent(D)=−k=1∑npklog2pk
n为属性可能的取值个数,在本实验中,待判断属性为好坏瓜,故n=2; p k p_{k} pk为该属性取值对应的元素个数,假设样本集合中好瓜有7个,坏瓜有10个,共17个,则样本集合的计算过程为
E n t ( D ) = − ∑ k = 1 2 p k l o g 2 p k = − ( 7 17 l o g 2 7 17 + 10 17 l o g 2 10 17 ) = 0.977 Ent(D)=-\sum_{k=1}^{2}p_{k}log_{2}p_{k}=-(\frac{7}{17}log_{2}\frac{7}{17}+\frac{10}{17}log_{2}\frac{10}{17})=0.977 Ent(D)=−k=1∑2pklog2pk=−(177log2177+1710log21710)=0.977
条件熵也是信息熵,只不过是某一属性值确定时的各信息熵加权和,假设对于纹理属性有
| 清晰 | 稍糊 | 模糊 | |
|---|---|---|---|
| 好瓜个数 | 3 | 4 | 1 |
| 坏瓜个数 | 3 | 2 | 4 |
则纹理的三个分支节点的信息熵为
清晰: E n t ( D 1 ) = − ( 3 6 l o g 2 3 6 + 3 6 l o g 2 3 6 ) = 1.000 稍糊: E n t ( D 2 ) = − ( 2 6 l o g 2 2 6 + 4 6 l o g 2 4 6 ) = 0.918 模糊: E n t ( D 3 ) = − ( 1 5 l o g 2 1 5 + 4 5 l o g 2 4 5 ) = 0.722 \begin{align*} 清晰:Ent(D^1)=-(\frac{3}{6}log_{2}\frac{3}{6}+\frac{3}{6}log_{2}\frac{3}{6})=1.000\\稍糊:Ent(D^2)=-(\frac{2}{6}log_{2}\frac{2}{6}+\frac{4}{6}log_{2}\frac{4}{6})=0.918\\模糊:Ent(D^3)=-(\frac{1}{5}log_{2}\frac{1}{5}+\frac{4}{5}log_{2}\frac{4}{5})=0.722 \end{align*} 清晰:Ent(D1)=−(63log263+63log263)=1.000稍糊:Ent(D2)=−(62log262+64log264)=0.918模糊:Ent(D3)=−(51log251+54log254)=0.722
得纹理的信息增益为
G a i n ( D , 纹理 ) = E n t ( D ) − ∑ v = 1 3 ∣ D v ∣ ∣ D ∣ E n t ( D v ) = 0.977 − ( 6 17 ∗ 1.000 + 6 17 ∗ 0.918 + 5 17 ∗ 0.722 ) = 0.109 \begin{align*} Gain(D,纹理) & =Ent(D)-\sum_{v=1}^{3}\frac{|D^v|}{|D|}Ent(D^v)\\ & =0.977-(\frac{6}{17}*1.000+\frac{6}{17}*0.918+\frac{5}{17}*0.722)\\ & =0.109 \end{align*} Gain(D,纹理)=Ent(D)−v=1∑3∣D∣∣Dv∣Ent(Dv)=0.977−(176∗1.000+176∗0.918+175∗0.722)=0.109
若通过计算得到另一个属性,色泽的信息增益为0.231,大于纹理的信息增益,那么可以确定,色泽的判断节点应该放在纹理之前。通过递归可以将整棵决策树构建出来,具体流程如下:
- 创建树的根节点;
- 计算所有属性信息增量;
- 将各属性信息增量排序,取最大信息增量对应的属性做为该节点的判断条件;
- 根据判断条件分支创建子节点,并将集合中元素划分到各个子节点,
- 在各个子节点对剩余属性重复2-5过程直到整棵树构建完成。
该过程的python实现的主要代码如下,完整代码见程序清单。
def createTree(dataSet, labels):
# dataset为构建决策树用的数据集
classList = [example[-1] for example in dataSet]
# 如果类别相同则停止划分
if classList.count(classList[0]) == len(classList):
return classList[0]
# 判断是否遍历完所有的特征,若是则返回个数最多的类别
if len(dataSet[0]) == 1:
return majorityCnt(classList)
#按照信息增益最高选择分类特征属性
bestFeat = chooseBestFeatureToSplit(dataSet) #分类编号
bestFeatLabel = labels[bestFeat] #该特征的label
myTree = {bestFeatLabel: {}}
del (labels[bestFeat]) #移除该label
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:] #子集合
#构建数据的子集合,并进行递归
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value), subLabels)
return myTree
构建树的结果如图
用构建出来的树进行预测,输入样例1:[‘浅白’, ‘蜷缩’, ‘浊响’, ‘清晰’, ‘凹陷’, ‘硬滑’],样例2:[‘乌黑’, ‘硬挺’, ‘浊响’, ‘稍糊’, ‘凹陷’, ‘硬滑’];得到预测结果:
单个样例1测试:好瓜
单个样例2测试:坏瓜
输入测试数据集得到结果为 :
[‘好瓜’, ‘好瓜’, ‘好瓜’, ‘好瓜’, ‘坏瓜’, ‘好瓜’, ‘好瓜’, ‘坏瓜’, ‘好瓜’, ‘坏瓜’, ‘坏瓜’]
2.3.3 C45算法构建决策树
通过分析ID3算法的求解公式可以看出,对于可能取值较多的属性,其信息增益往往较大,即信息增益准则对可取值数目较多的属性有所偏好,假设数据集中西瓜的“编号”也作为一个候选划分属性,可以得到“编号”的信息增益是0.998,这是因为每一个样本的编号都是不同的。当出现类似于这样的属性时,其它属性的作用将会被弱化,这样生成的决策树明显受制于局部特性,泛化能力较弱;为解决此问题,C45算法引入了信息增益率,信息增益率在信息增益的基础上除以一个量Int(D,a),一般情况下,Int(D,a)取属性每个取值的信息熵之和:
G a i n R a t i o ( D , a ) = G a i n ( D , a ) I n t ( D , a ) I n t ( D , a ) = − ∑ i = 0 n E n t ( a i ) \begin{align*} GainRatio(D,a)=\frac{Gain(D,a)}{Int(D,a)}\\ Int(D,a)=-\sum_{i=0}^{n} Ent(a_{i}) \end{align*} GainRatio(D,a)=Int(D,a)Gain(D,a)Int(D,a)=−i=0∑nEnt(ai)
该量反映该属性a内部信息,属性a的取值越多,Int(D,a)越大,这样在决策树上层节点采用信息增益率而非信息增益进行比较,可以有效屏蔽分支过多的属性对决策树构建的影响。与上例ID3使用同样的数据集,用C45构建出决策树和测试结果为:
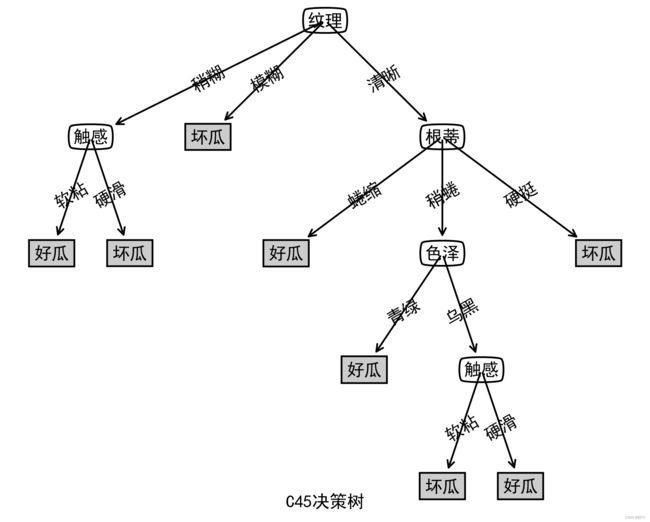
单个样例1测试:好瓜
单个样例2测试:坏瓜
测试集测试结果:[‘好瓜’, ‘好瓜’, ‘好瓜’, ‘好瓜’, ‘坏瓜’, ‘好瓜’, ‘好瓜’, ‘坏瓜’, ‘好瓜’, ‘坏瓜’, ‘坏瓜’]
2.4 梯度下降法
梯度下降法是一种求解的最优化算法。主要解决求最小值问题,其基本思想在于不断地逼近最优点,每一步的优化方向就是梯度的方向。梯度下降法常常用于机器学习,而学习的过程就是利用梯度下降法不断去优化的过程,后面的BP网络就用到了梯度下降法。
对于最简单的线性模型,如 h ( θ ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 + . . . + θ i x i h(\theta)={\theta}_0+{\theta}_1 x_1+{\theta}_2 x_2+{\theta}_3 x_3+...+{\theta}_ix_i h(θ)=θ0+θ1x1+θ2x2+θ3x3+...+θixi,假设其损失函数为 J ( θ ) = 1 2 [ h t ( x ) − y ] 2 J(\theta)=\frac{1}{2}[ h_t(x)-y]^2 J(θ)=21[ht(x)−y]2 则梯度下降的基本形式为 θ n + 1 = θ n − α J ′ ( θ ) \theta_{n+1}=\theta_n-{\alpha}J^{'}(\theta) θn+1=θn−αJ′(θ) 其中,α为学习率,下一步便是要将损失函数最小化,需要对J(θ)求导:
J ′ ( θ ) = ∂ J ( θ ) ∂ θ = [ h θ ( x ) − y ] ∗ h θ ′ J^{'}(\theta)=\frac{{\partial}J(\theta)}{\partial\theta}=[h_{\theta}(x)-y]*h^{'}_{\theta} J′(θ)=∂θ∂J(θ)=[hθ(x)−y]∗hθ′
其中 h θ ′ = x h^{'}_{\theta}=x hθ′=x 所以不难得出 J ′ ( θ ) = [ h θ ( x ) − y ] ∗ x J^{'}(\theta)=[h_{\theta}(x)-y]*x J′(θ)=[hθ(x)−y]∗x
即 θ n + 1 = θ n − α [ h θ ( x ( i ) ) − y ( i ) ] ∗ x ( i ) \theta_{n+1}=\theta_n-{\alpha}[h_{\theta}(x^{(i)})-y^{(i)}]*x^{(i)} θn+1=θn−α[hθ(x(i))−y(i)]∗x(i)
2.4.1 随机梯度下降法
随机梯度下降法指的是每次随机从样本集中抽取一个样本对θ进行更新,更新公式为:
θ n + 1 = θ n − α [ h θ ( x ( i ) ) − y ( i ) ] ∗ x ( i ) \theta_{n+1}=\theta_{n}-\alpha[h_{\theta}(x^{(i)})-y^{(i)}]*x^{(i)} θn+1=θn−α[hθ(x(i))−y(i)]∗x(i)
这种算法如果要遍历整个样本集的话需要迭代很多次,且每次更新并不是向着最优的方向进行,所以每走一步都要“很小心”,也就是说随机梯度下降法的学习率α不能设置太大,不然容易出现在最优解附近“震荡”,但始终无法更接近最优解的现象;但从另一个角度来看,这种“来回震荡”的优化路线在损失函数局部极小值较多时,能够有效避免模型陷入局部最优解。
2.4.2 标准梯度下降法
标准梯度下降法则是计算样本集中损失函数的总和之后再对参数进行更新:
θ n + 1 = θ n − α N [ h θ ( x ( i ) ) − y ( i ) ] ∗ x ( i ) \theta_{n+1}=\theta_n-\frac{\alpha}{N}[h_{\theta}(x^{(i)})-y^{(i)}]*x^{(i)} θn+1=θn−Nα[hθ(x(i))−y(i)]∗x(i)
这种算法是在遍历了整个样本集之后才对参数进行更新,因此它的下降方向是最优的方向,所以它就可以很理直气壮的走每一步。
因此,这种算法的学习率\alpha一般要比随机梯度下降法的大。但这种优化方法的缺点在于它每更新一次都需要遍历整个样本集,效率比较低,因为在很多时候整个样本集计算出的梯度和部分样本集计算出的梯度相差并不多。
2.4.3 批梯度下降法
批梯度下降法每次随机从样本集中抽取M个样本进行迭代:
θ n + 1 = θ n − α M [ h θ ( x ( i ) ) − y ( i ) ] ∗ x ( i ) \theta_{n+1}=\theta_n-\frac{\alpha}{M}[h_{\theta}(x^{(i)})-y^{(i)}]*x^{(i)} θn+1=θn−Mα[hθ(x(i))−y(i)]∗x(i)
这种优化算法相比前两种来说,既能提高模型的准确度,又能提高算法的运行速度。
2.4.4 用梯度下降法求最值
使用梯度下降法求最值的流程为:
- 设置学习率、迭代次数和初始点
- 求所在点梯度(求导)
- 根据梯度和学习率乘积改变点的位置(上升或下降)
- 重复2、3步直到达到终止条件或迭代次数达到预设值
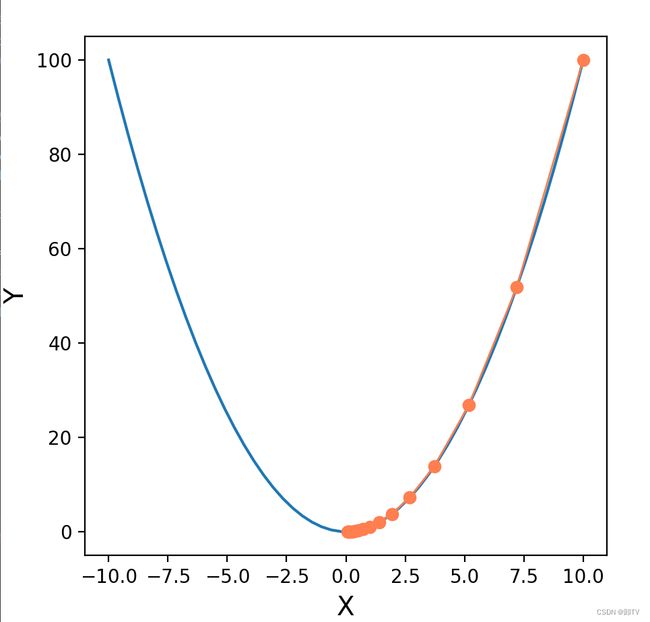
python实现梯度下降法求二次函数最小值程序如下
import matplotlib.pyplot as plt
import numpy as np
# fx的函数值
def fx(x):
return x ** 2
# 定义梯度下降算法
def gradient_descent():
times = 15 # 迭代次数
alpha = 0.14 # 学习率
x = 10 # 设定x的初始值
x_axis = np.linspace(-10, 10) # 设定x轴的坐标系
fig = plt.figure(1, figsize=(5, 5)) # 设定画布大小
ax = fig.add_subplot(1, 1, 1) # 设定画布内只有一个图
ax.set_xlabel('X', fontsize=14)
ax.set_ylabel('Y', fontsize=14)
ax.plot(x_axis, fx(x_axis)) # 作图
for i in range(times):
x1 = x
y1 = fx(x)
print("第%d次迭代:x=%f,y=%f" % (i + 1, x, y1))
x = x - alpha * 2 * x #求导并作为梯度下降
y = fx(x) # 代值
ax.plot([x1, x], [y1, y], 'ko', lw=1, ls='-', color='coral')
plt.show()
if __name__ == "__main__":
gradient_descent()
运行结果如下:
2.5 BP神经网络与MNIST手写识别
2.5.1 BP算法推导
由1.7节的推导可知,BP网络单个神经元的数学模型为
y ^ = f ( ∑ i = 0 n x i w i ) ( 令 w 0 = b , x 0 = 1 ) = f ( W T X ) ( 写成矩阵形式 ) \begin{align*} \hat{y}&=f(\sum_{i=0}^{n}x_{i}w_{i})&(令w_{0}=b,x_{0}=1)\\ &=f(W^TX)&{(写成矩阵形式)} \end{align*} y^=f(i=0∑nxiwi)=f(WTX)(令w0=b,x0=1)(写成矩阵形式)
这里激活函数不使用之前的step函数而采用sigmoid函数,
f ( u ) = 1 1 + e − u f ′ ( u ) = f ( u ) ( 1 − f ( u ) ) 记 W T X 为 u 则有 ∂ y ^ ∂ w i = ∂ f ( u ) ∂ u ∂ u ∂ w i = y ^ ( 1 − y ^ ) ⋅ x i \begin{align*} f(u)&=\frac{1}{1+e^{-u}}\\ f'(u)&=f(u)(1-f(u))\\ 记W^TX为u则有 \frac{\partial \hat{y}}{\partial w_{i}} &=\frac{\partial f(u)}{\partial u}\frac{\partial u}{\partial w_{i}}=\hat{y}(1-\hat{y})\cdot x_i \end{align*} f(u)f′(u)记WTX为u则有∂wi∂y^=1+e−u1=f(u)(1−f(u))=∂u∂f(u)∂wi∂u=y^(1−y^)⋅xi
与之前不同,误差e不再使用残差,而使用误差函数 e = 1 2 ( y − y ^ ) 2 e=\frac{1}{2}(y-\hat{y})^2 e=21(y−y^)2。若采用随机梯度法,随机测试n个样本,则每个样本会得到一个误差e,这n个样本的综合误差为
E = ∑ k = 1 n e k = 1 2 ∑ k = 1 n ( y k − y ^ k ) 2 E=\sum_{k=1}^{n}e_{k}=\frac{1}{2}\sum_{k=1}^{n}(y_{k}-\hat{y}_{k})^2 E=k=1∑nek=21k=1∑n(yk−y^k)2
由梯度下降法得权重修正值如下,再代入1.7.3的公式用于更新权重。
Δ w = − η ∂ E ∂ w = − η ∂ E ∂ y ^ ∂ y ^ ∂ w i = − η 2 ∑ k = 1 n ∂ e k ∂ y ^ k ∂ y ^ k ∂ w k i = − η ∑ k = 1 n ( y ^ k − y k ) y k ^ ( 1 − y k ^ ) x k i \begin{align*} \Delta w&=-\eta\frac{\partial E}{\partial w}=-\eta\frac{\partial E}{\partial \hat y}\frac{\partial \hat y}{\partial w_{i}}\\ &=-\frac{\eta}{2}\sum_{k=1}^{n}\frac{\partial e_{k}}{\partial\hat{y}_{k}}\frac{\partial \hat y_{k}}{\partial w_{ki}}\\ &=-\eta\sum_{k=1}^{n}(\hat y_{k}-y_{k})\hat{y_k}(1-\hat{y_k})x_{ki} \end{align*} Δw=−η∂w∂E=−η∂y^∂E∂wi∂y^=−2ηk=1∑n∂y^k∂ek∂wki∂y^k=−ηk=1∑n(y^k−yk)yk^(1−yk^)xki
2.5.2 BP网络用于MNIST手写数字识别的实验
mnist数据集为人手写体的数字图片,数据集中的每张图片由 28 x 28 个像素点构成, 每个像素点用一个灰度值表示,可将每张图片看成是一个28 x 28的矩阵,可以定义28 x28=784个输入节点;数字0到9共10个数,故可定义10个输出节点。通过构建一个有784个输入节点,10个输出节点,有一层隐层的神经网络用于手写体数字识别。网络的隐含节点个数,学习率和重复训练代际可以有所变化;隐含节点个数在10到784之间为宜,这里取50,学习率一般取值在0.1到0.5之间,这里学习率取0.26,训练代数取8代。
从数据集中取出100条数据用于测试,剩余结果用于训练,测试结果如下,正确率为0.96.!


2.5.3 python实现代码及分析
# 定义神经网络对象
class NeuralNetwork:
# 神经网络的初始化函数,包括了“输入节点、隐藏节点,输出节点,学习率”这四个可变参数
# 也包括权重向量的初始化,以及激活函数的定义。
def __init__(self, inputnodes, hiddennodes, outputnodes, learningrate):
# 定义输入节点、隐含节点和输出节点
self.inodes = inputnodes
self.hnodes = hiddennodes
self.onodes = outputnodes
# 定义权重向量
# 将正态分布的中心设为0,pow表达式的意思是节点数目的-0.5次方,采用这种方式对神经网络的初始权重进行随机化的赋予初始值。
# 产生self.hnodes * self.inodes个随机数并排成矩阵
# 输入节点和隐含节点间的权重
self.wih = numpy.random.normal(0.0, pow(self.hnodes, -0.5), (self.hnodes, self.inodes))
# 隐含节点和输出节点间的权重
self.who = numpy.random.normal(0.0, pow(self.onodes, -0.5), (self.onodes, self.hnodes))
# 定义学习率
self.lr = learningrate
# 定义激活函数,此处我们将激活函数定义为sigmoid函数,该函数在scipy包中
self.activation_function = lambda x: scipy.special.expit(x)
pass
# query函数为网络查询算法,接受神经网络的输入,返回神经网络的输出值;
# query函数遵循了神经网络的计算方式,即输入节点经过Wih权重计算得到西格玛后通过激活函数得到先得到隐含层的输出;
# 再通过第二层的Who权重计算得到西格玛后通过激活函数得到输出层的输出;
def query(self, inputs_list):
# 向量转换
inputs = numpy.array(inputs_list, ndmin=2).T
# 矩阵的点乘计算
hidden_inputs = numpy.dot(self.wih, inputs)
# 计算隐层结果
hidden_outputs = self.activation_function(hidden_inputs)
# 输出层的输入
final_inputs = numpy.dot(self.who, hidden_outputs)
# 输出层结果
final_outputs = self.activation_function(final_inputs)
return final_outputs
pass
# 神经网络的训练方法,既有输入参数列表,也有输出目标值
def train(self, inputs_list, targets_list):
inputs = numpy.array(inputs_list, ndmin=2).T
targets = numpy.array(targets_list, ndmin=2).T
# 前期的流程与query函数一样
hidden_inputs = numpy.dot(self.wih, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = numpy.dot(self.who, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
# 处理误差,并且把误差反向传播回去改进权重
output_errors = targets - final_outputs
# 对于在隐蔽层和最终层之间的权重,使用output_errors进行优化
hidden_errors = numpy.dot(self.who.T, output_errors)
# 对于输入层和隐藏层之间的权重,使用hidden_errors进行优化。
# 学习率是self.lr,它就是很简单地与表达式的其余部分进行相乘。
# 使用numpy.dot进行矩阵乘法,final_outputs *(1.0 - final_outputs)显示了与来自下一层的误差和S函数相关的部分,
# 使用2.6.1推导的公式
self.who += self.lr * numpy.dot((output_errors * final_outputs * (1.0 - final_outputs)),
numpy.transpose(hidden_outputs))
# 用于输入层和隐藏层之间权重的更新原理类似的
self.wih += self.lr * numpy.dot((hidden_errors * hidden_outputs * (1.0 - hidden_outputs)),
numpy.transpose(inputs))
pass
pass
3 深入实践
MNIST手写识别调试
承接2.6节的内容,在不修改主要代码的情况下,改变参数继续测试。首先保持节点个数不变,在不同学习率和训练代数的情况下测试正确率如下:
| 4代 | 8代 | 12代 | |
|---|---|---|---|
| 学习率0.18 | 0.93 | 0.96 | 0.97 |
| 学习率0.26 | 0.93 | 0.96 | 0.98 |
| 学习率0.34 | 0.92 | 0.92 | 0.94 |
可见,学习率过高或过低都会导致正确率下降,而训练代际增加,一般情况下可以一定程度上提高正确率。接下来,保持学习率为0.26,训练代数为8代不变,改变隐层节点个数,训练结果如下
| 节点个数 | 40 | 50 | 60 | 70 | 80 | 90 | 100 | 150 | 200 |
|---|---|---|---|---|---|---|---|---|---|
| 正确率 | 0.94 | 0.96 | 0.94 | 0.96 | 0.95 | 0.98 | 0.98 | 0.96 | 0.96 |
可见,增加隐含节点个数对正确率的提高作用并不明显,节点个数达增加到一定值后,正确率便不再上升,反而有下降趋势,可能是因为出现了过拟合问题。根据上面的测试结果,选定参数,学习率为0.26,隐层节点90个,训练代际8代,可得到较优结果,0.98的正确率,出错的两例的正确答案依此是4和2,分别误判成9和4,前者误判可以理解,因为其字迹确实模棱两可,后者人工可较明显辨认出是2,但历次训练后测试经常在这例上出错,据此分析算法有待改进。
