基于阿里云 MaxCompute 构建企业云数据仓库CDW
在本文中阿里云资深产品专家云郎分享了基于阿里云 MaxCompute 构建企业云数据仓库CDW的最佳实践建议。
本文内容根据演讲视频以及PPT整理而成。
大家下午好,我是云郎,之前在甲骨文做企业架构师8年,目前是MaxCompute产品经理。
在这么长的客户工作过程中,作为产品PD,一定是跟客户在一起的。我经常被一些问题挑战:云郎,我们现在要建数据仓库,我该怎么去规划?云郎,我现在这边是大数据的建设团队,好像数据团队不怎么理我,什么情况?云郎,我们这边现在建了一个平台,现在性能好像有问题,是不是我们哪些地方设计的有问题,还是考虑的不够?可以看到,不同的客户在不同的阶段有不同的问题,在这么多的客户问题里,背后到底隐藏了什么规律?在这里面有没有一些最佳实践,我们可以总结出来,让大家去少走一些弯路,这是我的出发点。
既然谈到最佳实践,你一定要知道哪些不是最佳实践,就像医生一定要看过很多病人以后,才更容易判断是不是健康。
我的客户从哪里来呢?
第一,是阿里巴巴本身有很多个BU,刚才我们也谈到了阿里巴巴所有的数据都是运行在MaxCompute,去做数据仓库,去做加工处理。也许你会挑战我,你解决阿里的问题,我们碰不到,没错,我也确实发现这个问题,即使我们能解决阿里的问题,但是不一定能解决客户的问题。
第二,我们碰到的问题,也不一定能代表客户的问题,因为你的规模和我不一样、你的现状和我不一样、你的能力和我不一样、你的目标和我不一样。MaxCompute也在云上提供服务,我们云上有很多客户,在座的很多朋友都是MaxCompute的用户。所以我把客户的范围进一步纳入到我目前已有的这些客户里面。也许你还会问,你说你是最佳实践,那是基于你自己产品的最佳实践,难道他不用你的产品,你就不能再去分析吗?
所以,我又分析了第三类客户,在中国,有很多企业使用了非阿里的技术,那么他们在这大数据方面又碰到了哪些问题?我相信在座各位也做过很多分享,例如A公司的大数据实践经验, B公司的大数据演进历程,那么我们也会基于这样的案例做出分析。
第四,在阿里这样的一个生态里,收购了很多公司,在外界公司和阿里内部公司融合迁移的过程中,又有哪些最佳实践?
所以我们把这四类客户统一起来看,从现象到本质,这是今天我想要跟大家分享的内容。
大家都在谈大数据,最早在2013年开始在甲骨文做信息解决方案,当时已经研究出了大数据。我在之前是做DB的,Data Base。后来发现转了个身,转成了BD,Big Data。在这个过程中,技术好像做了个变化,就翻了个身,关涛讲了很多,大家很有体会。那这些技术在过程中怎么去用?方法有没有发生变化?客户经常问我一个问题,云郎,我要拿MaxCompute来干什么?我说了不算,后来我就做了很多分析。我发现不管去做什么应用,客户在MaxCompute之上,他首先主要都是在构建他的数据仓库,现在我们把它叫作Cloud Data Warehouse,大家知道数据仓库,它既是一套数据体系,同时它也是一个工程过程,要更多的从工程的角度来看,我们看到这是现在目前业界非常典型的数据仓库实时的生命周期流程。我们发现技术从Data Base,DB转到了BD,但是这张图很多还被广泛的应用,当我跟很多客户的架构师,大数据负责人或者开发人员去沟通的时候,我们发现他背后的思路都是沿着这张设计的生命周期而产生的。那我们可以看到从这个数据仓库,当碰到Cloud Native,再到我们说转到Big Data以后,那么怎么真的去做Cloud Native这样一个Data Warehouse,我们看到在这个过程中,从项目的工程规划到业务需求,到最终我们看到一个小的迭代维护,数仓开发完成,交付大家去使用。
在这个过程中,我们可以看到传统的DB时代,是以建设为中心的一个项目。那么到了大数据,建了是生下来,养才是关键。养之道在于什么呢?在于运营。所以整个环节中,我们可以看缺失了大数据的精髓所在。
我们看分别是哪些情况呢?
第一,我相信很多人来自于互联网公司,如果你来自央企、政府部门,恭喜你,你可能没有这个痛苦,因为你有足够的时间去规划,给你半年时间,给你500万,你帮我做规划咨询出来。但你如果是互联网公司,对不起,今天上岗,明天帮我把数据拿出来,好不好?所以我们是没有那么多时间的。那我们在这里面需要做到什么呢?轻量化,我们从数据仓库整个生命周期上,我们要的是敏捷数仓。那软件工程,我们要的是敏捷开发,数据仓库。
第二,对于需求的问题,为什么你能做规划?因为你能知道后面会发生什么,你的业务基本上是固定的,你能知道政府部门后面要干什么、你能知道央企后面要干什么,但如果你是互联网公司,你到明年存不存在都还不一定,也就是说你可能还没规划完,就要转型了,业务要转型了,需求非常不明确,那你能不能做到明确,挑战非常大。
第三,如果我们规划出来一个非常完美复杂的技术方案,它的落地周期会给我们带来挑战,所以我们需要技术上能否简化?要快速才是王道。
第四,关于数据建模,你一开始就想把这些模型都建立起来,其实这是很多数据工程师经常碰到的问题,我有这么多数据,我全部都能把它灌进来,把这个模型固化下来。我们发现掉到这个井里以后,带来的后果是什么呢?你长长久久的是技术自己关在门里边,结果业务在门外边,他敲你的门,永远敲不开,因为我还在做数据模型的事情,我还在做我自己的事情。
我们可以看到关于数仓的应用,你建了大数据,绝对不是传统的把DB转成BD,你就仍然去做报表,你的场景绝不是这么简单。在这里一定还有机器学习,人工智能、预测等众多的应用,它才能发挥价值。这是一个迭代的过程。可能按月都是对这个模型比较赞美的,因为往往可能三个月是一个周期,从提出一个需求,到最后实现,在传统里,可能需要月的时间。今天按小时、按天帮我实现,我的数据仓库要发生变化,你怎么去构造?
还有就是运维这一侧,开发人员和运维人员能做到咱们今天的所谓的DevOps,如果你是数据开发人员,怎么样能做到整个大数据平台的DevOps,这是很大一个挑战。
在以项目管理为中心、以建设为中心这样的背景下,我们可以看到真正的数据运营是被忽视的,所以这是我们今天整个要引出的话题,就是数据的价值一定要通过运营才能得以呈现。运营又是什么概念呢?
企业大数据计算平台的建设,跟我们人的发展一样,刚开始,谈恋爱,蜜月期非常好,其实很多锅碗瓢盆的问题是不用考虑的。但随着建设的发展,结婚,生小孩,锅碗瓢盆的问题一定要考虑的,所以不同的问题,其实考虑的痛苦点不一样。
我们看到这样一个时间轴,横轴,以时间来推动,第一个月,六到十二个月,十二个到十八个月,到第二十四个月,在分析了上百家的企业客户后,我们看到在这样一个周期里,分别会碰到什么样的问题,技术方案不一样,但痛苦是一样的,风险是一样的,这是横轴。
纵轴,业务规模是这条黄色的线,风险是蓝色线。业务在这里面能包出来的半径就是我们所谓的价值,蓝线包起的面积就是我们的风险,刚才关涛也谈到了,说我们的业务面积和风险面积,哪一个更大,这就决定了我们的成败。我们看到这样一张图,在第一个月是蜜月期,大部分客户都可以快速的通过定制化方案,快速启动数据仓库,因为是蜜月期,非常快,这个时候有热情、有投资、有人手,我们快速一个月搞起来了。到了半年到十二个月,业务上来了、规模上来了,这个时候要搭火箭了,要快速成长了,进入青春期了,青春期这个地方是有一个火箭的,这个火箭跟小孩子的成长一样,到青春期有两个方面,你管得好,他就是一个人才,管得不好,他可能就变成了一个混混。那这个火箭就在于往哪条线上走。
随着业务大规模的扩展,数据量、计算量急速增长,这个时候就给我们的性能、成本带来了巨大的挑战和要求,系统能不能解决持续的发展矛盾,就成本、性能、数据安全和分析效率里面的矛盾随着我们业务的发展,我们现在碰到这些问题,该怎么去解决?在整个风险上升的过程中,我们看到这条线是说风险在上升的。上升了以后,有很多公司,包括我们的客户,可以看到在这个之后就会启动一轮治理和优化,包括性能的优化、成本的优化,通过阶段性的优化,达到好的效果。
接下来业务还在不断发展,我们可以看到在这两条线里面又会走向风险失控的过程中,也就是说我们的系统在这个时候变成了成本中心。我们过去因为有钱有想法,开发了很多定制化的系统,这个时候你的人员开始流动了,你所有定制化的系统就变成了什么?黑盒子,你碰都不敢碰,就放在这儿等,等SOS,这是风险演变的过程。
对于我们而言,最佳实践显然是不能走这条路的,我们要避免这样一条弯路。
再进一步的思考,对我们做的这样一个平台经过治理和优化还不够。如果我们能转型再造,其实可以回到一个好的状态,健康最佳实践的状态。那这个转型再造,以阿里大数据平台来说,有两个重要的转型再造,第一个是技术的转型再造,大家也知道,我们是最早使用云梯一Hadoop,我们从技术的转型再造就是变成我们的备胎MaxCompute,其实在2013年在阿里内部早就转正了,最近备胎很火,它在最初是备胎。转型再造由自己的技术来替换升级。
接下来,就是业务,阿里这样的规模,我们内部的技术可以输出到阿里云上,来进行业务的转型。我们获得了这样新生的过程,可以看到在整个风险转移过程中,大家是在哪一个位置,我们要有清晰的认识。我们期望的是我们的技术和业务都可持续发展。在这个里面的核心点,要解决的是成本可控和性能的不断提升。数据越多,不是变慢,而一定要更快。数据既要安全,还要共享。大家知道数据进来,谁都不能碰,是没有用的,要让数据价值要得到充分体现。
所以我们看到整个建设数据平台的阶段性风险,在这个里面,大家都会栽跟头,包括我们都会碰到很多困难。运用《三体》的一句话:“在这些拐点上,毁灭你,与你无关。”,真的是等不及的。对这样一些客户的实质性的洞察,我提出一个新的方法论,不知大家有没有钓过鱼,有没有钓过大鱼?钓小鱼时,是把鱼钩和鱼绳是直接拴在一起的,因为小鱼的力量不会那么猛。但如果你做过海钓,钓大鱼的时候,你有没有发现,如果你的鱼钩和鱼绳是直接拴在一起的,那个鱼咬了饵以后,把钩挂住以后,它会突然有一个很大的力,你的鱼绳是直的,所以它会把你的鱼绳直接崩掉,造成系统崩溃,在这个里面就会出现这样的问题,钓过鱼的人就会有这样的经验。
但是这里面是有解决方案的,鱼绳上大家都知道是有一个8字环绕线法,把这个线绕得比较虚一点,当这个鱼咬到我的钩,拉的时候,它不会直接拉后面的鱼绳,它会用力用到8字环缓冲的这一段线,它突然间把这一段线拉紧了,那一段线是多股绕在一起的,会有更大的抗击力,这时候大鱼上钩以后,这个线就不会断了。
平台和数据有没有这样一种过程?我们的平台和数据,刚才那一个过程是完全独立的,我只考虑建设平台,不考虑数据。但是我们看到在更多的企业里面,平台是一个团队,数据是一个团队,或者平台有很多拨人,数据有很多拨人,但不管怎样,平台就是平台,数据就是数据,我们说平台和数据的关系就是我中间画的一个阴阳图。所以在这里面可以看到,我们不是简单的把平台和数据的工作拼在一起,它就是8字环。我们可以看到8字环的奥妙在于从平台的策略与规划、设计与实现,这是两步。你有了最初的原型以后,有了基础平台以后,马上要进入数据运营。大家可以看到第三步,要在这个里面,有简单的数据要去发现,让数据人员去分析理解、要去探索、要去资产化、要去运营,到了这一步之后,再回到我们的平台侧去进行开发运维,再进行优化治理。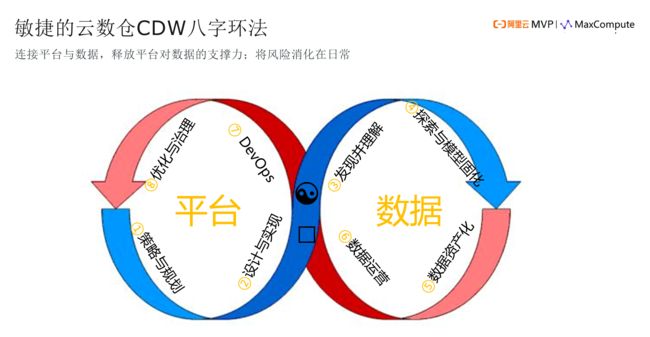
平台和数据是对立的,还是说平台孕育了数据,数据也孕育了平台,在这里面,我们树立了什么样的观点?我觉得是大家要去好好思考的。如果你是数据,你去想想你跟平台的关系。如果你是平台,你去想想你跟数据的关系是什么?这样的关系处理不好以后,基本上是不会有最佳实践的。
所以,第一个是要解决敏捷性的问题,因为你在这里面可以很快进入数据阶段,从而更敏捷。同时我们要避免刚才说的拉钩断掉的问题。要连接平台和数据,释放平台对数据的支撑力,平台本来对数据有很好的支撑力,怎么能释放出来?这是我们要考虑的。
还有一个是“风险”,我们要通过这种方式,不断的实践、验证,将风险消化在日常中。而非做了一个3年规划,到第二年才发现风险是巨大的。
针对如上内容,给出几点建议。
- 你是否试图通过大数据解决未知问题,还是天天在做已知的报表?
- 你是否有去做预测?是否有做机器学习?是否有对预测性问题的分析?
- 你是否有去引入外部数据来解决问题?大家也可以看到,刚才我为了要回答最佳实践,作为一个产品经理,他要去获得的数据源,不仅限于阿里内部客户和云上客户,如果我不能去看那些使用了非阿里大数据客户的情况的话,他本身也不是一个大数据思维的工作方式,所以我觉得它是一个思考的模式,无处不在。
- 你对待数据的态度。很多时候,数据处理完,就没事了。其实你在这里面不断的探索、挖掘、分析其中他人不知道的问题,这才是价值。你能发现问题、解决问题,就是价值,价值不是虚的,问题能解决了,就是有价值。但是我们做了吗?在这个过程当中,你也许会说人家没有给我提需求?如果别人提了需求,你来做,这叫支撑。如果你能发现问题,让别人去做,这叫驱动。什么叫数据驱动型,如果这些事情我们都不干,它不就是一个虚无飘渺的东西吗?
- 关于我们组织的问题,虽然说我们在做大数据,但是我们对它的态度是什么呢?每个人在谈PPT的时候,都会说数据是资产,从来没有人说服务器是资产。但是你做的时候,你一定会说:“我没有服务器,我怎么能活呢?我怎么能做事情呢?”我们看到就变成这样一个模式,在这种模式下,你可以看到貌似数据无处不在,但是数据到处不能用,因为到处都是孤岛。我们可以看到在数据驱动型的组织里面,整个业务本身是受数据驱动的,比如说蚂蚁金服,所以你的数据在中间,业务在外面。这样的情况下,你才可能把本末倒置的问题解决掉,这是关于组织的问题。
我们对驱动组织做了一个分类,数据支撑了我们运营、生产最基本的工作,还是支撑了我们的管理工作,还是对决策起到了作用,到底在哪一个层面上?


一定要基于可持续发展的策略进行规划,以终为始去想这个问题,这个终,可能是一年、两年、也可能是三年。阿里有句话,路走对了,就不怕远。但是我们走错了,本来往东的,就走西了。在规划阶段要看四个方面。
- 第一,TCO和TVO,TCO是我们整体运营的成本,我们要花的钱。TVO是我们想要得到的价值是什么?
- 第二,技术方案。
- 第三,可持续发展。
- 第四,风险控制。
挑重点来说,第一,大家都谈到TCO,我觉得大家要注意财务的结构,不同的公司的喜好程度是不一样的,有的希望现金流更充足,有的希望一下子能把钱花出去。要符合企业财务的成本结构,也就是说你要把它变成一次性的资产支出,还是变成日常的运营支出?要想清楚企业要的是什么?如果这个搞不清楚,后面就是很大的矛盾。
第二,在这个过程中不要忽视隐性支出,要知道隐性成本是什么的,不能对隐性成本是视而不见的。TVO,我们要以终为始,兑现数据的业务价值。
做大数据的同学,不管是做数据还是做平台,如果我们不能帮助企业兑现数据的业务价值,可能很快就会面临残酷的结果。这里的价值,就是我们通过支撑业务、驱动业务也罢,你一定要挖掘出数据的价值的。
关于技术方案。说到定制化,通常因为我们后面看到了风险,定制化就变成黑盒。我们说定制化和产品化的边界要考虑清楚。当我们无限的扩充自己定制化边界以后,你要想到有一天这些东西变成黑盒子以后,它意味着什么?另外,你是选择服务器,还是无服务器,我们的聚焦点是平台,还是数据,这是大家要去考虑。
还有业务适配,不要总是推倒重来。风险应尽早暴露,大家知道规划出来都是PPT文档,文档里面都是坑,你越晚执行,坑就埋得越久,前面滚雪球滚得很大了,后面解决起来,成本就非常大了。跟软件开发缺陷解决的原理是一样的。这个里面一定要有风险意识。
关于规划,在设计阶段,要支持快速的实现。并非要求你一天做到,但在互联网行业去做,可能两周、一个月,往往三个月就是个阶段,能快速实现,三个月真的是一个很长的时间。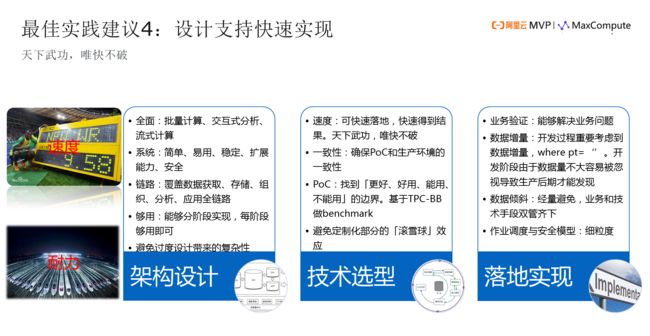
架构的设计,从全面性、系统、链路,这都是很美好的事情,但是我真心给出建议是够用就好了,不要过度设计。
技术选型,在PoC我们要找的是什么?好用、能用、不能用?你要在这个里面找到它们的边界、它们的拐点。你总是找每个系统里面最好的那一点,但是你不知道这个里面不可用的点在哪里?我举一个例子,大家就明白了,就是你评测这个系统的时候,你要知道它哪个地方更好,哪个地方好用、哪个地方能用、哪个地方不能用?当有人承诺所有都是最好用的时候,你就一定要注意。要避免定制化部分的滚雪球,避免定制化陷阱。
在落地实现方面,举个例子,数据增量,对开发者而言,做数据开发时,比如我写一个数据的生产过程,那时候的数据量很小,你不会考虑分区。180天以后,因为你没有考虑外延,它慢慢就增多到180倍了,这个最佳实践,大家是要留意的。后面我们的团队也会总结出来一个技术方面的最佳实践。包括数据倾斜、作业调度与安全模型、细粒度,这些大家都要考虑到。
在数据价值呈现中,要结合我们的数据探索和模型固化,因为数据仓库都是讲模型固化的,一定要有模型。但是模型,大家知道周期会变长、会变得僵化、业务会变得不灵活,所以我们一定要把模型固化和数据探索结合起来,结合刚才那位同学关注的数据混合和数据仓库的关系,在我看来,数据仓库更适合做模型这一块的工作,数据混合往往更适合去做数据探索。你可以在数据探索中很快的发觉隐藏的问题,更快速的进行数据分析,但也会面临挑战,数据授权、产出是问题。因为你无法把你所有的数据都放在里面,让每个人想看什么就看什么。数据仓库,我们拼了命的做安全,仍然受到大家的挑战,这是现实问题。
探索之后,如何更敏捷的做数据仓库呢?那么你通过这个里面探索出来的模型来提高复用,通过复用来提升效率。通过模型传播知识,例如,我如何了解我客户的活跃程度呢?我们通过模型,拿到这个模型以后,另外一个同学也就理解了,这个模型里面藏的是知识。还有降低成本,所以我们把Schema、Schema less这两种结合起来,将会进一步提高我们数据处理分析的敏捷性。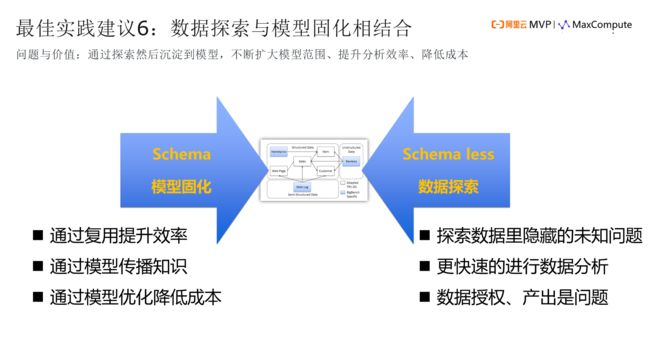
还有就是数据资产化,否则的话,你永远都说不清楚你自己的价值,你其实在帮别人做一个什么呢?你是在做别人成本的事情,你只有把它资产化了,做数据的人才能说清楚自己的价值在哪里。通过资产化可以做什么?要为治理提供依据,你只有列得清清楚楚了,才知道哪个地方花多了、哪个地方花少了,花得健康不健康,要有这样健康排名。有了这个排名,我们就可以做数据运营。
很多时候,数据运营被解释成数据化运营。数据化运营和数据运营是截然不同的概念。数据化运营是指拿了数据以后,去做运营工作。数据运营,指的是说要把我的数据运营起来。这里,可以结合货币的概念,流动性。要提高数据的流动性,提高在数据管理团队以外的投放量,这是很金融化的一个词,我在准备的时候,就是看了金融的模型来做这个事情。因为要解决流动性的问题金融行业最有经验,所以我也看了模型。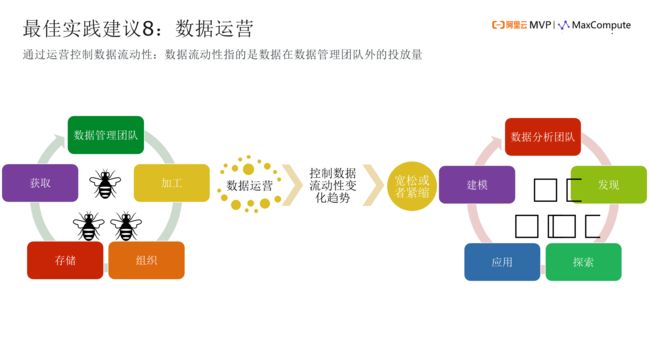
投放量,我们可以看到,这是我们的数据管理团队,大家都像小蜜蜂一样很勤劳,数据获取、加工组织、存储。。。小蜜蜂和蜂王都很勤快。那猫头鹰在哪里呢?这个图怎么没显示出来,做数据分析的人不是小蜜蜂,应该是猫头鹰,非常敏锐,眼睛很毒。数据分析要发现、要探索、要应用、要建模,在这里,通过数据运营核心要做什么呢?控制数据的流动性变化趋势,你的数据,谁在用?流到哪个地方去?你现在公司的数据流动性,你要采取紧缩政策,还是宽松政策?我们一定要把这个事情做起来,你可以通过数据安全来做,也可以通过专门的团队来做,如果没有这部分,就会有风险。
关于数据安全、数据生产管理、数据质量管理、开发管理,我们也要做到适可而止,不要过度。以安全为例,最初的时候,我作为MaxCompute PD,给客户推荐 MaxCompute是有细粒度安全管理的,你一定要用上。后来,客户慢慢教育了我,细粒度的安全管理固然很好,但他到用的那一天,他自然会用。他没用的那一天,固然有他的理由。因为任何管理,越细,成本就越高。企业是否愿意在这方面投资,这就是一个现实的问题。如果我没有那么多的投资,势必就会考虑把数据的授权范围做到以部门、团队为授权对象,授权粒度以一个项目为主就够了。所以要平衡细粒度安全管理和管理成本,并做出选择。包括生产管理基线,开发环境,质量管理等,一定要在管理上将责任落实到人,还要实现完善的监督机制,去确保这个能落实,保证数据质量。
优化和治理,往往是个沉重的话题。先说我们的城市,以前谈城市管理,现在谈城市治理。城市小的时候,管理就够了,城市大了,就要治理了,治理什么?三个字,脏乱差。就像我们的系统大到一定程度后,也会出现脏乱差。所以需要治理,要从计算层面、存储、质量、模型、安全、成本方面进行全方位治理,这当中最有效的抓手就是成本。在整个治理的闭环中,有现状分析、问题诊断、治理、优化、效果反馈,这些我们都要去落实,才能根本上治理脏乱差。
最后,我们来看基于MaxCompute构建大数据平台。从数据开发,是一套Dataworks的平台,通过接入业务数据源,到数据接入、到数据处理、数据服务以及到应用,这是一个完整的大数据解决方案。在整个大数据平台中,我们强调小核心、大外围。其实在大数据平台中,数据处理占据了80%以上的成本,所以一定要让它简单。阿里基于这样一个策略,推出了完整的解决方案。处理方面有MaxCompute,机器学习方面有PAI,在流计算方面,我们有Stream Compute。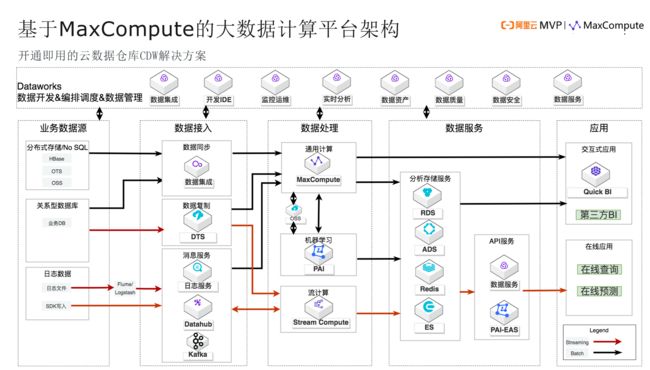
刚才谈到的关于数据那部分内容,这是平台、这是数据,由这张图映射到刚才我们说的数据中孕育着平台、平台中孕育着数据的这样一个设计理念。在上面,这是以数据为中心的,在下面,这是以平台为中心的,整个合成我们想要的大数据处理平台。
同时我们也分析了很多客户,很多客户都已经选择了Hadoop。所以,我们也推出了MMA迁移工具和迁移服务,来帮助我们把Hadoop这样的集群迁移到阿里云的MaxCompute和Dataworks,以及后面的机器学习PAI、流计算等等来帮助我们加速、提效、提高准确性。
最后总结一下,从方法到落地,我背后的思想就是8字环。这边是数据、这边是平台。平台侧,一定要支持按需裁减的方案。在这个过程中,要分阶段实施,整个过程中,性能、成本、灵活扩展性、数据的安全以及稳定运维的复杂度是我们要关注的问题。数据侧,我们要关注并打通数据的全链路,要关注全域数据以及数据资产化。
总之,通过我们背后的指导思想和我们给出的技术解决方案,希望与大家能够一起探索一些新的基于云上的数据仓库构建的最佳实践,从而尽量避免走弯路。这就是所有我今天想跟大家分享的内容与目的,非常感谢!
欢迎加入“MaxCompute开发者社区2群”,点击链接申请加入或扫描二维码
https://h5.dingtalk.com/invite-page/index.html?bizSource=____source____&corpId=dingb682fb31ec15e09f35c2f4657eb6378f&inviterUid=E3F28CD2308408A8&encodeDeptId=0054DC2B53AFE745
本文为阿里云原创内容,未经允许不得转载。
云栖号 - 上云就看云栖号