大数据概述【一】
1、什么是大数据
最早提出在2002年,来源于美国的麦肯锡报告
4V特征:
Volume(数据量大):PB级
Variety(数据多样性):文本、图像、视频、音频等
Velocity(输入和处理速度快):流式数据
Value(价值密度低):需要积累很多的数据才能发掘大数据隐含的意义,只要能发挥和挖掘数据隐藏的价值,不用纠结于数据量大小
由维克托·麦尔-舍恩伯格提出,被称作大数据之父
大数据核心问题:存储、计算和分析。通过组件(计算框架)解决
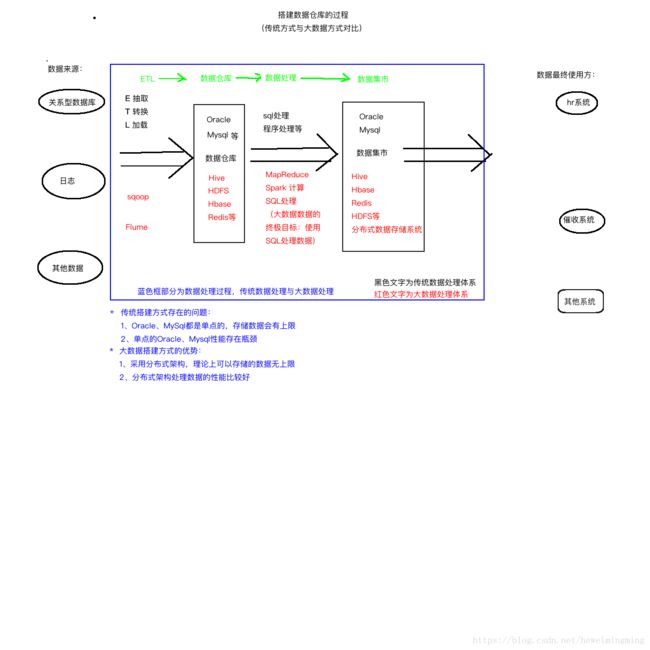
2、数据仓库和大数据
1、传统方式:DW(Data Warehouse),基于传统的关系数据库(Oracle、Mysql等),一般只做查询分析。TD(Teradata 天睿)数据仓库一体机。 2、数据仓库VS大数据 数据仓库:Share Everything,存储、计算、CPU共享 大数据:Share Nothing,单独计算(map)、结果汇总(reduce) (去红楼梦里找林黛玉出现了多少次,一个研究生(高性能服务器)读可能要一天,10个小学生(低性能服务器)读也要一天,但是研究生更贵,所以我们选择小学生方案)
3、OLTP和OLAP
1、OLTP: Online Transaction Processing 联机事物处理:(insert update delete) ACID: 所有的数据可追溯。-传统关系型数据库(Oracle Mysql Postgresql等) 2、OLAP: Online AnalyticProcessing 联机分析处理 真正生产中是二者的结合:OLTP(后台操作,前台展示,数据设计等) + OLAP(Hive, Hbase, Spark等)
4、Google三篇论文
4、1、GFS: Google File System《分布式文件系统》
主要是为了解决Google搜索内容和存储问题,造价低,易扩展。
倒排索引(Reverted Index)
4.1.1 传统的文件系统存在如下问题:
1、硬盘不够大。
2、数据存储单份,比较危险。
而Google提出的GFS(Google File System)思想能解决以上问题。GFS核心的思想是硬盘横向扩展以及数据冗余。
4.1.2 GFS的优点:
* 理论上能存储无限数据,因为硬盘可以横向扩展。
* 容错性,数据冗余多份,多份数据同时损坏的概念几乎为零。
* 存储大数据的性能比传统关系型数据库好。
4.1.3 分布式文件系统HDFS体系结构如下图:
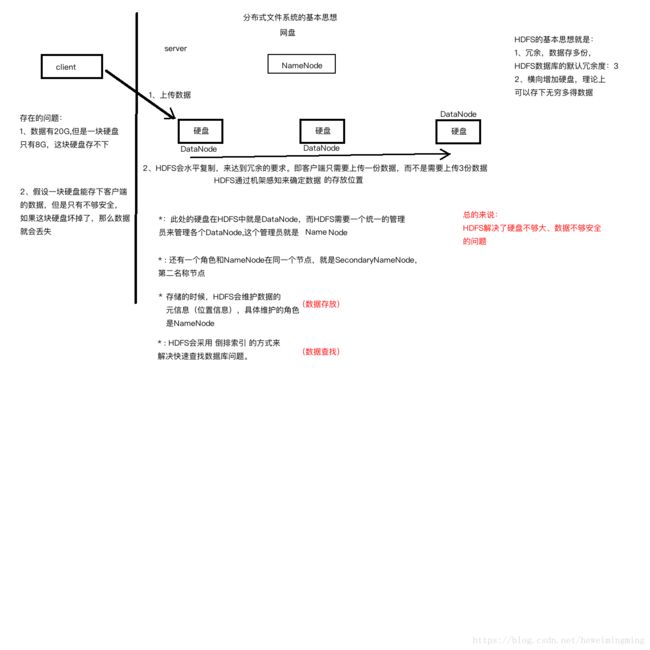
其中上传数据到分布式文件系统的基本过程如下(具体过程后面的文章再讲):
1、客户端上传数据块到其中一个硬盘。
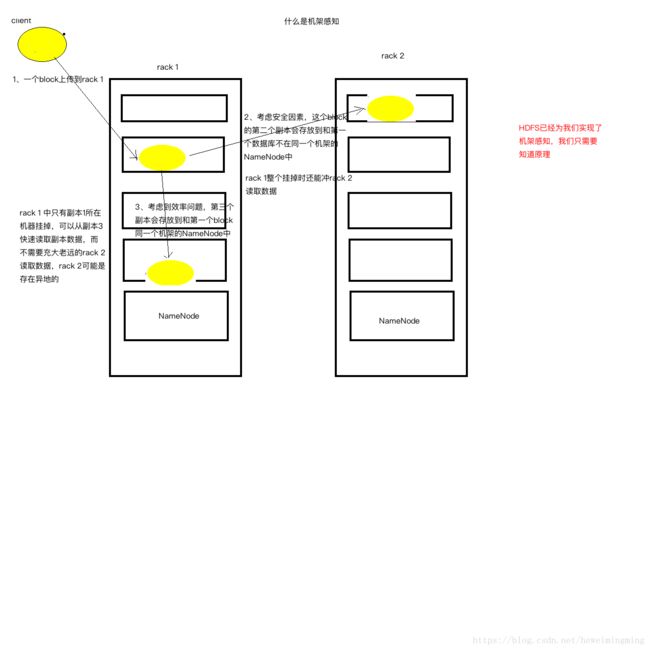
2、分布式文件系统会根据机架感知计算出存储数据库的位置,通过水平复制冗余多份数据。
那么何为机架感知?如下图:
4.1.4 分布式文件系统如何提高查询速度?
(HDFS通过倒排索引存储元数据)
采用倒排索引,倒排索引本质上也是索引。
说到倒排索引能联想到正排索引。那么什么是正排索引和倒排索引。通过如下例子来说明:
正排索引:根据文件找到关键字(如所有引擎爬到一个文件,这个文件提取出10个关键字,根据这个文件找到这10个关键字)
倒排索引:在搜索引擎中输入一个关键字,需要搜索出相关的文件,如果使用正排索引,需要遍历所有文件,这是不可能去遍历的(效率太低)。就产生了倒排索引,倒排索引是记录关键字对应文件的位置,把文件的位置根据关键字存起来,那么输入一个关键字的时候,就知道这个关键字所对应的文件都在什么地方,从而快速搜索得到相关的文件。
4.2分布式计算模型
2、MapReduce: 分布计算模型。
分而治之。
PageRank3、BigTable:大表
把所有数据存入一张表中,通过牺牲空间,换取时间。
4.2.1 来源:分布式计算模型来源于PageRank(网页排名)
4.2.2 什么是PageRank?
Google每天爬取海量的网页,那么如果按照重要程度来排名网页,应该如何排序?
如下图例子,下图说明的是4个网页之间如何排序,核心思想是把网页之间的关系转换成矩阵,因为矩阵是可以计算的,那么可以计算出各个网页的重要程度,用数据来表示,数字越大表示越重要。但是Google每天爬取的网页数量是非常庞大的,实际上不可能用一个矩阵来计算,因此分布式计算是来解决这个问题的。核心思想是把一个大的矩阵拆分成很多足够小的矩阵,计算每个小得矩阵,再合并各个小矩阵的结果,从而得出大矩阵的结果,而这个过程是在分布式环境中运行的,如下图: 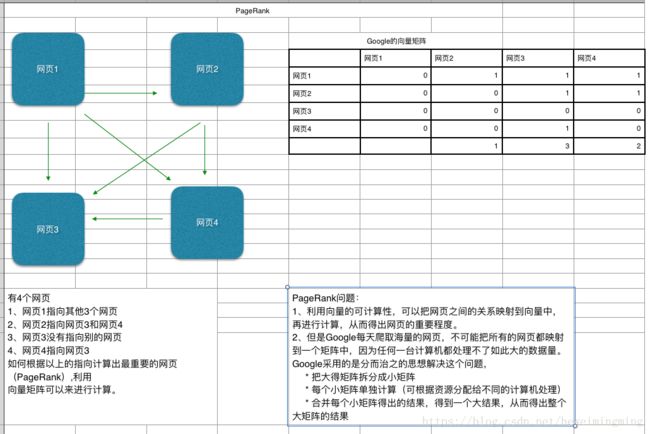
4.2.3 分布式计算框架MapReduce
关于MapReduce,有几点需要注意:
1、Map阶段的输出,是Reduce阶段的输入。每个Map输出的是一个值,Reduce阶段的输入是一个集合,集合中的每个元素就是Map的每个输出值。
2、Map的输入来自HDFS,Reduce也输出倒HDFS。
3、图中分别有4对key-value值。分别是k1 v1,k2 v2,k3 v3 ,k4 v4,分别是Map的输入,Map的输出,reduce的输入,reduce的输出。
4、k2=k3,v2的类型和v3的类型一致
5、MapReduce所有的输入输出类型必须是Hadoop的类型:LongWritable,java中得String对应Hadoop中得Text,java中得null对应hadoop中得NullWritable.
6、MapReduce的输入输出必须实现hadoop的序列化,除了原生类型,也可以是自定义类型,但必须实现hadoop序列化。
7、从hadoop2.x后,MapReduce程序必须运行在Yarn框架中,本地模式除外(本
地模式没有YARN,也没有HDFS,本地模式中的MapReduce就是一个单一的java程序) 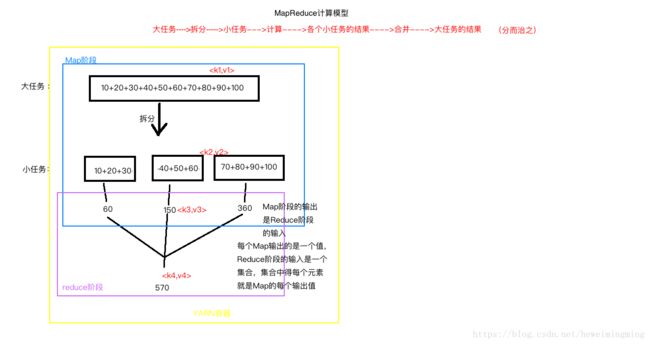
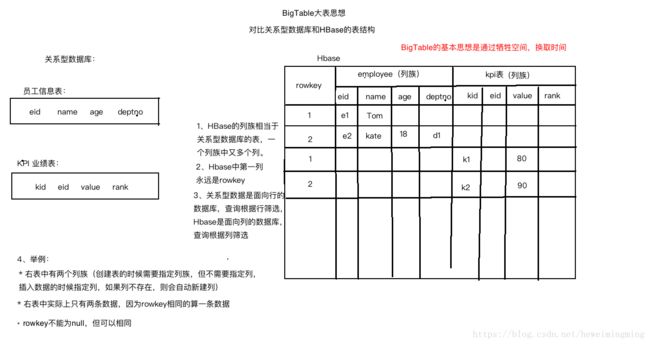
4.3 BigTable
4.3.1 大表的基本思想:把所有数据存入一张表,通过空间换取时间。
4.3.2 HBase是hadoop生态中大表的实现,看下面一个例子,对比数据存在关系型数据库Oracle和存在HBase中