FastSpeech理解分析和代码模型展示
文章目录
- FastSpeech:Fast, Robust and Controllable Text to Speech
-
- FFT Block
- Length Regulator
- Duration Predictor
- DURIAN(Tencent AI Lab)
FastSpeech:Fast, Robust and Controllable Text to Speech
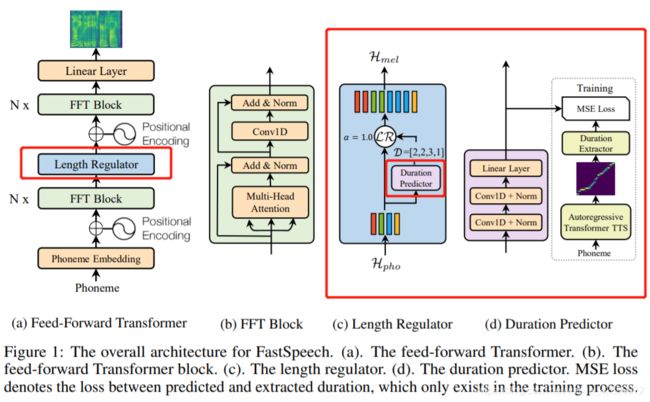
Feed-Forward模块在Phoneme端和Mel端都有各自N x FFT Block,这个Block其实就是一个非线性的模块,FFT是Feed-Forward Transformer的缩写,然后在二者之间有一个长度调节器Length Regulator,主要用来解决phoneme sequence和mel sequence长度不匹配的问题,这就是整个FFT的模型的框架。
FFT Block

FFT block和传统的Transformer中block比较类似,包括Multi-Head Attention以及非线性的计算,在speech问题上把dense connection换成了1D的卷积网络来计算非线性。同时,在Phoneme端和Mel端share了同样的模型结构,只是参数不共享。
Length Regulator
如图C所示,Length Regulator用于解决前向反馈Transformer中音素序列和频谱图序列之间的长度不匹配问题,以及控制语速和部分韵律。通常一个音素序列的长度小于它的mel频谱图序列,并且一个音素对应几个mel频谱图。定义对应于一个音素的mel频谱图的长度为phoneme duration。根据phoneme duration d将音素序列的隐藏状态扩展d倍,然后隐藏状态的总长度就等于mel频谱图的长度。
H m e l = L R ( H p h o , D , a ) H~mel=LR(H~pho,D,a) H mel=LR(H pho,D,a)
Length Regulator的作用是将Encoder Output智能地填充到与Mel Spectrogram一致的长度,Encoder Output先进入Duration Predictor,Duration Predictor根据Encoder Output输出一组数字,如[2,3,1,2,3],然后Length Regulator将Encoder Output的第一个向量复制1次,第二个向量复制三次,第三个不复制,第四个复制1次,最后一个复制2次,这样,2+3+1+2+3=11等于目标梅尔声谱图的长度,超参α用于控制语速等。
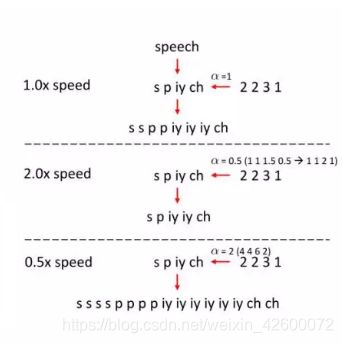
在展开Phoneme sequence时,我们引入了α(长度调节机制),如果α=1,它是一个正常的语音合成的长度,也就代表合成的语音的速度,如果我们想合成更快速的语音,我们可以把a调小一点,如上图右侧部分,把a调成0.5,那么对应的Duration会降低1倍,这样它展开的Phoneme sequence就变成了一个很短的Speech发音,来实现更快速的发音;如果我们想要慢速的声音,可以把a调大,它展开的Phoneme sequence就变成了很长的Speech发音,来对应比较慢的语音。
class LengthRegulator(nn.Module):
""" Length Regulator """
def __init__(self):
super(LengthRegulator, self).__init__()
self.duration_predictor = DurationPredictor()
def LR(self, x, duration_predictor_output, alpha=1.0, mel_max_length=None):
output = list()
for batch, expand_target in zip(x, duration_predictor_output):
output.append(self.expand(batch, expand_target, alpha))
if mel_max_length:
output = utils.pad(output, mel_max_length)
else:
output = utils.pad(output)
return output
def expand(self, batch, predicted, alpha):
out = list()
for i, vec in enumerate(batch):
expand_size = predicted[i].item()
out.append(vec.expand(int(expand_size*alpha), -1))
out = torch.cat(out, 0)
return out
def rounding(self, num):
if num - int(num) >= 0.5:
return int(num) + 1
else:
return int(num)
def forward(self, x, alpha=1.0, target=None, mel_max_length=None):
duration_predictor_output = self.duration_predictor(x)
if self.training:
output = self.LR(x, target, mel_max_length=mel_max_length)
return output, duration_predictor_output
else:
for idx, ele in enumerate(duration_predictor_output[0]):
duration_predictor_output[0][idx] = self.rounding(ele)
output = self.LR(x, duration_predictor_output, alpha)
mel_pos = torch.stack(
[torch.Tensor([i+1 for i in range(output.size(1))])]).long().to(device)
return output, mel_pos
Duration Predictor
如图D所示,duration predictor由包含RELU激活的两层一维卷积网络组成,然后接着layer normalization 和dropout layer,以及一个额外的线性层以输出标量,这正是predicted phoneme duration。请注意,此模块位于在音素侧的FFT模块顶部,并与FastSpeech模型一起进行训练,以预测每个音素的4个Mel频谱图的长度,并具有均方误差(MSE)损失。 我们在对数域中预测长度,这将使它们变得更加高斯,并且更易于训练。请注意,经过训练的持续时间预测变量仅用于TTS推断阶段,因为我们可以在训练中直接使用从自回归teacher模型中提取的音素持续时间。 为了训练duration predictor,我们从自回归teacher-TTS模型中提取了真实的phoneme duration。
Duration Predictor负责根据Encoder Output预测出每个向量对应需要复制的次数。这里,为了改变传统seq-to-seq模型隐式的Alignment,加入了显式的Alignment的标签(如图一最右侧),该标签由Transformer-TTS的Attention部分提供。因为Transformer是Multi-Head,制定了一个标准,选择了一个最佳的Head用作Alignment,Duration Extractor这一部件用于从此Head的Attention Matrix中提取目标。Duration Predictor的预测结果与目标做MSE Loss,在整个训练过程进行反向传播。
-
训练一个自回归encoder-attention-decoder的transformer TTS模型。
-
对于每个训练序列对,从训练好的teacher模型中提取decoder-to-encoder注意力对齐信息,从multi-head中选择对角线属性(音素和梅尔谱图序列单调对齐)最好的head。
-
根据duration extractor d i = ∑ s = 1 S [ a r g m a x t a s , t = i ] d~i=\sum_{s=1}^S[argmax_t a_{s,t} = i] d i=s=1∑S[argmaxtas,t=i]提取phoneme duration序列 D = [ d 1 , d 2 , . . . , d n ] 。 D=[d~1 ,d~2 ,...,d~n]。 D=[d 1,d 2,...,d n]。
最核心的模块还是Duration预测器,因为Duration预测准了,后面展开的机制其实是一个确定的机制,很关键的一个点是Duration Predictor如何去预测。主要由几层1D的卷积网络构成,针对每一个Phoneme输出对应的Duration。其中一个核心的问题就是Duration label信息从哪来。
我们在FastSpeech中设计了一个自回归的teacher模型,teacher模型训练好之后把相应的Phoneme作为输入,然后再生成语音得到一个attention map,这个attention也就是在speech和text之间的attention。我们可以看对应每个Phoneme有多少连续的mel帧去attention(也就是注意到Phoneme上了),我们就可以认为这个连续帧的帧数就是这个Phoneme的Duration 信息,就是这个Phoneme应该发多少帧的梅尔频谱声音。通过这种方法,我们把Duration的信息抽取出来作为Duration Predictor预测的label信息,通过MSE Loss来训练这个Duration Predictor,Predictor是和FastSpeech模型端到端一起联合训练的。
class DurationPredictor(nn.Module):
""" Duration Predictor """
def __init__(self):
super(DurationPredictor, self).__init__()
self.input_size = hp.d_model
self.filter_size = hp.duration_predictor_filter_size
self.kernel = hp.duration_predictor_kernel_size
self.conv_output_size = hp.duration_predictor_filter_size
self.dropout = hp.dropout
self.conv_layer = nn.Sequential(OrderedDict([
("conv1d_1", Conv(self.input_size,
self.filter_size,
kernel_size=self.kernel,
padding=1)),
("layer_norm_1", nn.LayerNorm(self.filter_size)),
("relu_1", nn.ReLU()),
("dropout_1", nn.Dropout(self.dropout)),
("conv1d_2", Conv(self.filter_size,
self.filter_size,
kernel_size=self.kernel,
padding=1)),
("layer_norm_2", nn.LayerNorm(self.filter_size)),
("relu_2", nn.ReLU()),
("dropout_2", nn.Dropout(self.dropout))
]))
self.linear_layer = Linear(self.conv_output_size, 1)
self.relu = nn.ReLU()
def forward(self, encoder_output):
out = self.conv_layer(encoder_output)
out = self.linear_layer(out)
out = self.relu(out)
out = out.squeeze()
if not self.training:
out = out.unsqueeze(0)
return out
DURIAN(Tencent AI Lab)
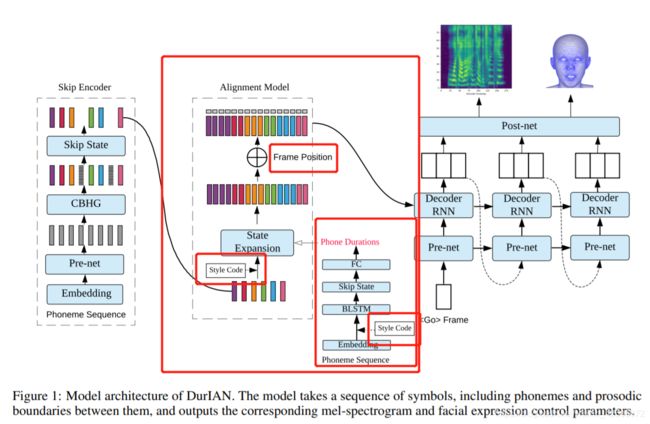
DURIAN与fast speech有异曲同工之妙。
相关参考链接如下:
http://blog.sina.com.cn/s/blog_8af106960102xhy9.html
https://zhuanlan.zhihu.com/p/67939482
https://mp.weixin.qq.com/s/qdFwvnT2HlYqDzl20co3NA
https://www.cnblogs.com/skydaddy/p/11988186.html
https://www.cnblogs.com/skydaddy/p/12174666.html
https://zhuanlan.zhihu.com/p/98692254
欢迎进群交流~