工程项目创新实践课程-esp32单片机tcp/udp传输图片到opencv的实现
写在最前面
内容来自我写的报告,文章结构也照搬了我的报告,因为报告有篇幅限制删掉了很多代码。水平很低难免有不少错误,希望看到的朋友可以帮我指出,后续会继续整理,继续更新。
越是学习,越觉得自己只是一个小学生,甚至有点滑稽,根本没有自己的创新,更多的时候只是一个搬运工,一个调包侠。诚然其实调包、调试代码事情也没那么简单,但是更希望自己能做一些属于自己的东西,令自己满意的东西,令自己赏心悦目的东西。
希望未来回来看的自己仍然继续探索继续探索计算机的世界,保持热爱,在更深的层面探索开发。
文章目录
- 写在最前面
- 一、课题背景
- 二、解决主要问题
- 三、关键技术
-
- 3.1 ESP32物联网技术
- 3.2 PC端python数据接口
- 3.3 ESP32web技术
- 3.4 ESP32舵机云台控制
- 四、实验数据
-
- 4.1图片视频系统
-
- 4.1.1 图片视频系统简介
- 4.1.2 图像采集单片机核心代码
- 4.1.3 TCP连接下python数据接收接口核心代码(HTTP)
- 4.1.4 改进1:对TCP连接下python数据接收接口的速度改进
- 4.1.5 改进2:用jpegturbo对python的opencv中解码速度改进
- 4.1.6 改进3:改用ttgo-camera开发板
- 4.1.7 改进4:esp32由sta模式改用ap模式
- 4.1.8 改进5:相机属性设置
- 4.1.9 改进6:由tcp传输改为用udp传输
- 4.2 ESP32AsyncWebServer的web
-
- 4.2.1web模块简介
- 4.2.2 web实现关键代码
- 4.3 ESP32舵机云台控制
-
- 4.3.1 舵机云台人脸追踪设计思路
- 4.3.2 控制原理
- 4.3.3 控制细节
- 4.3.4 esp32控制舵机核心代码
- 4.3.5 获取舵机角度的pc端程序核心代码
- 4.3.6 舵机云台应用其他思路
- 五、结论
- 六、代码
-
- 6.1 pytorch的人脸检测模型
- 6.2 UDP下改造人脸识别模型接口程序
- 6.3 UDP TTGO-camera代码
- 6.4 TCP web服务器
- 6.5 TCP人脸识别模型接口程序
- 6.6 TCP esp32cam图片传输代码
- 6.6 esp32控制舵机代码
一、课题背景
课题为“疫情下基于ESP32的居家隔离登记系统设计与实现”,借此课题对ESP32即时视频传输和与深度学习项目进行研究,是我主持的已结项大创项目“基于深度学习的面部表情识别方法在远程考试巡查系统中的应用研究”中技术的延伸与改良,为现在正在进行的大创“基于深度学习的智能垃圾分类箱”作铺垫。
随着社会的发展和当下疫情的特殊形势,在社会各行各业出现了一定程度上对视觉人工智能技术的需求,然而可以在本地采集并运行人工智能模型应用的设备价格不菲,而且在一些领域还有对无线的需求。针对这种情况有人提出可以由相对廉价单片机设备采集图像并通过网络交由pc或服务器进行处理,来压低成本,但由于全球贸易波动,之前由国外芯片主导的单片机价格也水涨船高。但随着中国芯片行业的发展,由上海乐鑫公司研发的esp32芯片给了这个情况一个答案,esp32芯片性价比极高,芯片的性能、价格和可拓展性完全适配了廉价采集设备的需求。
2020年esp32cam由安可信推出,这个含ov2640摄像头和esp32-s芯片的开发板有极低的价格和同价位无可匹敌的性能,完全可以承担采集设备的任务。
二、解决主要问题
课题以居家隔离登记系统为例,主要介绍实现基于esp32系列芯片实现的图像传输的方法和python环境下opencv的上位机接口程序,通过物联网技术在pc上实现高性能的人脸识别。还介绍在两轴舵机云台上实现的人脸识别追踪和用esp32搭建异步web服务器提供的web服务这两种对系统的扩展。
三、关键技术
3.1 ESP32物联网技术
ESP32自带WIFI蓝牙双模,并且官方提供一种ESP32now的方法来实现不同esp32设备之间的通信。但课题设定的背景应该需要一种更通用的办法连接各种各样的设备,而WIFI无线网络及计算机网络技术必定是通用性和性能各方面权衡下最好的选择。在传输各种数据包括文本、图像、文件等时,我们常选择的传输层协议一般为TCP和UDP,应用层常用运行在TCP之上的HTTP和MQTT。在本课题中分别介绍TCP的http连接和udp的直接传输,而mqtt速度慢且不免费暂未考虑。由于硬件性能限制,MTU大约在1300字节左右,在UDP中将介绍对数据的手动分包。
3.2 PC端python数据接口
介绍分别在TCP与UDP下python实现数据收发,和摄像头图像在opencv中的重现,并以一个MTCNN来模型检测人脸、参考了ArcFace的损失函数结合MobileNet来识别人脸的项目为例介绍数据接口与实际人工智能项目的结合。
3.3 ESP32web技术
ESP32提供http服务的同时也支持web,可以静态写入HTML+css+JavaScript代码,应用Ajax等,但受制于开发板的内存限制,无法完成一些复杂的页面系统和应用现在流行的前端框架。Web的实现在本项目中可以极大丰富交互性,但也有设备带来的局限性,比如在板子中无法同时运行tcp和udp协议等。可以采取的办法是可以使用一个额外的设备搭载tcp服务器,下文将以一个疫情登记系统为例介绍实现在esp32上的简单前后端技术。
3.4 ESP32舵机云台控制
用esp32控制一个两自由度的舵机云台实现对人脸的追踪和通过GUI界面进行遥控方法是用esp32接收来自pc的角度信号,利用http的get请求附带角度信息从pc发送到esp32。
四、实验数据
4.1图片视频系统
4.1.1 图片视频系统简介
视频采集当前使用esp32系列单片机试验了两种为客户端提供图像的方法,一种为jpg模式,一种为mjpg模式。jpg模式是最容易实现也容易想到的一种模式,方法是当链接被客户端get请求访问,通过链接将图片发送至客户端,由客户端进行下一步处理。而mjpg模式,mjpg是一种视频编码格式,esp32服务器有支持将mjpg视频流直接传输,但是Opencv无法通过videocapture直接读取mjpg数据流,必须采用socket套接字方法进行传输,而且实际上videocapture原理与循环获取最新帧的原理一致,并无速度上的巨大优势。
视频处理是在pc上运行了一个人脸识别项目对单片机采集的数据进行处理,包括对数据的接收解码等,输出一个带有人脸识别结果的视频窗口。
下面将以整个项目的帧率性能为线索对视频采集系统进行介绍,一下帧率为一百次运行取平均帧率,帧率受网络状况,电脑性能等因素影响,仅有相对对比意义。(这个表数据不科学,但是大体上是这个趋势)
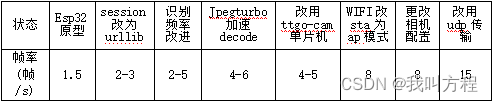
4.1.2 图像采集单片机核心代码
采用GitHub开源项目esp32cam对esp32cam单片机进行快速开发,esp32cam封装了官方关于camera提供的方法,为开发者提供了webserver适用的方法,服务器可开启总的开启了三个通道,分别用回调函数实现对http请求回复mjpg视频流、jpg图像。此时单片机工作在sta模式下,开启的是同步tcp服务器。
esp32cam库地址
void serveJpg()//jpg核心服务
{
auto frame = esp32cam::capture();
if (frame == nullptr) {
Serial.println("CAPTURE FAIL");
server.send(503, "", "");
return;
}
Serial.printf("CAPTURE OK %dx%d %db\n", frame->getWidth(), frame->getHeight(),static_cast<int>(frame->size()));
server.setContentLength(frame->size());
server.send(200, "image/jpeg");
WiFiClient client = server.client();
frame->writeTo(client);
}
void handleJpg()
{
server.sendHeader("Location", "/cam-hi.jpg");
server.send(302, "", "");
}
void handleMjpeg()//上传mjpeg数据流
{
if (!esp32cam::Camera.changeResolution(hiRes)) {
Serial.println("SET-HI-RES FAIL");
}
Serial.println("STREAM BEGIN");
WiFiClient client = server.client();
int res = esp32cam::Camera.streamMjpeg(client);
if (res <= 0) {
Serial.printf("STREAM ERROR %d\n", res);
return;
}
}
4.1.3 TCP连接下python数据接收接口核心代码(HTTP)
运用requests库建立session对象来加速http连接
imgResp = session.get(url).content
imgNp = np.array(bytearray(imgResp), dtype=np.uint8)
img = cv2.imdecode(imgNp,cv2.IMREAD_COLOR)
测得此方法下获得图像的时间为0.3s,此时系统的平均帧率不足3帧

4.1.4 改进1:对TCP连接下python数据接收接口的速度改进
#从request改用urllib库来进行http连接
imgResp = urllib.request.urlopen(url).read()
imgNp = np.array(bytearray(imgResp), dtype=np.uint8)
img = cv2.imdecode(imgNp,cv2.IMREAD_COLOR)
此方法下图片接收时间减少至0.1s,在同等情况下,每秒帧数上升至3帧左右

4.1.5 改进2:用jpegturbo对python的opencv中解码速度改进
因为800*600的图片有40kb左右,opencv的imdecode函数在处理稍大的文件时表现与jpegturbo有微弱的差距,jpegturbo是一个专门为jpg图片编解码加速的库,但是jpegturbo只能对彩色图片进行解码,而灰度图片是不可以的。
jpeg = TurboJPEG()
imgResp = urllib.request.urlopen(url)
imgNp = np.array(bytearray(imgResp.read()), dtype=np.uint8)
img = jpeg.decode(imgNp)
在加速后,帧率相对更加稳定,大概稳定在4-6帧率,编码时间在输入用时中

4.1.6 改进3:改用ttgo-camera开发板
ttgo-camera也是一款esp32芯片开发的开发板,与esp32cam最大的不同是ttgo-camera板载了更大的psram,这意味着ttgo-camera可以拍摄更大的照片。而在esp32cam上虽然有相机插座,但并不支持更换摄像头,也不支持高清摄像。esp32cam超低的清晰度导致神经网络模型识别率低,受光线等因素影响相当大。
关于这个我测试了很久,我的esp32cam根本不能更换摄像头,更换了摄像头之后会报错SCCB读写错误,这是个类似iic的协议是与摄像头传输数据有关的,只能说无解,遂放弃。
关于psram,我只能推测是影响因素,但是结论是就算是调满esp32cam的属性也很模糊,用arduino开发的时候建议选择esp32 dev module,如果选择安可信esp32cam不能选择psram enable。
ttgo-camera最大的缺点就是贵,不过也比stm32便宜多了,不过这个板子没什么扩展空间了,只有很少的拓展空间,因为上面已经集成了一些东西。
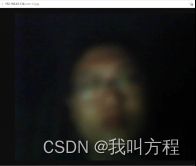
下面不得已放出了我的丑照为大家举例了
esp32cam拍的只能说初具人形 :
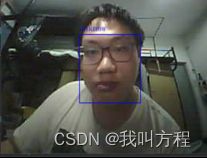
ttgo-camera拍摄的就清晰多了:
核心代码:
#define PWDN_GPIO_NUM -1
#define RESET_GPIO_NUM -1
#define XCLK_GPIO_NUM 4
#define SIOD_GPIO_NUM 18
#define SIOC_GPIO_NUM 23
#define Y9_GPIO_NUM 36
#define Y8_GPIO_NUM 37
#define Y7_GPIO_NUM 38
#define Y6_GPIO_NUM 39
#define Y5_GPIO_NUM 35
#define Y4_GPIO_NUM 26
#define Y3_GPIO_NUM 13
#define Y2_GPIO_NUM 34
#define VSYNC_GPIO_NUM 5
#define HREF_GPIO_NUM 27
#define PCLK_GPIO_NUM 25
4.1.7 改进4:esp32由sta模式改用ap模式
在测试中发现,由于ttgo-camera的拍摄图片清晰度大幅上升,在800*600分辨率下达到40kB大小,在tcp模式下接收图片的时间提升到一秒左右,画面卡顿非常严重,帧率下降到只有0.8帧每秒左右。问题的关键出在网络上,针对网络已成为了主要矛盾。
我对网络进行分析,我一般使用平板电脑的WLAN信号桥功能来构建一个局域网,下面用ap来代称开启WLAN功能的平板电脑。在这个系统中,主机1(pc)发送get请求通过ap转发到主机2(单片机),主机2(单片机)响应请求返回一张图片,这图片由tcp分包传输至ap再转发到主机1,但主机1并不只有一个进程使用网络,还会通过ap与互联网连接,我推测此系统的网络中发生了拥塞,原因可能是当前的路由不是专用设备。所以,我准备使用esp32的ap模式来改良这一情况,而ap模式开启后的表现也从现象上验证了我的猜想,开启ap模式后,由pc连接到esp32开启的网络,此时帧率上升到8左右。但此时的局限性是,pc无法连接互联网。
核心代码:
IPAddress local_IP(192,168,4,2);
IPAddress gateway(192,168,4,9);
IPAddress subnet(255,255,255,0);
WiFi.mode(WIFI_AP);
WiFi.softAPConfig(local_IP, gateway, subnet);//接入点的IP,网关IP,子网掩码
WiFi.softAP(AP_SSID, AP_PASS,3,1);//启动校验式网络
连接平板电脑wifi模式下的运行截图:

连接esp32的网络下的运行截图

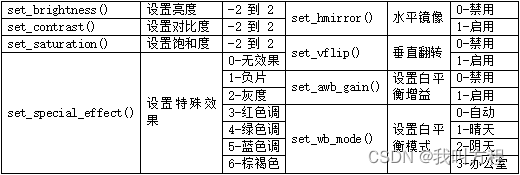
4.1.8 改进5:相机属性设置
通过阅读官方文档和摸索,效果最好最接近真实色彩的是对比度为 2,饱和度为 -2。
4.1.9 改进6:由tcp传输改为用udp传输
网络的问题除了可能存在的无线网络拥塞以外还有tcp与udp的选择上,理论上udp在此场景拥有比tcp更好的性能。
在系统设计上,我对视频的思路是单片机连续摄影不断获取最新帧来拼装成一个视频,在设计上势必一秒内就要进行多次完成get请求,在tcp连接的情况下,pc和单片机要不断进行3次握手建立连接和4次握手释放连接,我认为在视频这种对即时性要求比较高的情况下会造成一定的延时和帧率下降,这可能会导致这个模块以后不能用在更多对即时性有要求的项目中。而udp传输没有这样的问题,在理论层面上,udp是不需要建立连接的。
在实验环境中,两台主机之间距离近,相当于直接相连,中间没有经过任何路由。而在实际环境中,由于现在网络环境都比较好,误码率低,经过平板电脑路由之后,udp传输的效率仍然是明显高于tcp连接的HTTP。在实验中udp传输对性能的提升非常大,将ap模式下tcp连接平均0.06s的传输解码时间压缩到了0.001s
因为改用udp传输,而udp是不会自动分包的,会直接把整个数据报交给下一层传输,因为MTU有限制,经过测试大约在1300字节,这样40000字节的图片基本上就丢失了,所以必须要进行分包,再在pc端接收后组合起来。
设计的udp数据包: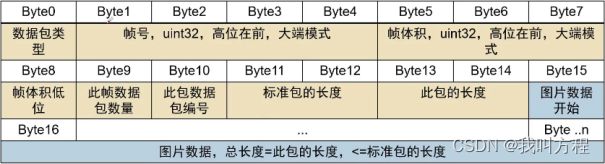
udp分包传输工作模式: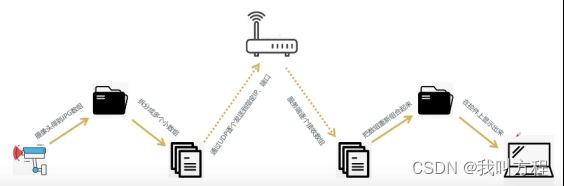
我其实都不算是参考了,基本上是照抄,这个up主太厉害了,我在网上找了很久资料,都没有相关的内容,比如udp分包传输这些内容,以后遇到类似的问题还是大概率会使用这些代码
参考:参考视频地址
udp传输下运行截图 :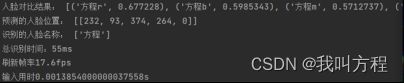
单片机上核心代码
void sendVideoDate(uint8_t* frame, size_t len, size_t frameCount)
{
uint8_t txBuffer[1024] = {0};
size_t frameId = frameCount; //帧号
size_t frameSize = len; //帧大小
int packetCount=0; //包个数
int packetId=1; //包号
int packetLen=1000; //包长
int packetSize=0; //包大小,小于等于包长
if(frameSize==0)
{
Serial.printf("send buffer len=0.\r\n");
return;
}
//计算包个数
packetCount=frameSize/packetLen+((frameSize%packetLen)==0?0:1);
size_t sendOffset=0;
while(sendOffset<frameSize)
{
packetSize=((sendOffset+packetLen)>frameSize)?(frameSize-sendOffset):(packetLen);
//数据包标志
txBuffer[0]=0x12;
//帧号
txBuffer[1]=(uint8_t)(frameId>>24);
txBuffer[2]=(uint8_t)(frameId>>16);
txBuffer[3]=(uint8_t)(frameId>>8);
txBuffer[4]=(uint8_t)(frameId);
//帧大小
txBuffer[5]=(uint8_t)(frameSize>>24);
txBuffer[6]=(uint8_t)(frameSize>>16);
txBuffer[7]=(uint8_t)(frameSize>>8);
txBuffer[8]=(uint8_t)(frameSize);
txBuffer[9]=packetCount; //包个数
txBuffer[10]=packetId; //包号
//包长
txBuffer[11]=(uint8_t)(packetLen>>8);
txBuffer[12]=(uint8_t)(packetLen);
//包大小,小于等于包长
txBuffer[13]=(uint8_t)(packetSize>>8);
txBuffer[14]=(uint8_t)(packetSize);
//图像数据
memcpy(&txBuffer[15], frame+sendOffset, packetSize);
//发送
udp.beginPacket(toAddress,toPort);
udp.write((const uint8_t *)txBuffer, 15+packetSize);
udp.endPacket();
//指向下一位置
sendOffset+=packetSize;
packetId++;
}
}
pc端接收核心代码:
udpbuff, address = usoc.recvfrom(10240) #阻塞接收数据,最多一次接收10240字节
#解析数据
frameId = (udpbuff[1] << 24) + (udpbuff[2] << 16) + (udpbuff[3] << 8) + udpbuff[4] #获取帧号
frameSize = (udpbuff[5] << 24) + (udpbuff[6] << 16) + (udpbuff[7] << 8) + udpbuff[8] #获取帧体积
packetId = udpbuff[10] #获取包号
packetSize = (udpbuff[13] << 8) + udpbuff[14] #获取包体积
if frameIdNow != frameId: #换帧,记录新一帧的数据信息
frameIdNow = frameId #更新帧号
frameSizeNow = frameSize #更新帧体积
packetCount = udpbuff[9] #更新数据包数量
packetLen = (udpbuff[11] << 8) + udpbuff[12] #更新数据包长度
frameSizeOk = 0 #清除当前帧已接收数据量
packetIdNow = 0 #最新已接收数据包号清零
jpgBuff = bytes('', 'utf-8') #清空图片数据缓存
#复制至缓冲区,并只接收安全范围内的数据包
if (packetId <= packetCount) and (packetId > packetIdNow): #新数据包包号不超过总数据包数量,且包号刚好比前一包多1
if packetSize == (len(udpbuff)-15): #数据包减去包头等于包体积
if (packetSize == packetLen) or (packetId == packetCount): #标准包或最后一包
jpgBuff = jpgBuff + udpbuff[15:] #拼接数据包
frameSizeOk = frameSizeOk + len(udpbuff) - 15 #帧数据总量累加
if frameSizeNow == frameSizeOk: #当前帧接收完成
nparr = np.frombuffer(jpgBuff, dtype=np.uint8) #将图片数组转为numpy数组
image = cv2.imdecode(nparr, cv2.IMREAD_COLOR) #解码图片
4.2 ESP32AsyncWebServer的web
4.2.1web模块简介
使用ESP32提供的asyncwebServer异步web服务器库进行开发,与同步webserver不同的是,webserver只能同时处理一个连接,而基于freertos的asyncwebserver可以通过封装的任务切换同时处理多个连接,更符合web服务器的一个现实需求。
该模块分为两个部分,包括web部分和单片机上一块程序为显示一些交互内容的TFT彩屏构成。Web部分包含有html+css+JavaScript写的网页,并通过ajax的XMLHttpRequest实现前后端的数据交互,当我点击既定按钮,由ajax将发送一个携带数据请求到web服务器的一个端口,在回调函数中完成诸如数据更新的操作。彩屏可以显示一些互动信息,包括文字图片,该服务器地址等。
4.2.2 web实现关键代码
其实代码有点问题,但是当时做的那个课设没时间改了,做的很粗糙,有逻辑错误,但是运行肯定没问题。
const char index_html[] PROGMEM = R"rawliteral(
<!DOCTYPE HTML><html>
<head>
<title>疫情防控居家隔离系统</title>
<meta charset="utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<style>
html {font-family: Arial; display: inline-block; text-align: center;}
h2 {font-size: 2.6rem;}
body {max-width: 600px; margin:0px auto; padding-bottom: 10px;}
.switch {position: relative; display: inline-block; width: 120px; height: 68px}
.switch input {display: none}
.slider {position: absolute; top: 0; left: 0; right: 0; bottom: 0; background-color: #c
cc; border-radius: 34px}
.slider:before {position: absolute; content: ""; height: 52px; width: 52px; left: 8px; b
ottom: 8px; background-color: #fff; -webkit-transition: .4s; transition: .4s; border-radius:
68px}
input:checked+.slider {background-color: #2196F3}
input:checked+.slider:before {-webkit-transform: translateX(52px); -ms-transform: tra
nslateX(52px); transform: translateX(52px)}
</style>
</head>
<body>
<h2>疫情防控居家隔离系统</h2>
<button onclick="logoutButton()">退出登录</button>
<p>成员 1 - 方程 - 状态 <span id="state1">%STATE1%</span></p>
%BUTTONPLACEHOLDER1%
<p>成员 1 - 何诚 - 状态 <span id="state2">%STATE2%</span></p>
%BUTTONPLACEHOLDER2%
<script>function toggleCheckbox1(element) {
var xhr = new XMLHttpRequest();
if(element.checked){
xhr.open("GET", "/update?state1=1", true);
document.getElementById("state1").innerHTML = "已做核酸";
}
else {
xhr.open("GET", "/update?state1=0", true);
document.getElementById("state1").innerHTML = "未做核酸";
}
xhr.send();
}
function toggleCheckbox2(element) {
var xhr = new XMLHttpRequest();
if(element.checked){
xhr.open("GET", "/update?state2=1", true);
document.getElementById("state2").innerHTML = "已做核酸";
}
else {
xhr.open("GET", "/update?state2=0", true);
document.getElementById("state2").innerHTML = "未做核酸";
}
xhr.send();
}
function logoutButton() {
var xhr = new XMLHttpRequest();
xhr.open("GET", "/logout", true);
xhr.send();
setTimeout(function(){ window.open("/logged-out","_self"); }, 1000);
}
</script>
</body>
</html>
)rawliteral";
const char logout_html[] PROGMEM = R"rawliteral(
<!DOCTYPE HTML><html>
<head>
<meta name="viewport" content="width=device-width, initial-scale=1">
</head>
<body>
<p>Logged out or <a href="/">return to homepage</a>.</p>
<p><strong>Note:</strong> close all web browser tabs to complete the logout pro
cess.</p>
</body>
</html>
)rawliteral";
//在调用此回调函数时将占用符对应位置的内容替换
String processor(const String& var){
if(var == "BUTTONPLACEHOLDER1"){
String buttons ="";
String outputStateValue = outputState();
String no1="state1";
buttons+= "<p><label class=\"switch\"><input type=\"checkbox\" onclick=\"toggl
eCheckbox1(this)\" id=\"output\" " + outputStateValue + "><span class=\"slider\"></sp
an></label></p>";
return buttons;
}
if(var == "BUTTONPLACEHOLDER2"){
String buttons ="";
String outputStateValue = outputState();
String no2="state2";
buttons+= "<p><label class=\"switch\"><input type=\"checkbox\" onclick=\"toggl
eCheckbox2(this)\" id=\"output\" " + outputStateValue + "><span class=\"slider\"></sp
an></label></p>";
return buttons;
}
if (var == "STATE1"){
if(!flag1){
return "未做核酸";
}
else {
return "已做核酸";
}
}
if (var == "STATE2"){
if(!flag2){
return "未做核酸";
}
else {
return "已做核酸";
}
}
return String();
}
String outputState(){
if(key== "fc"){//添加判断条件
return "checked/";
}
else {
return "";
}
return "";
}
前端页面运行截图

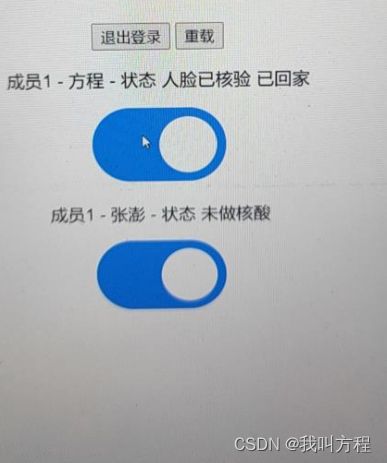
4.3 ESP32舵机云台控制
参考博客:文章地址链接
4.3.1 舵机云台人脸追踪设计思路
使用OpenCV的人脸检测的API获取人脸在画面中的位置,根据人脸位置距离画面中心的x轴与y轴的偏移量(offset) ,通过PID中的P比例控制控制二自由度云台上臂与下臂的旋转角度,将角度信息通过串口通信发送给Arduino单片机解析执行对应的操作,从而使得人脸尽可能处在画面的正中间。
4.3.2 控制原理
舵机角度获取如下:Offset = Real - Target(偏移量 = 实际值 - 目标值),y_offset = cy - height/2(Y轴的偏移量 = 人脸矩形中心Y轴坐标 - 整个画面高度/2),delta_degree2 = Kp2 * y_offset(上臂舵机的角度增量 = 比例系数2 × Y轴偏移量,比例系数越大,步幅越大,失稳的可能性越大),new_degree2 = old_degree2 + delta_degree2(新的舵机角度 = 旧的舵机角度 + 角度增量)。
舵机控制原理如下:舵机的伺服系统由可变宽度的脉冲来进行控制,控制线是用来传送脉冲的。脉冲的参数有最小值,最大值,和频率。一般而言,舵机的基准信号都是周期为20ms,宽度为1.5ms。ESP32通过输出PWM波调节脉宽来控制舵机。
4.3.3 控制细节
如果舵机数据更新过快,会导致舵机角度变化不断积分,最终舵机会失控。在现在简单的控制算法下我设计的做法是可以对舵机角度进行平均值滤波,取一段时间内的平均角度值为发送的角度,这样做的缺点是这样会导致实时性降低。
4.3.4 esp32控制舵机核心代码
int calculatePWM(int degree)//处理角度
{ //0-180 度
//20ms 周期,高电平 0.5-2.5ms,对应 0-180 度角度
const float deadZone = 6.4;//对应 0.5ms(0.5ms/(20ms/256))
const float max = 32;//对应 2.5ms
if (degree < 0)
degree = 0;
if (degree > 180)
degree = 180;
return (int)(((max - deadZone) / 180) * degree + deadZone);
}
void handleArg(AsyncWebServerRequest *request) //接收角度数据的回调函数
{
posx=request->arg("posx");
posy=request->arg("posy");
key=request->arg("key");
x=posx.toInt();
y=posy.toInt();
ledcWrite(channel, calculatePWM(y)); // 输出 PWM
delay(400);
ledcWrite(channel1, calculatePWM(x)); // 输出 PWM
delay(400);
x=90;
y=90;
request->send(200,"text/plain","ok");
}
4.3.5 获取舵机角度的pc端程序核心代码
mtcnn识别人脸后可以获取人脸的坐标
def dodegree(x1,y1,x2,y2):
global last_btm_degree
global last_top_degree
offset_dead_block=0.1
xm=(x1+x2)/2
ym=(y1+y2)/2
x_offset=(xm/320-0.5)*2
y_offset=(ym/240-0.5)*2
if abs(x_offset) < offset_dead_block:
x_offset = 0
if abs(y_offset) < offset_dead_block:
y_offset = 0
kp1=5
kp2=5
delta_degreex = kp1 * x_offset
delta_degreey = y_offset * kp2
next_btm_degree = last_btm_degree + delta_degreex
next_top_degree = last_top_degree + delta_degreey
if next_btm_degree < 0:
next_btm_degree = 0
elif next_btm_degree > 180:
next_btm_degree = 180
if next_top_degree < 0:
next_top_degree = 0
elif next_top_degree > 180:
next_top_degree = 180
return int(next_btm_degree),int(next_top_degree)
4.3.6 舵机云台应用其他思路
可以实现一个由web控制的舵机云台结合摄像头模块,因为udp是可以一对多的,在理论上可以形成一个可以应用人工智能技术低成本监控系统等。
云台运行图片:

五、结论
最终得出结论,esp32系列单片机的视频传输在esp32的ap模式下应用udp分包模式进行传输,在python中运用jpegturbo编码的方法组合可以在系统中实现最好的性能。而在单片机的配置的选择方面,配置psram的开发板可以提供更好的画面,最适配的摄像头是ov2640。在实验中还发现给芯片配置增益天线后,单片机在网络中的表现更加稳定。
esp32cam:

ttgo-camera plus:

运行截图:
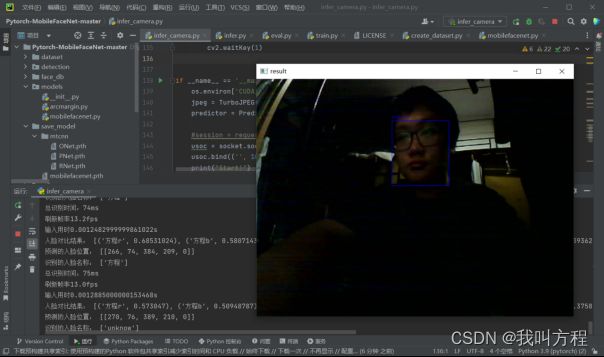
六、代码
6.1 pytorch的人脸检测模型
夜雨飘零1这个博主非常牛逼,做的东西也非常多,模型可以去他的博客下载。也推荐大家关注这个博主,这个博主在paddlepaddle方面也有特别多文章,特别厉害,真的超级强。
参考博客1
参考博客2
参考博客3
6.2 UDP下改造人脸识别模型接口程序
import argparse
import functools
import os
import time
import urllib.request
#import requests
import cv2
import numpy as np
import torch
import socket
from PIL import ImageDraw, ImageFont, Image
from detection.face_detect import MTCNN
from utils.utils import add_arguments, print_arguments
from turbojpeg import TurboJPEG, TJPF_GRAY, TJSAMP_GRAY, TJFLAG_PROGRESSIVE, TJFLAG_FASTUPSAMPLE, TJFLAG_FASTDCT
parser = argparse.ArgumentParser(description=__doc__)
add_arg = functools.partial(add_arguments, argparser=parser)
add_arg('camera_id', int, 0, '使用的相机ID')
add_arg('face_db_path', str, 'face_db', '人脸库路径')
add_arg('threshold', float, 0.6, '判断相识度的阈值')
add_arg('mobilefacenet_model_path', str, 'save_model/mobilefacenet.pth', 'MobileFaceNet预测模型的路径')
add_arg('mtcnn_model_path', str, 'save_model/mtcnn', 'MTCNN预测模型的路径')
args = parser.parse_args()
print_arguments(args)
def classifyname(name):
name = name[0:2]
return name
class Predictor:
def __init__(self, mtcnn_model_path, mobilefacenet_model_path, face_db_path, threshold=0.7):
self.threshold = threshold
self.mtcnn = MTCNN(model_path=mtcnn_model_path)
self.device = torch.device("cuda")
# 加载模型
self.model = torch.jit.load(mobilefacenet_model_path)
self.model.to(self.device)
self.model.eval()
self.faces_db = self.load_face_db(face_db_path)
def load_face_db(self, face_db_path):
faces_db = {}
for path in os.listdir(face_db_path):
name = os.path.basename(path).split('.')[0]
image_path = os.path.join(face_db_path, path)
img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), -1)
imgs, _ = self.mtcnn.infer_image(img)
if imgs is None or len(imgs) > 1:
print('人脸库中的 %s 图片包含不是1张人脸,自动跳过该图片' % image_path)
continue
imgs = self.process(imgs)
feature = self.infer(imgs[0])
faces_db[name] = feature[0][0]
return faces_db
@staticmethod
def process(imgs):
imgs1 = []
for img in imgs:
img = img.transpose((2, 0, 1))
img = (img - 127.5) / 127.5
imgs1.append(img)
return imgs1
# 预测图片
def infer(self, imgs):
assert len(imgs.shape) == 3 or len(imgs.shape) == 4
if len(imgs.shape) == 3:
imgs = imgs[np.newaxis, :]
features = []
for i in range(imgs.shape[0]):
img = imgs[i][np.newaxis, :]
img = torch.tensor(img, dtype=torch.float32, device=self.device)
# 执行预测
feature = self.model(img)
feature = feature.detach().cpu().numpy()
features.append(feature)
return features
def recognition(self, img):
imgs, boxes = self.mtcnn.infer_image(img)
if imgs is None:
return None, None
imgs = self.process(imgs)
imgs = np.array(imgs, dtype='float32')
features = self.infer(imgs)
names = []
probs = []
for i in range(len(features)):
feature = features[i][0]
results_dict = {}
for name in self.faces_db.keys():
feature1 = self.faces_db[name]
prob = np.dot(feature, feature1) / (np.linalg.norm(feature) * np.linalg.norm(feature1))
results_dict[name] = prob
results = sorted(results_dict.items(), key=lambda d: d[1], reverse=True)
print('人脸对比结果:', results)
result = results[0]
prob = float(result[1])
probs.append(prob)
if prob > self.threshold:
name = result[0]
name = classifyname(name)
names.append(name)
else:
names.append('unknow')
return boxes, names
def add_text(self, img, text, left, top, color=(0, 0, 0), size=20):
if isinstance(img, np.ndarray):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
font = ImageFont.truetype('simfang.ttf', size)
draw.text((left, top), text, color, font=font)
return cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
# 画出人脸框和关键点
def draw_face(self, img, boxes_c, names):
if boxes_c is not None:
for i in range(boxes_c.shape[0]):
bbox = boxes_c[i, :4]
name = names[i]
#if name == 'unknow':
corpbbox = [int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3])]
# 画人脸框
cv2.rectangle(img, (corpbbox[0], corpbbox[1]),
(corpbbox[2], corpbbox[3]), (255, 0, 0), 1)
# 判别为人脸的名字
img = self.add_text(img, name, corpbbox[0], corpbbox[1] - 15, color=(0, 0, 255), size=12)
cv2.imshow("result", img)
cv2.waitKey(1)
if __name__ == '__main__':
jpeg = TurboJPEG()
predictor = Predictor(args.mtcnn_model_path, args.mobilefacenet_model_path, args.face_db_path,
threshold=args.threshold)
#session = requests.Session()
usoc = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) # 建一个UDP socket
usoc.bind(('', 10000)) # 监听端口号
print("Start!")
frameIdNow = 0 # 当前帧帧号
frameSizeNow = 0 # 当前接收到的帧体积
packetIdNow = 0 # 最新已接收的数据包号
packetCount = 0 # 当前帧包的数量
packetLen = 0 # 标准数据包大小
frameSizeOk = 0 # 当前帧已接收数据量
jpgBuff = bytes('', 'utf-8') # 图片数据缓存
while True:
st = time.perf_counter()
udpbuff, address = usoc.recvfrom(10240) # 阻塞接收数据,最多一次接收10240字节
# 解析数据
frameId = (udpbuff[1] << 24) + (udpbuff[2] << 16) + (udpbuff[3] << 8) + udpbuff[4] # 获取帧号
frameSize = (udpbuff[5] << 24) + (udpbuff[6] << 16) + (udpbuff[7] << 8) + udpbuff[8] # 获取帧体积
packetId = udpbuff[10] # 获取包号
packetSize = (udpbuff[13] << 8) + udpbuff[14] # 获取包体积
if frameIdNow != frameId: # 换帧,记录新一帧的数据信息
frameIdNow = frameId # 更新帧号
frameSizeNow = frameSize # 更新帧体积
packetCount = udpbuff[9] # 更新数据包数量
packetLen = (udpbuff[11] << 8) + udpbuff[12] # 更新数据包长度
frameSizeOk = 0 # 清除当前帧已接收数据量
packetIdNow = 0 # 最新已接收数据包号清零
jpgBuff = bytes('', 'utf-8') # 清空图片数据缓存
# 复制至缓冲区,并只接收安全范围内的数据包
if (packetId <= packetCount) and (packetId > packetIdNow): # 新数据包包号不超过总数据包数量,且包号刚好比前一包多1
if packetSize == (len(udpbuff) - 15): # 数据包减去包头等于包体积
if (packetSize == packetLen) or (packetId == packetCount): # 标准包或最后一包
jpgBuff = jpgBuff + udpbuff[15:] # 拼接数据包
frameSizeOk = frameSizeOk + len(udpbuff) - 15 # 帧数据总量累加
if frameSizeNow == frameSizeOk: # 当前帧接收完成
nparr = np.frombuffer(jpgBuff, dtype=np.uint8) # 将图片数组转为numpy数组
img = jpeg.decode(nparr) # 解码图片
print('输入用时' +str(time.perf_counter() - st)+ 's')
if True:
start = time.time()
boxes, names = predictor.recognition(img)
if boxes is not None:
predictor.draw_face(img, boxes, names)
print('预测的人脸位置:', boxes.astype('int32').tolist())
print('识别的人脸名称:', names)
print('总识别时间:%dms' % int((time.time() - start) * 1000))
print('刷新帧率' + str((1 / (time.perf_counter() - st)).__round__(1)) + 'fps')
else:
cv2.imshow("result", img)
cv2.waitKey(1)
6.3 UDP TTGO-camera代码
要使用esp32cam把相机引脚换了就行,select_pins.h就是写的相机引脚
#include "Arduino.h"
#include "esp_camera.h"
#include "esp_timer.h"
#include 6.4 TCP web服务器
不得不承认里面是有问题的,但是暂时没心思改了
#include /update?state=
server.on("/update", HTTP_GET, [] (AsyncWebServerRequest *request) {
if(!request->authenticate(http_username, http_password))
return request->requestAuthentication();
String inputMessage1;
String inputMessage2;
String inputParam;
// GET input1 value on /update?state=
if (request->hasParam(PARAM_INPUT_1)) {
inputMessage1 = request->getParam(PARAM_INPUT_1)->value();//PARAM_INPUT_
1 是"state"
inputMessage2 = request->getParam(PARAM_INPUT_2)->value();
}
else {
inputMessage1 = "No message sent";
inputMessage2 = "No message sent";
inputParam = "none";
}
request->send(200, "text/plain", "OK");
});
server.on("/updatepos",HTTP_GET,handleArg);
// 开启 Web 服务
server.begin();
}
void loop() {
}
里面有一块是画屏幕的代码,函数是showlxy(),用的库是TFT_eSPI,之前桌面时钟的博客讲过这个库怎么用。用这个实现了,可以接收pc上识别的结果显示在屏幕上,但是只仅仅只是实现了而已。


6.5 TCP人脸识别模型接口程序
其实就只有在main里面与udp有区别
import argparse
import functools
import os
import time
import urllib.request
#import requests
import cv2
import numpy as np
import torch
from PIL import ImageDraw, ImageFont, Image
from detection.face_detect import MTCNN
from utils.utils import add_arguments, print_arguments
from turbojpeg import TurboJPEG, TJPF_GRAY, TJSAMP_GRAY, TJFLAG_PROGRESSIVE, TJFLAG_FASTUPSAMPLE, TJFLAG_FASTDCT
url='http://192.168.4.2/cam-lo.jpg'
parser = argparse.ArgumentParser(description=__doc__)
add_arg = functools.partial(add_arguments, argparser=parser)
add_arg('camera_id', int, 0, '使用的相机ID')
add_arg('face_db_path', str, 'face_db', '人脸库路径')
add_arg('threshold', float, 0.6, '判断相识度的阈值')
add_arg('mobilefacenet_model_path', str, 'save_model/mobilefacenet.pth', 'MobileFaceNet预测模型的路径')
add_arg('mtcnn_model_path', str, 'save_model/mtcnn', 'MTCNN预测模型的路径')
args = parser.parse_args()
print_arguments(args)
def classifyname(name):
name = name[0:2]
return name
class Predictor:
def __init__(self, mtcnn_model_path, mobilefacenet_model_path, face_db_path, threshold=0.7):
self.threshold = threshold
self.mtcnn = MTCNN(model_path=mtcnn_model_path)
self.device = torch.device("cuda")
# 加载模型
self.model = torch.jit.load(mobilefacenet_model_path)
self.model.to(self.device)
self.model.eval()
self.faces_db = self.load_face_db(face_db_path)
def load_face_db(self, face_db_path):
faces_db = {}
for path in os.listdir(face_db_path):
name = os.path.basename(path).split('.')[0]
image_path = os.path.join(face_db_path, path)
img = cv2.imdecode(np.fromfile(image_path, dtype=np.uint8), -1)
imgs, _ = self.mtcnn.infer_image(img)
if imgs is None or len(imgs) > 1:
print('人脸库中的 %s 图片包含不是1张人脸,自动跳过该图片' % image_path)
continue
imgs = self.process(imgs)
feature = self.infer(imgs[0])
faces_db[name] = feature[0][0]
return faces_db
@staticmethod
def process(imgs):
imgs1 = []
for img in imgs:
img = img.transpose((2, 0, 1))
img = (img - 127.5) / 127.5
imgs1.append(img)
return imgs1
# 预测图片
def infer(self, imgs):
assert len(imgs.shape) == 3 or len(imgs.shape) == 4
if len(imgs.shape) == 3:
imgs = imgs[np.newaxis, :]
features = []
for i in range(imgs.shape[0]):
img = imgs[i][np.newaxis, :]
img = torch.tensor(img, dtype=torch.float32, device=self.device)
# 执行预测
feature = self.model(img)
feature = feature.detach().cpu().numpy()
features.append(feature)
return features
def recognition(self, img):
imgs, boxes = self.mtcnn.infer_image(img)
if imgs is None:
return None, None
imgs = self.process(imgs)
imgs = np.array(imgs, dtype='float32')
features = self.infer(imgs)
names = []
probs = []
for i in range(len(features)):
feature = features[i][0]
results_dict = {}
for name in self.faces_db.keys():
feature1 = self.faces_db[name]
prob = np.dot(feature, feature1) / (np.linalg.norm(feature) * np.linalg.norm(feature1))
results_dict[name] = prob
results = sorted(results_dict.items(), key=lambda d: d[1], reverse=True)
print('人脸对比结果:', results)
result = results[0]
prob = float(result[1])
probs.append(prob)
if prob > self.threshold:
name = result[0]
name = classifyname(name)
names.append(name)
else:
names.append('unknow')
return boxes, names
def add_text(self, img, text, left, top, color=(0, 0, 0), size=20):
if isinstance(img, np.ndarray):
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
font = ImageFont.truetype('simfang.ttf', size)
draw.text((left, top), text, color, font=font)
return cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
# 画出人脸框和关键点
def draw_face(self, img, boxes_c, names):
if boxes_c is not None:
for i in range(boxes_c.shape[0]):
bbox = boxes_c[i, :4]
name = names[i]
#if name == 'unknow':
corpbbox = [int(bbox[0]), int(bbox[1]), int(bbox[2]), int(bbox[3])]
# 画人脸框
cv2.rectangle(img, (corpbbox[0], corpbbox[1]),
(corpbbox[2], corpbbox[3]), (255, 0, 0), 1)
# 判别为人脸的名字
img = self.add_text(img, name, corpbbox[0], corpbbox[1] - 15, color=(0, 0, 255), size=12)
cv2.imshow("result", img)
cv2.waitKey(1)
if __name__ == '__main__':
jpeg = TurboJPEG()
predictor = Predictor(args.mtcnn_model_path, args.mobilefacenet_model_path, args.face_db_path,
threshold=args.threshold)
#session = requests.Session()
while True:
st = time.perf_counter()
imgResp = urllib.request.urlopen(url).read()
#imgResp = session.get(url).content
imgNp = np.array(bytearray(imgResp), dtype=np.uint8)
img = jpeg.decode(imgNp)
print('输入用时' +str(time.perf_counter() - st)+ 's')
if True:
start = time.time()
boxes, names = predictor.recognition(img)
if boxes is not None:
predictor.draw_face(img, boxes, names)
print('预测的人脸位置:', boxes.astype('int32').tolist())
print('识别的人脸名称:', names)
print('总识别时间:%dms' % int((time.time() - start) * 1000))
print('刷新帧率' + str((1 / (time.perf_counter() - st)).__round__(1)) + 'fps')
else:
cv2.imshow("result", img)
cv2.waitKey(1)
6.6 TCP esp32cam图片传输代码
#include 6.6 esp32控制舵机代码
#include