python内存性能分析
一些情况下,预期之外的内存占用过多时,需要分析代码哪个位置消耗内存,从而针对性的优化代码,本文介绍一些方便的工具可用于内存分析。
1. memory_profiler
memory_profiler 可逐行分析内存占用情况,提供最直接明了的信息。
调用方式
from memory_profiler import profile
@profile(precision=4, stream=open('mem.log','w+')) # 也可不使用参数
def func(x):
# process
stream:设置输出到指定文件,不指定则打印到标准输出;
结果说明
Line # Mem usage Increment Line Contents
==============================================
3 @profile
4 5.97 MB 0.00 MB def my_func():
5 13.61 MB 7.64 MB a = [1] * (10 ** 6)
6 166.20 MB 152.59 MB b = [2] * (2 * 10 ** 7)
7 13.61 MB -152.59 MB del b
8 13.61 MB 0.00 MB return a
Line :代码在脚本中的行号;
Mem usage:该行执行后的内存占用;
Increment:该行执行产生的内存增长;
Line Contents:具体代码;
其他用法
mprof 可输出程序随时间变化的内存使用变化,并能可视化。此时并非按行计算内存消耗,而是程序整体内存使用情况。
函数前使用profile 装饰器后,mprof可输出对应函数在相应运行时间段的内存使用。
mprof run <script> # 输出文件到当前目录
mprof plot #可视化
# 汇总所有子进程和父进程的内存使用
mprof run --include-children <script>
# 独立于主进程,追踪每个子进程的内存使用
mprof run --multiprocess <script>

2. Pympler
Pympler可用于检测,监控和分析python对象的内存占用情况。主要包括3个模块:asizeof 可准确获得python对象的大小;muppy用于在线监测Python应用程序;Class Tracker提供对所选Python对象生命周期的分析。
对象内存占用
sys.getsizeof 只能获得默认对象(str,list,dict等)的大小,对于复杂对象不适用。而asizeof能准确检测对象大小
>>> from pympler import asizeof
>>> obj = [1, 2, (3, 4), 'text']
>>> asizeof.asizeof(obj)
176
>>> print(asizeof.asized(obj, detail=1).format())
[1, 2, (3, 4), 'text'] size=176 flat=48
(3, 4) size=64 flat=32
'text' size=32 flat=32
1 size=16 flat=16
2 size=16 flat=16
总体内存占用追踪
muppy可以检测两个参考点之间是否发生对象的内存泄露。有两种方式,一种先实例化 SummaryTracker,然后在任意位置调用print_diff方法,即输出当前位置与初始实例化位置之间的python对象差异。另一种分别在两个位置调用summary.summarize,比较不同后输出。但此结果似乎只能显示对象类型,一般没有对象名称,如果不是非常具体也难以确定具体是哪个对象占用内存较多。
>>> from pympler import tracker,muppy,summary
>>> tr = tracker.SummaryTracker()
>>> function_without_side_effects()
>>> tr.print_diff()
types | # objects | total size
======= | =========== | ============
dict | 1 | 280 B
list | 1 | 192 B
>>> all_objects = muppy.get_objects()
>>> sum1 = summary.summarize(all_objects)
>>> summary.print_(sum1)
types | # objects | total size
============================ | =========== | ============
dict | 546 | 953.30 KB
str | 8270 | 616.46 KB
list | 127 | 529.44 KB
wrapper_descriptor | 508 | 39.69 KB
builtin_function_or_method | 515 | 36.21 KB
<class 'abc.ABCMeta | 16 | 14.12 KB
>>> sum2 = summary.summarize(muppy.get_objects())
>>> diff = summary.get_diff(sum1, sum2)
>>> summary.print_(diff)
types | # objects | total size
=============================== | =========== | ============
list | 1097 | 1.07 MB
str | 1105 | 68.21 KB
dict | 14 | 21.08 KB
wrapper_descriptor | 215 | 16.80 KB
frame (codename: get_objects) | 1 | 488 B
builtin_function_or_method | 6 | 432 B
对象内存追踪
追踪某个对象,在两个参考点建立快照,查看在这之间的内存使用。
>>> from pympler import classtracker
>>> tr = classtracker.ClassTracker()
>>> tr.track_class(Document)
>>> tr.create_snapshot()
>>> create_documents()
>>> tr.create_snapshot()
>>> tr.stats.print_summary()
3. objgraph
objgraph 能够可视化的查看python对象的引用关系,对分析内存泄露有帮助,虽然在大多数时候也没什么用。
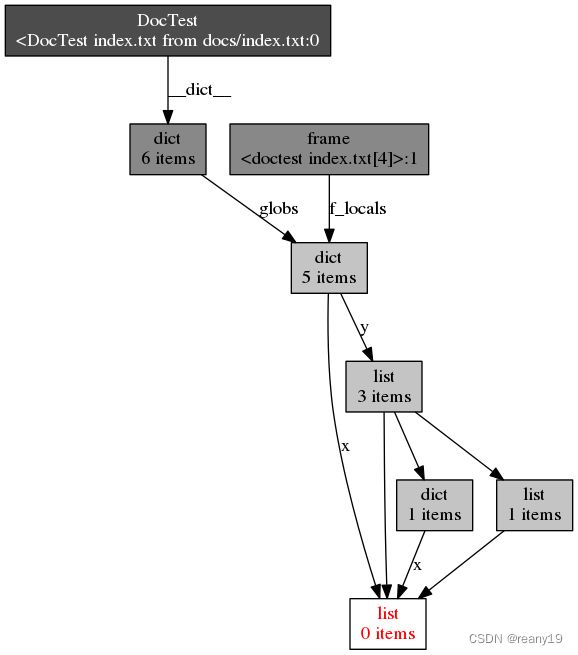
4. tracemalloc
tracemalloc模块是跟踪python分配的内存块的调试工具。它提供以下信息:
- 回溯对象的分配位置
- 每个文件名和每个行号的已分配内存块的统计信息:已分配内存块的总大小、数量和平均大小
- 计算两个快照之间的差异以检测内存泄漏
显示内存分配最多的10个文件
tracemalloc.start()
# ... run your application ...
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')
for stat in top_stats[:10]:
print(stat)
截取2个快照比较差异
tracemalloc.start()
# ... start your application ...
snapshot1 = tracemalloc.take_snapshot()
# ... call the function leaking memory ...
snapshot2 = tracemalloc.take_snapshot()
top_stats = snapshot2.compare_to(snapshot1, 'lineno')
for stat in top_stats[:10]:
print(stat)
获取内存块回溯
# Store 25 frames
tracemalloc.start(25)
# ... run your application ...
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('traceback')
# pick the biggest memory block
stat = top_stats[0]
for line in stat.traceback.format():
print(line)
记录所有追踪内存块的当前大小和峰值
tracemalloc.start()
# Example code: compute a sum with a large temporary list
large_sum = sum(list(range(100000)))
first_size, first_peak = tracemalloc.get_traced_memory()
#first_size=664, first_peak=3592984
5. pyrasite
pyrasite没有过多使用。如果以上都不能定位问题,可以继续尝试。
6. gc垃圾回收
Python使用引用计数方法管理内存,一个python对象被引用时计数就+1,取消引用则-1。当引用计数为0时,该对象就自动地被回收。但是由于一些稍复杂的原因,执行一次gc.collect()开销较大,要减少使用。
总结
之前遇到一些内存问题,把上面的大多数用了个遍,发现除了memory_profiler 能提供最直接的信息外,其他的并没有特殊的帮助。当然具体问题具体分析。