浅谈sklearn之决策树(分类树)
sklearn之决策树(分类树)
分类树sklearn.tree.DecisionTreeClassifier()
sklearn.tree.DecisionTreeClassifier ( *, criteria = ‘gini’, splitter = ‘best’, max_depth = None, min_samples_split = 2, min_samples_leaf = 1, min_weight_fraction_leaf = 0.0, max_features = None, random_state = None, max_leaf_nodes = None, min_impurity_decrease = 0.0,class_weight =无, ccp_alpha = 0.0 )
废话少说,上实战!
# 导入分类树
from sklearn.tree import DecisionTreeClassifier
# 导入sklearn数据集库中的红酒数据集
from sklearn.datasets import load_wine
# 导入训练集测试集划分函数
from sklearn.model_selection import train_test_split
# 加载红酒数据
wine = load_wine()
(这里详解一下数据集。知道数据集长啥样的,可以选择性略过)
# 看一下这一数据集类的属性
print(dir(wine))
'''
['DESCR', 'data', 'feature_names', 'frame', 'target', 'target_names']
'''
# 看一下红酒数据集的特征
print(wine.feature_names)
# 从结果来看共13个特征
print(len(wine.feature_names))
'''
['alcohol', 'malic_acid', 'ash', 'alcalinity_of_ash', 'magnesium', 'total_phenols', 'flavanoids', 'nonflavanoid_phenols', 'proanthocyanins', 'color_intensity', 'hue', 'od280/od315_of_diluted_wines', 'proline']
13
'''
# wine.data 就是红酒的真实数据
print(wine.data)
# 从结果来看,这一数据集内有178个红酒样本,每个样本由13个特征数值组成
print(wine.data.shape)
'''
[[1.423e+01 1.710e+00 2.430e+00 ... 1.040e+00 3.920e+00 1.065e+03]
[1.320e+01 1.780e+00 2.140e+00 ... 1.050e+00 3.400e+00 1.050e+03]
[1.316e+01 2.360e+00 2.670e+00 ... 1.030e+00 3.170e+00 1.185e+03]
...
[1.327e+01 4.280e+00 2.260e+00 ... 5.900e-01 1.560e+00 8.350e+02]
[1.317e+01 2.590e+00 2.370e+00 ... 6.000e-01 1.620e+00 8.400e+02]
[1.413e+01 4.100e+00 2.740e+00 ... 6.100e-01 1.600e+00 5.600e+02]]
(178, 13)
'''
# 看一下这个红酒数据集共分几类
print(wine.target_names)
'''
['class_0' 'class_1' 'class_2']
'''
# 看一下每个红酒样本对应的分类
print(wine.target)
print(wine.target.shape)
'''
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
(178,)
'''
import pandas as pd
# 总览一下
print(pd.concat([pd.DataFrame(wine.data),pd.DataFrame(wine.target)],axis=1))
'''
0 1 2 3 4 5 ... 8 9 10 11 12 0
0 14.23 1.71 2.43 15.6 127.0 2.80 ... 2.29 5.64 1.04 3.92 1065.0 0
1 13.20 1.78 2.14 11.2 100.0 2.65 ... 1.28 4.38 1.05 3.40 1050.0 0
2 13.16 2.36 2.67 18.6 101.0 2.80 ... 2.81 5.68 1.03 3.17 1185.0 0
3 14.37 1.95 2.50 16.8 113.0 3.85 ... 2.18 7.80 0.86 3.45 1480.0 0
4 13.24 2.59 2.87 21.0 118.0 2.80 ... 1.82 4.32 1.04 2.93 735.0 0
.. ... ... ... ... ... ... ... ... ... ... ... ... ..
173 13.71 5.65 2.45 20.5 95.0 1.68 ... 1.06 7.70 0.64 1.74 740.0 2
174 13.40 3.91 2.48 23.0 102.0 1.80 ... 1.41 7.30 0.70 1.56 750.0 2
175 13.27 4.28 2.26 20.0 120.0 1.59 ... 1.35 10.20 0.59 1.56 835.0 2
176 13.17 2.59 2.37 20.0 120.0 1.65 ... 1.46 9.30 0.60 1.62 840.0 2
177 14.13 4.10 2.74 24.5 96.0 2.05 ... 1.35 9.20 0.61 1.60 560.0 2
[178 rows x 14 columns]
'''
废话少说,接着来!
# 测试集为总样本量的30%进行随机划分
x_train,x_test,y_train,y_test = train_test_split(wine.data,wine.target,test_size=0.3)
*注意:这里x_train,x_test,y_train,y_test顺序不能乱,
否则结果可能会出错。
这里x代表红酒样本,y代表该红酒样本对应哪一类,
train就是训练用的数据,test就是测试用的数据。
# 实例化分类树
dtc = tree.DecisionTreeClassifier(
# criterion="entropy"
# ,random_state=30
# ,splitter="best"
# ,max_depth=3
# ,min_samples_leaf=10
# ,min_samples_split=60
)
# 训练分类树
dtc = dtc.fit(x_train,y_train)
# 训练后的分类树在测试集上的得分
score = dtc.score(x_test,y_test)
print(score)
'''
0.9074074074074074
'''
可视化一下(不是重点,可以略过)
from sklearn import tree
import graphviz
feature_names = wine.feature_names
class_names = wine.target_names
dot_data = tree.export_graphviz(
dtc
# 每个小框框的第一行就是根据这个特征序列来命名
,feature_names=feature_names
# 每个小框框的最后一行就是根据这个类别序列来命名
,class_names=class_names
# 当参数为True时,每个小框框的主题颜色代表类别,而深浅则代表纯度
,filled=True
# 当参数为True时,每个小框框四周的角将会变圆
,rounded=True
)
graph = graphviz.Source(dot_data)
# 该行命令运行后将会自动生成pdf并打开。
graph.render(view=True,outfile=None)

- 注意graphviz库的安装建议用anaconda来安装
- 命令 conda install python-graphviz
- 直接pip安装的话,运行时可能会报环境异常的错。
参数criterion
模型优化的标准,有三种标准,分别是“gini”, “entropy”, “log_loss”,默认是“gini”。特征少的时候使用“entropy”会更好,特征多的时候“gini”的效果会更好,当然这并不绝对。
*使用哪种标准,往往需要根据实际情况来选择。
参数random_state
设定随机状态,也就是设定一个随机种子。当设定随机种子后,对同一数据集的训练结果将不会再发生改变,即树模型不再改变。其原理是,将数据的所有特征按照一定顺序排列,并依照此顺序对树进行分支。
*该参数存在的意义是在一系列随机训练结果中,找到最符合期望的树,然后设定其随机种子,再调整其他参数,求得最优模型。
参数splitter
同random_state的存在意义。当设定random_state设定随机种子后,splitter参数往往使用“random”策略,即splitter=“random”。默认是splitter=“best”,在一系列随机生成的树中,优先选择更重要的特征进行分支。
*当模型过拟合时,参数选取“random”可以有效防止过拟合。
参数max_depth
一种剪枝策略,多说无益,上实战!
允许树生成的最大深度,
根节点为第0层,
当max_depth=3时,如下:
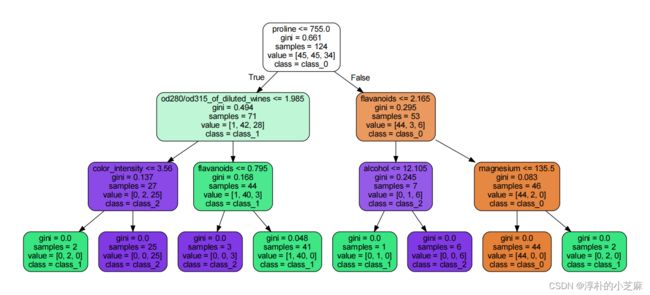
参数min_samples_leaf
一种剪枝策略,多说无益,上实战!
当min_samples_leaf=10时,
即要求每个叶子节点最少要有10个样本包含在内。

参数min_samples_split
一种剪枝策略,多说无益,上实战!
当min_samples_split=60时,
即要求每个节点的样本最少为60时,才能继续分枝。

至此分类树的主要应用参数就介绍完了
q:实战中如何选取对应参数呢?
a:一遍一遍试呗!
import matplotlib.pyplot as plt
import numpy as np
if __name__ == '__main__':
test = []
for i in range(10):
dtc = tree.DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=30)
dtc = dtc.fit(x_train,y_train)
score = dtc.score(x_test,y_test)
test.append(score)
# 打印出得分最高的那组max_depth的参数值
print(np.array(test).argmax()+1)
'''
3
'''
plt.plot(range(len(test)),test,color="blue",label="max_depth")
plt.legend()
plt.show()

那这结果不就显而易见了,max_depth=3,效果最好。再次训练时,max_depth参数直接填上3即可。
其他参数的选择可以同上进行操作,选出最优参数。
那么,“码完收工”!