python爬虫——豆瓣top250之scrapy框架
记录下对 scrapy 框架的认识,以及爬取豆瓣 top250 实战。
一、前提
编译IDA:pycharm 社区版
python版本:python3.7.4
二、Scrapy框架介绍
2.1、结构图
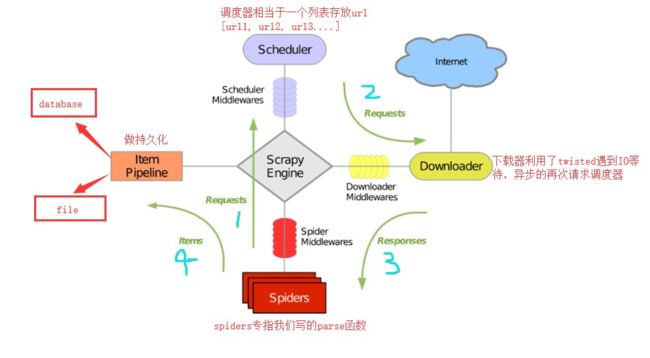
2.2、模块分析
- 引擎(Scrapy)
用来处理整个系统的数据流处理, 触发事务(框架核心) - 调度器(Scheduler)
用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址 - 下载器(Downloader)
用于下载网页内容, 并将网页内容返回给蜘蛛(Scrapy下载器是建立在twisted这个高效的异步模型上的) - 爬虫(Spiders)
爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。用户也可以从中提取出链接,让Scrapy继续抓取下一个页面 - 项目管道(Pipeline)
负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 - 下载器中间件(Downloader Middlewares)
介于Scrapy引擎和下载器之间的框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 - 爬虫中间件(Spider Middlewares)
介于Scrapy引擎和爬虫之间的框架,主要工作是处理蜘蛛的响应输入和请求输出。 - 调度中间件(Scheduler Middewares)
介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。
三、操作及完整代码
豆瓣 top250:https://movie.douban.com/top250,很容易就获取全部信息,就不再分析,直接开始创建工程。
默认已经安装好 scrapy 框架
3.1、创建工程
如果使用的是 IDE(集成开发环境),在下方点击 Terminal 输入以下命令就创建好了一个工程;如果不是,就在 cmd 中进入自己文件夹路径输入命令。
scrapy startproject douban
其中 douban 是工程名,结果如下图所示,可以看到自动生成了很多文件:

- init.py:初始化,一般为空
- scrapy.cfg:配置文件
- spiders:存放你Spider文件,也就是你爬取的py文件
- items.py:相当于一个容器,和字典较像
- middlewares.py:定义Downloader Middlewares(下载器中间件)和Spider Middlewares(爬虫中间件)的实现
- pipelines.py:定义Item Pipeline的实现,实现数据的清洗,储存,验证。
- settings.py:全局配置
3.2、创建自己的爬虫文件
cd douban
scrapy genspider doubanmovie douban.com
其中 doubanmovie 是 python 文件名,douban.com 是目标网址,结果如下图所示:

3.3、编写爬虫
因为很简单,所以写的地方很少,主要用了 xpath 和 re 正则表达式提取数据
(1)doubanmovie.py
# -*- coding: utf-8 -*-
import scrapy
import re
from ..items import DoubanItem
class DoubanmovieSpider(scrapy.Spider):
name = 'doubanmovie'
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
for item in response.xpath('/html/body/div[3]/div[1]/div/div[1]/ol/li'):
rank = item.xpath('./div/div[1]/em/text()').extract_first()
title = item.xpath('./div/div[2]/div[1]/a/span[1]/text()').extract_first()
director = item.xpath('./div/div[2]/div[2]/p[1]/text()').extract_first()
director = re.findall('导演: (.*?) 主演', director)
if director:
director = director[0]
year = item.xpath('./div/div[2]/div[2]/p[1]/text()[2]').extract_first()
year = re.findall(r'\d+', year)[0]
country = item.xpath('./div/div[2]/div[2]/p[1]/text()[2]').extract_first()
country = re.findall(r'/ (.*?) /', country)[0]
star = item.xpath('./div/div[2]/div[2]/div/span[2]/text()').extract_first()
quote = item.xpath('./div/div[2]/div[2]/p[2]/span/text()').extract_first()
film_info_url = item.xpath('./div/div[1]/a/@href').extract_first()
image_url = item.xpath('./div/div[1]/a/img/@src').extract_first()
movie = DoubanItem()
movie['rank'] = rank
movie['title'] = title
movie['director'] = director
movie['year'] = year
movie['country'] = country
movie['star'] = star
movie['quote'] = quote
movie['film_info_url'] = film_info_url
movie['image_url'] = image_url
yield movie
# 获取下一页的url
next_url = response.xpath('/html/body/div[3]/div[1]/div/div[1]/div[2]/span[3]/a/@href').extract_first()
if next_url is not None:
url = self.start_urls[0] + next_url
yield scrapy.Request(url=url, callback=self.parse)
(2)items.py
定义存放爬取数据名称
# -*- coding: utf-8 -*-
import scrapy
class DoubanItem(scrapy.Item):
# 豆瓣排名
rank = scrapy.Field()
# 电影标题
title = scrapy.Field()
# 导演
director = scrapy.Field()
# 上映年份
year = scrapy.Field()
# 国家
country = scrapy.Field()
# 豆瓣评分
star = scrapy.Field()
# 描述
quote = scrapy.Field()
# 豆瓣详情页
film_info_url = scrapy.Field()
# 图片
image_url = scrapy.Field()
(3)settings.py
主要设置请求、响应、管道管理、全局配置,在其中目前设置了User-Agent,管道开启,保存路径;
注释的没显示。
# -*- coding: utf-8 -*-
import random
BOT_NAME = 'douban'
SPIDER_MODULES = ['douban.spiders']
NEWSPIDER_MODULE = 'douban.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'douban (+http://www.yourdomain.com)'
# 设置 USER_AGENT
user_agent_list = [
"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0",
"Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; .NET4.0C; .NET4.0E; .NET CLR 2.0.50727; .NET CLR 3.0.30729; .NET CLR 3.5.30729; InfoPath.3; rv:11.0) like Gecko",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1",
"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; en) Presto/2.8.131 Version/11.11",
"Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11"
]
USER_AGENT = random.choice(user_agent_list)
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
# 开启管道,用于处理爬取的数据(保存数据)
ITEM_PIPELINES = {
'douban.pipelines.SaveFilePipeline': 300,
'douban.pipelines.SaveImgPipeline': 300,
}
# 电影数据保存JOSN
JSON_STORE = './json'
# 电影数据保存文件夹
# MOVIE_STORE = './xlsx'
# 电影海报保存文件夹
IMAGES_STORE = './images'
(4)pipelines.py
管道:把爬取数据以自己格式保存保存
# -*- coding: utf-8 -*-
import os
import json
import codecs
import requests
from .settings import IMAGES_STORE, JSON_STORE
# 将爬取的内容保存到 josn 中
class SaveFilePipeline(object):
def __init__(self) -> None:
self.res_list = []
super().__init__()
def process_item(self, item, spider):
res = dict(item)
self.res_list.append(res)
return item
def open_spider(self, spider):
pass
def close_spider(self, spider):
if not os.path.exists(JSON_STORE):
os.mkdir(JSON_STORE)
else:
# 打开文件, w+ 读写, 如果文件不存在会被创建, 存在则内容会被清空会重写写入
file = codecs.open(filename='{}/top250.json'.format(JSON_STORE), mode='w+', encoding='utf-8')
# ensure_ascii=False 保证输出的是中文而不是unicode字符
file.write(json.dumps(self.res_list, ensure_ascii=False))
file.close()
# 保存电影海报图片
class SaveImgPipeline(object):
def process_item(self, item, spider):
file_path = "{}/{}.jpg".format(IMAGES_STORE, item['title'])
# 目录不存在则创建目录
if not os.path.exists(IMAGES_STORE):
os.mkdir(IMAGES_STORE)
else:
if not os.path.exists(file_path):
with open(file_path, "wb") as f:
r = requests.get(item['image_url'])
f.write(r.content)
else:
pass
return item
四、结果
运行程序:scrapy crawl doubanmovie
这样就会运行整个程序,数据保存到指定位置
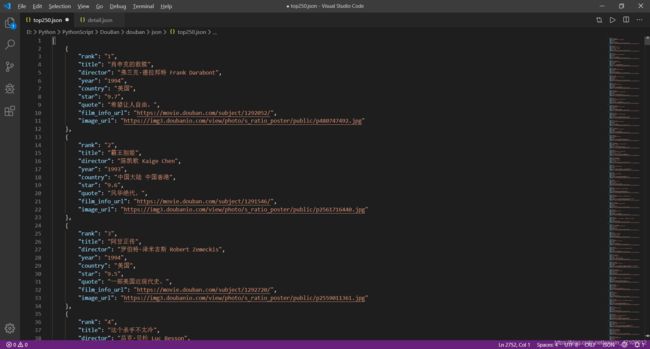
图片:
数据:
五、总结
5.1、基本操作
scrapy startproject 【工程名】
cd 【目录】
scrapy genspider 【python文件】 【目标网址】
crapy crawl 【python文件】
5.2、scrapy自带保存格式
把 items 保存的数据按照字母排序,以给定格式保存
是否需要转换编码
scrapy crawl doubanmovie -o detail.json -s FEED_EXPORT_ENCODING=utf-8 #为json格式保存
scrapy crawl doubanmovie -o detail.jsonlines
scrapy crawl doubanmovie -o detail.jl
scrapy crawl doubanmovie -o detail.csv #以csv文件格式保存
scrapy crawl doubanmovie -o detail.xml #以xml文件格式保存
scrapy crawl doubanmovie -o detail.marshal
scrapy crawl doubanmovie -o detail.pickle
5.3、关于调包
不知道为什么,在这个框架里调用自己的包,不能写全名,只能 ..settings 来用点省略调包
5.4、关于多线程
可以看到分类下线程函数,很多都没有使用 spider,但是必须保留,因为是固定格式。