数据集的划分与交叉验证
数据集的划分与交叉验证
- 数据集的划分
- 交叉验证
- 学习曲线
- 验证曲线
- 网格搜索
数据集的划分
训练模型的时候,为防止模型只在训练集上有效,需将数据集划分为训练集,验证集,如8/2分,训练集占比80%, 验证集占比20%
此时,不能从整体样本空间划分数据集,
应按照每个类别,进行8/2分
理解:
若在整个样本集上划分,比如

- 对2类样本的规律学习到的很少,模型有偏差
- 用学习到大多数0,1类样本规律的模型,预测2类样本,准确率也不会很高
就好比我们人的学习,学习的时候让你学习大量的语文,数学,然后考试的时候让你考大量的英语,那这尴尬了
能考好吗?肯定不能!
正确做法:
每类样本均按照8/2分的思想,保证训练集,验证集中每个类别的样本均衡

sklearn提供的数据集划分API
sklearn.model_selection.train_test_split(X,y,test_size=0.2,random_state=3,stratify=None)
stratify默认为None,此时若数据集类别不均衡,那划分的训练集,验证集中的类别也可能差别很大,导致训练的模型不能学习到所有类别的知识规律,然后在不均衡的验证集上预测,效果更好不到哪去。
此时需指定stratify=y,按照每个类别抽取20%放入验证集,保证训练集,验证集中类别间的样本均衡性跟总数据集中类别的均衡性是一样的
代码:
可以更改stratify参数,试着运行看 结果的差异
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
import numpy as np
#加载鸢尾花数据
X,y = load_iris(return_X_y=True)
print("总鸢尾花样本数:",X.shape[0])
m = X.shape[0]
#随机采样 制造样本不均衡的情况
X_ = np.random.choice(m,200) #返回一维数组 index
X_ = list(X_)
X_.extend(list(range(50)))
X_ = np.array(X_)
X_ = np.unique(X_) #去除重复的样本
print("随机选择%d个样本"%X_.shape[0])
#选出样本
X = X[X_]
y = y[X_]
print("总0类:",X[y==0].shape[0]/X.shape[0])
print("总1类:",X[y==1].shape[0]/X.shape[0])
print("总2类:",X[y==2].shape[0]/X.shape[0])
#
#划分随机采样的样本集
#在样本类别不均衡时,才可以看出stratify=y效果
X_train,X_verify,y_train,y_verify=train_test_split(X,y,test_size=0.2,\
random_state=3,stratify=None)
print("\n")
print("train 0类:",X_train[y_train==0].shape)
print("train 1类:",X_train[y_train==1].shape)
print("train 2类:",X_train[y_train==2].shape)
#验证集
v0 = X_verify[y_verify==0]
v1 = X_verify[y_verify==1]
v2 = X_verify[y_verify==2]
#验证集里第0类 占总样本中第0类 的比例
print("test 0类:",v0.shape[0],"占比:",v0.shape[0]/X[y==0].shape[0])
#验证集里第1类 占总样本中第1类 的比例
print("test 1类:",v1.shape[0],"占比:",v1.shape[0]/X[y==1].shape[0])
#验证集里第2类 占总样本中第2类 的比例
print("test 2类:",v2.shape[0],"占比:",v2.shape[0]/X[y==2].shape[0])
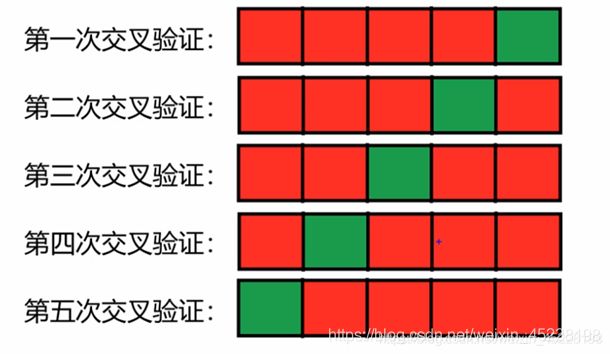
交叉验证
数据集的划分具有不确定性,一次的划分可能会使训练集或者验证集中具有某些特殊样本,那此时仅经过一次数据集划分训练的模型,预测的准确率可能会受到到这些特殊样本的影响。
比如:我们该考试了,复习的全是基础题型,结果一考试全是竞赛题型,瞬间蒙圈,能考好吗?肯定不能
所以模型也是一样
解决方法:多次交叉验证,取准确率的平均值
如下:
代码:

from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=5,weights="distance")
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
#划分数据集
X_train,X_verify,y_train,y_verify = train_test_split(X,y,test_size=0.2,random_state=3,stratify=y)
#交叉验证
cv_score = cross_val_score(clf,X_train,y_train,cv=10,scoring="accuracy")
print("交叉验证分数:",cv_score)
print("平均准确率:%.5f"%(cv_score.mean()))
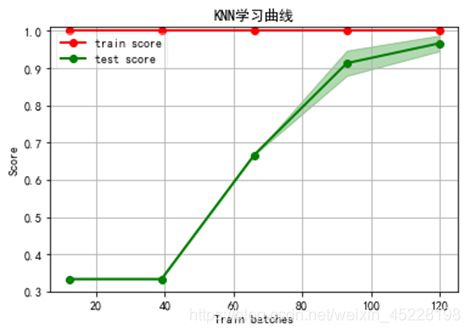
学习曲线
学习曲线是诊断模型的最有效方法之一
可以清楚的看出是过拟合/欠拟合
选择训练集的大小
#sklearn API
from sklearn.model_selection import learning_curve
#model
#X,y
#cv
#train_sizes
验证曲线
模型性能 关于某个超参数不同取值的函数关系
只能验证一个参数
from sklearn.model_selection import validation_curve
#参数
#model
#X,y
#参数名--“n_estimators” 只能对一个参数验证
#序列值
#cv=5
#原理
#当前model取不同的参数值时,分别对数据集进行5次交叉验证
#返回train_scores验证分数,test_scores验证分数
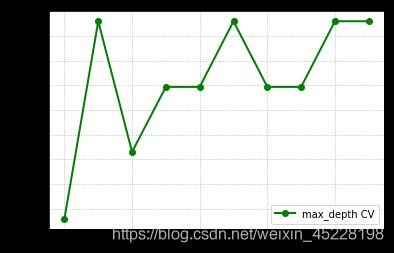
使用鸢尾花数据,基于随机森林建立分类模型,并对max_depth验证最佳取值
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from matplotlib import pyplot as plt
from sklearn.model_selection import validation_curve
X,y = load_iris(return_X_y=True)
rf = RandomForestClassifier()
train_scores,test_scores = validation_curve(rf,X,y,"max_depth",range(2,12),cv=5,scoring="f1_weighted")
#画验证曲线
plt.plot(range(2,12),test_scores.mean(axis=1),"go-",lw=2,label="max_depth CV")
plt.grid(linestyle=":")
plt.legend()
plt.show()
网格搜索
可以同时搜索多组参数的组合
from sklearn.model_selection import GridSearchCv
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier()
params = [{"n_estimators":range(100,500,50),"max_depth":range(2,12)}]
gs = GridSearchCV(rf,params,cv=5,scoring="f1_weighted")
gs.fit(X,y)
gs.predict(y_test)
gs.cv_results_
gs.best_estimator_
gs.best_params_
gs.best_score_