使用ubantu+pyspark完成对美国疫情的数据分析和可视化显示
实验参考林子雨老师的博客http://dblab.xmu.edu.cn/blog/2636-2/
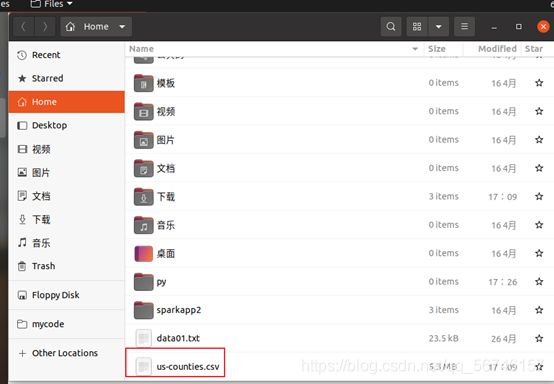
原始数据集是以.csv文件组织的,为了方便spark读取生成RDD或者DataFrame,首先将us-counties.csv转换为.txt格式文件us-counties.txt。转换操作使用python实现,代码组织在transform.py中,过程如下:
将熊猫导入为 pd
#.csv 转化成 .txt
data = pd.read_csv('/home/hadoop/us-counties.csv')
with open('/home/hadoop/us-counties.txt','a+',encoding='utf-8') as f:
??? 对于 data.values 中的行:
f.write((str(line[0])+' '+str(line[1])+' '+str(line[2])+' '+str(line[3]) )+' '+str(line[4])+'
'))
使用python运行文件
hadoop@zyj-virtual-machine:/usr/local/spark/mycode$ python3 transform.py
可以看到文件系统已经产生了txt文件, 转换成功
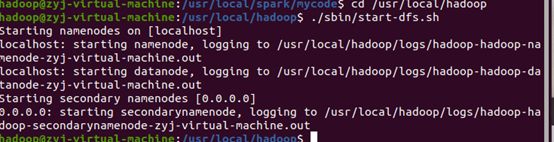
接下来要把文件放进hdfs中进行操作, 首先先启动我们的hdfs服务
hadoop@zyj-virtual-machine:/usr/local/spark/mycode$ cd /usr/local/hadoop
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./sbin/start-dfs.sh
启动情况

用jps查看
hadoop@zyj-virtual-machine:/usr/local/hadoop$ jps
启动成功, 接下来把文件放入hdfs中
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -put /home/hadoop/us-counties.txt /user/hadoop
查看hdfs的文件列表
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -ls | .txt
![]()
文件已经转换好格式并放入hdfs中, 接下来使用py脚本对文件进行下一步处理
analyst.py文件完整内容
从 pyspark 导入 SparkConf,SparkContext
从 pyspark.sql 导入行
从 pyspark.sql.types 导入 *
从 pyspark.sql 导入 SparkSession
从日期时间导入日期时间
导入 pyspark.sql.functions 作为 func
def toDate(inputStr):
??? newStr = ""
??? 如果 len(inputStr) == 8:
??????? s1 = inputStr[0:4]
??????? s2 = inputStr[5:6]
??????? s3 = inputStr[7]
??????? newStr = s1+"-"+"0"+s2+"-"+"0"+s3
??? 别的:
??????? s1 = inputStr[0:4]
??????? s2 = inputStr[5:6]
??????? s3 = inputStr[7:]
??????? newStr = s1+"-"+"0"+s2+"-"+s3
??? date = datetime.strptime(newStr, "%Y-%m-%d")
??? 归期
#主程序:
spark = SparkSession.builder.config(conf = SparkConf()).getOrCreate()
fields = [StructField("date", DateType(),False),StructField("county", StringType(),False),StructField("state", StringType(),False),
??????????????????? StructField("cases", IntegerType(),False),StructField("死亡数", IntegerType(),False),]
架构 = 结构类型(字段)
rdd0 = spark.sparkContext.textFile("/user/hadoop/us-counties.txt")
rdd1 = rdd0.map(lambda x:x.split(" ")).map(lambda p: Row(toDate(p[0]),p[1],p[2],int(p[3]) ]),int(p[4])))
shemaUsInfo = spark.createDataFrame(rdd1,schema)
shemaUsInfo.createOrReplaceTempView("usInfo")
#1.计算每日的累计确诊病例数和死亡数
df = shemaUsInfo.groupBy("date").agg(func.sum("cases"),func.sum("deaths")).sort(shemaUsInfo["date"].asc())
#列重命名
df1 = df.withColumnRenamed("sum(cases)","cases").withColumnRenamed("sum(deaths)","deaths")
df1.repartition(1).write.json("result1.json")?????????????????????????????? #写入hdfs
#注册为临时表供下一步使用
df1.createOrReplaceTempView("ustotal")
#2.计算每日较昨日的新增确诊病例数和死亡病例数
df2 = spark.sql("select t1.date,t1.cases-t2.cases as caseIncrease,t1.deaths-t2.deaths as deathIncrease from ustotal t1,ustotal t2 where t1.date = date_add(t2.date,1) ”)
df2.sort(df2["date"].asc()).repartition(1).write.json("result2.json") #写入hdfs
#3.统计截止5.19日 美国各州的累计确诊人数和死亡人数
df3 = spark.sql("select date,state,sum(cases) as totalCases,sum(deaths) as totalDeaths,round(sum(deaths)/sum(cases),4) as deathRate from usInfo where date = to_date(' 2020-05-19','yyyy-MM-dd') 按日期分组,状态")
df3.sort(df3["totalCases"].desc()).repartition(1).write.json("result3.json") #写入hdfs
df3.createOrReplaceTempView("eachStateInfo")
#4.找出美国确诊最多的10个州
df4 = spark.sql("select date,state,totalCases from eachStateInfo order by totalCases desc limit 10")
df4.repartition(1).write.json("result4.json")
#5.找出美国死亡最多的10个州
df5 = spark.sql("select date,state,totalDeaths from eachStateInfo order by totalDeaths desc limit 10")
df5.repartition(1).write.json("result5.json")
#6.找出美国确诊最少的10个州
df6 = spark.sql("select date,state,totalCases from eachStateInfo order by totalCases asc limit 10")
df6.repartition(1).write.json("result6.json")
#7.找出美国死亡最少的10个州
df7 = spark.sql("select date,state,totalDeaths from eachStateInfo order by totalDeaths asc limit 10")
df7.repartition(1).write.json("result7.json")
#8.统计截止5.19全美和各州的病死率
df8 = spark.sql("select 1 as sign,date,'USA' as state,round(sum(totalDeaths)/sum(totalCases),4) as deathRate from eachStateInfo group by date union select 2 as sign,date,state ,来自eachStateInfo的deathRate").cache()
df8.sort(df8["sign"].asc(),df8["deathRate"].desc()).repartition(1).write.json("result8.json")
主要功能:
先引入spark模块功能, 将txt文件读取进内存中生成rdd, 再将rdd转化成dataframe格式用于后续分析和进一步解析
将dataframe格式的数据进行进一步拆分, 用sql语句筛选源数据, 为图制作提供需要的数据格式
本实验主要统计以下8个指标,分别是:
-
统计美国截止每日的累计确诊人数和累计死亡人数。做法是以date作为分组字段,对cases和deaths字段进行汇总统计。
-
统计美国每日的新增确诊人数和新增死亡人数。因为新增数=今日数-昨日数,所以考虑使用自连接,连接条件是t1.date = t2.date + 1,然后使用t1.totalCases – t2.totalCases计算该日新增。
-
统计截止5.19日,美国各州的累计确诊人数和死亡人数。首先筛选出5.19日的数据,然后以state作为分组字段,对cases和deaths字段进行汇总统计。
-
统计截止5.19日,美国确诊人数最多的十个州。对3)的结果DataFrame注册临时表,然后按确诊人数降序排列,并取前10个州。
-
统计截止5.19日,美国死亡人数最多的十个州。对3)的结果DataFrame注册临时表,然后按死亡人数降序排列,并取前10个州。
-
统计截止5.19日,美国确诊人数最少的十个州。对3)的结果DataFrame注册临时表,然后按确诊人数升序排列,并取前10个州。
-
统计截止5.19日,美国死亡人数最少的十个州。对3)的结果DataFrame注册临时表,然后按死亡人数升序排列,并取前10个州
-
统计截止5.19日,全美和各州的病死率。病死率 = 死亡数/确诊数,对3)的结果DataFrame注册临时表,然后按公式计算。
在计算以上几个指标过程中,根据实现的简易程度,既采用了DataFrame自带的操作函数,又采用了spark sql进行操作。
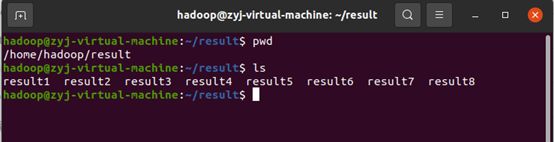
上述结果保存在hdfs内, 先查看文件是否生成成功
使用pyspark运行脚本
hadoop@zyj-virtual-machine:/usr/local/spark/mycode$ cd /usr/local/hadoop
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -ls | result
![]()
接下来依次将文件从hdfs中取到系统文件结构下
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /user/haddop/result1.json /home/hadoop/result/result1
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /user/haddop/result2.json /home/hadoop/result/result2
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /user/haddop/result3.json /home/hadoop/result/result3
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /user/haddop/result4.json /home/hadoop/result/result4
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /user/haddop/result5.json /home/hadoop/result/result5
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /user/haddop/result6.json /home/hadoop/result/result6
hadoop@zyj-virtual-machine:/usr/local/hadoop$ ./bin/hdfs dfs -get /user/haddop/result7.json /home/hadoop/result/result7
hadoop@zyj-virtual-machine:/usr/local/hadoop$./bin/hdfs dfs -get /user/haddop/result8.json /home/hadoop/result/result8
数据转换完成后使用pyecharts只做图表
使用pip 安装pyecharts

编写具体实现代码, 代码如下:
从 pyecharts 导入选项作为 opts
从 pyecharts.charts 导入栏
从 pyecharts.charts 导入行
从 pyecharts.components 导入表
从 pyecharts.charts 导入 WordCloud
从 pyecharts.charts 导入饼图
从 pyecharts.charts 导入漏斗
从 pyecharts.charts 导入散点图
从 pyecharts.charts 导入 PictorialBar
从 pyecharts.options 导入 ComponentTitleOpts
从 pyecharts.globals 导入 SymbolType
导入json
?
?
?
#1.画出每日的累计确诊病例数和死亡数——>双柱状图
def drawChart_1(index):
??? root = "/home/hadoop/result/result" + str(index)
??? 日期 = []
??? 案例 = []
??? 死亡 = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
??????????? if not line:??????????????????????????? # 到 EOF,返回空字符串,则终止循环
? ??????????????休息
??????????? js = json.loads(line)
??????????? date.append(str(js['date']))
??????????? case.append(int(js['cases']))
??????????? 死亡.追加(int(js ['死亡']))
?
??? d = (
??? 酒吧()
??? .add_xaxis(日期)
??? .add_yaxis("累计确诊人数", cases, stack="stack1")
??? .add_yaxis("累计死亡人数", deaths, stack="stack1")
??? .set_series_opts(label_opts=opts.LabelOpts(is_show=False))
??? .set_global_opts(title_opts=opts.TitleOpts(title="美国每日累计确诊和死亡人数"))
??? .render("/home/hadoop/result/result1.html")
??? )
?
?
#2.画出每日的新增确诊病例数和死亡数——>折线图
def drawChart_2(index):
??? root = "/home/hadoop/result/result" + str(index)
??? 日期 = []
??? 案例 = []
??? 死亡 = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
??????????? if not line:??????????????????????????? # 到 EOF,返回空字符串,则终止循环
??????????????? 休息
??????????? js = json.loads(line)
??????????? date.append(str(js['date']))
??????????? case.append(int(js['caseIncrease']))
??????????? 死亡.追加(int(js ['deathIncrease']))
?
??? (
??? Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
??? .add_xaxis(xaxis_data=date)
??? .add_yaxis(
??????? series_name="新增确诊",
??????? y_axis = 案例,
??????? markpoint_opts=opts.MarkPointOpts(
??????????? 数据=[
??????????????? opts.MarkPointItem(type_="max", name="最大值")
?
??????????? ]
??????? ),
??????? markline_opts=opts.MarkLineOpts(
??????????? data=[opts.MarkLineItem(type_="average", name="平均值")]
??????? ),
??? )
??? .set_global_opts(
??????? title_opts=opts.TitleOpts(title="美国每日新增确诊折线图", subtitle=""),
??????? tooltip_opts=opts.TooltipOpts(trigger="axis"),
??????? toolbox_opts=opts.ToolboxOpts(is_show=True),
??????? xaxis_opts=opts.AxisOpts(type_="category",boundary_gap=False),
??? )
??? .render("/home/hadoop/result/result2.html")
??? )
??? (
??? Line(init_opts=opts.InitOpts(width="1600px", height="800px"))
??? .add_xaxis(xaxis_data=date)
??? .add_yaxis(
??????? series_name="新增死亡",
??????? y_axis=死亡人数,
??????? markpoint_opts=opts.MarkPointOpts(
??????????? data=[opts.MarkPointItem(type_="max", name="最大值")]
??????? ),
??????? markline_opts=opts.MarkLineOpts(
??????????? 数据=[
??????????????? opts.MarkLineItem(type_="average", name="平均值"),
??????????????? opts.MarkLineItem(symbol="none", x="90%", y="max"),
??????????????? opts.MarkLineItem(symbol="circle", type_="max", name="最高点"),
??????????? ]
??????? ),
??? )
??? .set_global_opts(
??????? title_opts=opts.TitleOpts(title="美国每日新增死亡折线图", subtitle=""),
??????? tooltip_opts=opts.TooltipOpts(trigger="axis"),
??????? toolbox_opts=opts.ToolboxOpts(is_show=True),
??????? xaxis_opts=opts.AxisOpts(type_="category",boundary_gap=False),
??? )
??? .render("/home/hadoop/result/result2.html")
??? )
?
?
?
?
#3.画出截止5.19,美国各州累计确诊、死亡人数和病死率--->表格
def drawChart_3(index):
??? root = "/home/hadoop/result/result" + str(index)
??? allState = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
??????????? if not line:??????????????????????????? # 到 EOF,返回空字符串,则终止循环
??????????????? 休息
??????????? js = json.loads(line)
??????????? 行 = []
??????????? row.append(str(js['state']))
??????????? row.append(int(js['totalCases']))
??????????? row.append(int(js['totalDeaths']))
??????????? row.append(float(js['deathRate']))
??????????? allState.append(row)
?
??? 表 = 表()
?
??? headers = [“州名”、“总病例数”、“总死亡人数”、“死亡率”]
??? 行 = allState
??? table.add(标题,行)
??? table.set_global_opts(
??????? title_opts=ComponentTitleOpts(title="美国各州疫情一览", subtitle="")
??? )
??? table.render("/home/hadoop/result/result3.html")
?
?
#4.画出美国确诊最多的10个州——>词云图
def drawChart_4(index):
??? root = "/home/hadoop/result/result" + str(index)
??? 数据 = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
??????????? if not line:???????? ???????????????????# 到 EOF,返回空字符串,则终止循环
??????????????? 休息
??????????? js = json.loads(line)
??????????? row=(str(js['state']),int(js['totalCases']))
??????????? 数据.附加(行)
?
??? c = (
??? 词云()
??? .add("", data, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
??? .set_global_opts(title_opts=opts.TitleOpts(title="美国各州确诊Top10"))
??? .render("/home/hadoop/result/result4.html")
??? )
?
?
?
?
#5.画出美国死亡最多的10个州——>象柱状图
def drawChart_5(index):
??? root = "/home/hadoop/result/result" + str(index)
??? 状态 = []
??? 总死亡数 = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
??????????? if not line:??????????????????????????? # 到 EOF,返回空字符串,则终止循环
?????????? ?????休息
??????????? js = json.loads(line)
??????????? state.insert(0,str(js['state']))
??????????? totalDeath.insert (0, int (js ['totalDeaths']))
?
??? c = (
??? 画报栏 ()
??? .add_xaxis(状态)
??? .add_yaxis(
??????? "",
??????? 总死亡,
??????? label_opts=opts.LabelOpts(is_show=False),
??????? 符号大小=18,
??????? 符号重复=“固定”,
??????? symbol_offset=[0, 0],
??????? is_symbol_clip=真,
??????? 符号=符号类型.ROUND_RECT,
??? )
??? .reversal_axis()
??? .set_global_opts(
??????? title_opts=opts.TitleOpts(title="PictorialBar-美国各州死亡人数Top10"),
??????? xaxis_opts=opts.AxisOpts(is_show=False),
??????? yaxis_opts=opts.AxisOpts(
??????????? axistick_opts=opts.AxisTickOpts(is_show=False),
??????????? axisline_opts=opts.AxisLineOpts(
??????????????? linestyle_opts=opts.LineStyleOpts(不透明度=0)
??????????? ),
??????? ),
??? )
??? .render("/home/hadoop/result/result5.html")
??? )
?
?
?
#6.找出美国确诊最少的10个州——>词云图
def drawChart_6(index):
??? root = "/home/hadoop/result/result" + str(index)
??? 数据 = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
??????????? if not line:??????????????????????????? # 到 EOF,返回空字符串,则终止循环
??????????????? 休息
??????????? js = json.loads(line)
??????????? row=(str(js['state']),int(js['totalCases']))
??????????? 数据.附加(行)
?
??? c = (
??? 词云()
??? .add("", data, word_size_range=[100, 20], shape=SymbolType.DIAMOND)
??? .set_global_opts(title_opts=opts.TitleOpts(title="美国各州确诊最少的10个州"))
??? .render("/home/hadoop/result/result6.html")
??? )
?
?
?
?
#7.找出美国死亡最少的10个州——>漏斗图
def drawChart_7(index):
??? root = "/home/hadoop/result/result" + str(index)
??? 数据 = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
??????????? if not line:??????????????????????????? # 到 EOF,返回空字符串,则终止循环
??????????????? 休息
??????????? js = json.loads(line)
??????????? data.insert (0, [str (js ['state']), int (js ['totalDeaths'])])
?
??? c = (
??? 漏斗()
??? 。添加(
??????? “状态”,
??????? 数据,
??????? sort_="升序",
??????? label_opts=opts.LabelOpts(position="inside"),
??? )
??? .set_global_opts(title_opts=opts.TitleOpts(title=""))
??? .render("/home/hadoop/result/result7.html")
??? )
?
?
#8.美国的病死率--->饼状图
def drawChart_8(index):
??? root = "/home/hadoop/result/result" + str(index)
??? 值 = []
??? 使用 open(root, 'r') 作为 f:
??????? 为真:
??????????? 行 = f.readline()
???? ???????if not line:??????????????????????????? # 到 EOF,返回空字符串,则终止循环
??????????????? 休息
??????????? js = json.loads(line)
??????????? 如果 str(js['state'])=="USA":
??????????????? values.append(["Death(%)",round(float(js['deathRate'])*100,2)])
??????????? ????values.append(["No-Death(%)",100-round(float(js['deathRate'])*100,2)])
??? c = (
??? 馅饼 ()
??? .add("", 值)
??? .set_colors(["blcak","orange"])
??? .set_global_opts(title_opts=opts.TitleOpts(title="全美的病死率"))
??? .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
??? .render("/home/hadoop/result/result8.html")
??? )
?
?
#可视化主程序:
指数 = 1
而指数<9:
??? funcStr = "drawChart_" + str(index)
??? 评估(funcStr)(索引)
指数+=1
最后代码运行结果是生成各自对于的html文件来展示可视化内容
