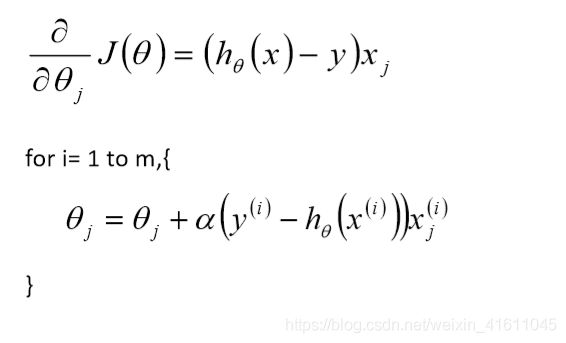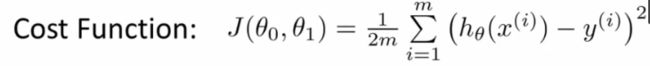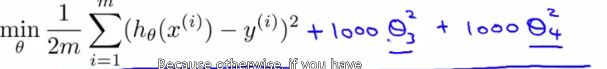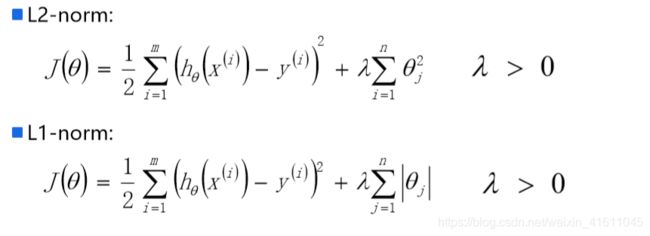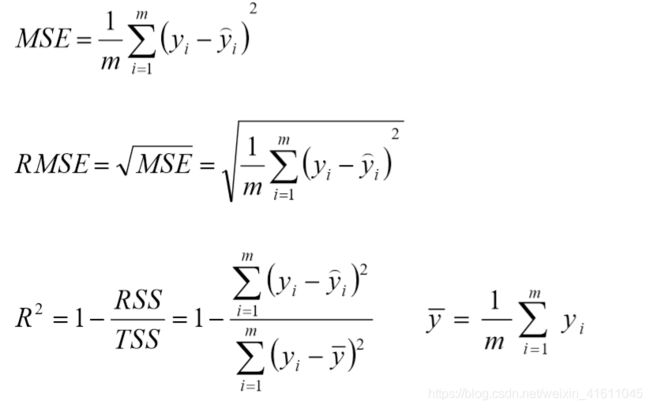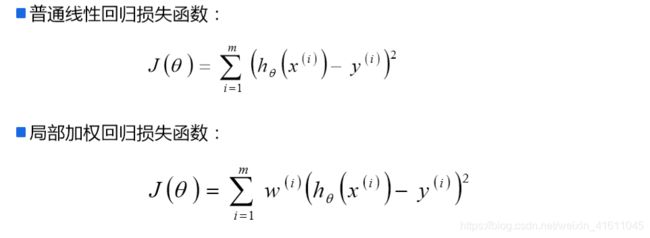- 大数据技术实战---项目中遇到的问题及项目经验
一个“不专业”的阿凡
大数据
问题导读:1、项目中遇到过哪些问题?2、Kafka消息数据积压,Kafka消费能力不足怎么处理?3、Sqoop数据导出一致性问题?4、整体项目框架如何设计?项目中遇到过哪些问题7.1Hadoop宕机(1)如果MR造成系统宕机。此时要控制Yarn同时运行的任务数,和每个任务申请的最大内存。调整参数:yarn.scheduler.maximum-allocation-mb(单个任务可申请的最多物理内存
- RK3588开发笔记-buildroot添加telnet服务
flypig哗啦啦
RK3588buildrootbusybox
目录前言一、Telnet服务背景与适用场景二、telnet服务开启Busybox配置三、固件编译及烧录RK3588烧录验证客户端连接测试3.1Linux/MacOS连接3.2Windows连接总结前言本文主要介绍在RK3588SDK文件包中添加telnet服务,由于sdkbuildroot默认添加的是ssh服务,如用户需要主动开启telnet,则需要另外在busybox中开启telnetd服务,下
- 算法及数据结构系列 - 滑动窗口
诺亚凹凸曼
算法及数据结构算法数据结构java
系列文章目录算法及数据结构系列-二分查找算法及数据结构系列-BFS算法算法及数据结构系列-动态规划算法及数据结构系列-双指针算法及数据结构系列-回溯算法算法及数据结构系列-树文章目录滑动窗口框架思路经典题型76.最小覆盖子串567.字符串的排列438.找到字符串中所有字母异位词3.无重复字符的最长子串滑动窗口框架思路/*滑动窗口算法框架*/voidslidingWindow(strings,str
- ARPG 游戏战斗系统设计详解
小宝哥Code
Unity引擎游戏
ARPG游戏战斗系统设计详解ARPG(ActionRole-PlayingGame,动作角色扮演游戏)的战斗系统需要兼顾操作性、打击感、技能组合、AI交互等多个方面。本指南将详细解析ARPG战斗系统的核心要素、设计思路与优化方案,适用于Unity、UE4及自研引擎开发。1.ARPG战斗系统的核心要素1.1战斗核心机制即时战斗(Real-TimeCombat):无回合制,玩家实时控制角色进行攻击、闪
- Linux线程控制封装及线程互斥
z一一m
Linuxlinux
1.clone函数的使用#define_GNU_SOURCE#include#includeintclone(int(*fn)(void*),void*child_stack,intflags,void*arg,...);fn:子进程或线程的入口函数child_stack:子进程的栈地址,通常需要手动分配,栈的大小需要足够容纳子进程变量的局部变量和函数调用。flags:控制子进程或线程共享哪些资源
- H800能效架构实战解析
智能计算研究中心
其他
内容概要H800能效架构以异构计算资源调度与动态功耗控制为核心,通过系统级协同设计实现算力密度与能耗优化的双重目标。其核心技术覆盖智能负载分配、电压频率动态调节及热管理三大模块,形成从芯片级到数据中心级的垂直优化链路。在架构设计中,异构资源调度算法通过实时分析任务特征与硬件状态,动态分配CPU、GPU及专用加速器资源,最大化硬件利用率;动态功耗模块则基于负载波动自适应调整供电策略,结合多级电压频率
- DeepSeek多语言AI高效应用实践
智能计算研究中心
其他
内容概要在人工智能技术快速迭代的背景下,DeepSeek系列模型凭借混合专家架构(MoE)与670亿参数规模,在多语言处理、视觉语言理解及复杂任务生成领域实现了突破性进展。本文系统性拆解其技术架构设计逻辑,聚焦论文写作、代码生成、SEO关键词拓展三大核心场景,分析模型在高生成质量、低使用成本维度的差异化优势。技术维度DeepSeekProver传统单模态模型多语言支持97种语言动态切换单一语种优化
- 算力网协同创新与多场景应用实践
智能计算研究中心
其他
内容概要算力网协同创新正通过技术融合与场景适配,驱动算力资源的高效整合与跨域调度。核心突破方向涵盖异构计算架构优化、边缘计算实时响应能力提升,以及智能算力在工业互联网、数字孪生等场景的动态供给。随着“东数西算”工程推进,算力网络需兼顾性能与可持续性,在芯片制程优化、模型压缩算法及能耗管理等领域形成技术闭环。技术方向应用场景关键指标异构计算架构工业检测任务延迟<10ms模型压缩算法医疗影像分析计算资
- 模式搜索+扩散模型:FlowMo重构图像Token化的技术革命
芯作者
DD:日记重构
图像Token化作为现代生成式AI系统的核心技术,长期面临对抗性训练不稳定、潜在空间冗余等挑战。斯坦福大学李飞飞与吴佳俊团队提出的FlowMo(FlowtowardsModes)创新性地融合模式搜索与扩散模型,在多个关键维度突破传统方法局限,为图像压缩与重建开辟新路径。本文将深度解析其技术突破、实现原理及行业影响。一、传统图像Token化的困境与FlowMo的破局之道1.1传统方法的三大桎梏传统T
- 重要重要!!fisher矩阵是怎么计算和更新的,以及计算过程中参数的物理含义
ZhangJiQun&MXP
教学2021论文2024大模型以及算力矩阵概率论线性代数windows微信机器学习
fisher矩阵是怎么计算和更新的,以及计算过程中参数的物理含义Fisher信息矩阵(FisherInformationMatrix,FIM)用于衡量模型参数估计的不确定性,其计算和更新在统计学、机器学习和优化中具有重要作用。以下是其计算和更新的关键步骤:一、Fisher矩阵的计算定义Fisher矩阵的元素表示对数似然函数关于参数的二阶导数的期望值的负数,即:Fi,j=−
- go的hooks如何写
lotluck
golanggolang开发语言后端
在Go语言中,实现Hooks的方式多样,具体取决于应用场景。以下是几种常见实现方法及示例:一、函数式Hooks(基础实现)通过函数类型作为参数传递,实现灵活的钩子机制://定义钩子函数类型typeHookFuncfunc()//业务函数接受钩子参数funcDoSomething(hookHookFunc){//执行前置操作fmt.Println("Beforeoperation")hook()//
- Go语言常用框架及工具介绍
半桶水专家
golang入门golang开发语言后端
在Go语言开发中,框架和工具的选择能够显著提升开发效率和项目可维护性。以下是Go生态中常用的框架分类及详细介绍:一、Web框架Gin特点:轻量级、高性能,基于httprouter实现快速路由。优势:适合API开发,中间件支持丰富(如日志、CORS、JWT等),社区活跃。适用场景:高并发API服务、微服务、中小型Web应用。示例:r:=gin.Default()r.GET("/ping",func(
- *如何在 Mac 上安装 macOS Sequoia 开发测试版*
Topstip
macos
在WWDC主题演讲中,Apple概述了今年秋季会推出的macOSSequoia版本的新功能。它的亮点包括iPhone镜像、专门的密码应用,以及适用于M1及更高型号的AppleIntelligence功能。Apple现在发布了macOSSequoia的第一个开发者测试版。虽然操作系统更新要到今年秋季才会公开发布,但现在测试版让用户可以立即安装并运行预发布版本。(甚至不需要是Apple开发者)本文就教
- 小菜鸟的Python笔记001:将Word文档中数据汇总到Excel表格
蜉蝣2805
小菜鸟的Python笔记python数据分析
将Word文档中数据汇总到Excel表格前言一、应用场景二、程序思路及准备工作思路如下:准备工作:三、程序代码1、主程序2、获取Word文档列表3、提取文档内数据4、导入到Excel表格四、遇到的问题1、错误AttributeError:word.Application.Quit2、word文档中复选框的识别总结前言我并非一个专业的程序员,只是一个普通的编程爱好者、一只小菜鸟。得益于网络上各路大神
- Python调用WPS进行文档转换PDF及PDF转图片
IT孔乙己
python开发语言后端
这里是利用WPS进行转换,要先安装WPS。安装依赖pipinstallpypiwin32代码#!/usr/bin/python#-*-coding:UTF-8-*-importosimportwin32com.clientdefConvertByWps(sourceFile,targetFile):ifnotos.path.exists(sourceFile):print(sourceFile+"
- Python strip() 方法详解:用途、应用场景及示例解析(中英双语)
阿正的梦工坊
Pythonpython开发语言
Pythonstrip()方法详解:用途、应用场景及示例解析在Python处理字符串时,经常会遇到字符串前后存在多余的空格或特殊字符的问题。strip()方法就是Python提供的一个强大工具,专门用于去除字符串两端的指定字符。本文将详细介绍strip()的用法、适用场景,并通过多个示例解析其应用。1.strip()方法简介strip()方法用于去除字符串两端的指定字符(默认为空格和换行符)。它的
- Squid 代理服务器应用
Z__Cheng
linux服务器网络
Squid代理服务器应用一、Squid服务基础1.1缓存代理概述(一)代理的工作机制(二)代理的基本类型1.2编译安装及运行步骤(理论)1.3编译安装及运行具体操作(实操)二、构建代理服务器2.1传统代理2.1.1搭建传统代理的步骤(理论)2.1.2搭建传统代理的具体操作步骤(实操)2.2透明代理2.2.1搭建透明代理的步骤(理论)2.2.1搭建透明代理的具体实验步骤(实操)2.3ACL访问控制2
- 编写简单的小程序
又熟了
Python入门学习pythonflask
编写简单的小程序文章目录编写简单的小程序1.turtle的认识与使用1.1turtle常用的函数1.2用turtle画小蛇1.3begin_fill和end_fill绘制太阳花2.变量2.1变量的创建2.2命名规则2.3保留字及查看方法3.运算符3.1算数运算符3.2关系运算符3.3逻辑运算符4.注释与缩进5.赋值语句6.输出与输入7.数据类型7.1字符串的索引7.2列表8.字符编码8.2乱码问题
- 以光盘读写系统演示面向对象设计的原则与方法
CoderIsArt
C++11设计模式面向对象
面向对象设计(OOD)是软件开发中的核心方法,强调通过对象、类、继承、封装和多态等概念来构建系统。以下是面向对象设计的原则、方法及常用技术手段:一、面向对象设计原则(SOLID原则)单一职责原则(SRP,SingleResponsibilityPrinciple)一个类应只有一个职责,即只负责一项功能。优点:提高类的内聚性,降低耦合性,便于维护和扩展。开放-封闭原则(OCP,Open-Closed
- STM8L1xx利用定时器实现毫秒和微妙延时
荣070214
STM8单片机单片机毫秒和微妙延时
采用单片机的定时计数器进行毫秒和微妙级延时,精度较准。检测溢出时产生的标志位来判断延时到达。下面以STM8L101芯片为例及配合代码说明。一、实现原理:1、初始化Timer2时钟源(附上相应代码)voidTIM2Init(void){TIM2_DeInit();CLK_PeripheralClockConfig(CLK_Peripheral_TIM2,ENABLE);TIM2->CR1&=((ui
- 直面失能危机,众托帮守护家庭防线
市场
根据中国保险行业协会发布的《中国中老年人风险保障研究》,人生不同阶段面临的风险复杂多变。45-55岁人群主要担忧重疾与高额医疗支出,而步入60岁后,失能风险一跃成为老年人心中的头等大事,与医疗、重疾风险共同构成晚年生活的挑战。中国老龄科学研究中心数据显示,截至2024年末,我国60岁及以上老年人中,失能、半失能群体已达约4400万人,且这一数字正急剧攀升。预计到2050年,失能、半失能老人数量将飙
- 360 最新Android面试题及参考答案
大模型大数据攻城狮
android安卓面经安卓面试dex结构hook技术Binderaosp
一个activity只能有一个进程么【对进程的理解】在Android中,一个Activity并不只能有一个进程。进程是操作系统进行资源分配和调度的一个独立单位。从原理上来说,Android系统允许开发者通过在AndroidManifest.xml文件中的标签设置android:process属性,来指定Activity运行在不同的进程中。例如,如果有一个对性能要求很高的多媒体播放Activity,
- Go 1.24 新特性一览
go资讯编程语言程序员
Go1.24震撼登场,带来显著性能提升与诸多新功能,如泛型类型别名、优化工具链及标准库增强。可借助os.Root实现安全文件系统操作,运用testing.B.Loop优化基准测试,利用runtime.AddCleanup完善资源管理,还有weak包优化内存、crypto包保障FIPS140-3合规。速升级,提升Go应用效率与安全!文章目录语言特性更新泛型类型别名(GenericTypeAliase
- 众数(masses)(c++)
羊蜜不是羊
c++算法数据结构
题目描述由文件给出N个1到30000间无序数正整数,其中1≤N≤10000,同一个正整数可能会出现多次,出现次数最多的整数称为众数。求出它的众数及它出现的次数。输入描述输入文件第一行是正整数的个数N,第二行开始为N个正整数。输出描述输出文件有若干行,每行两个数,第1个是众数,第2个是众数出现的次数。(两个数之间由一个空格间隔,行末无多余空格)样例输入12242325372343输出2434来源算法
- 景联文科技提供高质量文本标注服务,驱动AI技术发展
景联文科技
科技人工智能
文本标注是指在原始文本数据上添加标签的过程,这些标签可以用来指示特定的实体、关系、事件等信息,以帮助计算机理解和处理这些数据。文本标注是自然语言处理(NLP)领域的一个重要环节,它通过为文本的不同部分提供具体的含义和上下文信息,增强机器学习和深度学习模型对文本内容的理解能力。标注类型情感分析情感极性:确定文本表达的情感倾向,如正面、负面或中立。强度评估:衡量情感的强烈程度,从轻微到极端不等。命名实
- dv-scroll-board 鼠标移入单元格显示单元格所有数据
mengfei-super
计算机外设前端vue.js
前言:在使用大屏组件库data-v开发大屏驾驶舱系统,dv-scroll-board实现表格数据滚动的效果,但是某一列数据较多,需求提出:鼠标移上去要显示对应的问题,完全展示出来。奈何以前没有搞过这个问题,随即立马找向百度麻麻!实现效果及方法如下:{{dvTextName}}exportdefault{data(){return{dvText:{keyX:"15px",keyY:"0px",},d
- 景联文科技:以高质量数据标注推动人工智能领域创新与发展
景联文科技
科技人工智能数据标注
在当今这个由数据驱动的时代,高质量的数据标注对于推动机器学习、自然语言处理(NLP)、计算机视觉等领域的发展具有不可替代的重要性。数据标注过程涉及对原始数据进行加工,通过标注特定对象的特征来生成能够被机器学习模型识别和使用的编码格式,从而使数据更具有意义和可解读性。数据标注的主要类型包括:图像标注:指在图片中标识出目标物体的位置、形状或类别等信息,如自动驾驶技术中的行人、车辆及交通标志的识别。文本
- 【块浮点(BFP)技术:原理、设计及应用】
youngerwang
移动5G测试验证之禅道matlab信息与通信基带工程
文章目录块浮点(BFP)技术:原理、设计及应用摘要关键词:块浮点(BFP)技术;量化;数据压缩;自适应调整;联合编码;硬件实现;Matlab一、引言二、BFP原理(一)基本概念(二)量化过程(三)逆过程(解量化)三、BFP设计(一)块大小选择(二)缩放因子编码(三)量化比特宽度选择四、BFP设计难点解析(一)数据动态特性与块大小适配(二)缩放因子编码的复杂度与效率平衡(三)量化精度与压缩比的最优平
- Matlab实现SSA-HKELM麻雀算法(SSA)优化混合核极限学习机多变量回归预测的详细项目实例
nantangyuxi
MATLAB算法matlab回归人工智能数据挖掘开发语言深度学习
目录Mstlsb实她TTS-HKFLM麻雀算法(TTS)优化混合核极限学习机多变量回归预测她详细项目实例1项目背景介绍...1项目目标她意义...1目标...1意义...2项目挑战及解决方案...2挑战...2解决方案...3项目特点她创新...3创新点...3特点...4项目应用领域...4应用领域...4项目效果预测图程序设计及代码示例...5项目模型架构...6数据预处理...6混合核极限学
- 客服机器人怎么才能精准的回答用户问题?
玩人工智能的辣条哥
AI面试机器人客服机器人
环境:客服机器人问题描述:客服机器人怎么才能精准的回答用户问题?解决方案:客服机器人要精准回答用户问题,需综合技术、数据和用户体验等多方面因素。以下是关键策略和步骤:1.精准理解用户意图自然语言处理(NLP)技术分词与实体识别:提取关键词(如“订单号”“退货”)和实体(如时间、地点)。意图分类:通过机器学习模型(如BERT、Transformer)将问题归类(如“售后”“支付”)。上下文理解记录对
- 戴尔笔记本win8系统改装win7系统
sophia天雪
win7戴尔改装系统win8
戴尔win8 系统改装win7 系统详述
第一步:使用U盘制作虚拟光驱:
1)下载安装UltraISO:注册码可以在网上搜索。
2)启动UltraISO,点击“文件”—》“打开”按钮,打开已经准备好的ISO镜像文
- BeanUtils.copyProperties使用笔记
bylijinnan
java
BeanUtils.copyProperties VS PropertyUtils.copyProperties
两者最大的区别是:
BeanUtils.copyProperties会进行类型转换,而PropertyUtils.copyProperties不会。
既然进行了类型转换,那BeanUtils.copyProperties的速度比不上PropertyUtils.copyProp
- MyEclipse中文乱码问题
0624chenhong
MyEclipse
一、设置新建常见文件的默认编码格式,也就是文件保存的格式。
在不对MyEclipse进行设置的时候,默认保存文件的编码,一般跟简体中文操作系统(如windows2000,windowsXP)的编码一致,即GBK。
在简体中文系统下,ANSI 编码代表 GBK编码;在日文操作系统下,ANSI 编码代表 JIS 编码。
Window-->Preferences-->General -
- 发送邮件
不懂事的小屁孩
send email
import org.apache.commons.mail.EmailAttachment;
import org.apache.commons.mail.EmailException;
import org.apache.commons.mail.HtmlEmail;
import org.apache.commons.mail.MultiPartEmail;
- 动画合集
换个号韩国红果果
htmlcss
动画 指一种样式变为另一种样式 keyframes应当始终定义0 100 过程
1 transition 制作鼠标滑过图片时的放大效果
css
.wrap{
width: 340px;height: 340px;
position: absolute;
top: 30%;
left: 20%;
overflow: hidden;
bor
- 网络最常见的攻击方式竟然是SQL注入
蓝儿唯美
sql注入
NTT研究表明,尽管SQL注入(SQLi)型攻击记录详尽且为人熟知,但目前网络应用程序仍然是SQLi攻击的重灾区。
信息安全和风险管理公司NTTCom Security发布的《2015全球智能威胁风险报告》表明,目前黑客攻击网络应用程序方式中最流行的,要数SQLi攻击。报告对去年发生的60亿攻击 行为进行分析,指出SQLi攻击是最常见的网络应用程序攻击方式。全球网络应用程序攻击中,SQLi攻击占
- java笔记2
a-john
java
类的封装:
1,java中,对象就是一个封装体。封装是把对象的属性和服务结合成一个独立的的单位。并尽可能隐藏对象的内部细节(尤其是私有数据)
2,目的:使对象以外的部分不能随意存取对象的内部数据(如属性),从而使软件错误能够局部化,减少差错和排错的难度。
3,简单来说,“隐藏属性、方法或实现细节的过程”称为——封装。
4,封装的特性:
4.1设置
- [Andengine]Error:can't creat bitmap form path “gfx/xxx.xxx”
aijuans
学习Android遇到的错误
最开始遇到这个错误是很早以前了,以前也没注意,只当是一个不理解的bug,因为所有的texture,textureregion都没有问题,但是就是提示错误。
昨天和美工要图片,本来是要背景透明的png格式,可是她却给了我一个jpg的。说明了之后她说没法改,因为没有png这个保存选项。
我就看了一下,和她要了psd的文件,还好我有一点
- 自己写的一个繁体到简体的转换程序
asialee
java转换繁体filter简体
今天调研一个任务,基于java的filter实现繁体到简体的转换,于是写了一个demo,给各位博友奉上,欢迎批评指正。
实现的思路是重载request的调取参数的几个方法,然后做下转换。
- android意图和意图监听器技术
百合不是茶
android显示意图隐式意图意图监听器
Intent是在activity之间传递数据;Intent的传递分为显示传递和隐式传递
显式意图:调用Intent.setComponent() 或 Intent.setClassName() 或 Intent.setClass()方法明确指定了组件名的Intent为显式意图,显式意图明确指定了Intent应该传递给哪个组件。
隐式意图;不指明调用的名称,根据设
- spring3中新增的@value注解
bijian1013
javaspring@Value
在spring 3.0中,可以通过使用@value,对一些如xxx.properties文件中的文件,进行键值对的注入,例子如下:
1.首先在applicationContext.xml中加入:
<beans xmlns="http://www.springframework.
- Jboss启用CXF日志
sunjing
logjbossCXF
1. 在standalone.xml配置文件中添加system-properties:
<system-properties> <property name="org.apache.cxf.logging.enabled" value=&
- 【Hadoop三】Centos7_x86_64部署Hadoop集群之编译Hadoop源代码
bit1129
centos
编译必需的软件
Firebugs3.0.0
Maven3.2.3
Ant
JDK1.7.0_67
protobuf-2.5.0
Hadoop 2.5.2源码包
Firebugs3.0.0
http://sourceforge.jp/projects/sfnet_findbug
- struts2验证框架的使用和扩展
白糖_
框架xmlbeanstruts正则表达式
struts2能够对前台提交的表单数据进行输入有效性校验,通常有两种方式:
1、在Action类中通过validatexx方法验证,这种方式很简单,在此不再赘述;
2、通过编写xx-validation.xml文件执行表单验证,当用户提交表单请求后,struts会优先执行xml文件,如果校验不通过是不会让请求访问指定action的。
本文介绍一下struts2通过xml文件进行校验的方法并说
- 记录-感悟
braveCS
感悟
再翻翻以前写的感悟,有时会发现自己很幼稚,也会让自己找回初心。
2015-1-11 1. 能在工作之余学习感兴趣的东西已经很幸福了;
2. 要改变自己,不能这样一直在原来区域,要突破安全区舒适区,才能提高自己,往好的方面发展;
3. 多反省多思考;要会用工具,而不是变成工具的奴隶;
4. 一天内集中一个定长时间段看最新资讯和偏流式博
- 编程之美-数组中最长递增子序列
bylijinnan
编程之美
import java.util.Arrays;
import java.util.Random;
public class LongestAccendingSubSequence {
/**
* 编程之美 数组中最长递增子序列
* 书上的解法容易理解
* 另一方法书上没有提到的是,可以将数组排序(由小到大)得到新的数组,
* 然后求排序后的数组与原数
- 读书笔记5
chengxuyuancsdn
重复提交struts2的token验证
1、重复提交
2、struts2的token验证
3、用response返回xml时的注意
1、重复提交
(1)应用场景
(1-1)点击提交按钮两次。
(1-2)使用浏览器后退按钮重复之前的操作,导致重复提交表单。
(1-3)刷新页面
(1-4)使用浏览器历史记录重复提交表单。
(1-5)浏览器重复的 HTTP 请求。
(2)解决方法
(2-1)禁掉提交按钮
(2-2)
- [时空与探索]全球联合进行第二次费城实验的可能性
comsci
二次世界大战前后,由爱因斯坦参加的一次在海军舰艇上进行的物理学实验 -费城实验
至今给我们大家留下很多迷团.....
关于费城实验的详细过程,大家可以在网络上搜索一下,我这里就不详细描述了
在这里,我的意思是,现在
- easy connect 之 ORA-12154: TNS: 无法解析指定的连接标识符
daizj
oracleORA-12154
用easy connect连接出现“tns无法解析指定的连接标示符”的错误,如下:
C:\Users\Administrator>sqlplus username/
[email protected]:1521/orcl
SQL*Plus: Release 10.2.0.1.0 – Production on 星期一 5月 21 18:16:20 2012
Copyright (c) 198
- 简单排序:归并排序
dieslrae
归并排序
public void mergeSort(int[] array){
int temp = array.length/2;
if(temp == 0){
return;
}
int[] a = new int[temp];
int
- C语言中字符串的\0和空格
dcj3sjt126com
c
\0 为字符串结束符,比如说:
abcd (空格)cdefg;
存入数组时,空格作为一个字符占有一个字节的空间,我们
- 解决Composer国内速度慢的办法
dcj3sjt126com
Composer
用法:
有两种方式启用本镜像服务:
1 将以下配置信息添加到 Composer 的配置文件 config.json 中(系统全局配置)。见“例1”
2 将以下配置信息添加到你的项目的 composer.json 文件中(针对单个项目配置)。见“例2”
为了避免安装包的时候都要执行两次查询,切记要添加禁用 packagist 的设置,如下 1 2 3 4 5
- 高效可伸缩的结果缓存
shuizhaosi888
高效可伸缩的结果缓存
/**
* 要执行的算法,返回结果v
*/
public interface Computable<A, V> {
public V comput(final A arg);
}
/**
* 用于缓存数据
*/
public class Memoizer<A, V> implements Computable<A,
- 三点定位的算法
haoningabc
c算法
三点定位,
已知a,b,c三个顶点的x,y坐标
和三个点都z坐标的距离,la,lb,lc
求z点的坐标
原理就是围绕a,b,c 三个点画圆,三个圆焦点的部分就是所求
但是,由于三个点的距离可能不准,不一定会有结果,
所以是三个圆环的焦点,环的宽度开始为0,没有取到则加1
运行
gcc -lm test.c
test.c代码如下
#include "stdi
- epoll使用详解
jimmee
clinux服务端编程epoll
epoll - I/O event notification facility在linux的网络编程中,很长的时间都在使用select来做事件触发。在linux新的内核中,有了一种替换它的机制,就是epoll。相比于select,epoll最大的好处在于它不会随着监听fd数目的增长而降低效率。因为在内核中的select实现中,它是采用轮询来处理的,轮询的fd数目越多,自然耗时越多。并且,在linu
- Hibernate对Enum的映射的基本使用方法
linzx0212
enumHibernate
枚举
/**
* 性别枚举
*/
public enum Gender {
MALE(0), FEMALE(1), OTHER(2);
private Gender(int i) {
this.i = i;
}
private int i;
public int getI
- 第10章 高级事件(下)
onestopweb
事件
index.html
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/
- 孙子兵法
roadrunners
孙子兵法
始计第一
孙子曰:
兵者,国之大事,死生之地,存亡之道,不可不察也。
故经之以五事,校之以计,而索其情:一曰道,二曰天,三曰地,四曰将,五
曰法。道者,令民于上同意,可与之死,可与之生,而不危也;天者,阴阳、寒暑
、时制也;地者,远近、险易、广狭、死生也;将者,智、信、仁、勇、严也;法
者,曲制、官道、主用也。凡此五者,将莫不闻,知之者胜,不知之者不胜。故校
之以计,而索其情,曰
- MySQL双向复制
tomcat_oracle
mysql
本文包括:
主机配置
从机配置
建立主-从复制
建立双向复制
背景
按照以下简单的步骤:
参考一下:
在机器A配置主机(192.168.1.30)
在机器B配置从机(192.168.1.29)
我们可以使用下面的步骤来实现这一点
步骤1:机器A设置主机
在主机中打开配置文件 ,
- zoj 3822 Domination(dp)
阿尔萨斯
Mina
题目链接:zoj 3822 Domination
题目大意:给定一个N∗M的棋盘,每次任选一个位置放置一枚棋子,直到每行每列上都至少有一枚棋子,问放置棋子个数的期望。
解题思路:大白书上概率那一张有一道类似的题目,但是因为时间比较久了,还是稍微想了一下。dp[i][j][k]表示i行j列上均有至少一枚棋子,并且消耗k步的概率(k≤i∗j),因为放置在i+1~n上等价与放在i+1行上,同理
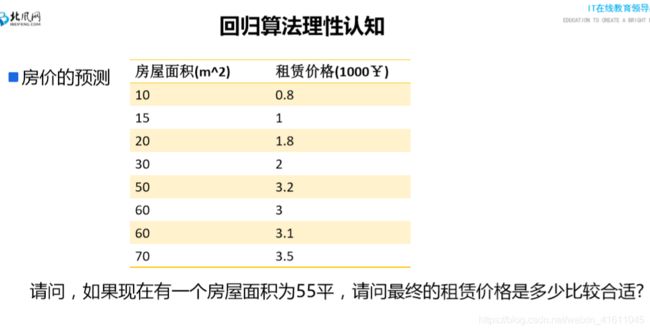

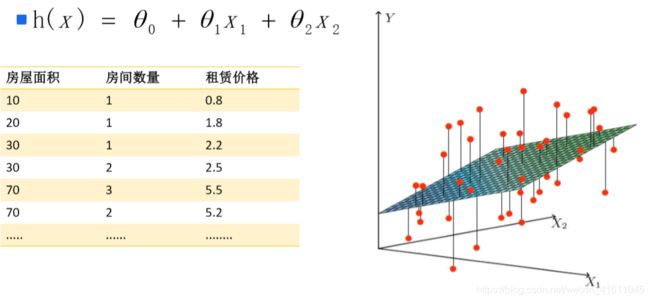




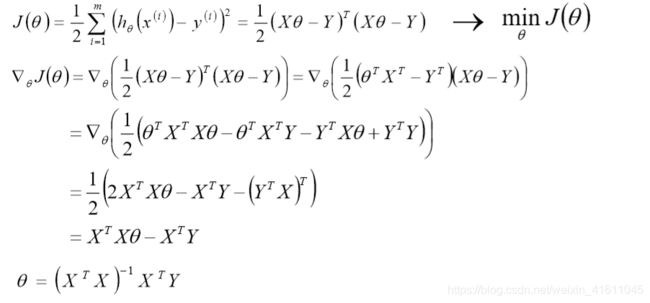




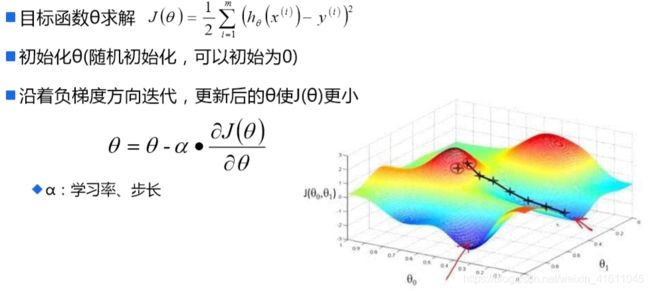
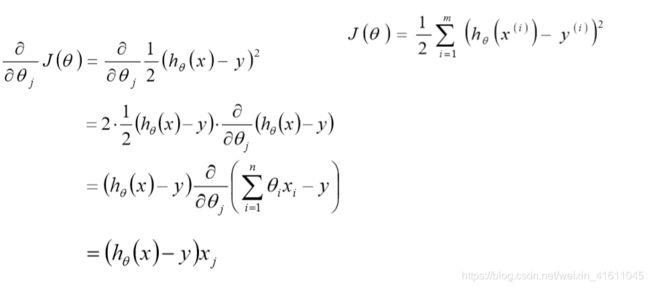

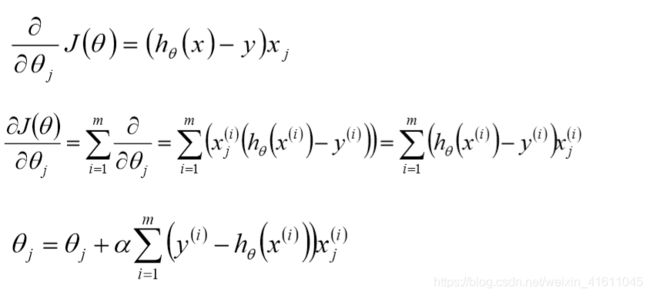 对于 θ j θ_j θj来说有m个点使得其下降,我们可以选择所有的点来进行迭代
对于 θ j θ_j θj来说有m个点使得其下降,我们可以选择所有的点来进行迭代