论文中文解读 End-to-End Multimodal Emotion Recognition using Deep Neural Networks 基于深度神经网络的端到端多模态情感识别
论文解读 End-to-End Multimodal Emotion Recognition using Deep Neural Networks 基于深度神经网络的端到端多模态情感识别
英文文献https://www.researchgate.net/publication/316538984
摘要:我们提出了一种使用听觉和视觉的情绪识别系统。利用卷积神经网络(CNN)从语音中提取特征,视觉模态使用50层的深度残差网络(ResNet)。另外,机器学习算法要对异常值不敏感,同时能够对上下文进行建模。所以,本文利用了长短期记忆(LSTM)网络,通过利用每个流的相关性,以端到端的方式进行训练。
I.介绍
情感分析很重要,在很多领域广泛应用(文献1、2)
大量研究显示出这些网络变体在建模语音信号固有结构时的有利属性,最近的研究尝试尽可能少的使用人类先验知识进行端到端优化。然而,这些工作大多数使用手工特征作为输入特征,比如MFCC、感知线性预测系数、超段特性,这些是建立在几十年听觉研究中获得的知识之上的 。
近期,出现一种趋势:直接从原始的、未处理的数据导出输入信号的表示。这种趋势的出现是因为网络自动学习的原始输入信号的中间表示,更好地适合手头的任务,从而提高性能。
本文中研究自动情感感应。音频频道用CNN架构获取语音信号特征,用ResNet-50 获取视觉信息。这两种网络的输出融合在一起,然后fed to 一个lstm。采用端到端的方式训练,使用一致性相关系数(ρc)的显式最大化,这比用均方误差目标优化表现好。通过进一步研究循环层不同细胞的激活,发现存在可解释细胞,与韵律和声学特征高度相关,试图传达情感信息。
II. 相关工作
近来,一系列新的神经网络,比如:autoencoder netwarks,CNNs, DBNs、LSTM。
Ngiam et al. [15]提出 a Multimodal Deep Autoencoder (MDAE) network 从视频音频中提取特征,首先,是一个bimodal DBN训练初始化深的自动编码器,然后MDAE微调,以尽量减少两种模态的重建误差。
Hu et al. [16] 提出一种时序多模态网络 叫做 Recurrent Temporal Multimodal Restricted Boltzmann Machine (RTMRBM) 来模拟视听数据序列。
DNNs用来手势识别。在[17]作者使用骨骼信息和RGB-D图像识别手势。更特别的是,他们使用DBNs要处理骨架特征和RGB-D数据使用3DCNN,通过在顶部堆叠一个隐马尔可夫模型(HMM)来考虑时间信息。
Han et al. [18] 使用手工特征 to feed a DNN .
Lim et al [19] 在使用短时傅立叶变换对数据进行变换之后,使用 CNNs来提取高级特征。使用LSTM获取时序结构
Trigeorgis et al.[10] 提出了一种端到端的模型,使用CNN从原始信号中提取特征 ,然后使用一个LSTM网络获取数据中的上下文信息 。
用DNN通过脸部信息进行情绪分析。比如Huang et al. [20] 提出了通过结合DNN和超图的基于图像的情感识别的一个直观的学习框架。在DNN训练情感分类任务,在最后一个完全连接层的每个节点被视为一个属性,用来在超图中形成超边。Ebrahimi et al. [21] 合并了CNNs和RNNs来识别视频中的情绪。首先训练CNN来识别静态图像中的情感。然后,从CNN中提取到的特征用来训练RNN来产生整个视频中的情绪。
近来合并视听模式取得进展。Kim et al. [23] 提出了四个不同DBN 架构,其中一个是基本的2层DBN,其余的变异体,基本的架构首先分别学习音频和视频特征。 之后,连接两个模态中的这些特征来学习第二层。 使用一个 Support Vector Machine (SVM)来评估这些特征。
Kahou et al. [24]提出结合具体模态DNNs来识别视频中的情感。 一个CNN被用来分析视频帧,一个DBN捕捉音频信息,一个深度的自动编码器来模拟整个场景中描绘的人类行为, 最后是CNN网络从人类嘴型提取特征。他们使用两种方法输出最后的预测。第一种方法,取每种模态预测的平均值,第二种方法用级联特征学习带有RBF的SVM.[25] 25]比较使用multi-scale Dense SIFT features (MSDF)从人脸中提取的手工特征和从CNNs中提取的特征训练训练线性支持向量回归.提取的音频特征是the extended Geneva Minimalistic Acoustic Parameter Set (eGeMAPS). 这些级联特征用来学习支持向量回归a Support Vector Regression (SVR).
Zhang et al. [26]对音频和声频使用多模态CNN进行情绪分类。模型分两阶段进行训练. 第一阶段,两个CNNs在大的图像数据集上进行预训练并且微调情感识别. 声频CNN将音频信号的melspectogram段作为输入 ,视频 CNN将脸作为输入。在第二阶段DNN由一系列完全连接的层组成的训练,由两个CNNs提取出来的级联特征作为输入。 Ringeval et al. [27] 使用一种捕获上下文信息的双向BLSTM-RNN,上下文信息存在于从数据中提取的多模态特征(音频视频生理)Han et al. [28]提出了加强建模框架,能作为特征级和决策级融合策略来实现,包括两个回归模型。第一个模型的预测连接到原始特征向量,并反馈到第二回归模型做最终预测。
2016年挑战赛中,在一个提交的挑战模型中, Huang et al. [30] 提出使用相关向量机Relevance Vector Machine(RVM)的变体建模音频,视频和视听数据。另一个,Weber et al. [31]提出模型使用 high-level geometry features for predicting dimensional features.Low-level feature:通常是指图像中的一些小的细节信息,例如边缘(edge),角(corner),颜色(color),像素(pixeles), 梯度(gradients)等,这些信息可以通过滤波器、SIFT或HOG获取; High level feature:是建立在low level feature之上的,可以用于图像中目标或物体形状的识别和检测,具有更丰富的语义信息。通常卷积神经网络中都会使用这两种类型的features: 卷积神经网络的前几层学习low level feature,后几层学习的是high level feature 。Brady et al. [32] 也是用 low- and high-level features 来建模情绪.Povolny et al. [33] 为音频和视频补充原始基线功能,进行情感识别.Somandepalli et al. [34] also used additional features but only for the audio modality.
本文我们提出一个既考虑时序也考虑上下文的端到端训练的模型。
III.提出的方法
传统算法提取音频特征,使用时频分解的有限脉冲响应滤波器减少背景噪声的影响。更复杂的人工设计内核也被使用,例如 gammatone filters [36], 通过研究草蛙听觉神经元的感受野的频率响应制定的.
我们模型的一个关键组成部分就是卷积操作,音频、视频信号分别用1-d and 2-d 卷积(2d卷积:对于图中的RGB图像,采用了三个独立的2-D kernel)

f(x) 是一个核函数,它的参数从手头任务的数据中学习。对信号进行空间建模之后.消除背景噪声,增强手头任务信号的特定部分,我们通过使用一个LSTM建模语音和视频的时间结构。我们使用LSTM 1)简单,2)为了公平对比现存的方法,这些方法结合手工特征和LSTM网络。反向传播的目标函数训练模型,目标函数详见公式3
A. Visual Network
我们使用一个50层的深度残差网络,用从参与者视频裁剪脸的像素强度作为网络输入。
![]() 其中x和y是层k的输入和输出,F(xk,{Wk})要学习的残差函数,h(xk)可以是恒等映射,也可以是线性投影到匹配函数F和输入x的维数。
其中x和y是层k的输入和输出,F(xk,{Wk})要学习的残差函数,h(xk)可以是恒等映射,也可以是线性投影到匹配函数F和输入x的维数。
ResNet-50的第一层是包含 64 个feature maps的7x7卷积层,然后是大小为3x3的最大池化层。网络的其余部分由4 个bottleneck architectures组成,这些架构包含3个卷积层,大小为1x1,3x3,和1X1,for each residual function。
Table I shows the replication and the sizes of the feature maps for each bottleneck architecture. After the last bottleneck architecture an average pooling layer is inserted.

B. Speech Network
Input.考虑到说话者之间不同音量的变化,预处理时间序列为零均值和单位方差,之后把原始波形分段为6s长的序列。 在16千赫采样率,这对应于96000维的输入向量。
Temporal Convolution时间卷积. 用F = 20 时空有限脉冲滤波器,窗口大小 5ms,从高采样率信号提取精细尺度光谱信息
Pooling across time.跨时间池化 每个滤波器的脉冲响应通一个过半波整流器(类似于人耳中的耳蜗转导步骤),然后下采样到8千赫,通过池化每个脉冲,池化层:a pool size = 2.
Temporal Convolution. 时间卷积。我们用M= 40 时空有限脉冲滤波器,窗口大小 500ms,用来提取更长期的语音特征和语音信号的粗糙度
Max pooling across channels. 跨通道最大池化。with a pool size of 10. 这减少了信号的维度同时也保存卷积信号的必要统计信息
Dropout. 由于参数众多,为了避免过拟合,进行正则化,选择以0.5的概率dropout
C. Objective function目标函数
损失函数考虑到 the concordance correlation coefficient (ρc), we define Lc as
follow:
 为了最小化损失函数,我们反向传播最后一层权重的梯度。
为了最小化损失函数,我们反向传播最后一层权重的梯度。
 where all vector operations are done element-wise.
where all vector operations are done element-wise.
D. Network Training
在训练多模态网络之前,每个特定模态的网络分别进行训练,以加快训练过程。
Visual Network.视频网络.我们选择微调预训练的ResNet-50。这个模型是在2012年ImageNet上训练的[38]由1000个类组成的分类数据集。预先训练的模型是首选比训练网络从零开始,受益于模型已学到的特征。要训练这个网络模型,用一个2层LSTM,每层有256个细胞,堆叠在这个网络模型的顶部,以捕捉时间信息。
Speech Network.CNN网络通过原始信号来提取特征。为了考虑语音的时间结构,我们用两LSTM层与每层256个细胞在CNN的顶部。
Multimodal Network. 多模态网络。训练视觉和言语网络后,LSTM层被丢弃,只考虑提取到的特征。网络提取1280个特征,其中视觉网络640个特征。这些被串联起来形成一个1920维的特征向量,并feed to一个2层LSTM,每层有256个细胞,训练LSTM层同时视觉和语音网络进行微调。图1显示了多模态网络

每个单模态和多模态网络的目标是最小化: 其中Lac和Lvc分别是arousal and valence的一致性。分段6s序列为150较小的子序列,以匹配匹配标注频率为40ms的粒度。
其中Lac和Lvc分别是arousal and valence的一致性。分段6s序列为150较小的子序列,以匹配匹配标注频率为40ms的粒度。
IV. DATASET
REmote COLlaborative and Affective (RECOLA) database introduced by Ringeval et al. [39];该数据集有46个说法语的参与者,一共9.5小时的多模态录音,每五分钟一个标签,在一个视频会议中执行二人合作任务。46个参与者中,17个法国人,3个德国人,三个印第安人,数据集分为三部分,16人用于测试,15人用于验证,15人用于测试。其中平衡了性别和年龄。最后有六个法国人三男三女标记了所有的录音。
V. 实验与结果
使用Adam优化器,整个实验固定学习率10 e-4.
音频模型25个样本的小批量。为了规范网络,除了循环层,其余所有层用dropout p=0.5,这一步很重要,因为参数很多防止过拟合。
视频模型,图像96*96,2个样本的小批量。由于硬件局限性,选择小批量。通过将图像大小调整为110×110,并随机剪切到与原来的大小相等的大小,数据得到了增强。这会产生一个尺度不变的模型。此外,通过给图像引入随机亮度和饱和度使用彩色增强。
对于所有研究的方法,一系列在预测中获得的后验证被应用在验证数据集上。1)中值滤波(窗口大小从0.4秒到20秒不等)[7]。2)定心(通过计算标签与预测之间的偏差) [42]。3)标度(使用标签和预测间的标准偏差比率作为标度因子)[42] 4)时移(通过将预测值从0.04秒到10秒的时间向前移动),以补偿评级中的延迟[43]。当在验证集的ρc上观察到改进时,将保留这些后处理步骤中的任何一个,然后在测试分区上应用相同的配置。
A. Ablation study 消融研究
由于内存和训练不稳定的问题[44]在循环网络中使用非常大的序列并不总是最佳的。其理由可以是过度的梯度或非常深的展开图,使训练这样的大网络更困难。
为了选择最佳长度的序列,我们进行了实验,使用序列长度为75,150,300的语音和视觉模型。表二显示了数据集上的结果,所有实现模型都运行60 a total of 60 epochs ,对于视觉网络,我们期望在配价维度得到最高的值,而对于言语模型在唤醒维度。综合考虑,我们选择训练150序列长度的多模态网络。

B. Speech Modality
使用所有46名参与者,每种方法获得的结果见表3.所有的实验中,ρc方面,我们的模型优于设计的特征.eGEMAPS特征集在valence上提供了接近的性能,相比唤醒arousal是更难以预测的。此外,我们表明,通过将ρc直接纳入所有网络的优化函数,允许我们在我们评估的模型上在度量(ρc)上优化模型。这为我们提供了1)一个优化模型更好的方式
2)如表三所示,在所有测试运行中始终提供更好的结果。
此外,我们比较了现存方法得到结果上的性能。它们中的大多数都参加了2016年的AVEC挑战赛,使用27个参与者(表四)。如果在测试或验证集上的性能没有在论文中报告,则插入一个破折号。
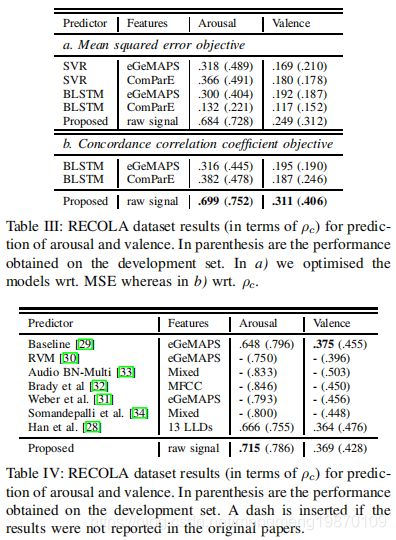
结果表明,唤醒维度,我们的模型优于测试集中的其他模型。虽然在验证集上,相比较挑战中的baseline而言,我们的模型得到较低的唤醒维度,但是在测试集上其性能更好.
- 与现有声学和韵律特征的关系:无论是明确的,即通过语言手段,或含蓄,即,通过声学或韵律线索,语音信号传达有关情感状态的信息。某些声学和韵律特征发挥重要作用,识别情感状态[45].这些特征中,如基频的平均值(F0)、平均语音强度、响度以及音高范围。[46],应该被我们的模型捕获。
为了更好地了解我们的语音模型学习什么,以及这与现有文献的关系,我们研究了应用在看不见语音记录的网络中门激活的统计,网络中循环层不同细胞隐藏层输出可视化,在图2给出。表明,模型的某些细胞对原始语音波形的不同特征是非常敏感的
C. Visual Modality视觉形态
比起arousal,视觉模式更容易预测valence。表五给出了,RECOLA数据集的valence维度上的最佳结果。只有Han et al. [28]的没有提交给AVEC2016挑战。所有模型的特征都是外观和几何。对于外观,局部Gabor二值模式从三个正交平面(Local Gabor Binary Patterns from Three Orthogonal Planes:LGBPTOP)提取特征,几何特征用面部地标facial landmarks提取的。使用多域卷积神经网络跟踪器(MDNet)跟踪算法从视频的帧提取的面部原始像素强度[47作为网络的输入。该算法将视频中第一个帧的人脸的边界框,并在所有帧跟踪它。
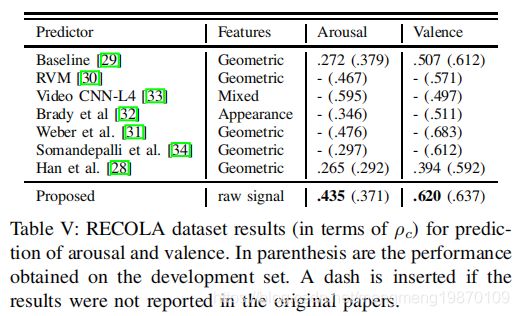
正如预期的那样,视觉模态有利于模型的 valence维度。唯一的例外是视频CNN-L4模型表现更好的唤醒维度,当使用外观特征。我们的模型优于测试集的valence维度的所有其他模型
D. Multimodal Analysis多模态分析
文献中,只发现其他两个模型使用语音和视觉模态上的RECOLA数据库。Output-Associative Relevance Vector Machine Staircase Regression (OA RVM-SR) [30]
and the strength modeling system proposed by Han et al. [28]
.结果见表六。

我们的模型高幅度优于其他两个模型的valence dimension。对于觉醒维度OARVM-SR产生最好的结果。有两个主要差异[30]
(a)该系统[30]是同时使用训练集和验证集来训练的,而我们的模型只使用了训练集
(b)我们的系统直接在原始像素域上操作,而[30]利用一些几何特征(例如,2D/3D人脸标志等)这需要一个一种精确的面部标志点跟踪方法的存在(我们的只是传统的面部检测器)。
我们期望我们的结果将进一步改善,通过应用类似的策略。最后,为了进一步证明我们的模型自动预测arousal and valence的好处图3说明了来自RECOLA的单个测试对象的结果。 