【SingleShotMultiBoxDetector(SSD,单步多框目标检测)】
文章目录
- SSD的特点
- 算法的对比图
- SSD算法概述
- 优缺点
- 主干网络
- 其他细节
-
- 一,重用了faster rcnn的锚点框机制。
- 二,为什么要这样多尺度特征图预测?
- 三,全卷积网络结构(Convolutionalpredictorsfordetection)
- 损失函数
- 预测过程
项目源码:
SSD的特点
•One-Stage
•均匀的密集抽样
•Priorboxes/Defaultboxes(Anchorboxes)
•不同尺度抽样•不同scale尺度的特征图抽样
•对于小目标检测效果不错
•预测速度快
•训练困难(正负样本极度不均衡)
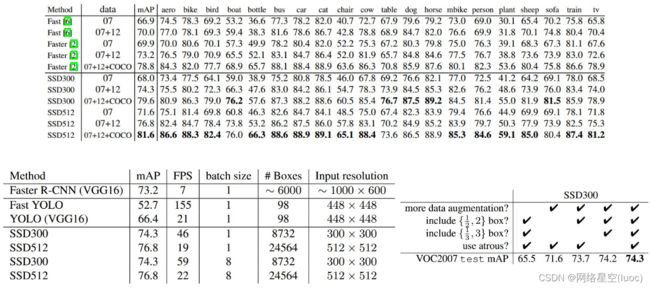
下图为一些网络结构的效率对比图,一般来说,map达到75%到80%就可以了
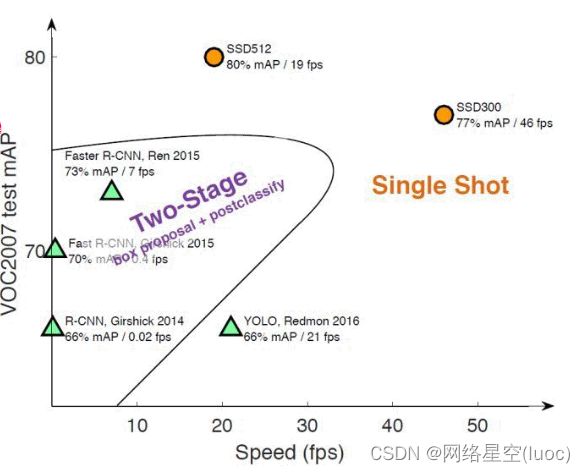
算法的对比图
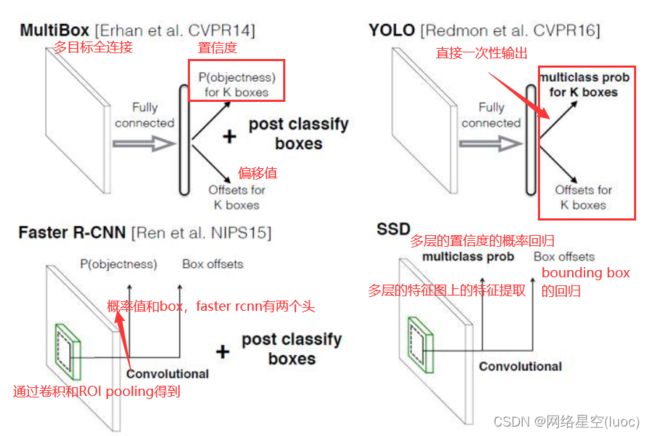
SSD算法概述
输入:3003003的图像。
骨干网络:VGG 16 再加10个卷积层
6个特征图输出: 从骨干网中6个不同深度位置抽取feature map,每个位置的feature map会经过两个输出路线,一个路线feature map经过1个卷积层,直接输出4或6个anchor框的坐标回归信息。另一个路线feature map经过1个卷积层,直接输出4或6个anchor框的21个目标类别(20类+背景类)的置信度。
最终输出:将6个尺度的output结果统一送入NMS中,得到唯一预测框。
优缺点
优点: 相对同年代的YOLO1,使用多尺度特征进行目标检测,极大提高精度。
缺点: SSD的缺点是对小尺寸的目标识别仍比较差,还达不到Faster R-CNN的水准。这主要是因为小尺寸的目标多用较低层级的anchor来训练(因为小尺寸目标在较低层级IOU较大),较低层级的特征非线性程度不够,无法训练到足够的精确度。
主干网络
其主干网络为做了一些改动的VGG net
正负样本选择:
anchor预测框与GT框IOU>0.5,视为候选正样本,其他均为候选负样本(数量极为庞大)。
SSD中候选正样本和候选负样本转正的条件,以及如何确保1:3正负样本比例:
举例:假设在这 8732 个 default box 里,经过 FindMatches 后得到候选正样本 P 个,候选负样本那就有 8732−P个。将 prior box(预测框) 的 prediction loss (类别损失值)按照从大到小顺序排列后选择最高的 M个 prior box。如果这 P 个候选正样本里有 a 个不在这 M 个 prior box 里(说明这a个预测框损失小,与GT框很接近,不需要再让网络去学习了),将这 a个 box 从候选正样本集中踢出去。如果这 8732−P个候选负样本集中有 b个在这 M 个 prior box(说明这b个预测框损失大,与GT框差距大,属于困难的负样本),则将这b个候选负样本作为正式负样本。即删除易识别的正样本,同时留下典型的负样本,组成1:3的prior boxes样本集合。
其他细节
SSD中,为什么只有conv4_3层做归一化?
损失函数计算中,variance参数有什么作用?
上面总结好了,下面来分析一下它的特点:
一,重用了faster rcnn的锚点框机制。
在featuremap上提取各种不同尺度大小的defaultbox,也就是类似Anchor的一系列大小固定的框。不同featuremap上尺度是一样的。
二,为什么要这样多尺度特征图预测?
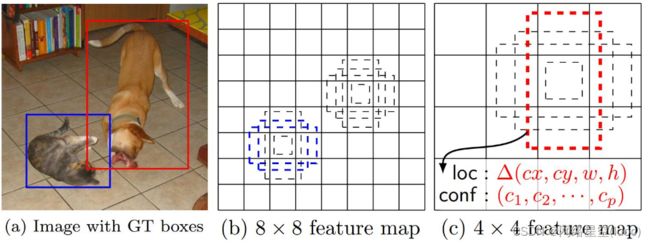
因为小物体在感受野小的大特征图上容易检测目标,反之,小的特征图,它的感受野大,检测大物体有利。
上图举了个某一层特征图的例子,该层每个锚点设置4个锚点框,loc为坐标偏移值,conf为类别的置信度,所以针对于每个锚框会得到20+1+4个预测值
三,全卷积网络结构(Convolutionalpredictorsfordetection)
•结合RFCN网络的优点,将所有的全连接网络全部更改为全卷积网络结构。
•使用卷积来提取候选框特征(offsetbox+score)。
特别注意:当你设置的特征图上的锚点还原到原图上的时候,要以特征图上的锚点的坐标下采样的倍数+下采样的倍数/2,这样是为了防止你的锚点的坐标如果是(0,0),直接下采样倍数还是(0,0)
下图是关于锚点和锚点框的计算:
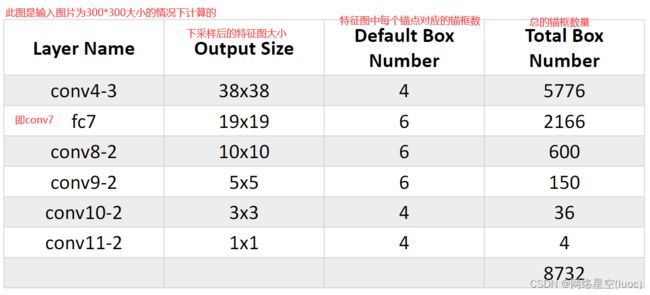
我把开局第一张图分成了三部分,如图
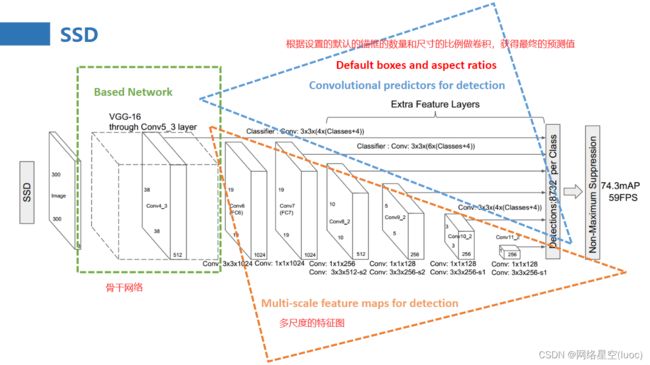
接下来说一说基于VGG网络做的具体的改动:
1.基础网络结构使用VGG,并且将FC6Layer和FC7Layer转换为卷积层,并将原来的MaxPooling5的大小从2x2-s2变化为3x3-s1(没有像原来一样做下采样,这样相当于做了一个特征的融合),这样pooling5操作后featuremap还是保持较大的尺寸,这样就会导致之后的感受野变小,也就是一个点对应到原始图形中的区域变小了。
2.为了保障感受野以及利用到原来的FC6和FC7的模型参数,使用atrousalgorithm的方式来增大感受野,也就是膨胀卷积/空洞卷积。(上图中fc6到fc7做了膨胀卷积)
膨胀卷积:为了增大感受野,但是又不想增加参数量时,在卷积核内部填充0,即可达到目的,如下图。但是会有一些信息损失。

膨胀卷积核尺寸=膨胀系数(原始卷积核尺寸-1)+1*
•Conv6(fc6)中卷积核kernel为3,pad为6,dilation为6,所以相当于真实的卷积核大小为13,pad为6是为了保障输出featuremap大小尺度不变,仍为19x19。
•膨胀卷积(DilatedConvolution)的存在是为了解决一下几个问题的:
•普通的数据上采样层参数不可学习;
•内部数据结构丢失,空间层级化信息丢失;
•小物体信息无法重建。
•TensorFlow中膨胀卷积/空洞卷积API:•tf.nn.atrous_conv2d(value,filters,rate,padding,name=None)
一些提取框框的解说:
•在基础网络之后,使用不同层次卷积的featuremap来分别提取defaultbox,对于每个layer的featuremap使用两个并行的3x3卷积分别来提取位置信息(offsetbox)和置信度信息;结合Defaultbox和GroundTruthbox构建损失函数。
•对于Con4_3的数据提取的时候,会先对featuremap做一个L2 norm的操作(在进行3*3卷积进行预测前),因为层次比较靠前,防止出现数据值过大的情况。
在CNN网络中,层次越深,featuremap的尺寸(size)会越来越小,这样设计主要是为了以下两个目的:
•减少计算与内存的需求;
•最终提取的featuremap在某种程度上具备平移和尺度不变性,契合分类的业务场景要求。
•在目标检测场景中,经常需要处理不同尺度的物体,在某些网络中,会通过将图像转换为不同尺度大小的图像独立的通过网络处理,然后将这些不同尺度的图像结果合并,但是实际上,在同一个网络中,对不同层次上的featuremaps进行特征的处理实际上效果是一样的,并且所有尺度的物体处理参数是共享的,计算会更快。
一些结构的细节:
SSD结构中,defaultboxes不需要和每一层layer的receptivefields对应,通过产生不同scale大小的boxes来负责图像中特定区域以及物体的特定尺寸。
下面我们来谈一谈先验框的大小是如何计算的:
在提取先验框的时候,主要通过尺度(大小)和长宽比两个方面来进行设置,其中在先验框尺度上遵守一个线性递增规则:随着特征图大小降低,先验框尺度线性增加。
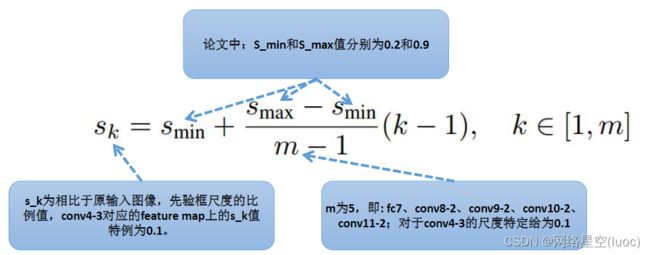
对应到我们这里就是下图,这五层的先验框的大小相对于原图的比例是从0.2到0.9不等。
 下图是该网络计算好的先验框大小:
下图是该网络计算好的先验框大小:

计算好大小后还要计算它们的宽高的比例:
在提取先验框的时候,主要通过尺度(大小)和长宽比两个方面来进行设置,在长宽比上,论文中建议比率值选择范围为:[1,2,3,1/2,1/3]。对于Conv4-3、Conv10-2以及Conv11-2这三层,由于仅使用4个先验框,不使用1:3和3:1的这个比例值。

除了使用上述5个长宽比外,还引入一个特殊尺度并且长宽比为1的先验框。引入这个框的主要目的是为了体现最终的候选框中出现两个长宽比为1但是大小不同的正方形先验框。

最后计算得到所有的先验框大小:

来看一下正负样本的组成:

HardNegativeMining(难负样本挖掘):
•在生成先验框后,会产生很多符合GroundTruthBox的先验框,但是不符合的边框会更多,也就是negativeboxes的数目远多于positiveboxes的数目,也就会导致数据之间极度不均衡的情况出现,训练的时候比较难收敛。故在SSD中,采用R-CNN中介绍的难负样本挖掘算法对数据进行处理。将每个物体位置上对应的defaultboxes是negative的boxes按照前向loss的大小进行排序,获取loss比较大的N个negativeboxes参与模型训练,最终保证正负样本比例在1:3左右。
然后还做了数据增强:
•水平翻转(HorizontalFlip)
•随机剪裁加颜色扭曲(RandomCrop&ColorDistortion)
•随机采集块域(Randomlysampleapath)
训练数据类别给定标准:
•正样本:若先验框和GroundTruth框匹配,那么认为当前先验框为正样本;
•负样本:若先验框和所有GroundTruth框都不匹配,那么认为当前先验框为负样本。
•NOTE:采用hardnegativemining(难负样本挖掘算法)选择loss大的样本作为负样本,正负样本比例1:3;
SSD的先验框与GroundTruth的匹配原则主要有几点:
•1.对于图片中每个GroundTruth,找到与其IoU最大的先验框,该先验框与其匹配,
•2.对于剩余的未匹配先验框,若其和某个GroundTruth的IoU大于某个阈值(一般是0.5),那么该先验框也与这个GroundTruth(选择最大IoU的GT框)进行匹配。这意味着某个GroundTruth可能与多个先验框匹配,这是可以的。
•3.如果某个先验框和多个GroundTruth的IoU值大于阈值或者是最大IoU的先验框,那么这个先验框仅和IoU最大的那个GroundTruth匹配。
终于写到最后了…
损失函数
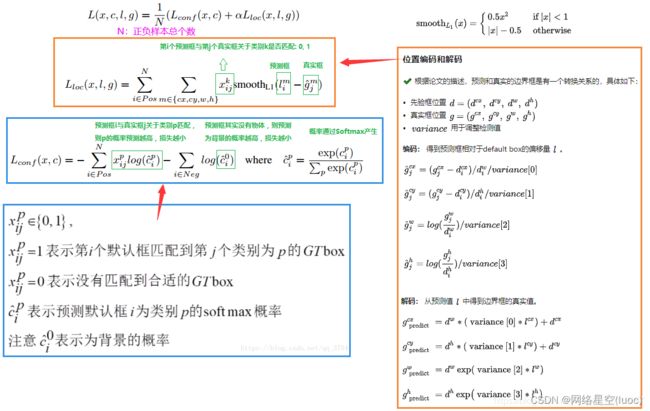
在SSD中,损失函数被定义为位置误差(locatizationloss,loc)与置信度误差(confidenceloss,conf)的加权和


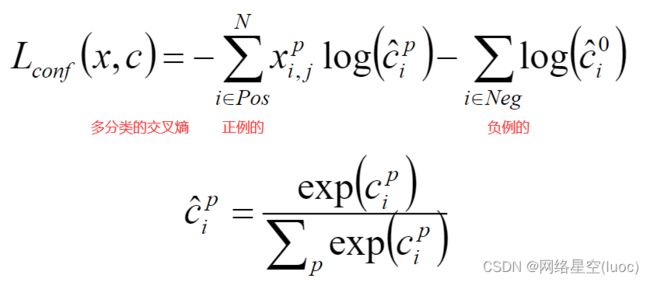

class MultiBoxLoss(nn.Module):
"""
多盒损耗,一种用于目标检测的损耗函数。
这是以下各项的组合:
(1) 盒子预测位置的本地化损失,
(2) 预测的班级分数的置信度损失。
"""
def __init__(self, priors_cxcy, threshold=0.5, neg_pos_ratio=3, alpha=1.):
super(MultiBoxLoss, self).__init__()
self.priors_cxcy = priors_cxcy # 8732个预选框
# 将边界框从中心尺寸坐标 (c_x, c_y, w, h) 转换为边界坐标 (x_min, y_min, x_max, y_max)
self.priors_xy = cxcy_to_xy(priors_cxcy)
self.threshold = threshold
self.neg_pos_ratio = neg_pos_ratio
self.alpha = alpha
self.smooth_l1 = nn.L1Loss()
self.cross_entropy = nn.CrossEntropyLoss(reduce=False)
def forward(self, predicted_locs, predicted_scores, boxes, labels): # (N, 8732, 4) (N, 8732, n_classes)
"""
Forward propagation.
:param predicted_locs: 预测位置/方框w.r.t 8732之前的方框,尺寸张量(N,8732,4)
:param predicted_scores: 每个编码位置/框的类别分数,维度张量(N,8732,N\u类)
:param boxes: 边界坐标中的真实对象边界框,N个张量的列表
:param labels: 真对象标签,N个张量的列表
:return: multibox loss, 标量
"""
batch_size = predicted_locs.size(0) # 该方法返回的是当前张量的形状,返回值是元组tuple的一个子类.
n_priors = self.priors_cxcy.size(0) # 8732个预选框
n_classes = predicted_scores.size(2) # tuple的第三个元素
assert n_priors == predicted_locs.size(1) == predicted_scores.size(1)
true_locs = torch.zeros((batch_size, n_priors, 4), dtype=torch.float).to(device) # (N, 8732, 4)
true_classes = torch.zeros((batch_size, n_priors), dtype=torch.long).to(device) # (N, 8732, n_classes)
# For each image
for i in range(batch_size):
n_objects = boxes[i].size(0)
# 计算IOU
overlap = find_jaccard_overlap(boxes[i],
self.priors_xy) # (n_objects, 8732)
# 对于每个先验,找到重叠最大的对象
overlap_for_each_prior, object_for_each_prior = overlap.max(dim=0) # (8732) # 先验框IOU值, 先验框中物体
# 我们不希望出现这样的情况,即在我们的正(非背景)先验中没有表示对象
# 1. 对象可能不是所有优先级的最佳对象,因此不在object_for_each_prior中。
# 2. 基于阈值(0.5),可以将对象的所有先验值指定为背景。
# 要解决这个问题-
# 首先,找到每个对象重叠最大的先验框。
_, prior_for_each_object = overlap.max(dim=1) # (n_objects) # 每个对象重叠最大的先验框, 总共n_objects个对象
# 然后,将每个对象指定给相应的最大重叠优先级。(这修复了1。)
object_for_each_prior[prior_for_each_object] = torch.LongTensor(range(n_objects)).to(device) # 对象
# 为了确保这些优先级符合要求,人为地给它们一个大于0.5的重叠。(这修复了2个。)
overlap_for_each_prior[prior_for_each_object] = 1. # IOU
# 每个之前的标签
label_for_each_prior = labels[i][object_for_each_prior] # (8732)
# 将与对象重叠小于阈值的优先级设置为背景(无对象)
label_for_each_prior[overlap_for_each_prior < self.threshold] = 0 # (8732)
# 存储
true_classes[i] = label_for_each_prior
# 将中心大小的对象坐标编码为我们将预测框回归到的形式
true_locs[i] = cxcy_to_gcxgcy(xy_to_cxcy(boxes[i][object_for_each_prior]), self.priors_cxcy) # (8732, 4)
# 确定积极的先验知识(对象/非背景)
positive_priors = true_classes != 0 # (N, 8732)
# 本地化损失
# 仅在正(非背景)先验条件下计算定位损失
loc_loss = self.smooth_l1(predicted_locs[positive_priors], true_locs[positive_priors]) # (), scalar
# Note: indexing with a torch.uint8 (byte) tensor flattens the tensor when indexing is across multiple dimensions (N & 8732)
# So, if predicted_locs has the shape (N, 8732, 4), predicted_locs[positive_priors] will have (total positives, 4)
# CONFIDENCE LOSS
# Confidence loss is computed over positive priors and the most difficult (hardest) negative priors in each image
# That is, FOR EACH IMAGE,
# we will take the hardest (neg_pos_ratio * n_positives) negative priors, i.e where there is maximum loss
# This is called Hard Negative Mining - it concentrates on hardest negatives in each image, and also minimizes pos/neg imbalance
# Number of positive and hard-negative priors per image
# 注意:使用torch.uint8(字节)张量进行索引时,当索引跨多个维度(N&8732)时,张量会变平
# 所以,如果 predict_locs 的形状为 (N, 8732, 4),则 predict_locs[positive_priors] 将有 (total positives, 4)
# 信心损失
# 置信度损失是在每个图像中的正先验和最困难(最难)的负先验上计算的
# 也就是说,对于每个图像,
# 我们将采用最困难的 (neg_pos_ratio * n_positives) 负先验,即损失最大的地方
# 这称为 Hard Negative Mining - 它专注于每张图像中最难的负片,并最大限度地减少 pos/neg 不平衡
# 每张图像的正面和硬负面先验数量
n_positives = positive_priors.sum(dim=1) # (N)
n_hard_negatives = self.neg_pos_ratio * n_positives # (N)
# 首先,找出所有先验框的损失
conf_loss_all = self.cross_entropy(predicted_scores.view(-1, n_classes), true_classes.view(-1)) # (N * 8732)
conf_loss_all = conf_loss_all.view(batch_size, n_priors) # (N, 8732)
# 我们已经知道哪些先验知识是积极的
conf_loss_pos = conf_loss_all[positive_priors] # (sum(n_positives))
# Next, find which priors are hard-negative
# To do this, sort ONLY negative priors in each image in order of decreasing loss and take top n_hard_negatives
# 接下来,找出哪些先验知识是硬负的
# 要做到这一点,请仅对每张图像中的负片优先级进行排序,以减少损失,并取前 n_hard_negatives
conf_loss_neg = conf_loss_all.clone() # (N, 8732)
conf_loss_neg[positive_priors] = 0. # (N, 8732), positive priors are ignored (never in top n_hard_negatives)
conf_loss_neg, _ = conf_loss_neg.sort(dim=1, descending=True) # (N, 8732), sorted by decreasing hardness
hardness_ranks = torch.LongTensor(range(n_priors)).unsqueeze(0).expand_as(conf_loss_neg).to(device) # (N, 8732)
hard_negatives = hardness_ranks < n_hard_negatives.unsqueeze(1) # (N, 8732)
conf_loss_hard_neg = conf_loss_neg[hard_negatives] # (sum(n_hard_negatives))
# 如论文中所述,仅对正先验进行平均,尽管对正先验和硬负先验均进行了计算
conf_loss = (conf_loss_hard_neg.sum() + conf_loss_pos.sum()) / n_positives.sum().float() # (), scalar
# TOTAL LOSS
return conf_loss + self.alpha * loc_loss
预测过程
对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据DefaultBox先验框+offsetbox偏移量预测值做线性转换得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
最后一张与faster rcnn的效果对比图结束本场解说: