python进阶(异常处理,文件操作)
python进阶
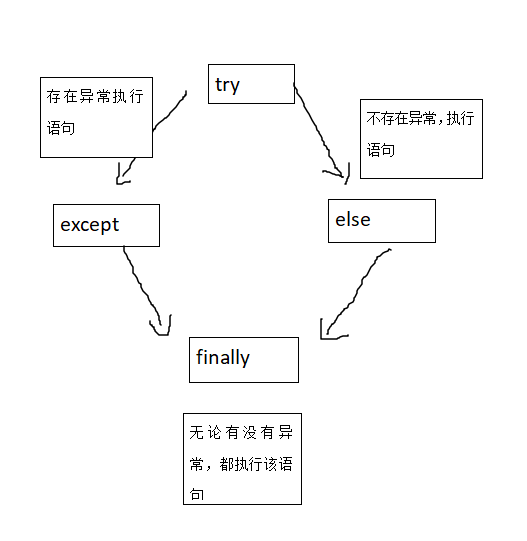
异常处理机制
try...except
try...except...else**结构**(发生异常的执行情况(执行 except 块,没有执行 else ))
try...except...finally**结构**
finally 块无论是否发生异常都会被执行;通常用来释放 try 块中申请的资源
with上下文管理
with open(r"a.txt","a", encoding="utf-8") as f:
s = "itbaizhan\nsxt\n"
f.write(s)
#traceback模块和生成异常日志
import traceback
try:
print("step1")
num = 1/0
except:
#traceback.print_exc()
with open("d:/a.log","a") as f:
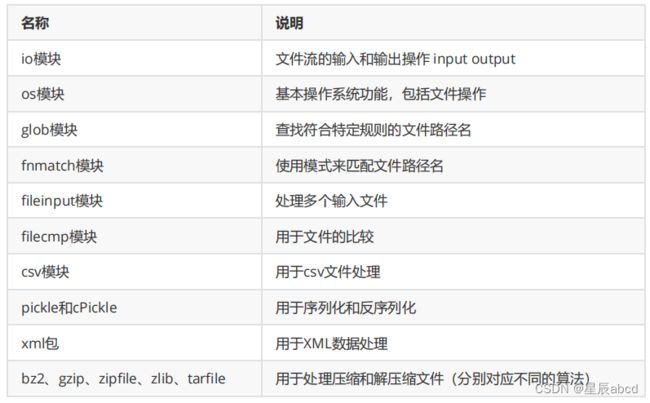
traceback.print_exc(file=f)文件操作
文件操作相关模块
文本文件的读取
1、read([size])
从文件中读取 size 个字符,并作为结果返回。如果没有 size 参数,则读取整个文件。读取到文件末尾,会返回空字符串。
2 、readline()
读取一行内容作为结果返回。读取到文件末尾,会返回空字符串
3 、readlines()
文本文件中,每一行作为一个字符串存入列表中,返回该列表
# 字符长度读取
with open('aa.txt', "r") as f:
a = f.read(10)
print(a)
# 行数读取
with open("bb.txt", "r") as f:
while True:
data = f.readline()
if not data:
break
else:
print(data,end=" ")
# 迭代读取
with open('cc.txt', 'r') as f:
for i in f:
print(i)文本文件的写入
1、write(a) :把字符串 a 写入到文件中
2、writelines(b) :把字符串列表b写入文件中,不添加换行符
with open("算法与数据结构/a.txt", "w", encoding="utf-8") as f:
f.write("lz")
# 不换行
a = ['lz\n', 'zp\n', 'zms\n']
f.writelines(a)#将对象序列化到文件中
import pickle
with open("./data.dat","wb") as f:
name = "lz"
age = 34
score = [90,80,70]
resume ={'name':name,'age':age,'score':score}
pickle.dump(resume,f)
#将获得的数据反序列化成对象
import pickle
with open("data.dat","rb") as f:
resume = pickle.load(f)
print(resume)csv文件操作
# csv的读取
import csv
with open("d:/a.csv") as a:
a_csv = csv.reader(a) #创建csv对象, 它是一个包含所有数据的列表,每一行为一个元素
headers = next(a_csv) #获得列表对象,包含标题行的信息
print(headers)
for row in a_csv: #循环打印各行内容
print(row)
# csv的写入
import csv
headers = ["工号","姓名","年龄","地址","月薪"]
rows = [("1001","lz",18,"西三旗1号院","50000"), ("1002","zp",19,"西三旗2号院","30000")]
with open("d:/b.csv", "w") as b:
b_csv = csv.writer(b) #创建csv对象
b_csv.writerow(headers) #写入一行(标题)
b_csv.writerows(rows) #写入多行(数据)
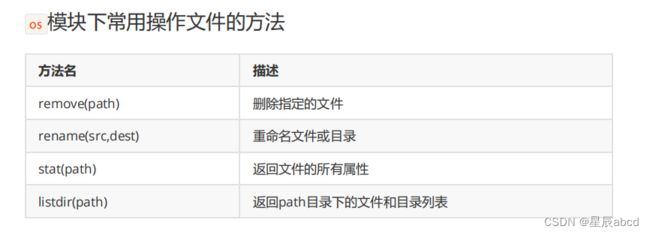
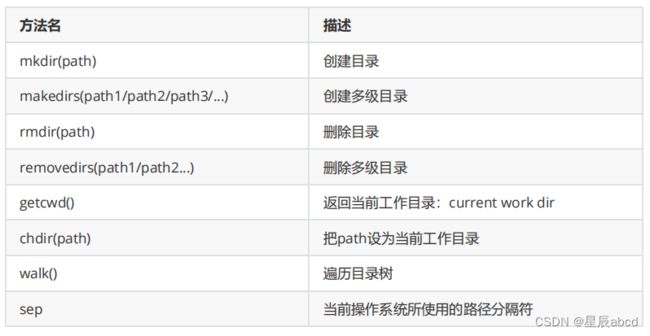
os和os.path模块
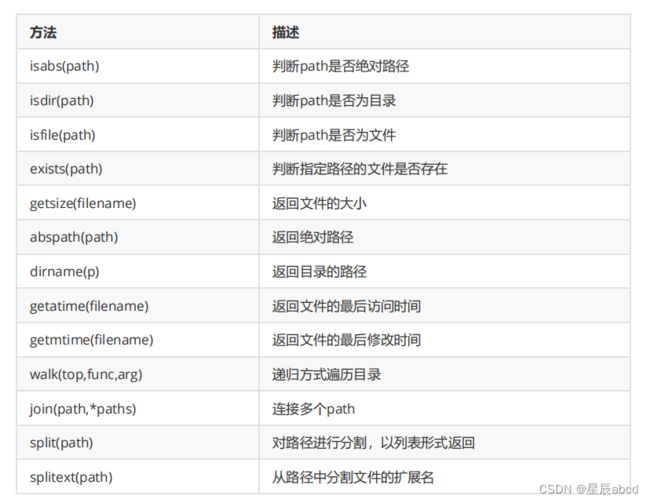
"""
os.walk() 方法是一个简单易用的文件、目录遍历器,可以帮助我们高
效的处理文件、目录方面的事情。格式如下:
os.walk(top[, topdown=True[, onerror=None[, followlinks=False]]])
其中, top :是要遍历的目录。 topdown :可选, True ,先遍历 top 目录
再遍历子目录。
返回三元组( root 、 dirs 、 files ):
"""
#root :当前正在遍历的文件夹本身
#dirs :一个列表,该文件夹中所有的目录的名字
#files :一个列表,该文件夹中所有的文件的名字
#测试os.walk()
import os
#返回工作环境根目录
path = os.getcwd()
list_files = os.walk(path,topdown=False)
for root,dirs,files in list_files:
for name in files:
print(os.path.join(root,name))
for name in dirs:
print(os.path.join(root,name))遍历一个文件夹下的所有文件
import os
import os.path
#递归遍历目录树
def my_print_file(path,level):
child_files = os.listdir(path)
for file in child_files:
file_path = os.path.join(path,file)
print("\t"*level+file_path[file_path.rfind(os.sep)+1:])
if os.path.isdir(file_path):
my_print_file(file_path,level+1)
my_print_file("./阶段一",0)ps:python进阶深入学习,异常处理流程和文件操作