python(并发编程,网络编程,函数编程)
并发编程
进程、线程、协程的区别
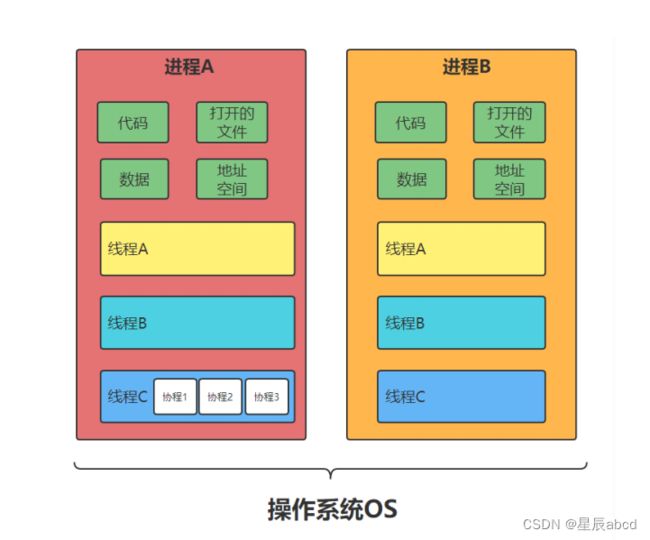
进程(Process):拥有自己独立的堆和栈,既不共享堆,也不共享栈,进程由操作系统调度;进程切换需要的资源很最大,效率低
线程(Thread):拥有自己独立的栈和共享的堆,共享堆,不共享栈,标准线程由操作系统调度;线程切换需要的资源一般,效率一般(当然了在不考虑GIL的情况下)
协程(coroutine):拥有自己独立的栈和共享的堆,共享堆,不共享栈,协程由程序员在协程的代码里显示调度;协程切换任务资源很小,效率高
线程的创建方式
#方法包装
#encoding=utf-8
#方法方式创建线程
from threading import Thread
from time import sleep
def func1(name):
for i in range(3):
print(f"thread:{name} :{i}")
sleep(1)
if __name__ == '__main__':
print("主线程,start")
#创建线程
t1 = Thread(target=func1,args=("t1",))
t2 = Thread(target=func1,args=("t2",))
#启动线程
t1.start()
t2.start()
print("主线程,end")
#类包装
#encoding=utf-8
#类的方式创建线程
from threading import Thread
from time import sleep
class MyThread(Thread):
def __init__(self,name):
Thread.__init__(self)
self.name =name
def run(self):
for i in range(3):
print(f"thread:{self.name} :{i}")
sleep(1)
if __name__ == '__main__':
print("主线程,start")
#创建线程(类的方式)
t1 = MyThread('t1')
t2 = MyThread('t2')
#启动线程
t1.start()
t2.start()
t1.join() #守护线程
t2.join()
print("主线程,end")全局锁GIL(Global Interpreter Lock)问题
#多线程操作同一个对象(未使用线程同步)
'''Python代码的执行由Python 虚拟机(也叫解释器主循环,CPython
版本)来控制,Python 在设计之初就考虑到要在解释器的主循环
中,同时只有一个线程在执行,即在任意时刻,只有一个线程在解
释器中运行。对Python 虚拟机的访问由全局解释器锁(GIL)来控
制,正是这个锁能保证同一时刻只有一个线程在运行'''#锁机制
'''
1 必须使用同一个锁对象
2 互斥锁的作用就是保证同一时刻只能有一个线程去操作共享数据,保证共享数据不会出现错误问题
3 使用互斥锁的好处确保某段关键代码只能由一个线程从头到尾完整地去执行
4 使用互斥锁会影响代码的执行效率
5 同时持有多把锁,容易出现死锁的情况
'''
# 线程冲突案例不加同步与互斥锁
from threading import Thread, Lock
from time import sleep
class Account:
"""创建了一个账户类"""
def __init__(self, money, name):
self.name = name
self.money = money
# 模拟取钱操作
class Drawing(Thread):
"""创建一个取钱类"""
def __init__(self, drawing_num, account):
Thread.__init__(self)
self.drawing_num = drawing_num
self.account = account
self.expenseTotal = 0
def run(self):
lock1.acquire() # 设置锁
if self.account.money < self.drawing_num:
print('账户余额不足')
return
sleep(1)
self.account.money -= self.drawing_num
self.expenseTotal += self.drawing_num
lock1.release() # 释放锁
print(f'账户:{self.account.name},余额:{self.account.money}')
print(f'账户:{self.account.name},取了:{self.expenseTotal}')
if __name__ == '__main__':
a = Account(100, 'lz')
lock1 = Lock() # 创建锁
t1 = Drawing(80, a)
t2 = Drawing(80, a)
t1.start()
t2.start()
'''
acquire 和 release 方法之间的代码同一时刻只能有一个线程去操作
如果在调用 acquire 方法的时候 其他线程已经使用了这个互斥锁,那么此时 acquire 方法会
堵塞,直到这个互斥锁释放后才能再次上锁。
'''
#锁同一时间只允许一个对象(进程)通过,信号量同一时间允许多个对象(进程)通过
# 信号量的使用案例
from threading import Semaphore, Thread
from time import sleep
def home(name, se):
se.acquire()
print(f'{name}进入了房间')
sleep(2)
print(f'{name}出去了房间')
se.release()
if __name__ == '__main__':
se = Semaphore(5)
for i in range(7):
t = Thread(target=home, args=(f'tom{i}', se))
t.start()
#事件的使用
# Event的使用
# 模拟吃火锅
from threading import Thread, Event
from time import sleep
def eat_hg(name):
# 等待事件,线程进入堵塞状态
print(f'{name}入席了')
print(f'{name}准备好开吃了')
event.wait()
sleep(2)
# 收到事件后执行的任务进入运行状态
print(f'{name}收到通知了')
print(f'{name}已经开吃了')
if __name__ == '__main__':
event = Event()
t = Thread(target=eat_hg, args=('tom',))
s = Thread(target=eat_hg, args=('cherry',))
t.start()
s.start()
# 发送事件通知
sleep(5)
print('收到主人通知')
event.set()
# 生产者消费者模式
# 生产者 缓冲区 消费者
from queue import Queue #使用队列创建缓冲区
from threading import Thread
from time import sleep
def producer():
num = 1
while True:
if queue.qsize() < 5:
print(f'生产{num}号大馒头')
queue.put(f'大馒头:{num}号')
num += 1
else:
print('满了,等待消费')
sleep(1)
def consumer():
while True:
print(f'获取馒头{queue.get()}')
sleep(1)
if __name__ == '__main__':
queue = Queue()
t1 = Thread(target=producer)
t2 = Thread(target=consumer)
t1.start()
t2.start()进程Process
#方法包装 类包装(继承Process)
from multiprocessing import Process
from time import sleep
import os
def func1(name):
print(f'当前进程func1的id:{os.getpid()}')
print(f'当前进程的父进程的id:{os.getppid()}')
print(f'当前进程的名字:{name} start')
sleep(3)
print(f'当前进程的名字:{name} end')
if __name__ == '__main__':
print(f'main进程的id:{os.getpid()}')
p1 = Process(target=func1, args=('p1',))
p2 = Process(target=func1, args=('p2',))
p1.start()
p2.start()
# 进程管道通信Pipe
import multiprocessing
from time import sleep
def func1(conn1):
sub_info = "Hello!"
print(f"进程1--{multiprocessing.current_process().pid}发送数据:{sub_info}")
sleep(1)
conn1.send(sub_info)
print(f"来自进程2:{conn1.recv()}")
sleep(1)
def func2(conn2):
sub_info = "你好!"
print(f"进程2--{multiprocessing.current_process().pid}发送数据:{sub_info}")
sleep(1)
conn2.send(sub_info)
print(f"来自进程1:{conn2.recv()}")
sleep(1)
if __name__ == '__main__':
# 创建管道
conn1, conn2 = multiprocessing.Pipe()
# 创建子进程
process1 = multiprocessing.Process(target=func1, args=(conn1,))
process2 = multiprocessing.Process(target=func2, args=(conn2,))
# 启动子进程
process1.start()
process2.start()
# Manager 管理器
from multiprocessing import Process,current_process
from multiprocessing import Manager
def func(name,m_list,m_dict):
m_dict['name'] = 'lz'
m_list.append('你好')
if __name__ == "__main__":
with Manager() as mgr:
m_list = mgr.list()
m_dict = mgr.dict()
m_list.append('Hello!!')
#两个进程不能直接互相使用对象,需要互相传递
p1 = Process(target=func,args=('p1', m_list, m_dict))
p1.start()
p1.join() #等p1进程结束,主进程继续执行
print(m_list)
print(m_dict)进程池
#with管理进程池
#coding=utf-8
from multiprocessing import Pool
import os
from time import sleep
def func1(name):
print(f"当前进程的ID:{os.getpid()}, {name}")
sleep(2)
return name
if __name__ == "__main__":
with Pool(5) as pool:
args = pool.map(func1, ('lz1,','lz2,','lz3,','lz4,','lz5,','lz6,','lz7,','lz8,'))
for a in args:
print(a)协程Coroutines
#协程使用异步函数实现
import asyncio
import time
async def func1(): #async表示方法是异步的
for i in range(3):
print(f'北京:第{i}次打印啦')
await asyncio.sleep(1)
return "func1执行完毕"
async def func2():
for k in range(3):
print(f'上海:第{k}次打印了' )
await asyncio.sleep(1)
return "func2执行完毕"
async def main():
res = await asyncio.gather(func1(),func2())
#await异步执行func1方法
#返回值为函数的返回值列表,本例为["func1执行完毕", "func2执行完毕"]
print(res)
if __name__ == '__main__':
start_time = time.time()
asyncio.run(main())
end_time = time.time()
print(f"耗时{end_time-start_time}") #耗时3秒,效率极大提高线程和进程的区别
1、线程共享本进程的地址空间,而进程之间是独立的地址空间
2、线程共享本进程的资源如内存、I/O、cpu等,不利于资源的管理和保护,而进程之间的资源是独立的,能很好的进行资源管理和保护
3、多进程要比多线程健壮,一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉
4、每个独立的进程有一个程序运行的入口、顺序执行序列和程序入口,执行开销大。但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,执行开销小
5、线程是处理器调度的基本单位,但是进程不是
6、进程切换时,消耗的资源大,效率高。所以涉及到频繁的切换时,使用线程要好于进程。同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程
网络编程

TCP(Transmission Control Protocol,传输控制协议)面向连接的,传输数据安全,稳定,效率相对较低。
UDP(User Data Protocol,用户数据报协议)是面向无连接的,传输数据不安全,效率较高。
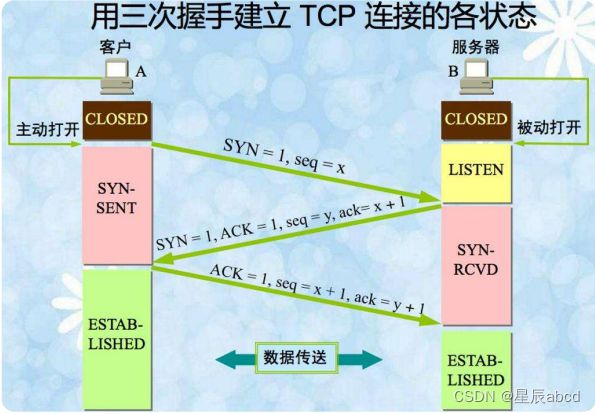
TCP的三次握手
第一步,客户端发送一个包含SYN即同步(Synchronize)标志的TCP报文,SYN同步报文会指明客户端使用的端口以及TCP连接的初始序号。
第二步,服务器在收到客户端的SYN报文后,将返回一个SYN+ACK的报文,表示客户端的请求被接受,同时TCP序号被加一,ACK即确认(Acknowledgement)
第三步,客户端也返回一个确认报文ACK给服务器端,同样TCP序列号被加一,到此一个TCP连接完成。然后才开始通信的第二步:数据处理。
TCP的四次挥手
第一次: 当主机A完成数据传输后,将控制位FIN置1,提出停止TCP连接的请求 ;
第二次: 主机B收到FIN后对其作出响应,确认这一方向上的TCP连接将关闭,将ACK置1;
第三次: 由B 端再提出反方向的关闭请求,将FIN置1 ;
第四次: 主机A对主机B的请求进行确认,将ACK置1,双方向的关闭结束.。
socket对象的内置函数和属性



UDP编程的实现
# UDP接受数据
from socket import *
# 最简单的UDP服务器代码
s = socket(AF_INET, SOCK_DGRAM) # 创建UDP类型的套接字
s.bind(('127.0.0.1', 8888)) # 绑定端口,ip可以不写
print('等待接受数据....')
recv_data = s.recvfrom(1024) # 接受最大字节数 ([0]信息,[1]元组发送方的套接字(ip,port))
print(recv_data)
print(f'收到远程信息:{recv_data[0].decode("gbk")},from{recv_data[1]}')
s.close()
# UDP发送数据 持续通信加循环
from socket import *
# 最简单的UDP服务器代码
s = socket(AF_INET, SOCK_DGRAM) # 创建UDP类型的套接字
address = ('127.0.0.1', 8888) # 准备接受数据的地址
data = input('please input data:')
# 发送数据时要将数据转换成二进制流
s.sendto(data.encode('gbk'), address) # 默认编码为gbk模式
s.close()# 实现UDP双向持续通信
from threading import Thread
from socket import *
def recv_data():
while True:
rec_data = s.recvfrom(1024) # 接受最大字节数 ([0]信息,[1]元组发送方的套接字(ip,port))
recv_content = rec_data[0].decode("gbk")
print(f'\n收到远程信息:{recv_content},from{rec_data[1]}')
if recv_content == '88':
print('结束聊天!')
break
def send_data():
while True:
address = ('127.0.0.1', 9999) # 准备接受数据的地址
data = input('please input data:')
# 发送数据时要将数据转换成二进制流
s.sendto(data.encode('gbk'), address) # 默认编码为gbk模式
if data == '88':
print('结束聊天!')
break
if __name__ == '__main__':
s = socket(AF_INET, SOCK_DGRAM)
s.bind(('127.0.0.1', 8888))
t1 = Thread(target=recv_data)
t2 = Thread(target=send_data)
t1.start()
t2.start()
t1.join()
t1.join()
# 实现UDP双向持续通信
from threading import Thread
from socket import *
def recv_data():
while True:
rec_data = s.recvfrom(1024) # 接受最大字节数 ([0]信息,[1]元组发送方的套接字(ip,port))
recv_content = rec_data[0].decode("gbk")
print(f'\n收到远程信息:{recv_content},from{rec_data[1]}')
if recv_content == '88':
print('结束聊天!')
break
def send_data():
while True:
address = ('127.0.0.1', 8888) # 准备接受数据的地址
data = input('please input data:')
# 发送数据时要将数据转换成二进制流
s.sendto(data.encode('gbk'), address) # 默认编码为gbk模式
if data == '88':
print('结束聊天!')
break
if __name__ == '__main__':
s = socket(AF_INET, SOCK_DGRAM)
s.bind(('127.0.0.1', 9999))
t1 = Thread(target=recv_data)
t2 = Thread(target=send_data)
t1.start()
t2.start()
t1.join()
t1.join()TCP编程的实现
#使用多线程实现无限制收发信息
#服务端
from socket import *
from threading import Thread
def recv_data():
while True:
rec_data = c_socket.recv(1024)
data = rec_data.decode('gbk')
print(f'收到客户端信息:{data},来自:{c_info}')
if data == '88':
print('结束聊天')
break
def send_data():
while True:
msg = input('>')
c_socket.send(msg.encode('gbk'))
if msg == '88':
print('结束聊天!')
break
if __name__ == '__main__':
s = socket(AF_INET, SOCK_STREAM)
s.bind(('127.0.0.1', 8989))
s.listen(5)
print('等待建立连接...')
c_socket, c_info = s.accept()
print('一个客户连接成功')
t1 = Thread(target=recv_data)
t2 = Thread(target=send_data)
t1.start()
t2.start()
t1.join()
t2.join()
c_socket.close()
s.close()
#客户端
from socket import *
from threading import Thread
def recv_data():
while True:
rec_data = s.recv(1024)
data = rec_data.decode('gbk')
print(f'服务器端说:{data}')
if data == '88':
print('结束聊天!')
break
def send_data():
while True:
msg = input('>')
s.send(msg.encode('gbk'))
if msg == '88':
print('结束聊天!')
break
if __name__ == '__main__':
s = socket(AF_INET, SOCK_STREAM)
s.connect(('127.0.0.1', 8989))
t1 = Thread(target=recv_data)
t2 = Thread(target=send_data)
t1.start()
t2.start()
t1.join()
t2.join()
s.close()函数编程
高阶函数(一个函数可以接收另一个函数作为参数)
#lambda表达式和匿名函数
f = lambda a,b,c:a+b+c
print(f)
print(f(2,3,4))
#偏函数
def int2(x, base=2):
return int(x, base)
print(int2('1000000')) #64
print(int2('1010101')) #85
print(int('64', base=8)) #将八进制数64 转换为10进制数52
print(int('111', base=2)) #将二进制数111 转换为10进制数7
#functools.partial 就是帮助我们创建一个偏函数的
import functools
int2 = functools.partial(int, base=2)
print(int2('1000000')) #64
print(int2('1010101')) #85
print(int2('1000000', base=10)) #也可以修改base的值
闭包closure
"""
闭包的特点:
1. 存在内外层函数嵌套的情况
2. 内层函数引用了外层函数的变量或者参数(自由变量)
3. 外层函数把内层的这个函数本身当作返回值进行返回,而不是返回内层函数产生的某个值
局部变量:如果名称绑定再一个代码块中,则为该代码块的局部变量,除非声明为nonlocal
或global
全局变量:如果模块绑定在模块层级,则为全局变量
自由变量:如果变量在一个代码块中被使用但不是在其中定义,则为自由变量
"""
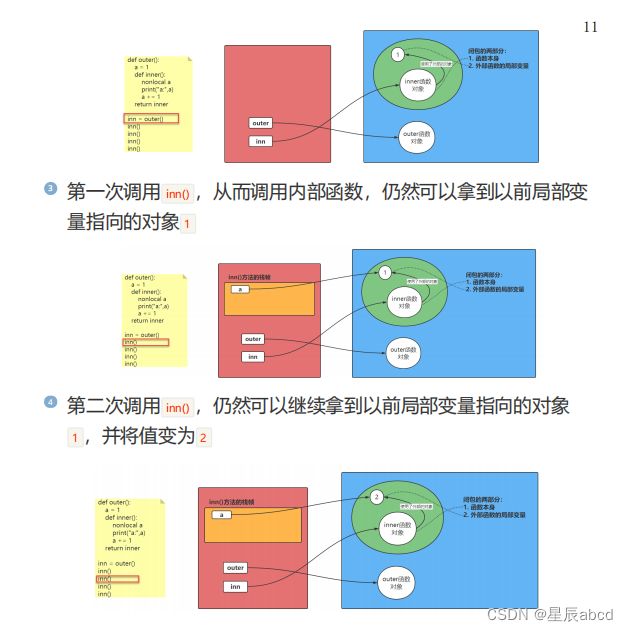
def outer():
a = 1
def inner():
nonlocal a
#闭包是由于函数内部使用了函数外部的变量。这个函数对象不销毁,则外部函数的局部变量也不会被销毁!
print("a:", a)
a += 1
return inner
inn = outer()
inn()
inn()闭包内存分析
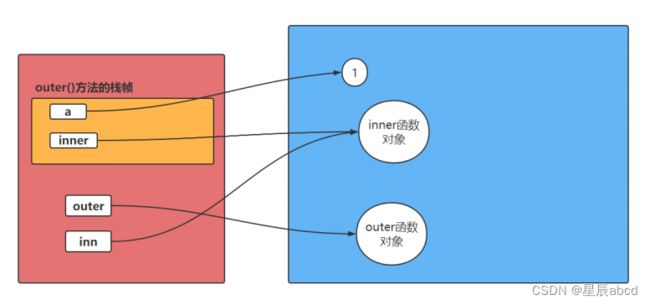
#用闭包实现不修改源码添加功能
# coding=utf-8
# 本次内容,是装饰器的基础
def outfunc(func):
def infunc(*args,**kwargs):
print("日志纪录 start...")
func(*args,**kwargs)
print("日志纪录 end...")
return infunc
def fun1():
print("使用功能1")
def fun2(a,b,c):
print("使用功能2",a,b,c)
print(id(fun1))
fun1 = outfunc(fun1)
print(id(fun1))
fun1()
fun2 = outfunc(fun2)
fun2(100,200,300)函数使用
#map函数
"""
map() 函数接收两种参数,一是函数,一种是序列(可以传入多个序
列),map将传入的函数依次作用到序列的每个元素,并把结果作为
新的list返回
"""
def f(x):
return x * x
L = []
for i in [1, 2, 3, 4, 5, 6, 7, 8, 9]:
L.append(f(i))
print(L)
print('===================')
L=map(f,[1, 2, 3, 4, 5, 6, 7, 8, 9])
print(list(L))
#reduce函数 reduce(f, [x1, x2, x3, x4]) = f(f(f(x1, x2), x3), x4)
from functools import reduce
def add(x, y):
return x + y
sum=reduce(add, [1, 3, 5, 7, 9])
print(sum)
#filter函数
# 在一个list中,删掉偶数,只保留奇数
def is_odd(n):
return n % 2 == 1
L=filter(is_odd, [1, 2, 4, 5])
print(list(L))
#sorted函数
sorter1 = sorted([1,3,6,-20,34])
print("升序排列:",sorter1)
# sorted()函数也是高阶函数,它还可以接收一个key函数来实现自定义的排序
sorter2 = sorted([1,3,6,-20,-70],key=abs)
print("自定义排序:",sorter2)
sorter2 = sorted([1,3,6,-20,-70],key=abs,reverse=True)
print("自定义反向排序:",sorter2)
# 4.2 字符串排序依照ASCII
sorter3 = sorted(["ABC","abc","D","d"])
print("字符串排序:",sorter3)
# 4.3 忽略大小写排序
sorter4 = sorted(["ABC","abc","D","d"],key=str.lower)
print("忽略字符串大小写排序:",sorter4)
# 4.4 要进行反向排序,不必改动key函数,可以传入第三个参数reverse=True:
sorter5 = sorted(["ABC","abc","D","d"], key=str.lower, reverse=True)
print("忽略字符串大小写反向排序:",sorter5)ps:希望对大家有帮助,可以的话给个点赞