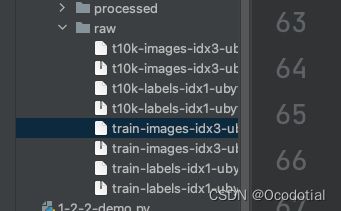
MNIST数据集在Pycharm上读取失败-pytorch入门-问题一
任务:
将MNIST数据集修改后保持,放入CNN训练和测试,任务地址DL-CV-github
构思:
对在线数据集MNIST动手,然后存入本地,再模拟从torchvision下载的数据集流程一样,喂给CNN,进行训练和测试。
遇到的问题
- 这个数据集里面到底长啥样?
- 我能不能对其进行直接修改,然后骗过模型,说我这个是网上下载的?
- 数据集改完了,如果第二个问题是我头脑简单,那么如何存这个改完的数据集?从而如何顺利喂给模型?
解决方法:
首先使用torchvision包老老实实的使用在线下载的MNIST数据集,是这般的丝滑:
# 转换器对象实现了图像预处理功能
transform = transforms.Compose(
[transforms.ToTensor(),
# transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
transforms.Normalize((0.5), (0.5))]
)
# 数据集对象实现了数据加载功能
trainset = torchvision.datasets.MNIST(root='./data',
train=True,
download=True,
transform=transform)
# 加载器对象实现了批量加载数据功能
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=BATCH_SIZE,
shuffle=True,
)
testset = torchvision.datasets.MNIST(root='./data',
train=False,
download=True,
transform=transform)
testloader = torch.utils.data.DataLoader(testset,
batch_size=BATCH_SIZE,
shuffle=False,
)
net = Net()
通过一般花里胡哨的操作后,自定义数据集又是这般:(这里参考了官方文档和其他网友1,网友2-自定义数据集入门强推的文章,然后再按照自己所需去改)
# 文件名;CreateNewSets.py
import os
from PIL import Image
import torch
import numpy as np
from torch.utils.data import DataLoader, Dataset
# 下面两个包是自己定义用来处理打开文件的
from OpenDataSets import open_labels_set, open_images_set
from ModifyImage import modify_image
# 读取标签数据集
path_tra_img = '/Users/pengchen/workspace/PytorchBeginner/Task/Task2/data/MNIST/raw/train-images-idx3-ubyte'
path_tra_lab = '/Users/pengchen/workspace/PytorchBeginner/Task/Task2/data/MNIST/raw/train-labels-idx1-ubyte'
path_tes_img = '/Users/pengchen/workspace/PytorchBeginner/Task/Task2/data/MNIST/raw/t10k-images-idx3-ubyte'
path_tes_lab = '/Users/pengchen/workspace/PytorchBeginner/Task/Task2/data/MNIST/raw/t10k-labels-idx1-ubyte'
def mkdir(path):
# 判断路径是否存在
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录,创建目录操作函数
'''
os.mkdir(path)与os.makedirs(path)的区别是,当父目录不存在的时候os.mkdir(path)不会创建,os.makedirs(path)则会创建父目录
'''
# 此处路径最好使用utf-8解码,否则在磁盘中可能会出现乱码的情况
os.makedirs(path)
# print(path+' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
# print(path+' 目录已存在')
return False
def create_new_sets(path_new_datasets, modify_num=-1, modify_size=2):
if mkdir(path_new_datasets):
if os.path.split(path_new_datasets)[-1]=='Train':
tra_img, tra_img_num = open_images_set(path_tra_img)
tra_lab, tra_lab_num = open_labels_set(path_tra_lab)
images, labels, images_num = tra_img, tra_lab, tra_img_num
elif os.path.split(path_new_datasets)[-1]=='Test':
tes_img, tes_img_num = open_images_set(path_tes_img)
tes_lab, tes_lab_num = open_labels_set(path_tes_lab)
images, labels, images_num = tes_img, tes_lab, tes_img_num
else:
print('Create Trainset[?] or Testset[?]')
return None
os.chdir(path_new_datasets)
# 指定一个标签/数字
for which_num in range(10):
total_num = 0
# if which_num > 1:
# break
for index in range(0, images_num):
if labels[index] == which_num:
# 取出一张图片和对应标签
label = labels[index]
image = images[index].reshape(28, 28)
if which_num == modify_num:
modify_image(image, modify_size)
filename = str(label) + '_' + str(total_num) + '.jpg'
Image.fromarray(image).save(filename)
# image[0][0], image[0][1], image[1][0], image[1][1] = 255, 255, 255, 255
total_num += 1 # 统计标签为which_num在训练集中的总数
os.chdir('../')
else:
print(os.path.split(path_new_datasets)[-1]+' is Existed.')
# modify_num = 1
# path_new_datasets = '/Users/pengchen/workspace/PytorchBeginner/Task/Task22/TrainNew'
# if __name__=='__main__':
# create_new_sets(path_new_datasets, modify_num)
class MyData(Dataset): # 继承Dataset
def __init__(self, root_dir, transform=None): # __init__是初始化该类的一些基础参数
self.root_dir = root_dir # 文件目录
self.transform = transform # 变换
# os.listdir()不保证按序进行:www.runoob.com/python3/python3-os-listdir.html
self.images = os.listdir(self.root_dir) # 目录里的所有文件
def __len__(self): # 返回整个数据集的大小
return len(self.images)
def __getitem__(self, index): # 根据索引index返回dataset[index]
image_index = self.images[index] # 根据索引index获取该图片
# print(f'image_index: {image_index}')
img_path = os.path.join(self.root_dir, image_index) # 获取索引为index的图片的路径名
img_PIL = Image.open(img_path)
# 打印图像的源, 尺寸,像素的类型和深度
# print(img_PIL.format, img_PIL.size, img_PIL.mode)
# 有必要再为灰度图像的通道来扩展?
# img = np.expand_dims(np.array(img_PIL), axis=0)
# print('img(tensor): :', torch.from_numpy(img).shape)
# img = io.imread(img_path) # 读取该图片
label = os.path.split(img_path)[-1].split('_')[
0] # 根据该图片的路径名获取该图片的label,具体根据路径名进行分割。我这里是"E:\\Python Project\\Pytorch\\dogs-vs-cats\\train\\cat.0.jpg",所以先用"\\"分割,选取最后一个为['cat.0.jpg'],然后使用"."分割,选取[cat]作为该图片的标签
# sample = {'image': img, 'label': label} # 根据图片和标签创建字典
# print(f'img_PIL: {img_PIL}')
if self.transform:
img = self.transform(img_PIL)
# sample = self.transform(sample) # 对样本进行变换
# print(f'img: {img}')
label = torch.from_numpy(np.array(int(label)))
return img, label
# return sample # 返回该样本
其他问题和解决:
在读下载下来的数据集的时候,遇到了一个问题:
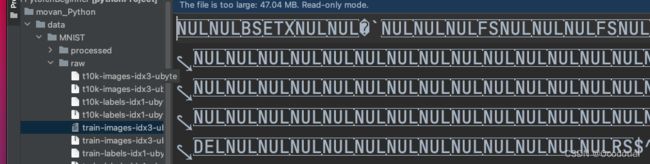
train-images-idx3格式与其他不一样,原因在于,pycharm把该文件修改了,如下图:
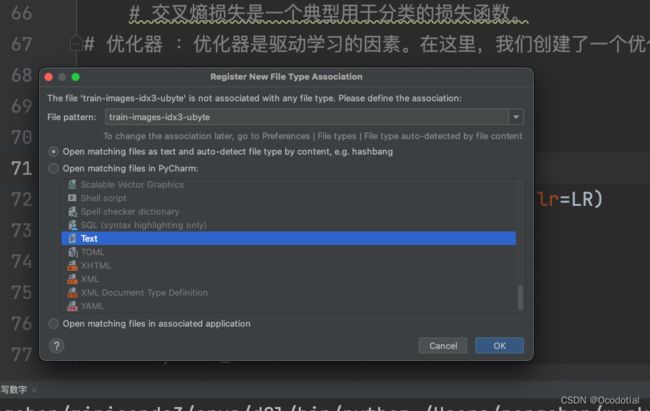
解决办法:
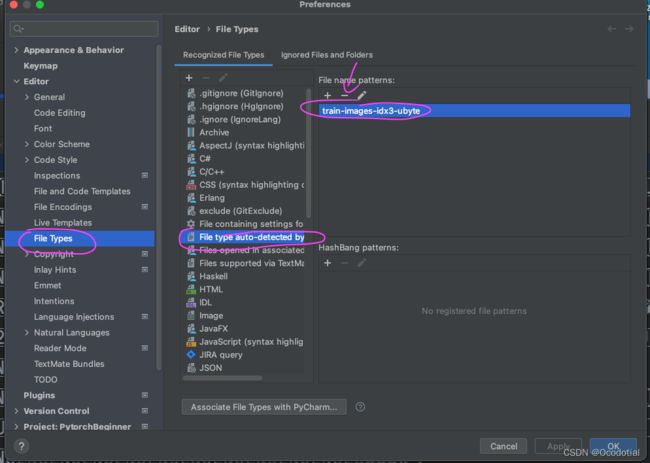
然后就恢复到原来的格式: