MapReduce迭代计算之网页评价PageRank案例
学习这个案例的目的:掌握mr程序是可以进行迭代计算的,但是要给它一个停下来的标准。
PageRank是什么
PageRank(网页排名)是Google提出的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度,是 Google 对网页重要性、价值的评估。是Google创始人拉里·佩奇和谢尔盖·布林于1997年创造的。PageRank实现了将链接价值概念作为排名因素。http://pr.chinaz.com/

扩展:
PR值的提高可有效提升你的网页在Google搜索引擎中的页面排名,但并不是说PR越高则排名越靠前。有一些网站尽管PR不算高,但却较一些PR高的网站排名还要靠前。所以你应该在对网站优化的同时,也要努力提高网站的PR值。提高PR最佳和最简单的办法在于:
1. 提供有趣、有价值的网站内容,这样站长们会主动和你进行友情链接,从而提高你的外部链接值。
2. 将网站提交到各大搜索引擎,这样可显著改善你的网站在Google上的排名。
3. 可将网站添加到行业门户站点、网上论坛、留言簿等等各种允许添加网址链接的地方。
4. 与其他网站交换链接来提高链接权值。
5. 与其他网站交换链接时首先要查看对方站点是否被Google删除,或是否被Google收录,没有被Google收录的站点最好不要做连接。
PR计算逻辑
算法原理(1)
思考超链接在互联网中的作用?入链 ====给?的投票 出链PageRank让链接来“投票“,到一个页面的超链接相当于对该页投一票。
入链数量:如果一个页面节点接收到的其他网页指向的入链数量越多,那么这个页面越重要。
入链质量:指向页面A的入链质量不同,质量高的页面会通过链接向其他页面传递更多的权重。所以越是质量高的页面指向页面A,则页面A越重要。
网络上各个页面的链接图:
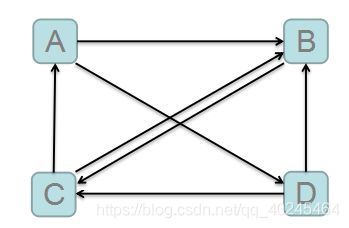
站在A的角度:
需要将自己的PR值分给B,D。
站在B的角度:
收到来自A,C,D的PR值。
PR需要迭代计算:其PR值会趋于稳定。

- 算法原理(2)
初始值:Google的每个页面设置相同的页面价值,即PR值pagerank算法给每个页面的PR初始值为1。迭代计算(收敛):Google不断的重复计算每个页面的PageRank。那么经过不断的重复计算,这些页面的PR值会趋向于稳定,也就是收敛的状态。在具体企业应用中怎么样确定收敛标准?1、每个页面的PR值和上一次计算的PR相等。2、设定一个差值指标(0.0001)。当所有页面和上一次计算的PR差值平均小于该标准时,则收敛。3、设定一个百分比(99%),当99%的页面和上一次计算的PR相等。
- 算法原理(3)
站在互联网的角度:只出,不入:PR会为0。只入,不出:PR会很高。直接访问网页:pagerank并不能百分百的表示页面价值,如果是直接访问某个网址的话,就不能像在a标签那样统计对它的点击,但是这种直接访问的方式,也会对页面价值产生影响,因此页面价值的计算不光要考虑入链出链,要考虑综合情况,要修正我们之前的计算方式。为修正PageRank计算公式,增加阻尼系数在简单公式的基础上增加了阻尼系数(damping factor)d一般取值d=0.85。完整PageRank计算公式:d:阻尼系数M(i):指向i的页面集合,即给Pi页面做入链的其它页面集合L(j):页面的出链数,即M(i)的某个页面的出链数PR(pj):j页面的PR值n:所有页面数

每一个给Pi页面投票(给它做入链的)的页面的页面价值除以出链数,
例如有3个页面A、B、C,页面价值分别为1、2、3,出链数分别为4、5、6
那么,整个公式结果就是
PR(Pi)=(1-0.85)/3 + 0.85 * (1/4 + 2/5 +3/6)
前边乘以0.85的意思就是其它页面给它的投票只能起到它85%的比重,
- 使用MR实现
解需求思路PR计算是一个迭代的过程,首先考虑一次计算思考:页面包含超链接每次迭代将pr值除以链接数后得到的值传递给所链接的页面so:每次迭代都要包含页面链接关系和该页面的pr值mr:相同的key为一组的特征map:1,读懂数据:第一次附加初始pr值 2,映射k:v1,传递页面链接关系,key为该页面,value为页面链接关系2,计算链接的pr值,key为所链接的页面,value为pr值reduce:*,按页面分组1,两类value分别处理2,最终合并为一条数据输出:key为页面&新的pr值,value为链接关系
文件准备(pagerank.txt)中间是tab键间隔

结果示例:

Node.java
package com.xiongluoluo.pagerank;
import java.util.Arrays;
import org.apache.commons.lang.StringUtils;
/*其实如果只是把上轮的投票关系写出去,大可不必写一个类.
但是还要算出投票页面给被投票页面的pr值,还是写类计算比较方便.*/
public class Node {
private double pr;//1.0 本节点的pr值
private String[] adjacentNodeName;//[B,D] 邻近结点
/*这里定义的char类型,所以要用单引号.
由于新的文本读取类只能读取以\t分割的特殊文本.
所以我们做迭代处理的时候,势必会用到\t,这里直接定义为一个静态常量,以供使用.*/
private static final char fieldsSeparator='\t';
//定义一个无参构造方法
public Node(){}
//定义一个有参构造方法
public Node(double pr,String[] adjacentNodeName){
this.pr = pr;
this.adjacentNodeName = adjacentNodeName;
}
//重写toString方法
public String toString(){
/*一直很奇怪老师为什么喜欢用StringBuffer,而不是StringBuilder,是因为安全吗?
可是这种小程序应该没必要啊,搞不懂*/
StringBuffer sb = new StringBuffer();
/*写的时候还奇怪为啥不直接append完,或者直接return一个String.
原来是考虑到不是所有设置的类adjacentNodeName属性都有值*/
sb.append(pr);
//如果当前这个类包含这个属性
if(containsAdjacentNodeName()){
//据说StringUtils的这个join方法,能够将第一个参数也就是数组,变成字符串,然后数组中每个值之间是第二个参数
sb.append(fieldsSeparator).append(StringUtils.join(getAdjacentNodeName(),fieldsSeparator));
}
return sb.toString();
}
//由于后续在mapper里面还会用,所以这里设置为public
public boolean containsAdjacentNodeName() {
//如果这个属性的地址不为空,并且length>0,那么证明这个属性有值
return adjacentNodeName!=null&&adjacentNodeName.length>0;
}
public double getPr() {
return pr;
}
public void setPr(double pr) {
this.pr = pr;
}
public String[] getAdjacentNodeName() {
return adjacentNodeName;
}
public void setAdjacentNodeName(String[] adjacentNodeName) {
this.adjacentNodeName = adjacentNodeName;
}
public static char getFieldsseparator() {
return fieldsSeparator;
}
public static Node getNode(String string, String line) throws Exception {
//第一次运行mr程序时,需要给所有页面加上初始pr值1.0,所以需要用一下这个方法
return getNode(string+fieldsSeparator+line);
}
public static Node getNode(String line) throws Exception {
//大于一次,运行mr程序时,所有页面都包含了pr值,直接调用这个方法即可
/*一开始使用的都是String类里面的split方法分割字符串.
* 今天用了个新的,org.apache.commons.lang包下面的工具类StringUtils
* 好像跟String.split也没啥差别,就是看起来更高大上一些*/
String[] split = StringUtils.split(line,fieldsSeparator);
//如果split.length小于1,那么应该是数据发生了错误.应该抛出异常
if(split.length<1){
throw new Exception("data error");
}
Node node = new Node();
//为pr设置值,由于pr是double类型,而这里的split[0]是字符串,所以需要转换一下类型
node.setPr(Double.parseDouble(split[0]));
/*这里需要为adjacentNodeName属性设置值.
需要将split数组中除了下标为0的其余值放到一个数组中,然后再赋值给这个属性
这里使用了工具类Arrays中的copyOfRange方法.
将split数组中的一部分变为一个数组赋值给adjacentNodeName属性
Arrays.copyOfRange(split, 1, split.length)
参数1是要复制的数组,参数2是复制的起点位置,参数3是复制得终点位置
包括前面的,不包括后面的*/
node.setAdjacentNodeName(Arrays.copyOfRange(split, 1, split.length));
return node;
}
}
PagerankMapper.java
package com.xiongluoluo.pagerank;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class PagerankMapper extends Mapper{
/*
A B D
B C
C A B
D B C
*/
@Override
protected void map(Text key, Text value, Context context)
throws IOException, InterruptedException {
try{
//第一件事:要把上轮的投票关系.投票页面的pr值写出去
/*如果是首次运行程序,那么需要将每一页面的pr值设置为1
runCount是通过context从driver中取出的值,是来计算运算次数的
getInt方法("",1)有两个参数,第二个参数是默认值.如果找到"runCount"对应的值就赋值,找不到用设置的默认值
*/
int runCount = context.getConfiguration().getInt("runCount",1);
String page = key.toString();//投票页面
/*由于使用的读取的类不是默认的,而是KeyValueTextInputFormat,所以第一个tab键之前是key
后面全是value,使用的这个类需要在driver设置.*/
String line = value.toString();//被投票页面
//定义一个类去处理数据
//这个类其实就是为每一行数据量身定做的
Node node = null;
//如果是第一次执行mr程序,需要将1.0赋值给每一个网页
if(runCount==1){//1.0 B D
//方法一
node = Node.getNode("1.0",line);
}else{//1.2 B D
//方法二
node = Node.getNode(line);
/*方法一和方法二都是Node中的方法,属于重载.
方法一将会先加上1.0,然后变成与方法二相同的参数,
再调用方法二,这个地方的处理还是很厉害的*/
}
//将上轮的投票关系,投票页面的pr值写出去
context.write(key, new Text(node.toString()));
//第二件事:要算出投票页面给被投票页面的pr值
/*如果邻近结点有值,也就是投票页面有给别的页面投票
那么我们就要算出投票页面给被投票页面贡献的pr值,并写出*/
if(node.containsAdjacentNodeName()){
//投票页面贡献给别的页面的pr值计算方法,用投票页面的pr值除以投票页面一共投票页面的数量
double v = node.getPr()/node.getAdjacentNodeName().length;// 1/2
for(String outPage : node.getAdjacentNodeName()){
/*写出被投票页面,以及被投票页面收到本投票页面贡献的pr值
由于v是double类型,所以加一个"",转为String类型*/
context.write(new Text(outPage), new Text(v+""));
}
}
}catch(Exception e){
e.printStackTrace();
}
}
}
PagerankReduce.java
package com.xiongluoluo.pagerank;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class PagerankReduce extends Reducer{
@Override
protected void reduce(Text key, Iterable values, Context context)
throws IOException, InterruptedException {
//
//
//
//
//以上数据值可能不真实
//区分出这两类数据:
//第一类数据:是上轮的投票关系,以及投票页面(A)的pr值
//第二类数据:是投票页面获得的其它页面投给它的pr值
try{
Node oriNode = null;
double sum = 0.0;
for(Text value : values){
Node node = Node.getNode(value.toString());
if(node.containsAdjacentNodeName()){//如果node有containsAdjacent属性,应该属于第一类数据
oriNode = node;//将node赋值给oriNode
}else{
sum = sum + node.getPr();//如果没有,则属于第二类数据,求和,以便计算pr值
}
}
//第一件事:算出本轮投资页面(A)它的新的pr值
//0.15和0.85是固定系数,4是页面总数.详细参考文档公式
double newPr = 0.15/4+0.85*sum;
//第二件事:算出本轮pr值与上轮pr值的差值,并写出,用于判断是否有必要进行下次mr运算
double diff = newPr-oriNode.getPr();
//由于得出的数很小,如果先强转int,会直接变成0
int diffInt = (int)(diff*1000);
//由于计算的是一个波动值,所以这里取绝对值
diffInt = Math.abs(diffInt);
System.out.println("本轮与上轮pr的差值"+diffInt);
//可以求出差值的总和,上面转为int也是为了这里用.这里的increment里面不能放double,只能放整型
context.getCounter(PagerankDriver.groupName,PagerankDriver.counterName).increment(diffInt);
//第三件事:写出本轮的投票关系以及新的pr值,
//投票关系没有变,只需要设置一下oriNode对象的pr值为新的pr值即可.这就是map中需要写出上一轮投票关系的原因,因为这里要用
oriNode.setPr(newPr);
//一切都是为了计算pr值.考虑到计算pr值需要什么即可
context.write(key, new Text(oriNode.toString()));
}catch(Exception e){
e.printStackTrace();
}
}
}
PagerankDriver.java
package com.xiongluoluo.pagerank;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PagerankDriver
{
//主要是为了计算总差值使用
public static final String groupName = "myGroup";
public static final String counterName = "myCounter";
public static void main( String[] args ) throws IOException, ClassNotFoundException, InterruptedException
{
//获取配置类对象
Configuration conf = new Configuration();
//用于记录运行的轮数,表示第几轮运行mr程序
int runCount = 0;
//定义一个标准,如果满足这个标准,则认为各个页面的pr值趋于稳定,可以停止mr程序的运算
double d = 0.0000001;
while(true){
runCount++;
//通过配置类将此变量传递出去,便可以在mapper中引用
conf.setInt("runCount", runCount);
//获取Job类对象的这行代码必须写在循环里面,每执行一次mr程序,创建一个新的对象.写在外面会报错.
Job job = Job.getInstance(conf);
job.setJarByClass(PagerankDriver.class);
job.setMapperClass(PagerankMapper.class);
job.setReducerClass(PagerankReduce.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
/* 设置采用KeyValueTextInputFormat来读取数据封装kv对送到mapper的map方法
会根据tab分割数据,把分割后的第一个数据当做key,其它当做value*/
job.setInputFormatClass(KeyValueTextInputFormat.class);
Path inputPaths = new Path("D:\\test\\mytest\\pagerank\\input");
//注意:除了第一次提交mr程序时读取的数据来自于input目录
//从第二次开始,mr程序读取的是上一轮mr程序的输出
if(runCount>1){
inputPaths = new Path("D:\\test\\mytest\\pagerank\\output"+(runCount-1));
}
FileInputFormat.setInputPaths(job, inputPaths);
Path outputDir = new Path("D:\\test\\mytest\\pagerank\\output"+runCount);
//如果输出目录存在,就删掉
if(outputDir.getFileSystem(conf).exists(outputDir)){
outputDir.getFileSystem(conf).delete(outputDir,true);
}
FileOutputFormat.setOutputPath(job, outputDir);
boolean waitForCompletion = job.waitForCompletion(true);
if(waitForCompletion){//如果上次任务成功执行
//计数器只会累加依次mr程序的数据,如果再次提交mr程序的话,计数器的值会重新增加
//value是4个页面各自本轮pr值与上轮pr值差值乘以1000以后结果的总和
long value = job.getCounters().findCounter(PagerankDriver.groupName, PagerankDriver.counterName).getValue();
//求4个页面平均与上轮pr值的差值,这个地方要加.0
double diff = value/4000.0;
//输出目前的精度
System.out.println("diff is "+diff);
//满足条件的情况下,则认为是页面的pr值趋于稳定,可以退出循环,不再提交mr程序
if(diffpom.xml
4.0.0
com.xiongluoluo
mycode0224
0.0.1-SNAPSHOT
jar
mycode0224
http://maven.apache.org
UTF-8
junit
junit
RELEASE
org.apache.logging.log4j
log4j-core
2.8.2
org.apache.hadoop
hadoop-common
2.7.2
org.apache.hadoop
hadoop-client
2.7.2
org.apache.hadoop
hadoop-hdfs
2.7.2