unet 学习笔记2神经网络结构
一个神经网络模型都是基于nn.module
不同的模型无非就是conv maxpool drop等设置的顺序层数等不同。
unet 先下采样再上采样,上下采样中包括卷积等
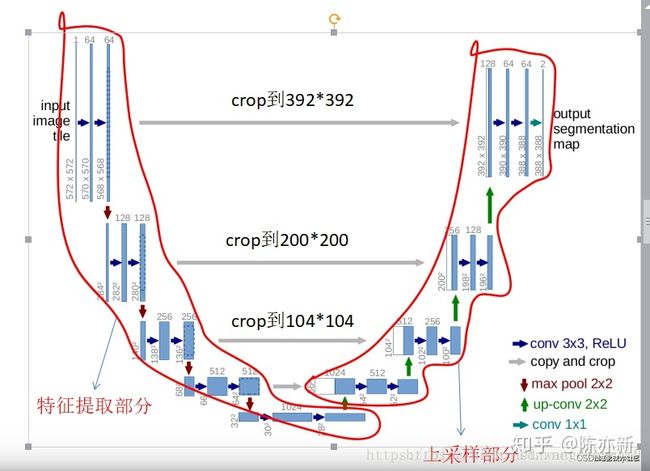
具体的代码编写注意的知识点:
1、卷积模块
需要注意的是卷积模块是有输入输出通道区别的,所以在初始化的时候需传入在这两个参数?,super继承类名,初始化()
sequential是一个容器,可以将多个nn 集成到一起作为一层,分别依次执行这层所有的,convd2d中(意思分别为输入输出通道,几称几卷积,步长,填充方式(reflect的意思就是将图里的特征像素进行填充而不是空洞填充,更利于学习特征),偏置是否(不偏置就是batchnorm))


2、下采样模块
下采样不改变通道数
因为利用池化会丢太多信息,所以在这里,用卷积层来代替,实际是用池化

上采样
torch.nn.functional.interpolate(input, size=None, scale_factor=None, mode=‘nearest’, align_corners=None, recompute_scale_factor=None)
利用插值方法,对输入的张量数组进行上\下采样操作,换句话说就是科学合理地改变数组的尺寸大小,尽量保持数据完整。
输入:
F.interpolate——数组采样操作
定义完每一小部分,再定义net网络,把他组合起来,其中注意里面的维数,以及先self,再forward
lass UNet(nn.Module):
def __init__(self,num_classes):
super(UNet, self).__init__()
self.c1=Conv_Block(3,64)
self.d1=DownSample(64)
self.c2=Conv_Block(64,128)
self.d2=DownSample(128)
self.c3=Conv_Block(128,256)
self.d3=DownSample(256)
self.c4=Conv_Block(256,512)
self.d4=DownSample(512)
self.c5=Conv_Block(512,1024)
self.u1=UpSample(1024)
self.c6=Conv_Block(1024,512)
self.u2 = UpSample(512)
self.c7 = Conv_Block(512, 256)
self.u3 = UpSample(256)
self.c8 = Conv_Block(256, 128)
self.u4 = UpSample(128)
self.c9 = Conv_Block(128, 64)
self.out=nn.Conv2d(64,num_classes,3,1,1)
def forward(self,x):
R1=self.c1(x)
R2=self.c2(self.d1(R1))
R3 = self.c3(self.d2(R2))
R4 = self.c4(self.d3(R3))
R5 = self.c5(self.d4(R4))
O1=self.c6(self.u1(R5,R4))
O2 = self.c7(self.u2(O1, R3))
O3 = self.c8(self.u3(O2, R2))
O4 = self.c9(self.u4(O3, R1))
train部分
classnums就是分割成几块,下面代码中
需要学习如何保存图片、torch.save() 以及如何输出每轮结果,每隔几轮保存一次。
print(f’{epoch}-{i}-train_loss===>>{train_loss.item()}')
import os
import tqdm
from torch import nn, optim
import torch
from torch.utils.data import DataLoader
from data import *
from net import *
from torchvision.utils import save_image
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
weight_path = 'params/unet.pth'
data_path = r'data'
save_path = 'train_image'
if __name__ == '__main__':
num_classes = 2 + 1 # +1是背景也为一类
data_loader = DataLoader(MyDataset(data_path), batch_size=1, shuffle=True)
net = UNet(num_classes).to(device)
if os.path.exists(weight_path):
net.load_state_dict(torch.load(weight_path))
print('successful load weight!')
else:
print('not successful load weight')
opt = optim.Adam(net.parameters())
loss_fun = nn.CrossEntropyLoss()
epoch = 1
while epoch < 200:
for i, (image, segment_image) in enumerate(tqdm.tqdm(data_loader)):
image, segment_image = image.to(device), segment_image.to(device)
out_image = net(image)
train_loss = loss_fun(out_image, segment_image.long())
opt.zero_grad()
train_loss.backward()
opt.step()
if i % 1 == 0:
print(f'{epoch}-{i}-train_loss===>>{train_loss.item()}')
_image = image[0]
_segment_image = torch.unsqueeze(segment_image[0], 0) * 255
_out_image = torch.argmax(out_image[0], dim=0).unsqueeze(0) * 255
img = torch.stack([_segment_image, _out_image], dim=0)
save_image(img, f'{save_path}/{i}.png')
if epoch % 20 == 0:
torch.save(net.state_dict(), weight_path)
print('save successfully!')
epoch += 1
test部分
导入其他文件*
import os
import cv2
import numpy as np
import torch
from net import *
from utils import *
from data import *
from torchvision.utils import save_image
from PIL import Image
初始化模型,定义权重路径,加载预训练好的模型
net=UNet(3).cuda()
weights='params/unet.pth'
if os.path.exists(weights):
net.load_state_dict(torch.load(weights))
print('successfully')
else:
print('no loading')
函数input()接受一个参数
_input=input('please input JPEGImages path:')
文件输入这个地方有点不明白:
squeeze是降维,unsqueeze是升维。
测试的时候,net.eval()是参数不回传,将图片输入到模型中,再将输出结果显示或者保存就可以了。
img=keep_image_size_open_rgb(_input)
img_data=transform(img).cuda()
img_data=torch.unsqueeze(img_data,dim=0)
net.eval()
out=net(img_data)
out=torch.argmax(out,dim=1)
out=torch.squeeze(out,dim=0)
out=out.unsqueeze(dim=0)
print(set((out).reshape(-1).tolist()))
out=(out).permute((1,2,0)).cpu().detach().numpy()
cv2.imwrite('result/result.png',out)
cv2.imshow('out',out*255.0)
cv2.waitKey(0)
至此unet暂时学习完毕。
linux下载解压:wget +https地址
解压 unzip +文件名.zip