Pandas笔记
pandas笔记
- Pandas 基础处理
-
- 4.1Pandas介绍
-
- 4.1.1 Pandas介绍 - 数据处理工具
- 4.1.2 为什么使用Pandas
- 4.1.3 DataFram 对象
- 4.1.4 MultiIndex与pannel
-
- **1.MultiIndex**
- **2 Panel**
- **3 Series**
- 4.2 基本数据操作
-
- 4.2.1 索引操作
- 4.2.2赋值
- 4.2.3 排序
- 4.3 DataFrame运算
-
- 4.3.1 算术运算
- 4.3.2 逻辑运算
-
- 逻辑运算函
- 4.3.3统计运算
- 4.3.4 累计统计函数:
- 4.3.5 自定义运算
- 4.4 Pandas画图
- 4.5 文件读取与存储
-
- 4.5.1 CSV
- 4.5.2 HDF5(二进制文件)
- 4.5.3 JSON
- Pandas高级处理
-
- 4.6 高级处理-缺失值处理
-
- 4.6.1 如何处理nan
- 4.6.2 不是缺失值nan,有默认标记的
- 4.7 高级处理-数据离散化
-
- 4.7.1 什么是数据的离散化
- 4.7.2 为什么要离散化
- 4.7.3 如何实现数据的离散化
- 4.8 高级处理-合并
-
-
- 1)concat拼接(按方向拼接)
- 2)按索引拼接--merge
- 1)内连接
- 2)左连接
- 3)右连接
- 3)外连接
-
- 4.9 高级处理-交叉表与透视表
-
- 4.9.1 交叉表与透视表什么作用
- 4.9.2 使用crosstab(交叉表)实现
-
- pandas日期类型
- 4.9.3 使用pivot_table(透视表)
- 4.10 高级处理-分组与聚合
-
- 4.10.1 什么是分组与聚合
- 4.10.2 分组与聚合API
Pandas 基础处理
Pandas是什么?为什么用?
核心数据结构
DataFrame
Panel
Series
基本操作
运算
画图
文件的读取与存储
高级处理
pandas 安装:
#升级pip(选做)
python -m pip install --upgrads pip
#阿里镜像安装pandas
pip install pandas -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com/pypi/simple
4.1Pandas介绍
4.1.1 Pandas介绍 - 数据处理工具
panel + data + analys
panel面板数据 - 计量经济学 三维数据

核心数据结构
DataFrame
Pannel
Series
4.1.2 为什么使用Pandas
便捷的数据处理能
读取文件方便
封装了Matplotlib、Numpy的画图和计算
4.1.3 DataFram 对象

结构:
既有行索引,又有列索引的二维数组
import numpy as np
import pandas as pd
#创建一个符合正态分布的10个股票5天的涨幅数据
stock_change=np.random.normal(loc=0,scale=1,size=(10,5))
#添加行索引
stock=["股票{}".format(i) for i in range(10)]
#添加列索引
#pd.date_range() --用来生成日期
date=pd.date_range(start="20211224",periods=5,freq="B")
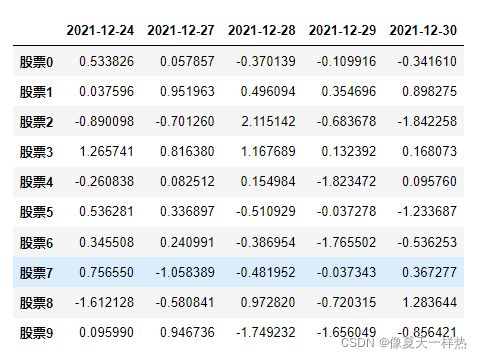
data_stocks=pd.DataFrame(stock_change,index=stock,columns=date)
data_stocks
属性:
shape #形状
index #行索引列表
columns #列索引列表
values #直接获取其中array的值
T #转置
data_stocks.shape
>>> (10, 5)
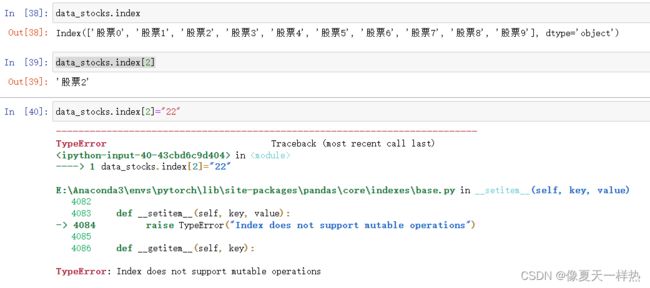
data_stocks.index
>>>Index(['股票0', '股票1', '股票2', '股票3', '股票4', '股票5', '股票6', '股票7', '股票8', '股票9'], dtype='object'
data_stocks.columns
>>>DatetimeIndex(['2021-12-24', '2021-12-27', '2021-12-28', '2021-12-29''2021-12-30'] dtype='datetime64[ns]', freq='B'
data_stocks.values
>>>array([[ 0.53382629, 0.05785681, -0.37013912, -0.10991607, -0.34161015],
[ 0.03759558, 0.95196327, 0.49609403, 0.35469635, 0.89827462],
[-0.89009782, -0.70126025, 2.11514223, -0.68367804, -1.84225813],
[ 1.26574084, 0.81638033, 1.16768865, 0.13239209, 0.16807341],
[-0.2608384 , 0.0825122 , 0.15498428, -1.8234721 , 0.0957601 ],
[ 0.53628063, 0.33689679, -0.51092882, -0.03727799, -1.2336869 ],
[ 0.34550794, 0.24099083, -0.38695422, -1.76550244, -0.53625289],
[ 0.75655038, -1.0583886 , -0.48195212, -0.03734291, 0.36727743],
[-1.61212811, -0.58084113, 0.97282033, -0.72031483, 1.28364436],
[ 0.09598993, 0.94673641, -1.74923158, -1.65604889, -0.8564206 ]]
data_stocks.T

方法:
head() #开头几行,默认返回前5行
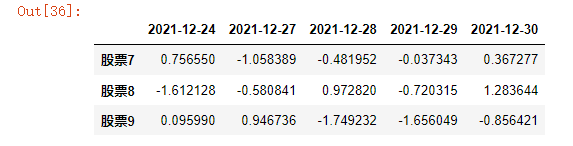
tail() #最后几行,默认返回后5行
data_stocks.head()

data_stocks.tail(3)
DataFrame索引的设置:
1)修改行、列索引值 (只能整体修改)
2)重设索引
3)设置新索引(以某列值设置为新索引)
1)修改股票索引:
不能单独修改一个索引。
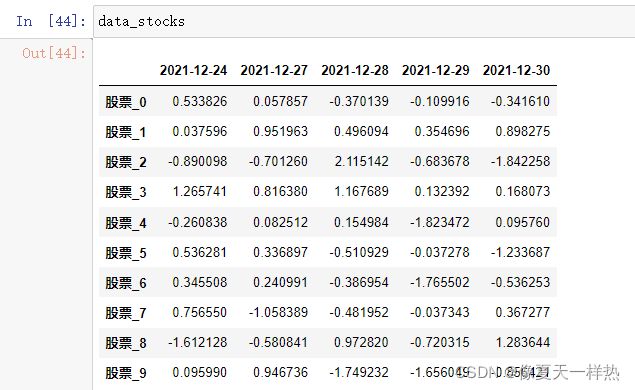
stock_=["股票_{}".format(i) for i in range(10)]
>>>stock_
['股票_0',
'股票_1',
'股票_2',
'股票_3',
'股票_4',
'股票_5',
'股票_6',
'股票_7',
'股票_8',
'股票_9']
data_stocks.index=stock_
data_stocks
2)重设索引

data_stocks.reset_index()

data_stocks.reset_index(drop=True)
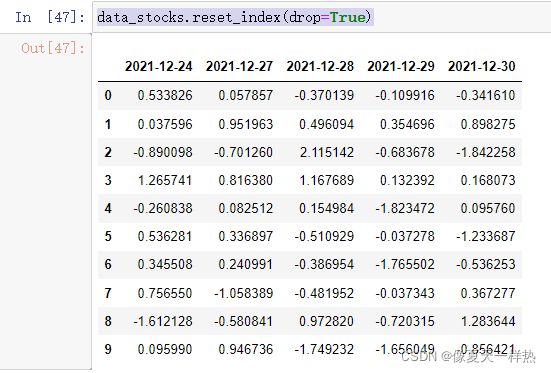
3)设置新索引

##创建数组
df=pd.DataFrame({'month':[1,4,7,10],
'year':[2001,2014,2020,2021],
'sale':[55,30,8,65]})
df
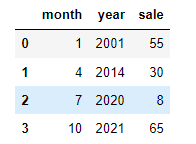
将月份设置为新的索引:
df.set_index("month",drop=False)

设置多个索引:
#设置多个索引
new_df=df.set_index(["year","month"])
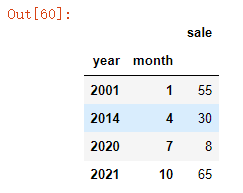
此时index变为多个:
new_df.index
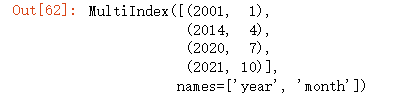
4.1.4 MultiIndex与pannel
1.MultiIndex

new_df.index.names
>>>FrozenList(['year', 'month']
new_df.index.levels
>>>FrozenList([[2001, 2014, 2020, 2021], [1, 4, 7, 10]]
2 Panel
DataFrame的容器
注:Pandas从版本0.20.0开始弃用,推荐的用于表示3D数据的方法是DataFrame上的MultiIndex方法

- items - axis 0,每个项目对应于内部包含的数据帧(DataFrame)。
- major_axis - axis 1,它是每个数据帧(DataFrame)的索引(行)。
- minor_axis - axis 2,它是每个数据帧(DataFrame)的列。
p = pd.Panel(np.arange(24).reshape(4,3,2),
items=list('ABCD'),
major_axis=pd.date_range('20130101', periods=3),
minor_axis=['first', 'second'])
p["A"]
p.major_xs("2013-01-01")
p.minor_xs("first")
3 Series
带索引的一维数组
属性:
index
values
data1=data_stocks.iloc[1,:]
data1

data1.index
》》》DatetimeIndex(['2021-12-24', '2021-12-27', '2021-12-28', '2021-12-29',
'2021-12-30'],
dtype='datetime64[ns]', freq='B')
data1.values
》》》array([0.03759558, 0.95196327, 0.49609403, 0.35469635, 0.89827462]
type(data1.values)
》》》numpy.ndarray
Series创建:
- 通过已有数据创建
pd.Series(range(10))
》》》0 0
1 1
2 2
3 3
4 4
5 5
6 6
7 7
8 8
9 9
dtype: int64
创建数据指定索引
pd.Series(range(3,9,2),index=("a","b","c"))
》》》a 3
b 5
c 7
dtype: int64
pd.Series(np.arange(3, 9, 2), index=["a", "b", "c"])
》》》a 3
b 5
c 7
dtype: int32
用字典创建Series:
#用字典创建
pd.Series({'red':100, 'blue':200, 'green': 500, 'yellow':1000})
总结:
DataFrame是Series的容器
Panel是DataFrame的容器
4.2 基本数据操作
4.2.1 索引操作
读取csv文件数据:
#读取csv文件数据
data=pd.read_csv("F:/b站视频资料/Python数据挖掘基础教程资料/day3资料/02-代码/stock_day/stock_day.csv")
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1) # 去掉一些不要的列
data
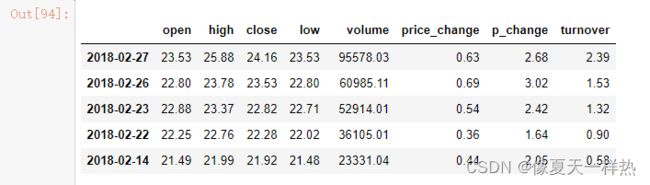
#numpy的索引
stock_change[2,2]
#data[2,2] #×pandas不可像numpy一样直接进行索
1)直接索引
先列后行
# 1)直接索引---先列后行
data["open"]["2018-02-26"]
》》》22.8
索引一列:
#取所有open列属性
data.open
data["open"]
2)按名字索引
loc
# 2) 使用loc按名字进行索引---先行后列
data.loc["2018-02-26"]["open"]
》》》22.8
data.loc['2018-02-26','open']
》》》22.8
3)按数字索引
iloc
# 3) 使用iloc 按数字进行索引
data.iloc[1,0]
》》》22.8
4)ix组合索引(ix已不能用)
数字、名字
data.index[0:4]
>>>Index(['2018-02-27', '2018-02-26', '2018-02-23', '2018-02-22'], dtype='object')
data.loc[data.index[0:4], ['open', 'close', 'high', 'low']
#查询多个
df_neg.loc[[1,2]]
df_neg = df_neg.loc[df_neg['文本'].str.len() >= SENTENCE_MIN_COUNT].reset_index(drop=True) # 丢弃句子太少的数据
data.columns.get_indexer(['open', 'close', 'high', 'low'])
>>array([0, 2, 1, 3], dtype=int64)
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
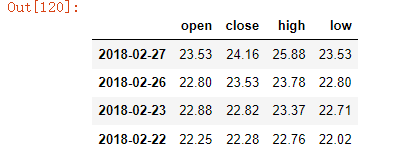
4.2.2赋值
#整列赋值
data.open=10
data["open"]=100
#单个属性赋值
data.iloc[1,0]=1000
4.2.3 排序
- 对内容排序
datafram
series

#对high属性列进行升序排序
data.sort_values(by="high")
#对high属性列进行降序排序
data.sort_values(by="high",ascending=False)
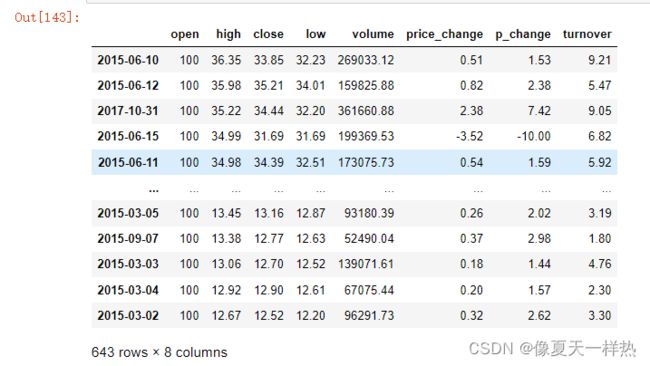
#先对high进行排序,high值相等,根据p_change进行排序
data.sort_values(by=["high","p_change"],ascending=False)
-
对索引排序
dataframe series
#根据索引进行排序
data.sort_index()
带索引的的一维数组series排序和DataFrame原理相同:
#构建一个serics序列
series1=data["price_change"]
series1
#升序排序
series1.sort_values()
#降序排序
series1.sort_values(ascending=False)
#对索引进行排序
series1.sort_index()
#排序后取头5个
series1.sort_index().head()
4.3 DataFrame运算
4.3.1 算术运算
#整列数据+3
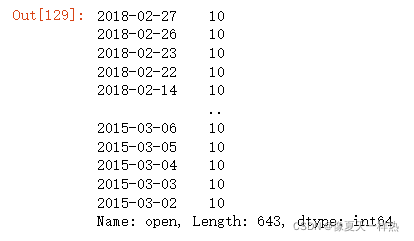
data["open"]+3
data.open.add(3)
data["open"].add(3)
》》》2018-02-27 26.53
2018-02-26 25.80
2018-02-23 25.88
2018-02-22 25.25
2018-02-14 24.49
...
2015-03-06 16.17
2015-03-05 15.88
2015-03-04 15.80
2015-03-03 15.52
2015-03-02 15.25
Name: open, Length: 643, dtype: float64
#数据整体+10
data+10
#两列数据相减---收盘价-开盘价
data["close"]-data["open"]
data["close"].sub(data["open"])
》》》2018-02-27 0.63
2018-02-26 0.73
2018-02-23 -0.06
2018-02-22 0.03
2018-02-14 0.43
...
2015-03-06 1.11
2015-03-05 0.28
2015-03-04 0.10
2015-03-03 0.18
2015-03-02 0.27
Length: 643, dtype: float64
data["open"]-10
》》》2018-02-27 13.53
2018-02-26 12.80
2018-02-23 12.88
2018-02-22 12.25
2018-02-14 11.49
...
2015-03-06 3.17
2015-03-05 2.88
2015-03-04 2.80
2015-03-03 2.52
2015-03-02 2.25
Name: open, Length: 643, dtype: float64
4.3.2 逻辑运算
逻辑运算符
![]()
data>20
data["p_change"]>2 #data["p_change"] p_change的serics的序列
data.p_change>2
》》》2018-02-27 True
2018-02-26 True
2018-02-23 True
2018-02-22 False
2018-02-14 True
...
2015-03-06 True
2015-03-05 True
2015-03-04 False
2015-03-03 False
2015-03-02 True
Name: p_change, Length: 643, dtype: bool
布尔索引
#返回data数据中所有p_change>2的
data[data.p_change>2]
data[data.p_change>2]

#组合逻辑运算符
(data["p_change"]>2) & (data["low"]>20)
》》》2018-02-27 True
2018-02-26 True
2018-02-23 True
2018-02-22 False
2018-02-14 True
...
2015-03-06 False
2015-03-05 False
2015-03-04 False
2015-03-03 False
2015-03-02 False
Length: 643, dtype: bool
#组合逻辑运算符的布尔索引
data[(data["p_change"]>2) & (data["low"]>20)]

逻辑运算函
query()
isin() #判断一组组书中是否有某个值
query()
#组合运算符查询数据
data.query("p_change>2 & close>20")

isin()
data["turnover"].isin([4.19,2.39])
》》》2018-02-27 True
2018-02-26 False
2018-02-23 False
2018-02-22 False
2018-02-14 False
...
2015-03-06 False
2015-03-05 False
2015-03-04 False
2015-03-03 False
2015-03-02 False
Name: turnover, Length: 643, dtype: bool
data[data["turnover"].isin([4.19,2.39])]

4.3.3统计运算
min max mean median var( 方差) std(标准差)
describe()
综合分析:能够直接得出很多统计结果,count,mean,std,min,max等
data.describe()
- 50%中位数

#获取最大值(默认按列获取axis=0,按行获取axis=1)
data.max()
》》》open 34.99
high 36.35
close 35.21
low 34.01
volume 501915.41
price_change 3.03
p_change 10.03
turnover 12.56
dtype: float64
在numpy中获取最大值最小值的位置:
np.argmax()
np.argmin()
在pandas中获取最大值最小值位置:
idxmax()
idxmin()
#获取最大值的索引(默认按列获取axis=0,按行获取axis=1)
data.idxmax()
》》》open 2015-06-15
high 2015-06-10
close 2015-06-12
low 2015-06-12
volume 2017-10-26
price_change 2015-06-09
p_change 2015-08-28
turnover 2017-10-26
dtype: object
4.3.4 累计统计函数:

#累计统计p_change列
data["p_change"].cumsum()
》》》2018-02-27 2.68
2018-02-26 5.70
2018-02-23 8.12
2018-02-22 9.76
2018-02-14 11.81
...
2015-03-06 114.70
2015-03-05 116.72
2015-03-04 118.29
2015-03-03 119.73
2015-03-02 122.35
Name: p_change, Length: 643, dtype: float64
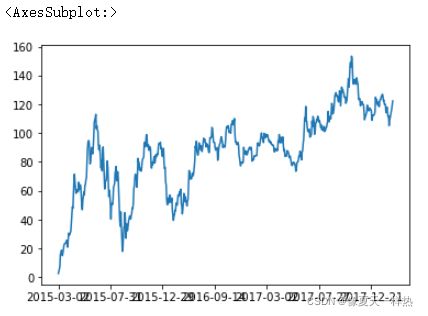
#pandas直接画图(需要先安装好matplotlib)
data["p_change"].sort_index().cumsum().plot()
#先排序后画图
data["p_change"].sort_index().cumsum().plot()
4.3.5 自定义运算
apply(func, axis=0)
func: 自定义函数
axis=0: 默认按列运算,axis=1按行运算
data.apply(lambda x:x.max()-x.min(),axis=0)# :左边是参数,右边是运算
4.4 Pandas画图

pandas.DataFrame.plot
DataFrame.plot(x=None, y=None, kind=‘line’)
-
x: label or position, default None
-
y: label, position or list of label, positions, default None
-
Allows plotting of one column versus another
-
kind: str
- ‘line’: line plot(default)
- ''bar": vertical bar plot
- “barh”: horizontal bar plot
- “hist”: histogram
- “pie”: pie plot
- “scatter”: scatter plot
#用散点图展示open列和close列的关系
data.plot(x="open",y="close",kind="scatter")

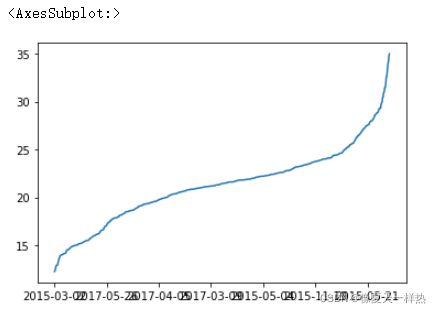
pandas.Series.plot
sr.plot()
data["open"].sort_values().plot(kind="line")
4.5 文件读取与存储

4.5.1 CSV
(1)读取CSV文件
pd.read_csv(path)
usecols=
names=

import pandas as pd
#读取csv文件数据
data=pd.read_csv("F:/b站视频资料/Python数据挖掘基础教程资料/day3资料/02-代码/stock_day/stock_day.csv",usecols=['high','low','open','close'])
data

当所读取文件没有列名,所读取的文件会把第一列数据当作列名,用names属性添加列名。
pd.read_csv('F:/b站视频资料/Python数据挖掘基础教程资料/day3资料/02-代码/stock_day2.csv')

pd.read_csv('F:/b站视频资料/Python数据挖掘基础教程资料/day3资料/02-代码/stock_day2.csv',names=["open", "high", "close", "low", "volume", "price_change", "p_change", "ma5", "ma10", "ma20", "v_ma5", "v_ma10", "v_ma20", "turnover"])

(2)写入CSV文件
dataframe.to_csv(path)
columns=[]
index=False
header=False

#保存open列数据的前10行
data[:10].to_csv("./open.csv",columns=['open'])

对保存的进行读取:
pd.read_csv("./open.csv")
#不保存索引列
data[:10].to_csv("./open.csv",columns=['open'],index=False)

# 保存opend列数据,index=False不要行索引,mode="a"追加模式|mode="w"重写,header=False不要列索引
data[:10].to_csv("test.csv", columns=["open"], index=False, mode="a", header=False)
4.5.2 HDF5(二进制文件)
hdf5 存储 3维数据的文件
key1 dataframe1二维数据
key2 dataframe2二维数据
pd.read_hdf(path, key=)
df.to_hdf(path, key=)
day_close =pd.read_hdf('F:/b站视频资料/Python数据挖掘基础教程资料/day3资料/02-代码/stock_data/day/day_close.h5')
》》》报错:ImportError: Missing optional dependency 'tables'. Use pip or conda to install tables.
day_close.to_hdf("test.h5", key="close")
pd.read_hdf("test.h5", key="close").head()
day_open=read_hdf('F:/b站视频资料/Python数据挖掘基础教程资料/day3资料/02-代码/stock_data/day/day_open.h5')
day_close.to_hdf("test.h5", key="open")
#一个文件下存储了两个键的文件,读取时必须指定key名称
pd.read_hdf("test.h5", key="close").head()

4.5.3 JSON
pd.read_json(path)
- orient=“records”
- lines=True
df.to_json(patn)
- orient=“records”
- lines=True
(1)读取

data_json=pd.read_json("F:/b站视频资料/Python数据挖掘基础教程资料/day3资料/02-代码/Sarcasm_Headlines_Dataset.json",orient="records",lines=True)

(2)写入
#lines=True ----显示为一行一行的json数据
data_json.to_json("test.json",orient="records",lines=True)
Pandas高级处理
缺失值处理
数据离散化
合并
交叉表与透视表
分组与聚合
综合案例
4.6 高级处理-缺失值处理
1)如何进行缺失值处理
两种思路:
1)删除含有缺失值的样本
2)替换/插补----计算平均值/中位数...替换到缺失值位置
4.6.1 如何处理nan

1)判断数据中是否存在NaN
- pd.isnull(df)
- pd.notnull(df)
2)删除含有缺失值的样本
- df.dropna(inplace=False)
- 替换/插补
df.fillna(value, inplace=False)
import pandas as pd
import numpy as np
#读取数据
data_move=pd.read_csv('F:\\b站视频资料\\Python数据挖掘基础教程资料\\day4资料\\02-代码\\IMDB\\IMDB-Movie-Data.csv')
data_move
# 1)判断是否存在NaN类型的缺失值
##判断是否存在缺失值
data_move.isnull()
pd.isnull(data_move)
##判断是否存在缺失值
np.any(pd.isnull(data_move)) #np.any()存在# 返回True,说明数据中存在缺失值
np.any(data_move.isnull())
np.all(pd.notnull(movie)) # 返回False,说明数据中存在缺失值
#利用pandas判断是否存在缺失值
pd.isnull(data_move).any()
pd.notnull(data_move).all()
>>>Rank False
Title False
Genre False
Description False
Director False
Actors False
Year False
Runtime (Minutes) False
Rating False
Votes False
Revenue (Millions) False
Metascore False
dtype: bool
# 2)缺失值处理
# 方法1:删除含有缺失值的样本
data_move1=data_move.dropna()#默认inplace=False会返回一个新的DataFrame,原始DataFrame不会发生改变
pd.isnull(data_move1).any()
>>>Rank False
Title False
Genre False
Description False
Director False
Actors False
Year False
Runtime (Minutes) False
Rating False
Votes False
Revenue (Millions) False
Metascore False
dtype: bool
# 方法2:替换
# 含有缺失值的字段
# Revenue (Millions)
# Metascore
data_move["Revenue (Millions)"].fillna(data_move["Revenue (Millions)"].mean(),inplace=True)
data_move["Metascore"].fillna(data_move["Revenue (Millions)"].mean(),inplace=True)
#查看是否还存在缺失值
pd.isnull(data_move).any()
》》》Rank False
Title False
Genre False
Description False
Director False
Actors False
Year False
Runtime (Minutes) False
Rating False
Votes False
Revenue (Millions) False
Metascore False
dtype: bool
4.6.2 不是缺失值nan,有默认标记的
1)替换 ?-> np.nan
df.replace(to_replace="?", value=np.nan)
2)处理np.nan缺失值的步骤
缺失值处理实例
# 读取数据
path = "https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data"
name = ["Sample code number", "Clump Thickness", "Uniformity of Cell Size", "Uniformity of Cell Shape", "Marginal Adhesion", "Single Epithelial Cell Size", "Bare Nuclei", "Bland Chromatin", "Normal Nucleoli", "Mitoses", "Class"]
data = pd.read_csv(path, names=name)
# 1)替换
data_new = data.replace(to_replace="?", value=np.nan)
# 2)删除nan
data_new.dropna(inplace=True)
#查看
data_new.isnull().any()
》》》Sample code number False
Clump Thickness False
Uniformity of Cell Size False
Uniformity of Cell Shape False
Marginal Adhesion False
Single Epithelial Cell Size False
Bare Nuclei False
Bland Chromatin False
Normal Nucleoli False
Mitoses False
Class False
dtype: bool
4.7 高级处理-数据离散化
性别 年龄
A 1 23
B 2 30
C 1 18
物种 毛发
A 1
B 2
C 3
男 女 年龄
A 1 0 23
B 0 1 30
C 1 0 18
狗 猪 老鼠 毛发
A 1 0 0 2
B 0 1 0 1
C 0 0 1 1
one-hot编码&哑变量
4.7.1 什么是数据的离散化
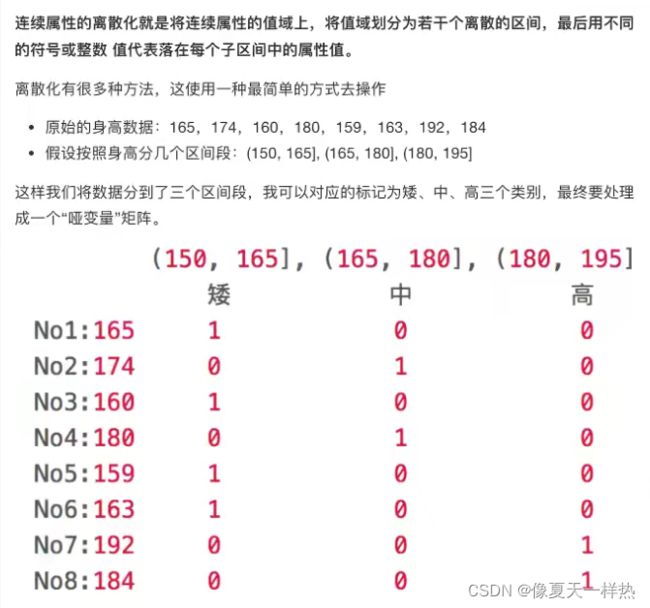
4.7.2 为什么要离散化
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
4.7.3 如何实现数据的离散化

1)分组
自动分组sr=pd.qcut(data, bins) #bins组数
自定义分组sr=pd.cut(data, []) #[]列表区间
2)将分组好的结果转换成one-hot编码
pd.get_dummies(sr, prefix=) #
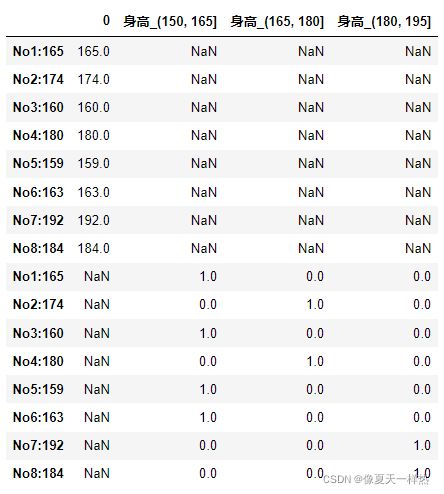
# 1)准备数据
data = pd.Series([165,174,160,180,159,163,192,184], index=['No1:165', 'No2:174','No3:160', 'No4:180', 'No5:159', 'No6:163', 'No7:192', 'No8:184'])
data
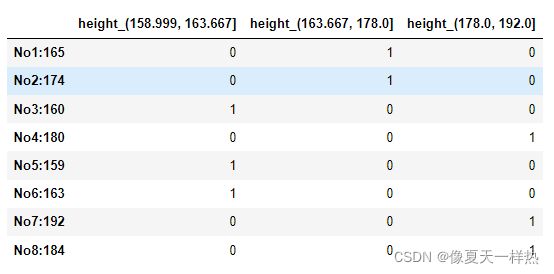
# 2)分组
# 自动分组
sr=pd.qcut(data,3)
sr
》》》No1:165 (163.667, 178.0]
No2:174 (163.667, 178.0]
No3:160 (158.999, 163.667]
No4:180 (178.0, 192.0]
No5:159 (158.999, 163.667]
No6:163 (158.999, 163.667]
No7:192 (178.0, 192.0]
No8:184 (178.0, 192.0]
dtype: category
Categories (3, interval[float64]): [(158.999, 163.667] < (163.667, 178.0] < (178.0, 192.0]]
sr.count() #查看总数据数
sr.value_counts() # 看每一组有几个数据
# 3)转换成one-hot编码
pd.get_dummies(sr, prefix="height")
自定义分组
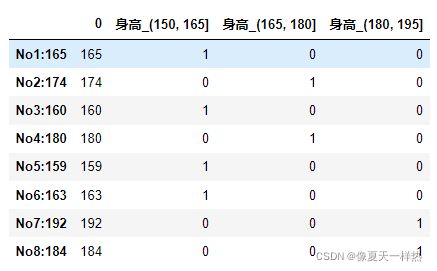
# (2)自定义分组
bins = [150, 165, 180, 195]
sr = pd.cut(data,bins)
sr
# 3)转换成one-hot编码
pd.get_dummies(sr, prefix="身高")
4.8 高级处理-合并
numpy
np.concatnate((a, b), axis=) #水平/ 竖直拼接
水平拼接
np.hstack()
竖直拼接
np.vstack()
pandas
1)按方向拼接
pd.concat([data1, data2], axis=1) #axis=0列(默认)--竖直拼接,axis=1行--水平拼接
2)按索引拼接
pd.merge实现合并
pd.merge(left, right, how="inner", on=[索引])
1)concat拼接(按方向拼接)
#水平拼接
pd.concat([data,data_new],axis=1)
#竖直拼接
pd.concat([data,data_new],axis=0)
2)按索引拼接–merge

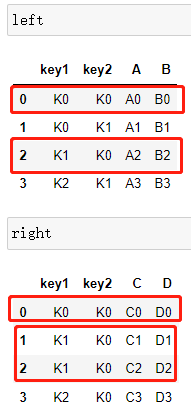
#准备数据
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
1)内连接
只保留索引中,共同含有的。
pd.merge(left,right,how='inner',on=['key1','key2'])

2)左连接
以左表为主
pd.merge(left,right,how='left',on=['key1','key2'])
3)右连接
以右表为主
pd.merge(left,right,how='right',on=['key1','key2'])
3)外连接
保留两表的数据
pd.merge(left,right,how='outer',on=['key1','key2'])
4.9 高级处理-交叉表与透视表
找到、探索两个变量之间的关系
4.9.1 交叉表与透视表什么作用
4.9.2 使用crosstab(交叉表)实现

pd.crosstab(value1, value2)
pandas日期类型
#pandas 日期类型
date=pd.to_datetime(stock_data.index)
date
》》》DatetimeIndex(['2018-02-27', '2018-02-26', '2018-02-23', '2018-02-22',
'2018-02-14', '2018-02-13', '2018-02-12', '2018-02-09',
'2018-02-08', '2018-02-07',
...
'2015-03-13', '2015-03-12', '2015-03-11', '2015-03-10',
'2015-03-09', '2015-03-06', '2015-03-05', '2015-03-04',
'2015-03-03', '2015-03-02'],
dtype='datetime64[ns]', length=643, freq=None)
date.year
》》》Int64Index([2018, 2018, 2018, 2018, 2018, 2018, 2018, 2018, 2018, 2018,
...
2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015, 2015],
dtype='int64', length=643)
date.weekday
》》》Int64Index([1, 0, 4, 3, 2, 1, 0, 4, 3, 2,
...
4, 3, 2, 1, 0, 4, 3, 2, 1, 0],
dtype='int64', length=643)
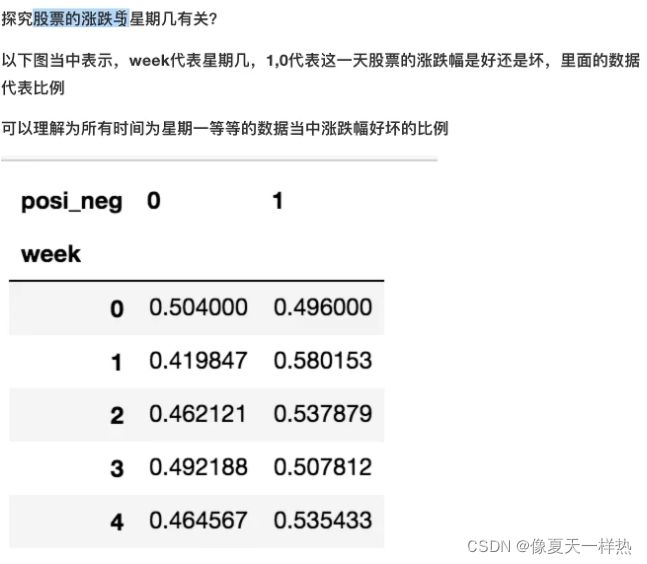
#准备星期数据列
stock_data["week"]=date.weekday
#准备涨跌幅数据列
stock_data["pona"]=np.where(stock_data["p_change"]>0,1,0)
#交叉表
data_cross=pd.crosstab(stock_data["week"],stock_data["pona"])
data_cross
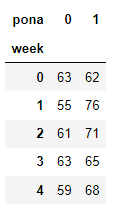
data_cross.div(data_cross.sum(axis=1),axis=0)
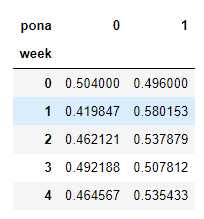
data_cross.div(data_cross.sum(axis=1),axis=0).plot(kind='bar',stacked=True)

4.9.3 使用pivot_table(透视表)

stock_data.pivot_table(["pona"], index=["week"])
4.10 高级处理-分组与聚合
4.10.1 什么是分组与聚合
例子:
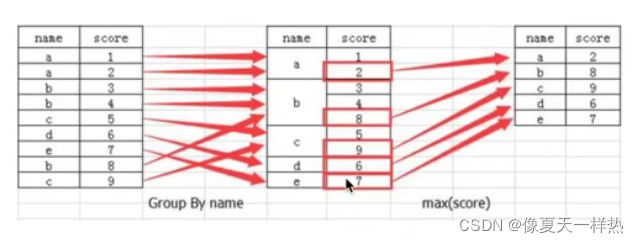
4.10.2 分组与聚合API
dataframe
sr

#创建数据
col =pd.DataFrame({'color': ['white','red','green','red','green'], 'object': ['pen','pencil','pencil','ashtray','pen'],'price1':[5.56,4.20,1.30,0.56,2.75],'price2':[4.75,4.12,1.60,0.75,3.15]})
col
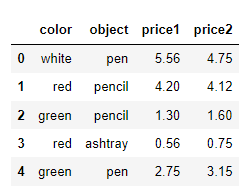
DataFrame:
# 进行分组,对颜色分组,price1进行聚合
# 用dataframe的方法进行分组
col.groupby(by="color")["price1"].max()#对颜色进行分组,根据price1进行聚合
》》》color
green 2.75
red 4.20
white 5.56
Name: price1, dtype: float64
Serics:
# 或者用Series的方法进行分组聚合
col["price1"].groupby(col["color"]).max()
》》》color
green 2.75
red 4.20
white 5.56
Name: price1, dtype: float64
哔哩哔哩