论文笔记:Enhancing Pre-trained Chinese Character Representation with Word-aligned Attention
1. 概述
目前,很多NLP算法大多采用主流的预训练模型+下游任务微调这样的算法架构。预训练模型种类繁多,如下图
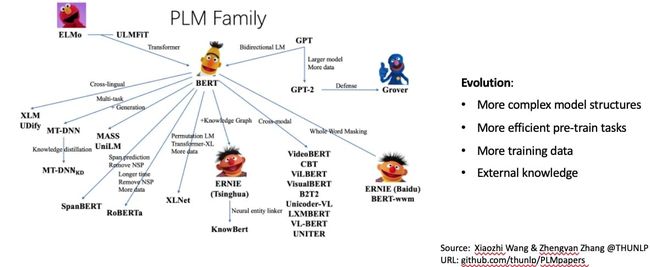
用的最多的莫过于大名鼎鼎的BERT预训练模型,同样是基于Pre-training和Fine-tuning模式架构的

不管啥模型,第一件事都是 tokenizer。对于 BERT 来说,英文的 token 是 word-piece,中文的是字(这也对后面的实验造成了很大的麻烦,因为要对齐)。而且已经有相当多的工作证明了,对于中文在 character-level 建模会比较合适(香侬在 ACL2019 的那篇《Is Word Segmentation Necessary for Deep Learning of Chinese Representations》很是经典)。不过在实际应用中,包括很多 Application of NLP 领域的文章,都发现将词信息融入到文本表示中会对应用有效果。不过将词信息融入到文本表示的过程中存在两个主要问题:①如何聚合分词后的word level信息到char level的attention中去;②如何降低分词工具不准确引入的分词噪声。
所以,这篇论文实质上就是在实验看有什么办法去各种拐着弯儿向 character-level 的表示模型融入词信息,并减轻外部分词器引入的分词噪声。
主要贡献:
① 这篇文章提出了一个word level对齐的attention机制来拓展基于char level的中文预训练模型(Multi-source Word Aligned Attention)。
② 并提出了一个mix-polling方法来讲char level的attention对齐到word level,以缓解多源分词器分词误差传播的问题。
2. 动机

语言心理学表明:在阅读中文的时候,人对每个单词中的字符的注意力是相近的,如上图所示。所以作者是想想找一些方法来改变 transformer 的 attention 分布,或者找一种可以折中 soft-attention 与 hard-attention 的方法,在维持原 attention 机制的情况下,用比较 soft 的方法来实现比较 hard 的效果,来方便某些任务;
另外,通过融合不同粒度的分词器的结果来降低单一分词器带来的分词噪声。
3. 模型
3.1 Character-level Pre-trained Encoder
利用BERT,ERNIE,BERT-wwm等预训练语言模型得到char-level的表示
3.2 Word-aligned Attention
单个分词器下的情况
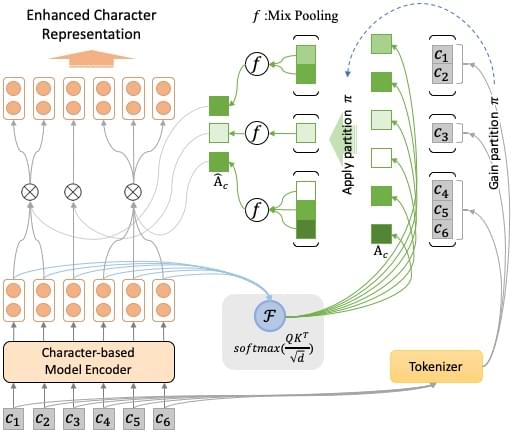
模型很简单,就是在预训练语言模型对下游任务进行微调时,中间插上一层 multi-head attention 的变体。
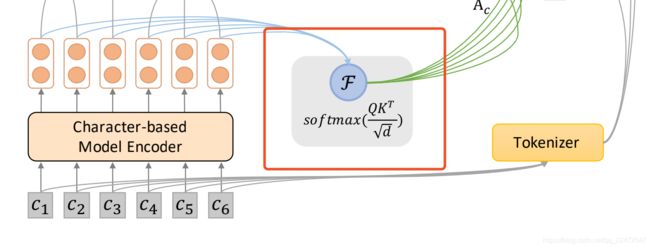
对预训练语言模型输出的每个char level的表示做self-attention
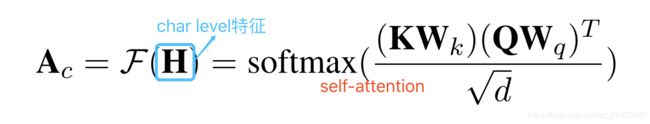
得到没有word boundary的字符之间的relationship。由于单个char的字面意在不同的word中经常会大不相同,比如 “拍” 这个char在 “球拍” 和 “拍卖” 这两个词中的语义完全不同,不能简单地直接取char level 的 weighted sum。
首先,可以使用分词工具将输入的文本进行分词,具体来说就是讲由字构成的序进行划分(parition),我们把这种划分策略称为 π。得到划分 π 后,将其应用于正常得到的 attention 权重矩阵Ac上,可以得到按词划分的(word-based)字级别(character-level)的 attention 权重组合。
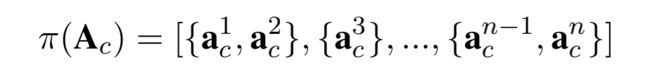
一个 { } 中代表了一个word中包含的所有char的attention score。会将这个{ }中的字符向量组对齐到相应的word的attention vector。方法就是文中提到的mixed pooling.
为了同时考虑:1. 句子中所有词的语义表示;2. 句子中最重要的词的语义表示 这两种情况,我们使用 mix-pooling 来对 mean-pooling 和 max-pooling 进行混合:
MixPooling=λMeanPooling+(1−λ)MaxPooling)
并将 { } 中的每一个char的attention vector都替换成mixed-pooling后的word vector,从而得到对齐矩阵(5)。这样就会把在char-level的attention中融入具有分词边界信息的word segment information,从而缓解由于字符在不同单词中的奇异性所带来的attention bias。具体公式如下:

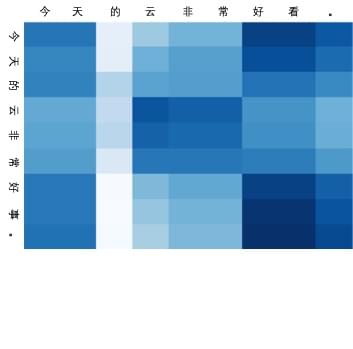
上图就是这种 attention 权重矩阵的可视化效果图。这个例子是从情感分类任务模型中拿出来试的,可以看到 attention 权重矩阵被转化为了 character-level to word-level 的形式,而实际上还是 character-level 的模型,保留了字建模的优秀表示,同时也做到了前面动机所说的接近 hard-attention 的效果。

同时,利用multi-head attention的思想得到K个不同的aligned attention矩阵,拼接降维后输出

把这样的 attention 权重再拿回 character-level 表示去调整它,就能得到最终的字表示,送往后续的下游任务。
3.3 Multi-source Word-aligned Attention
多个分词器下的情况
由于不同分词器的分词粒度不同 ,会引入分词误差,比如:
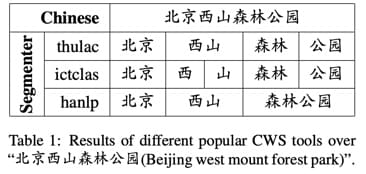
为了减少分词错误,以及用上不同粒度级别的特征,文章找了一种简单的方法,同时用上多个分词工具的分词结果。
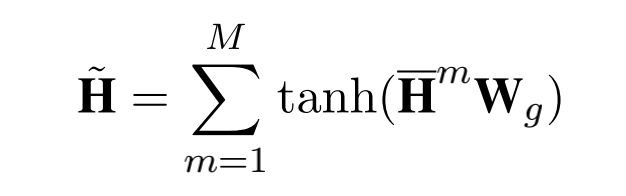
把几个分词器的结果,分别得到下游表示之后过个线性层结合在一起。
4. 总结
来自作者的自我总结和吐槽哈哈哈…
优点:
- 提出了这么一种有意思的结构
- 这么一种有意思的结构可以融入一些分词信息,并且对预训练语言模型的下游任务有一些帮助
- 单纯融入一种分词信息不够,就多加几种分词信息
缺点:
- 实在缺乏理论支撑
- 预处理的真的特别特别慢(尤其是要用几种分词器来分词),并且数据预处理无比复杂(因为各个分词器的处理逻辑都不一样,各种特殊符号、数字、英语、日语、繁体啥的全部都要单独处理,尤其是 BERT 会将英语单词 tokenize 成 word-piece,导致 token 对不上,前期实验有 80% 以上的时间都是在搞这些预处理)
- 在 forward 的时候把 transformer 的时间复杂度 O(n2)O(n2) 变成了 O(dn2)O(dn2)(这还好是常数级),但是要命的是,在这个方法中,每一条训练数据都会有各自不同的分词方式,都只能各自去分段计算 mix-pooling,这导致完全无法应用 cudnn 原语加速,也完全没可能写成矩阵运算来利用 GPU batch 加速,即使直接用 cuda 编程也没法改善。连 forward 都这么慢,backward 更不用说了……
- 总结下来,这个工作其实缺点其实挺明显的,主要集中在预处理和速度极慢这两块上。