SSD文章解读
@TOC
SIFT请参考 https://blog.csdn.net/u010440456/article/details/81483145
论文题目:SSD: Single Shot MultiBox Detector
论文链接:论文链接
论文代码:Caffe代码点击此处
This results in a significant improvement in speed for high-accuracy detection(59 FPS with mAP 74.3% on VOC2007 test, vs Faster-rcnn 7 FPS with mAP 73.2% or YOLO 45 FPS with mAP 63.4%)
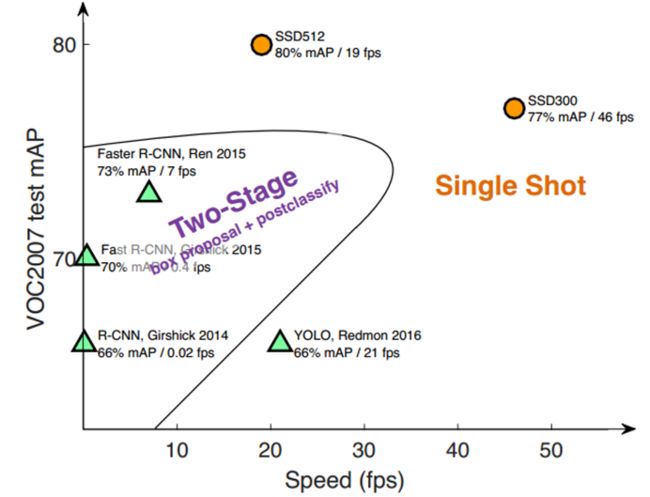
图1 SSD和其它算法的性能比较
一、SSD网络总体架构

图2 SSD网络架构(精简版)

图3 SSD网络架构(细节版)
SSD算法步骤:
1. 输入一幅图片(200x200),将其输入到预训练好的分类网络中来获得不同大小的特征映射,修改了传统的VGG16网络;
- 将VGG16的FC6和FC7层转化为卷积层,如图1上的Conv6和Conv7;
- 去掉所有的Dropout层和FC8层;
- 添加了Atrous算法(hole算法),参考该链接;
- 将Pool5从2x2-S2变换到3x3-S1;
2. 抽取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层的feature map,然后分别在这些feature map层上面的每一个点构造6个不同尺度大小的BB,然后分别进行检测和分类,生成多个BB,如图1下面的图所示;
3. 将不同feature map获得的BB结合起来,经过NMS(非极大值抑制)方法来抑制掉一部分重叠或者不正确的BB,生成最终的BB集合(即检测结果);
SSD论文贡献:
1. 引入了一种单阶段的检测器,比以前的算法YOLO更准更快,并没有使用RPN和Pooling操作;
2. 使用一个小的卷积滤波器应用在不同的feature map层从而预测BB的类别的BB偏差;
3. 可以在更小的输入图片中得到更好的检测效果(相比Faster-rcnn);
4. 在多个数据集(PASCAL、VOC、COCO、ILSVRC)上面的测试结果表明,它可以获得更高的mAp值;
二、 SSD算法细节
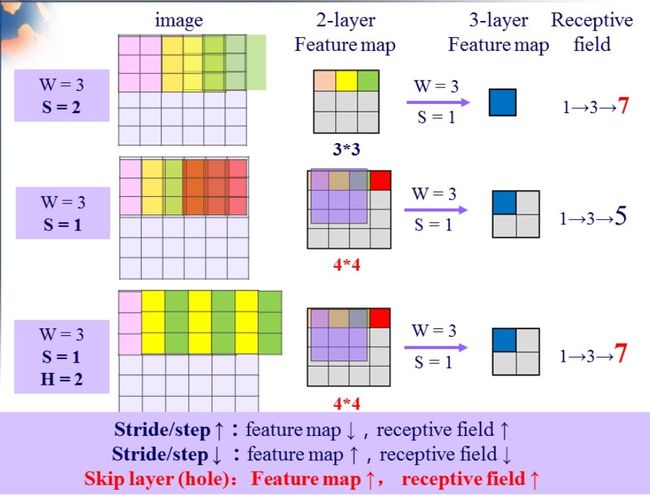
1. 多尺度特征映射
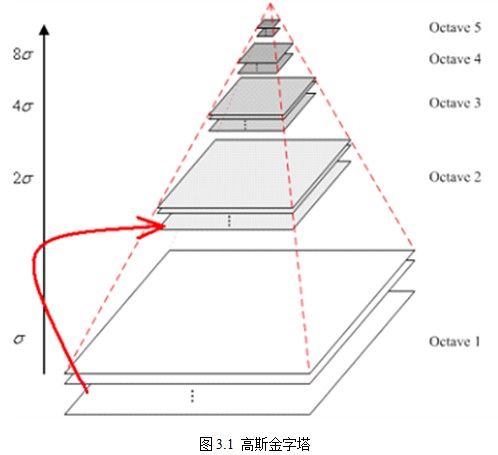
图4 高斯金字塔
做CV的你应该对上图很熟悉吧,对,没错,这就是SIFT算法中的高斯金字塔,对任意的一幅图片做一个高斯金字塔,你可以获得不同分辨率的图片,模拟了人眼看东西时近大远小的过程。这是针对整幅图像而言,那么,对于patch而言,同样也可以做这个操作。我们不仅可以在图像域做,当然我们也可以在特征域做。
传统算法与SSD算法的思路比较:
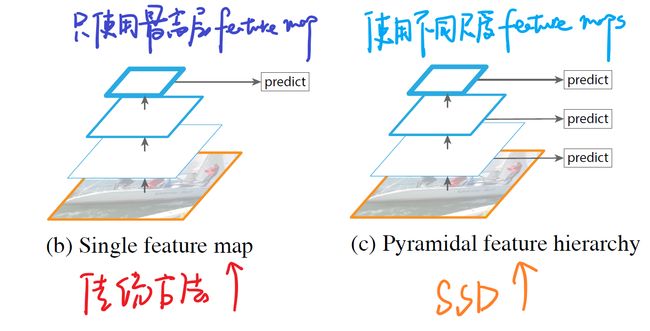
图5 传统做法和SSD做法的比较
如上图所示,我们可以看到左边的方法针对输入的图片获取不同尺度的特征映射,但是在预测阶段仅仅使用了最后一层的特征映射;而SSD不仅获得不同尺度的特征映射,同时在不同的特征映射上面进行预测,它在增加运算量的同时可能会提高检测的精度,因为它具有更多的可能性。
Faster-rcnn与SSD比较:
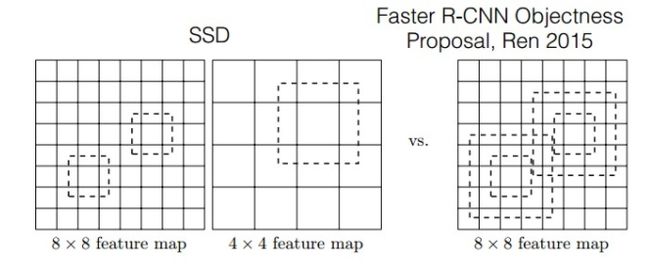
图6 Faster-rcnn与SSD比较
如图所示,对于BB的生成,Faster-rcnn和SSD有不同的策略,但是都是为了同一个目的,产生不同尺度,不同形状的BB,用来检测物体。对于Faster-rcnn而言,其在特定层的Feature map上面的每一点生成9个预定义好的BB,然后进行回归和分类操作进行初步检测,然后进行ROI Pooling和检测获得相应的BB;而SSD则在不同的特征层的feature map上的每个点同时获取6个不同的BB,然后将这些BB结合起来,最后经过NMS处理获得最后的BB。
原因剖析:
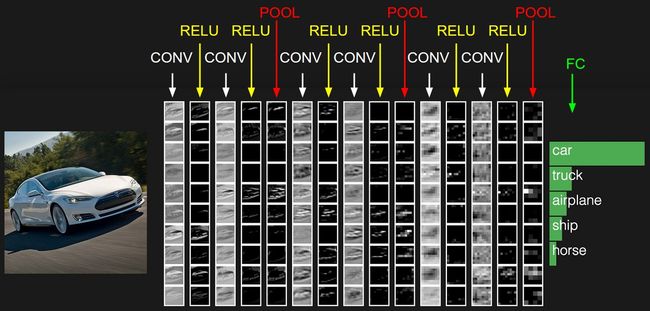
图7 不同卷积层的feature map
如上图所示,输入一幅汽车的图片,我们将其输入到一个卷积神经网络中,在这期间,经历了多个卷积层和池化层,我们可以看到在不同的卷积层会输出不同大小的feature map(这是由于pooling层的存在,它会将图片的尺寸变小),而且不同的feature map中含有不同的特征,而不同的特征可能对我们的检测有不同的作用。总的来说,浅层卷积层对边缘更加感兴趣,可以获得一些细节信息,而深层网络对由浅层特征构成的复杂特征更感兴趣,可以获得一些语义信息,对于检测任务而言,一幅图像中的目标有复杂的有简单的,对于简单的patch我们利用浅层网络的特征就可以将其检测出来,对于复杂的patch我们利用深层网络的特征就可以将其检测出来,因此,如果我们同时在不同的feature map上面进行目标检测,理论上面应该会获得更好的检测效果。
SSD多尺度特征映射细节:
SSD算法中使用到了conv4_3,conv_7,conv8_2,conv7_2,conv8_2,conv9_2,conv10_2,conv11_2这些大小不同的feature maps,其目的是为了能够准确的检测到不同尺度的物体,因为在低层的feature map,感受野比较小,高层的感受野比较大,在不同的feature map进行卷积,可以达到多尺度的目的。
2. Defalut box
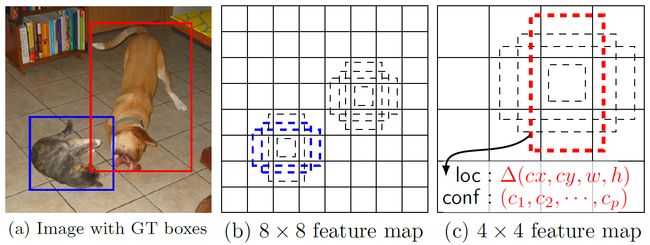
图8 default bounding box
如上图所示,在特征图的每个位置预测K个BB,对于每一个BB,预测C个类别得分,以及相对于Default box的4个偏移量值,这样总共需要(C+4)* K个预测器,则在mn的特征图上面将会产生(C+4) K * m * n个预测值。
Defalut box分析:
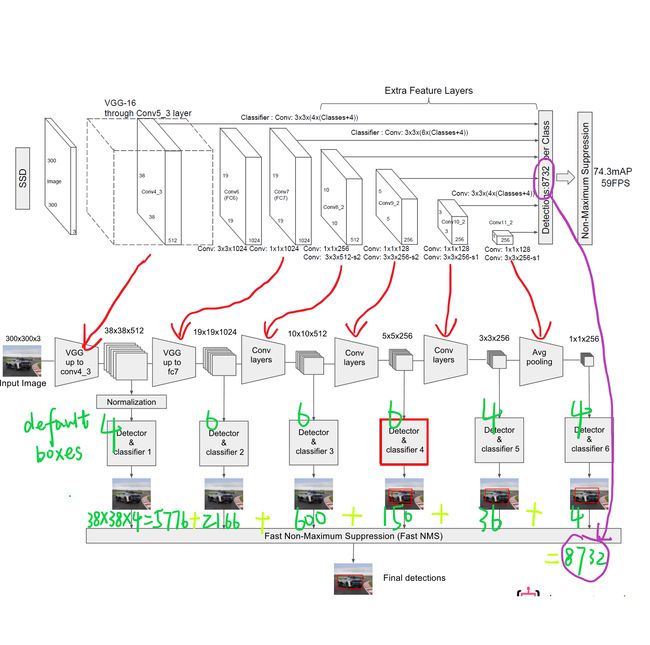
图9 Defalut box分析
SSD中的Defalut box和Faster-rcnn中的anchor机制很相似。就是预设一些目标预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。对于不同尺度的feature map 上使用不同的Default boxes。如上图所示,我们选取的feature map包括38x38x512、19x19x1024、10x10x512、5x5x256、3x3x256、1x1x256,Conv4_3之后的feature map默认的box是4个,我们在38x38的这个平面上的每一点上面获得4个box,那么我们总共可以获得38x38x4=5776个;同理,我们依次将FC7、Conv8_2、Conv9_2、Conv10_2和Conv11_2的box数量设置为6、6、6、4、4,那么我们可以获得的box分别为2166、600、150、36、4,即我们总共可以获得8732个box,然后我们将这些box送入NMS模块中,获得最终的检测结果。
以上的操作都是在特征图上面的操作,即我们在不同尺度的特征图上面产生很多的BB,如果将映射到原始图像中,我们会获得一个密密麻麻的BB集合,如下图所示:

图10 原始图像中生成的BB
Defalut box生成规则
- 以feature map上每个点的中点为中心(offset=0.5),生成一系列同心的Defalut box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)
- 使用m(SSD300中m=6)个不同大小的feature map 来做预测,最底层的 feature map 的 scale 值为 Smin=0.2,最高层的为Smax=0.95,其他层通过下面的公式计算得到:

- 使用不同的ratio值,[1, 2, 3, 1/2, 1/3],通过下面的公式计算 default box 的宽度w和高度h
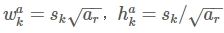
- 而对于ratio=0的情况,指定的scale如下所示,即总共有 6 中不同的 default box。
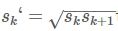
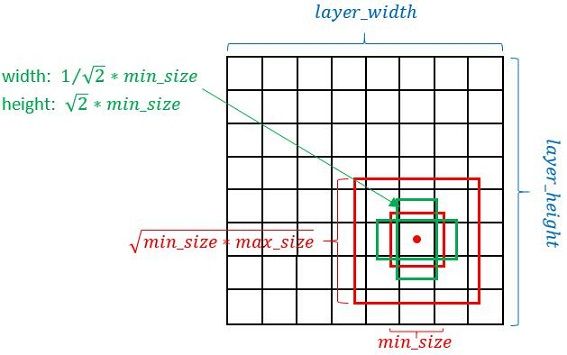
图11 default box的计算
3. LOSS计算
与常见的 Object Detection模型的目标函数相同,SSD算法的目标函数分为两部分:计算相应的default box与目标类别的confidence loss以及相应的位置回归。
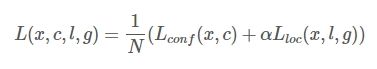
其中N是match到Ground Truth的default box数量;而alpha参数用于调整confidence loss和location loss之间的比例,默认alpha=1。
位置回归则是采用 Smooth L1 loss,目标函数为:

confidence loss是典型的softmax loss:
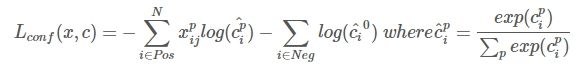
三、SSD提高精度的方法
1. 数据增强

图12 数据增强效果
如上图所示,不同于Faster-rcnn,SSD算法使用了多种数据增强的方法,包括水平翻转、裁剪、放大和缩小等。论文明确指出,数据增强可以明显的提高算法的性能。主要的目的是为了使得该算法对输入的不同大小和不同形状的目标具有更好的鲁棒性。直观的理解是通过这个数据增强操作可以增加训练样本的个数,同时构造出更多的不同形状和大小的目标,将其输入到网络中,可以使得网络学习到更加鲁棒的特征。
2. Hard Negative Mining技术
一般情况下negative default boxes数量是远大于positive default boxes数量,如果随机选取样本训练会导致网络过于重视负样本(因为抽取到负样本的概率值更大一些),这会使得loss不稳定。因此需要平衡正负样本的个数,我们常用的方法就是Hard Ngative Mining,即依据confidience score对default box进行排序,挑选其中confidience高的box进行训练,将正负样本的比例控制在positive:negative=1:3,这样会取得更好的效果。如果我们不加控制的话,很可能会出现Sample到的所有样本都是负样本(即让网络从这些负样本中找正确目标,这显然是不可以的),这样就会使得网络的性能变差。
3. 匹配策略(即如何重多个default box中找到和ground truth最接近的box)
- 首先,寻找与每一个ground truth有最大的IoU的default box,这样就能保证ground truth至少有default box匹配;
- SSD之后又将剩余还没有配对的default box与任意一个ground truth尝试配对,只要两者之间的IoU大于阈值(SSD 300 阈值为0.5),就认为match;
- 配对到ground truth的default box就是positive,没有配对的default box就是negative。
总之,一个ground truth可能对应多个positive default box,而不再像MultiBox那样只取一个IoU最大的default box。其他的作为负样本(每个default box要么是正样本box要么是负样本box)。
4. Atrous Algothrim(获得更加密集的得分映射)
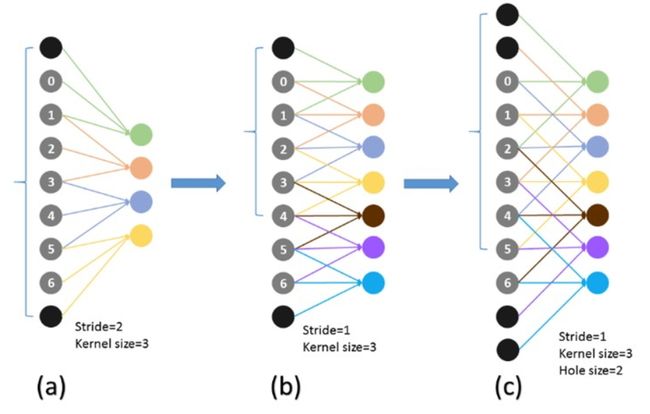
图13 Atrous Algothrim理解1
作用:既想利用已经训练好的模型进行fine-tuning,又想改变网络结构得到更加dense的score map。
这个解决办法就是采用Hole算法。如下图(a) (b)所示,在以往的卷积或者pooling中,一个filter中相邻的权重作用在feature map上的位置都是物理上连续的。如上图©所示,为了保证感受野不发生变化,某一层的stride由2变为1以后,后面的层需要采用hole算法,具体来讲就是将连续的连接关系是根据hole size大小变成skip连接的(图©为了显示方便直接画在本层上了)。不要被©中的padding为2吓着了,其实2个padding不会同时和一个filter相连。 pool4的stride由2变为1,则紧接着的conv5_1, conv5_2和conv5_3中hole size为2。接着pool5由2变为1, 则后面的fc6中hole size为4。
在SSD算法中,NMS至关重要,因为多个feature map 最后会产生大量的BB,然而在这些BB中存在着大量的错误的、重叠的、不准确的BB,这不仅造成了巨大的计算量,如果处理不好会影响算法的性能。仅仅依赖于IOU(即预测的BB和GT的BB之间的重合率)是不现实的,IOU值设置的太大,可能就会丢失一部分检测的目标,即会出现大量的漏检情况;IOU值设置的太小,则会出现大量的重叠检测,会大大影响检测器的性能,因此IOU的选取也是一个经验活,常用的是0.65,建议使用论文中作者使用的IOU值,因为这些值一般都是最优值。即在IOU处理掉大部分的BB之后,仍然会存在大量的错误的、重叠的、不准确的BB,这就需要NMS进行迭代优化。NMS的迭代过程可以看我以前的博客。链接
四、SSD性能评估
1. 模块性能评估

表1 模块性能评估
观察上图可以得到如下的结论:
- 数据增强方法在SSD算法中起到了关键性的作用,使得mAP从65.5变化到71.6,主要的原因可能是数据增强增加了样本的个数,使得模型可以获得更重更样的样本,即提高了样本的多样性,使得其具有更好的鲁棒性,从而找到更接近GT的BB。
- [1/2,2]和[1/3, 3]box可以在一定程度上提升算法的性能,主要的原因可能是这两种box可以在一定程度上增加较大和较小的BB,可以更更加准确的检测到较大和较小的目标,而且VOC数据集上面的目标一般都比较大。当然,更多的比例可以进一步提升算法的性能。
- atrous算法可以轻微提升算法性能,但是其主要的作用是用来提速,论文中表明它可以提速20%。主要的原因可能是虽然该算法可以获得更大的feature map和接收场,但是由于SSD本身利用了多个feature map来获取BB,BB的多样性已经足够,由于feature map扩大而多得到的BB可能是一些重复的,并没有起到提升检测性能的作用。
2. SSD加速的原因

表2 SSD的BB个数
如上图所示,当Faster-rcnn的输入分辨率为1000x600时,产生的BB是6000个;当SSD300的输入分辨率为300x300时,产生的BB是8372个;当SSD512的输入分辨率为512x512时,产生的BB是24564个,大家像一个情况,当SSD的分辨率也是1000x600时,会产生多少个BB呢?这个数字可能会很大!但是它却说自己比Faster-rcnn和YOLO等算法快很多,我们来分析分析原因。
- 原因1:首先SSD是一个单阶段网络,只需要一个阶段就可以输出结果;而Faster-rcnn是一个双阶段网络,尽管Faster-rcnn的BB少很多,但是其需要大量的前向和反向推理(训练阶段),而且需要交替的训练两个网络;
- 原因2:Faster-rcnn中不仅需要训练RPN,而且需要训练Fast-rcnn,而SSD其实相当于一个优化了的RPN网络,不需要进行后面的检测,仅仅前向推理就会花费很多时间;
- 原因3:YOLO网络虽然比SSD网络看起来简单,但是YOLO网络中含有大量的全连接层,和FC层相比,CONV层具有更少的参数;同时YOLO获得候选BB的操作比较费时;
- 原因4:SSD算法中,调整了VGG网络的架构,将其中的FC层替换为CONV层,这一点会大大的提升速度,因为VGG中的FC层都需要大量的运算,有大量的参数,需要进行前向推理;
- 原因5:使用了atrous算法,具体的提速原理还不清楚,不过论文中明确提出该算法能够提速20%。
- 原因6:SSD设置了输入图片的大小,它会将不同大小的图片裁剪为300x300,或者512x512,和Faster-rcnn相比,在输入上就会少很多的计算,不要说后面的啦,不快就怪啦!!!
3. SSD准确率评估
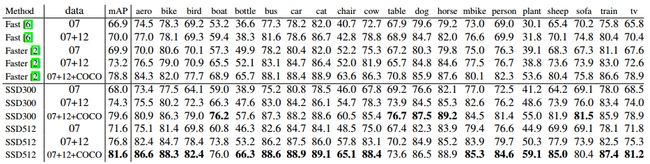
表3 VOC2007评估结果

表4 VOC2012评估结果
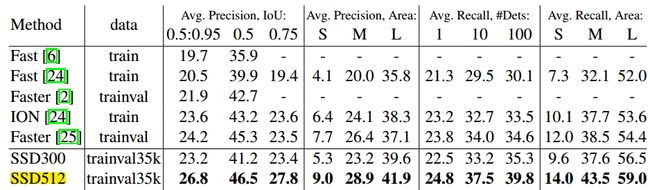
表5 COCO评估结果
分析:如上表所示,我们可以观察到在不同数据集上面(VOC2007、VOC2012、COCO),SSD512都获得了最佳的性能,在这里进行了加粗。可以看出,Faster-rcnn和SSD相比,在IOU上面最少相差3个点。
当然这只是作者的结果,具体的结果你可以去测试。好了,我不喜欢在博客里写这些东西,详细的分析经仔细阅读原文。
4. SSD算法的优缺点
优点:运行速度超过YOLO,精度超过Faster-rcnn(一定条件下,对于稀疏场景的大目标而言)。
缺点:
- 需要人工设置prior box的min_size,max_size和aspect_ratio值。网络中default box的基础大小和形状不能直接通过学习获得,而是需要手工设置。而网络中每一层feature使用的default box大小和形状恰好都不一样,导致调试过程非常依赖经验。(相比之下,YOLO2使用聚类找出大部分的anchor box形状,这个思想能直接套在SSD上)
- 虽然采用了pyramdial feature hierarchy的思路,但是对小目标的recall依然一般,并没有达到碾压Faster RCNN的级别。可能是因为SSD使用conv4_3低级feature去检测小目标,而低级特征卷积层数少,存在特征提取不充分的问题。
个人观点:SSD到底好不好,需要根据你的应用和需求来讲,真正合适你的应用场景的检测算法需要你去做性能验证,比如你的场景是密集的包含多个小目标的,我很建议你用Faster-rcnn,针对特定的网络进行优化,也是可以加速的;如果你的应用对速度要求很苛刻,那么肯定首先考虑SSD,至于那些测试集上的评估结果,和真实的数据还是有很大的差距,算法的性能也需要进一步进行评估。
五、总结
SSD算法是在YOLO的基础上改进的单阶段方法,通过融合多个feature map上的BB,在提高速度的同时提高了检测的精度,性能超过了YOLO和Faster-rcnn。下图是其检测结果:

图15 SSD检测效果
参考文献:
1 SSD论文阅读(Wei Liu——【ECCV2016】SSD Single Shot MultiBox Detector),相关链接
2 物体检测论文-SSD和FPN,相关链接
3 目标检测之YOLO,SSD,相关链接
4 论文阅读:SSD: Single Shot MultiBox Detector,相关链接
[5] http://blog.csdn.net/u014380165/article/details/72824889,相关链接
注意事项:
1 该博客是本人原创博客,如果您对该博客感兴趣,想要转载该博客,请与我联系(qq邮箱:[email protected]),我会在第一时间回复大家,谢谢大家。
2 由于个人能力有限,该博客可能存在很多的问题,希望大家能够提出改进意见。
3 如果您在阅读本博客时遇到不理解的地方,希望可以联系我,我会及时的回复您,和您交流想法和意见,谢谢。
欢迎使用Markdown编辑器
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
新的改变
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
强调文本 强调文本
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
图片: 
带尺寸的图片:
居中的图片: 
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图::
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件或者.html文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
mermaid语法说明 ↩︎
注脚的解释 ↩︎