Python爬虫+selenium——爬取淘宝商品信息和数据分析
浏览器驱动
点击下载chromedrive 。将下载的浏览器驱动文件chromedriver丢到Chrome浏览器目录中的Application文件夹下,配置Chrome浏览器位置到PATH环境。
需要用到的库
selenium库,time库,re库,csv库,json库,pandas库,matplotlib库,jieba库,wordcloud库
1.爬取显卡商品信息的效果图
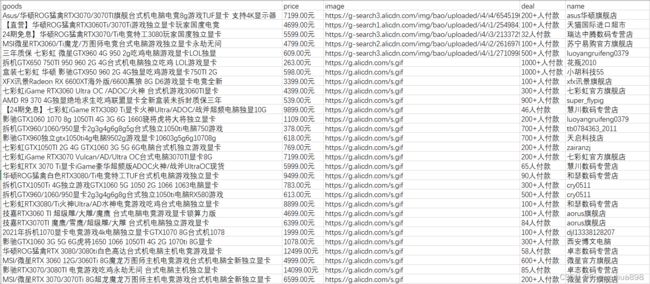
2.相关操作与代码
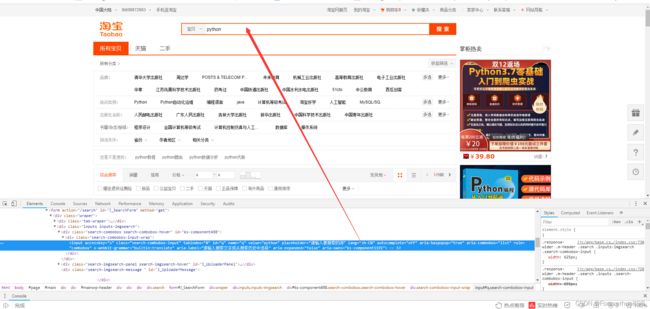
先找到搜索框并用selenium模拟点击(发现需要登录,我直接扫码登录,没有写模拟登录的过程)
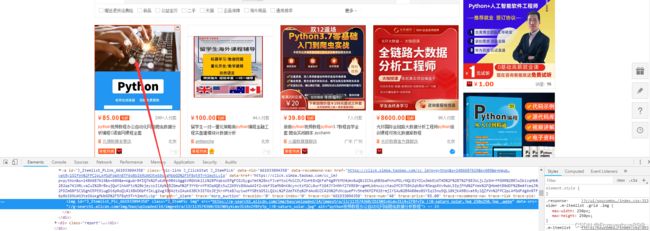
结合网页源代码,用xpath获得商品数据
from selenium import webdriver
import time
import re
import csv
from selenium.webdriver.common.by import By
import json
#输入框,搜索按钮
def search_product():
driver.find_element(By.XPATH,'//*[@id="q"]').send_keys(kw)
driver.find_element(By.XPATH,'//*[@id="J_TSearchForm"]/div[1]/button').click()
# 扫码登录
# driver.find_element(By.XPATH,'//*[@id="login"]/div[1]/i').click()
#阻止程序运行10s
time.sleep(10)
#得到查询的总页数
token=driver.find_element(By.XPATH,'//*[@id="mainsrp-pager"]/div/div/div/div[1]').text
token=int(re.compile('(\d+)').search(token).group(1))
return token
#页面滚动
def drop_down():
js = "document.documentElement.scrollTop=10000" # 下拉加载
driver.execute_script(js)
time.sleep(2)
#获得商品数据
def get_product():
#//代表任意位置
divs = driver.find_elements(By.XPATH,'//div[@class="items"]/div[@class="item J_MouserOnverReq "]')
for div in divs:
# div.find_element_by_xpath('.//a')被淘汰了
#产品名字
goods = div.find_element(By.XPATH,'.//div[@class="row row-2 title"]').text
#价格
price = div.find_element(By.XPATH,'.//div[@class="price g_price g_price-highlight"]/strong').text + '元'
#产品图片
image = div.find_element(By.XPATH,'.//div[@class="pic"]/a/img').get_attribute('src')
#交易量
deal = div.find_element(By.XPATH,'.//div[@class="deal-cnt"]').text
#店家名字
name = div.find_element(By.XPATH,'.//div[@class="shop"]/a/span[2]').text
data_dict = {} # 定义一个字典存储数据
data_dict["goods"] = goods
data_dict["price"] = price
data_dict["image"] = image
data_dict["deal"] = deal
data_dict["name"] = name
print(data_dict) # 输出这个字典
data_list.append(data_dict) # 将数据存入全局变量中
#主函数
def next_page():
token=search_product()
drop_down()
get_product()
num=1
while num != token:
print('--------------------------------------------------------------')
print("第%s页:" % str(num + 1))
driver.get('https://s.taobao.com/search?q={}&s={}'.format(kw, 44*num))#可以防止反扒
#time.sleep(4)
#智能等待 最高等待时间为10s 如果超出10s 抛出异常
#无限循环进入网页 可能会造成网页卡顿
driver.implicitly_wait(10)
drop_down()
get_product()
num += 1
#存取数据
def save():
content = json.dumps(data_list, ensure_ascii=False, indent=2)
# 把全局变量转化为json数据
with open("taobao.json", "a+", encoding="GBK") as f:
f.write(content)
print("json文件写入成功")
with open('taobao.csv', 'w', encoding='GBK', newline='') as f:
# 表头
title = data_list[0].keys()
# 声明writer
writer = csv.DictWriter(f, title)
# 写入表头
writer.writeheader()
# 批量写入数据
writer.writerows(data_list)
print('csv文件写入完成')
if __name__ =='__main__':
data_list = [] # 设置全局变量来存储数据
kw=input('请输入你想要查询的商品:')
#浏览器
driver= webdriver.Chrome()
#最大化窗口
driver.maximize_window()
driver.get('https://www.taobao.com/')
next_page()
save()3.商品数据分析
价格数据分析
import pandas as pd
from matplotlib import pyplot as plt
list=[]
# matplotlib中文显示
plt.rcParams['font.family'] = ['sans-serif']
plt.rcParams['font.sans-serif'] = ['SimHei']
# 读取数据
data = pd.read_csv('taobao.csv',index_col = None,encoding='GBK')
datas=data["price"]
for i in datas:
list.append(i)
# 价格分布
plt.figure(figsize=(15,20))
plt.hist(list,bins=10,alpha=0.6)
plt.title('价格频率分布直方图')
plt.xlabel('价格')
plt.ylabel('频数')
plt.savefig('价格分布.png')
plt.show() 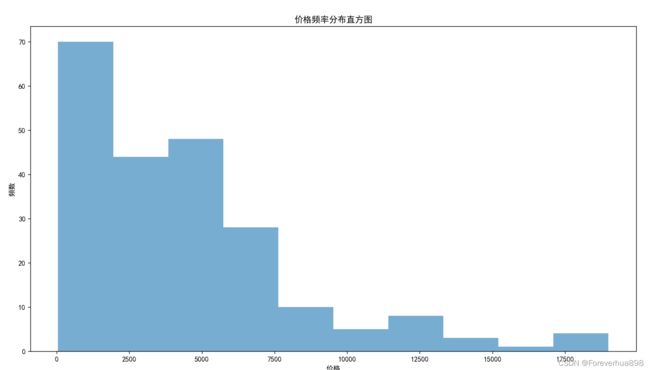
词云分析
import pandas as pd
import jieba
from wordcloud import WordCloud
# 制作词云
data = pd.read_csv('taobao.csv',index_col = None,encoding='utf-8')
content = ''
for i in range(len(data)):
content += data['goods'][i]
wl = jieba.cut(content,cut_all=True)
wl_space_split = ' '.join(wl)
wc = WordCloud('simhei.ttf',
background_color='white', # 背景颜色
width=1000,
height=600,).generate(wl_space_split)
wc.to_file('词云.png')
