CTR 预测理论(四):集成学习之模型融合与随机森林(Random Forest)
集成学习与随机森林(Random Forest)
在KDD CUP、Kaggle、天池等数据挖掘比赛中,常常用到集成学习。使用了集成学习后,模型的效果往往有很大的进步。
本文将介绍常见的集成学习方法,包括但不限于:
- 集成学习为什么有效
- Voting
- Linear Blending
- Stacking
- Bagging
- 随机森林
1. 集成学习
如果硬要把集成学习进一步分类,可以分为两类,一种是把强分类器进行强强联合,使得融合后的模型效果更强,称为模型融合。另一种是将弱分类器通过学习算法集成起来变为很强的分类器,称为机器学习元算法。
这里我们把用来进行融合的学习器称为个体学习器。
模型融合的代表有:投票法(Voting)、线性混合(Linear Blending)、Stacking。
而机器学习元算法又可以根据个体学习器之间是否存在依赖关系分为两类,称为Bagging和Boosting:
- Bagging: 个体学习器不存在依赖关系,可同时对样本随机采样并行化生成个体学习器。代表作为随机森林(Random Forest)
- Boosting: 个体学习器存在依赖关系,基于前面模型的训练结果误差生成新的模型,必须串行化生成。代表的算法有:Adaboost、GBDT、XGBoost
其中,Boosting相关的内容将在CTR 预测理论(四)进行介绍。
1.1 个体学习器
集成学习(ensemble learning)的一般结构:先产生一组“个体学习器”(individual learner),再用某种策略将他们结合起来,如下图所示,
个体学习器通常由一个现有的学习算法从训练数据产生:
-
只包含同种类型的个体学习器,这样的集成是“同质”的(homogeneous)。同质集成中的个体学习器亦称为”基学习器“(base learning),相应的学习算法称为”基学习算法“(base learning algorithm)。
-
集成也可包含不同类型的个体学习器,这样集成是”异质“的(heterogeneous)。相应的个体学习器,常称为”组件学习器“(component learning)或直接称为个体学习器。
在一般的经验中,如果把好坏不等的东西掺到一起,那么通常结果会是比坏的好一些,比好的要坏一些。集成学习把多个学习器结合起来,如何能获得比最好的单一学习器更好的性能呢?
- 弱学习器:弱学习器常指泛化性能略优于随机猜测的学习期;例如在二分类问题上精度略高于50%的分类器。
- 要获得好的集成个体学习器应“好而不同”,即个体学习器要有一定的“准确性”,即学习器不能太坏,并且要有“多样性”(diversity),即学习器间具有差异。
- 个体学习器应该至少不差于弱学习器
目前集成学习的方法大致可以分为两种:
- 个体学习器之间存在强依赖关系、必须串行生成的序列化方法。(Boosting)
- 个体学习器之间不存在强依赖关系、可同时生成的并行化方法。(Bagging和RF)
1.2 Boosting 简述
1.2.1 Boosting
Boosting是一族将弱学习器提升为强学习器的算法。工作机制如下:
先从初始训练集中训练出一个基学习器,再根据基学习器的表现对训练样本进行调整,使得先前基学习器错的的训练样本在后继受到更多的关注,然后基于调整后的样本分布来训练下一个基学习器;如此重复进行,直至基学习器的数目达到实现指定的值T,最终将这T个学习器进行加权结合。
具体概念可参考本博客中关于AdaBoost, GBDT与XGBoost区别章节
1.2.2 AdaBoost
Boosting 族算法最著名的代表是AdaBoost。该算法有多重推导方式,比较容易理解的是“加性模型”,即基学习器的线性组合来最小化指数损失函数。
算法基本流程如下:
- 初始化样本权值分布
- 基于分布 D t D_t Dt 从数据集中训练出分类器 h t h_t ht
- 估计 h t h_t ht 的误差,若误差 > 0.5 则重新下一轮训练
- 确定分类器 h t h_t ht 的权重
- 更新样本分布
- 若未达到预制的训练轮数,则继续进行训练
Boosting算法要求基学习器能对特定的数据分布进行学习,这可以通过“重赋权”实施,即在训练的每一轮中,根据样本为每个训练样本重新赋予一个权重。
对于无法接受带权样本的基学习算法,可以通过“重采样”来处理,再用重采样的样本集对基学习器进行训练。一般而言这两种算法没有优劣差别。
需要注意的是Boosting算法在训练的每一轮都要检查当前生成的基学习器是否满足基本条件(检查基分类器是否比随机猜测好),一旦条件不满足,当前基学习器被抛弃掉,学习过程停止。
在这种情形下,初始设置的学习轮数T也许还远远未达到,可能导致最终集成中只包含很少的基学习器而导致性能不佳。
若采用“重采样”,则可以获得“重启动”机会避免过早停止。即在抛弃不满足条件的当前基学习器之后,根据当前的分布重新对训练样本进行采样,再基于新的采样结果重新训练出基学习器,从而使得学习过程可以持续到预制的T轮。
从“偏差-方差”分解的角度看,Boosting主要关注降低偏差,因此基于泛化性能相当弱学习器能构建出很强的集成。
关于AdaBoost的详细推导可参考本博客中
CTR 预测理论(四):集成学习之Boosting家族(AdaBoost+GBDT)
Bagging,Boosting的主要区别
- 样本选择上:Bagging采用的是Bootstrap随机有放回抽样;而Boosting每一轮的训练集是不变的,改变的只是每一个样本的权重。
- 样本权重:Bagging使用的是均匀取样,每个样本权重相等;Boosting根据错误率调整样本权重,错误率越大的样本权重越大。
- 预测函数:Bagging所有的预测函数的权重相等;Boosting中误差越小的预测函数其权重越大。
- 并行计算:Bagging各个预测函数可以并行生成;Boosting各个预测函数必须按顺序迭代生成。
下面是将决策树与这些算法框架进行结合所得到的新的算法:
1)Bagging + 决策树 = 随机森林
2)AdaBoost + 决策树 = 提升树
3)Gradient Boosting + 决策树 = GBDT
2. 模型融合
上面提到,模型融合是把强分类器进行强强联合,变得更强。
在进行模型融合的时候,也不是说随意的融合就能达到好的效果。进行融合时,所需的集成个体(就是用来集成的模型)应该好而不同。好指的是个体学习器的性能要好,不同指的是个体模型的类别不同。
这里举个西瓜书的例子,在介绍例子之前,首先提前介绍简单投票法,以分类问题为例,就是每个分类器对样例进行投票,哪个类别得到的票数最多的就是融合后模型的结果。

在上面的例子中,采用的就是简单的投票法。中间的图b各个模型输出都一样,因此没有什么效果。第三个图c每个分类器的精度只有33%,融合后反而更糟。也就是说,想要模型融合有效果,个体学习器要有一定的准确率,并且要有多样性,学习器之间具有差异,即”好而不同“。
如何做到好而不同呢?可以由下面几个方面:
- 针对输入数据:使用采样的方法得到不同的样本(比如bagging方法采用自助法进行抽样)
- 针对特征:对特征进行抽样
- 针对算法本身:
- 个体学习器 h t h_t ht 来自不同的模型集合
- 个体学习器 h t h_t ht 来自于同一个模型集合的不同超参数,例如学习率η不同
- 算法本身具有随机性,例如用不同的随机种子来得到不同的模型
- 针对输出:对输出表示进行操纵以增强多样性
- 如将多分类转化为多个二分类任务来训练单模型
- 将分类输出转化为回归输出等
那么进行模型融合为什么比较好呢?虽然有俗话说:三个臭皮匠赛过诸葛亮,但是我们还是想知道,究竟是如何“赛过诸葛亮”的。这里摘录西瓜书如下:
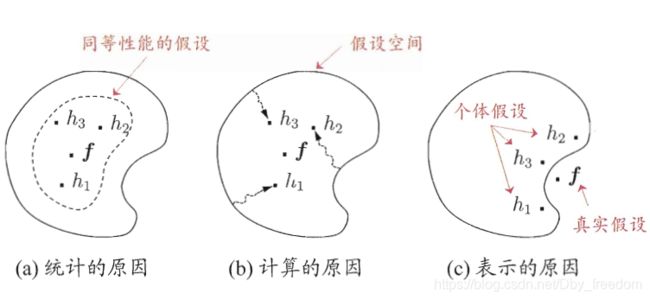
学习器的结合可能会从三个方面带来好处:
首先,从统计的方面来看,由于学习任务的假设空间往往很大,可能有多个假设在训练集上达到相同的性能,此时若使用单学习器,可能因误选而导致泛化性能不佳,结合多个学习器则会减少这一风险;
第二,从计算的方面来看,学习算法往往会陷入局部极小,有的局部极小点所对应的泛化性能可能很糟糕,而通过多次运行之后进行结合,可降低陷入糟糕局部极小点的风险;
第三,从表示的方面来看,某些学习任务的真实假设可能不在当前学习算法所考虑的假设空间中,此时若使用单学习器则肯定无效,而通过结合多个学习器,由于相应的假设空间有所扩大,有可能学得更好的近似。
下面介绍模型融合常见的方法。
2.1 投票和平均 Voting and Average
2.1.1 分类
对于分类任务来说,学习器 h i h_i hi 将从类别标记集合 c 1 , c 2 , … , c N {c_1, c_2, \dots, c_N} c1,c2,…,cN 中预测出一个标记,最常见的结合策略是使用 投票法(voting)。为了便于讨论,我们将 h i h_i hi在样本 x x x上的预测输出表示为一个 N N N维向量 h i 1 ( x ) ; h i 2 ( x ) ; … ; h i N ( x ) h_i^1(x); h_i^2(x); \dots; h_i^N(x) hi1(x);hi2(x);…;hiN(x),其中 h i j ( x ) h_i^j(x) hij(x)是 h i h_i hi在类别标记 c j c_j cj上的输出。
-
绝对多数投票法(majority voting)
H ( x ) = { c j , i f ∑ i = 1 T h i j ( x ) > 0.5 r e j e c t , o t h e r w i s e . H(x) = \begin{cases} c_j, & if \ \sum_{i=1}^{T}h_i^j(x) > 0.5 \\ reject, & \ otherwise. \end{cases} H(x)={cj,reject,if ∑i=1Thij(x)>0.5 otherwise.
即若某标记得票过半数,则预测为该标记;否则拒绝预测。 -
相对多数投票法(plurality voting)
H ( x ) = c a r g m i n x ∑ i = 1 T h i j ( x ) H({\bf x}) =c_{\underset{x}{\mathrm{argmin}}}\sum_{i=1}^Th_i^j({\bf x}) H(x)=cxargmini=1∑Thij(x)
即预测为得票最多的标记,若同时有多个暴击获最高票,则从中随机选取一个。 -
加权投票法(weighted voting)
H ( x ) = c a r g m i n x ∑ i = 1 T α i ⋅ h i j ( x ) H({\bf x}) =c_{\underset{x}{\mathrm{argmin}}}\sum_{i=1}^T\alpha_i\cdot h_i^j({\bf x}) H(x)=cxargmini=1∑Tαi⋅hij(x)
和上面的简单投票法类似,不过多了权重 α i \alpha_i αi,这样可以区分分类器的重要程度,通常 α i ≥ 0 ; ∑ i = 1 T α i = 1 \alpha_i \ge 0;\hspace{1ex} \sum_{i=1}^T\alpha_i = 1 αi≥0;∑i=1Tαi=1此外,个体学习器可能产生不同的 h i j ( x ) h_i^j({\bf x}) hij(x) 的值,比如类标记和类概率。
- 类标记 h i j ( x ) ∈ { 0 , 1 } h_i^j({\bf x}) \in \{0, 1\} hij(x)∈{0,1},若 h i h_i hi将样本 x 预测为类别 c j c_j cj 取值为1,否则为0。使用类标记的投票亦称“硬投票”。(其实就是多分类的输出),使用类标记的称为硬投票
- 类概率 h i j ( x ) ∈ [ 0 , 1 ] h_i^j({\bf x}) \in [0, 1] hij(x)∈[0,1],即输出类别为 c j c_j cj 的概率。使用类概率的投票称为软投票。对应 sklearn 中的 VotingClassifier 中voting 参数设为 soft。
Note:使用类概率进行结合往往比直接基于类标记的效果好,即使分类器估计出的概率值一般都不太准确。
标准的绝对多数投票法提供了“拒绝预测”选项,这在可靠性要求较高的学习任务中是一个很好的机制。但若学习任务要求必须提供预测结果,则绝对多数投票法将退化为相对多数投票法。详细论述可参考周志华 《机器学习》 P 1 83 P_183 P183页解释。
-
学习法
初级学习器+次级学习器,引入stacking集成架构,见下文。
2.1.2 回归
对于回归任务来说,采用的为平均法:
- 简单平均: H ( x ) = 1 T ∑ i = 1 T h i ( x ) H({\bf x}) =\frac{1}{T} \sum_{i=1}^Th_i({\bf x}) H(x)=T1∑i=1Thi(x)
- 加权平均: H ( x ) = 1 T ∑ i = 1 T α i ⋅ h i ( x ) ; α i ≥ 0 ; ∑ i = 1 T α i = 1 H({\bf x}) =\frac{1}{T} \sum_{i=1}^T\alpha_i \cdot h_i({\bf x}) ; \ \ \alpha_i \ge 0; \ \ \sum_{i=1}^T\alpha_i = 1 H(x)=T1∑i=1Tαi⋅hi(x); αi≥0; ∑i=1Tαi=1
由于加权平均法一般是从训练数据中学习而得,现实任务中训练样本通常不充分或者存在噪声,使得学出来的权值不可靠。同时学习的权重过多会导致过拟合,因此加权平均未必优于简单平均。
Note: 一般性能相差大学习器加权平均,相近简单平均。
2.2 线性混合 Linear Blending
前面提到过加权平均法,每个个体学习器的权重不再相等,看起来就像是对每个个体学习器做一个线性组合,这也是线性混合法名字的由来。那么最优的权重是什么呢?一个直接的想法就是最好的 α i \alpha_i αi 使得 error 最小,即对应了优化问题:
min α t ≥ 0 1 M ∑ i = 1 M ( y i – ∑ t = 1 T α t h t ( x i ) ) 2 \min_{\alpha_t\ge0}\ \frac{1}{M}\sum_{i=1}^M\left(y_i – \sum_{t=1}^T \alpha_th_t({\bf x}_i)\right)^2 αt≥0min M1i=1∑M(yi–t=1∑Tαtht(xi))2
这里有 T 个体学习器,每个学习器用 h t h_t ht 表示,而 α t \alpha_t αt 就是对应的权重。
这个优化问题很像之前讲的求解概率 SVM(Platt模型)分为两阶段求解。这里我们首先用训练数据训练出所有的 h,然后再做线性回归求出 α t \alpha_t αt 。注意到这里要求 α t ≥ 0 \alpha_t \ge 0 αt≥0,来个拉格朗日函数?其实不用,通常我们可以忽略这个条件。以二分类为例如果 α i \alpha_i αi 小于0,相当于把模型反过来用。(假如给你个错误率99%的模型,你反过来用正确率不就99%了么!)
如何得到 h t h_t ht 呢?这里我们将个体学习器称为初级学习器,用于结合的学习器称为次级学习器。首先从数据集中训练出初级学习器,然后”生成“一个新的数据集用于训练次级学习器。注意为了防止过拟合,我们需要在训练集上做训练得到初级学习器 h t h_t ht,而在验证集上比较不同 α \alpha α 的好坏。最终模型则在所有的数据上进行训练(数据量多可能使得模型效果更好)
步骤如下:
- 从训练集 D t r a i n D_{train} Dtrain 中训练得到 h 1 − , h 2 − , ⋯ , h t − h_1^-,h_2^-,\cdots,h_t^- h1−,h2−,⋯,ht−,并对验证集** D v a l D_{val} Dval中的数据 ( x i , y i ) ({\bf x_i},y_i) (xi,yi) 做转换为新的数据集 ( Φ − ( x i ) , y i ) (\Phi^-({\bf x_i}),y_i) (Φ−(xi),yi),其中 Φ − ( x i ) = ( h 1 − ( x i ) , h 2 − ( x i ) , ⋯ , h t − ( x i ) ) \Phi^-({\bf x_i}) = (h_1^-({\bf x_i}),h_2^-({\bf x_i}),\cdots,h_t^-({\bf x_i})) Φ−(xi)=(h1−(xi),h2−(xi),⋯,ht−(xi))
- 用线性回归求解 α = L i n ( { ( z i , y i ) } ) \alpha = Lin\left(\{(z_i, y_i)\}\right) α=Lin({(zi,yi)})
- 最后,用所有的数据 D 求解得到 h 1 , h 2 , ⋯ , h t h_1,h_2,\cdots,h_t h1,h2,⋯,ht,组成特征变换向量 Φ ( x ) = ( h 1 ( x ) , h 2 ( x ) , ⋯ , h t ( x ) ) \Phi({\bf x}) = (h_1({\bf x}),h_2({\bf x}),\cdots,h_t({\bf x})) Φ(x)=(h1(x),h2(x),⋯,ht(x))
- 对于新数据 x, f ( x ) = 1 T ∑ t = 1 T α t h t ( x ) f({\bf x}) = \frac{1}{T}\sum_{t=1}^T\alpha_th_t({\bf x}) f(x)=T1∑t=1Tαtht(x)
Blending:用不相交的数据训练不同的 Base Model,将它们的输出取(加权)平均。实现简单,但对训练数据利用少了。
2.3 Stacking
Stacking 相比 Linear Blending来说,更加强大,然而也更容易过拟合。
Stacking 做法和 Linear Blending类似,首先从数据集中训练出初级学习器,然后”生成“一个新的数据集用于训练次级学习器。为了防止过拟合,采用K折交叉验证法求解。
一个直观的图如下:
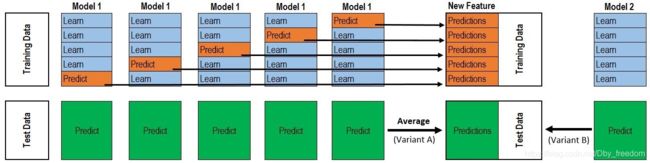
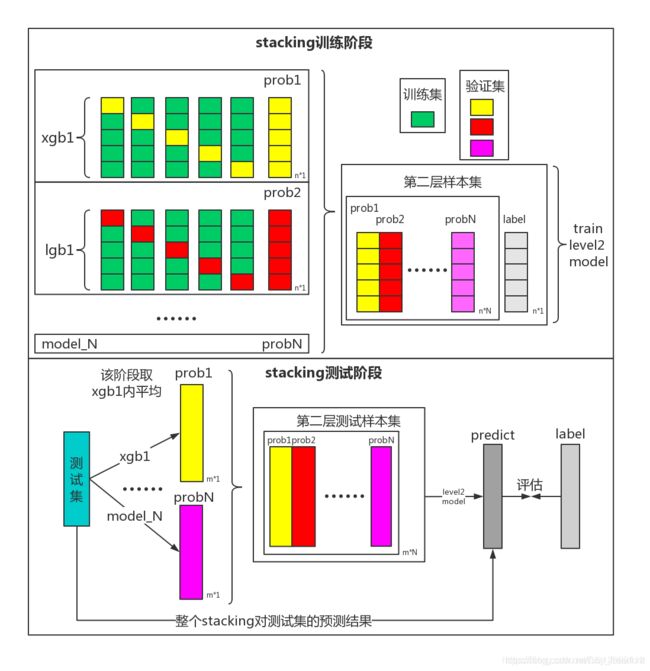
假设采用5折交叉验证,每个模型都要做满5次训练和预测,对于每一次:
- 从 80% 的数据训练得到一个模型 h t h_t ht,然后预测训练集剩下的那 20%,同时也要预测测试集。
- 每次有 20% 的训练数据被预测,5 次后正好每个训练样本都被预测过了。
- 每次都要预测测试集,因此最后测试集被预测 5 次,最终结果取 5 次的平均。
回归问题,代码如下(get_oof就是上图的过程):
_N_FOLDS = 5 # 采用5折交叉验证
kf = KFold(n_splits=_N_FOLDS, random_state=42) # sklearn的交叉验证模块,用于划分数据
def get_oof(clf, X_train, y_train, X_test):
# X_train: 1000 * 10
# y_train: 1 * 1000
# X_test : 500 * 10
oof_train = np.zeros((X_train.shape[0], 1)) # 1000 * 1 Stacking后训练数据的输出
oof_test_skf = np.empty((_N_FOLDS, X_test.shape[0], 1)) # 5 * 500 * 1,oof_test_skf[i]代表第i折交叉验证产生的模型对测试集预测结果
for i, (train_index, test_index) in enumerate(kf.split(X_train)): # 交叉验证划分此时的训练集和验证集
kf_X_train = X_train[train_index] # 800 * 10 训练集
kf_y_train = y_train[train_index] # 1 * 800 训练集对应的输出
kf_X_val = X_train[test_index] # 200 * 10 验证集
clf.fit(kf_X_train, kf_y_train) # 当前模型进行训练
oof_train[test_index] = clf.predict(kf_X_val).reshape(-1, 1) # 对当前验证集进行预测, 200 * 1
oof_test_skf[i, :] = clf.predict(X_test).reshape(-1, 1) # 对测试集预测 oof_test_skf[i, :] : 500 * 1
oof_test = oof_test_skf.mean(axis=0) # 对每一则交叉验证的结果取平均
return oof_train, oof_test # 返回当前分类器对训练集和测试集的预测结果
# 将数据换成你的数据
X_train = np.random.random((1000, 10)) # 1000 * 10
y_train = np.random.random_integers(0, 1, (1000,)) # 1000
X_test = np.random.random((500, 10)) # 500 * 10
# 将你的每个分类器都调用get_oof函数,并把它们的结果合并,就得到了新的训练和测试数据new_train,new_test
new_train, new_test = [], []
for clf in [LinearRegression(), RandomForestRegressor()]:
oof_train, oof_test = get_oof(clf, X_train, y_train, X_test)
new_train.append(oof_train)
new_test.append(oof_test)
new_train = np.concatenate(new_train, axis=1)
new_test = np.concatenate(new_test, axis=1)
# 用新的训练数据new_train作为新的模型的输入,stacking第二层
clf = RandomForestRegressor()
clf.fit(new_train, y_train)
clf.predict(new_test)
如果是分类问题,我们对测试集的结果就不能像回归问题一样直接取平均,而是分类器输出所有类别的概率,最后取平均。每个分类器都贡献了_N_CLASS(类别数)的维度。
修改get_oof函数如下即可:
_N_CLASS = 2
def get_oof(clf, X_train, y_train, X_test):
# X_train: 1000 * 10
# y_train: 1 * 1000
# X_test : 500 * 10
oof_train = np.zeros((X_train.shape[0], _N_CLASS)) # 1000 * _N_CLASS
oof_test = np.empty((X_test.shape[0], _N_CLASS)) # 500 * _N_CLASS
for i, (train_index, test_index) in enumerate(kf.split(X_train)):
kf_X_train = X_train[train_index] # 800 * 10 交叉验证划分此时的训练集和验证集
kf_y_train = y_train[train_index] # 1 * 800
kf_X_test = X_train[test_index] # 200 * 10 验证集
clf.fit(kf_X_train, kf_y_train) # 当前模型进行训练
oof_train[test_index] = clf.predict_proba(kf_X_test) # 当前验证集进行概率预测, 200 * _N_CLASS
oof_test += clf.predict_proba(X_test) # 对测试集概率预测 oof_test_skf[i, :] , 500 * _N_CLASS
oof_test /= _N_FOLDS # 对每一则交叉验证的结果取平均
return oof_train, oof_test # 返回当前分类器对训练集和测试集的预测结果
上面的代码只做了两层,你想的话还可以在加几层,因此这个方法叫做stacking,堆叠。。
3. Bagging
前面的模型融合中都是得到了尽可能好而不同 h t h_t ht,然后在进一步的进行处理,这些 h t h_t ht 往往是用不同的模型、同一模型的不同的超参数或者不同随机种子得到的。
要让分类器不同,还可以对训练样本进行采样,但如果采样出的每个子集都完全不同,则每个基学习器只用到了一小部分训练数据,甚至不足以进行有效学习,这就不能保证训练出的学习器好。我们可以考虑使用有重叠的采样子集。对此,Bagging 算法采用Bootstrap(也称为自助法)进行采样。
3.1 Booststrap (自助采样) 的优点
Bootstrap 为有放回的抽样,每次从 m 个样本的数据集 D 中抽取一个,重复 m 次,最终得到包含m个样本的采样集 D ′ D\prime D′。显然,数据集 D 中有一部分样本会在 D ′ D\prime D′ 中出现,而一部分不会。可以做一个简单的估计,样本在 m 次采样过程中始终不会被采样到的概率是 ( 1 – 1 m ) m (1 – \frac{1}{m})^m (1–m1)m,取极限得到:
lim m → ∞ ( 1 – 1 m ) m → 1 e ≈ 0.368 \lim_{m\rightarrow\infty} \ (1 – \frac{1}{m})^m \rightarrow \frac{1}{e} \approx 0.368 m→∞lim (1–m1)m→e1≈0.368
也就是说,每个基学习器用到了初始训练集中约63.2%的样本,剩下的36.8%的样本可以用来做 ”袋外估计“(out-of-bag estimate),即这些没有用到的样本可以来做验证集,这会在随机森林中讲解。
-
由于只用了原始训练集的63.2%样本进行训练,剩下的36.8%可以用作验证集来对泛化性能进行“包外估计”。
-
包外估计还可以辅助决策树进行剪枝,或者估计决策树中各节点的后验概率用于辅助对零训练样本节点的处理;还可以辅助神经网络早期停止减小过拟合风险。
-
从“偏差-方差”分解的角度看,Bagging主要关注降低方差,因此它在不剪枝的决策树、神经网络等易受样本扰动的学习器上效用更为明显。
从“偏差-方差”分解的角度看,即Bagging更适用于强分类器(如不剪枝的决策树、神经网络)集成,旨在降低方差;Boosting则更侧重于弱分类器集成,旨在降低偏差。(AdaBoost、GBDT可以算是两种不同实现类型的Boosting算法,而XGBoost可以理解为GBDT算法架构的一种扩展变体(目标函数loss function不同,加入了正则化以及贪婪法加入新的决策树等方式),具体可参考本博客中关于AdaBoost, GBDT与XGBoost区别章节,而随机森林则是Bagging的一个扩展变体)
3.2 Bagging 算法
Bagging是“并行式”集成学习方法中最著名的代表,基于我们之前介绍的自主采样法。
假设有个学习器,则我们可以描述Bagging的算法如下:
对 t = 1 , 2 , … , T t=1,2,\ldots, T t=1,2,…,T
\quad 通过 bootstrap 算法抽样得到一个大小为 m 的采样集 D ′ D\prime D′,在该采样集 D ′ D\prime D′上训练得到 h t h_t ht最后得到 T 个 h t h_t ht,用均匀混合法得到最后的模型。
- 给定包含 m 个样本的数据集,随机取出一个样本放入采样机,再将样本放回初始数据集,使得下次采样仍有可能被选中,经过 m 次随机采样,得到 m 个样本的数据集,初始数据集中约63.2%出现在采样集中。
- 我们采样出 T 个含 m 个 ( T ≥ m T \geq m T≥m) 训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器进行结合。
- 在对预测输出进行结合的时候,Bagging通常对分类任务采用简单投票法,回归任务采用简单平均法,若遇到相同票数则随机选择一个或者根据投票置信度来选择。
PS:Bagging是英文Bootstrap Aggregation的缩写。其示意图如下:
[外链图片转存失败(img-CN2CYNY9-1562418031186)(https://www.hrwhisper.me/wp-content/uploads/2018/07/bagging.png)]
训练一个Bagging集成与直接使用基学习算法训练一个学习器复杂度同阶,说明是一个高效的集成算法,与标准AdaBoost只适用于二分类任务不同,Bagging可以不经修改的用于多分类、回归等任务。
- 标准的AdaBoost只能处理二分类,现在已有变体能处理多分类或者回归任务。
- 从方差和偏差的角度看,Bagging主要降低的是方差,如果基算法对随机性比较敏感,那么bagging的结果会比较好。如不剪枝的决策树、神经网络。
3.4 随机森林(Random Forest, RF)
随机森林是Bagging的一个扩展变体。
RF在以决策树为基学习器,构建Bagging的基础上,进一步在决策树的训练过程中引入了随机属性选择。
具体来说,传统的决策树在选择划分属性的时候是在当前节点的属性集合中选择一个最优属性,而在RF中,对基决策树的每个节点,先从该节点的属性集中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个最优属性用于划分。
这里的参数k控制了随机性的引入程度,若令 k = d,则基决策树的构建与传统决策树相同;
若 k = 1,则随机选择一个属性进行划分;一般情况下推荐 k = l o g 2 d k=log_{2}d k=log2d
可以看出,随机森林对Bagging只做了微小的改动,但是与Bagging中基学习器的“多样性”仅通过样本扰动(通过对初始训练集采样)而来不同,随机森林中基学习器的多样性不仅来自于样本扰动,还来自于属性扰动,这就使得最终集成的泛化性能可以通过个体学习器之间的差异度的增加而进一步提升。
Bagging中基学习器的“多样性”仅通过样本扰动(通过对初始训练集采样),而RF中基学习器的多样性不仅来自于样本扰动,还来自于属性扰动。
随机森林的收敛性与bagging相似,随机森林其实性能很差,随着个体学习器增加,会收敛到更低泛化性能。
随机森林训练效率通常优于bagging,因为在个体决策树的构建过程中,bagging使用的是“确定型”决策树,需要考虑全部属性,但是随机森林使用的是“随机型”只需要考虑一个属性集合。
3.4.1 随机森林的建立
基本就是两个步骤:随机采样与完全分裂。
(1)随机采样
首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。
对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。假设输入样本为 N 个,那么采样的样本也为 N 个,这选择好了的 N 个样本用来训练一个决策树,作为决策树根节点处的样本,同时使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现 over-fitting。
对于列采样,从 M 个 feature 中,选择 m 个(m << M),即:当每个样本有 M 个属性时,在决策树的每个节点需要分裂时,随机从这 M 个属性中选取出 m 个属性,满足条件 m << M。
(2)完全分裂
对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。分裂的办法是:采用上面说的列采样的过程从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
决策树形成过程中每个节点都要按完全分裂的方式来分裂,一直到不能够再分裂为止(如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。
随机森林的过程为:
对 t = 1 , 2 , … , T t=1,2,\ldots, T t=1,2,…,T
- 通过对原始数据集 D 做 Bootstrap抽样,得到大小为m的数据集 D ~ t \tilde{D}_t D~t
- 在 D ~ t \tilde{D}_t D~t上运行基分类器学习算法 A ( D ~ t ) A(\tilde{D}_t) A(D~t),得到基分类器 h t h_t ht
返回 G = U n i f o r m ( { h t } ) G={\rm Uniform}(\{h_t\}) G=Uniform({ht}) (就是对所有 h t h_t ht 做均匀混合)
其中基分类器 h t h_t ht 的训练算法 A ( D ~ t ) A(\tilde{D}_t) A(D~t) 为:

可以看出:
- 随机森林一开始采用自助法Bootstrap抽取数据
- 对于每棵树,在待分裂的节点上,随机选择K个特征
- 每一棵树为 CART
上面的两种做法都是为了让基学习器尽可能好而不同。通常来说,K << d(原始特征个数),随机森林的效率能进一步提升。随机森林的提出者建议,每个 h t h_t ht 每次分裂时都对特征都重采样一遍,这样效果会更好。若 k=d,则与传统决策树相同,一般而言,推荐 k = log 2 d k = \log_2d k=log2d 或者 k = d k = \sqrt{d} k=d
随机森林的生成过程相比于一般决策树生成过程多了:Bagging步骤的bootstrap sampling(自助采样)与属性集(M个)随机选择m个(由参数m控制,建议 m = l o g 2 M m = log_2 M m=log2M)
一般决策树的生成过程可参考本博客决策树之ID3, C4.5与CART区别与联系
3.4.2 随机森林的优点
- 在数据集上表现良好
- 在当前的很多数据集上,相对其他算法有着很大的优势
- 它能够处理很高维度(feature很多)的数据,并且不用做特征选择
- 在训练完后,它能够给出哪些feature比较重要
- 在创建随机森林的时候,对generlization error使用的是无偏估计
- 训练速度快
- 在训练过程中,能够检测到feature间的互相影响
- 容易做成并行化方法
- 实现比较简单
- 能够处理带有缺失数据的样本
3.4.3 Random Froest 小结
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。
-
在建立每一棵决策树的过程中,有两点需要注意自助采样与完全分裂。
- 首先是两个随机采样的过程,random forest对输入的数据要进行行、列的采样。对于行采样,采用有放回的方式,也就是在采样得到的样本集合中,可能有重复的样本。
- 假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。
- 然后进行列采样,从M个feature中,选择m个(m << M)。
- 之后就是对采样之后的数据使用完全分裂的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。
- 一般很多的决策树算法都有一个重要的步骤 - 剪枝,但是这里不这样干,由于之前的两个随机采样的过程保证了随机性,所以就算不剪枝,也不会出现over-fitting。
-
按这种算法得到的随机森林中的每一棵都是很弱的,但是大家组合起来就很厉害了。
- 我觉得可以这样比喻随机森林算法:每一棵决策树就是一个精通于某一个窄领域的专家(因为我们从M个feature中选择m让每一棵决策树进行学习),这样在随机森林中就有了很多个精通不同领域的专家,对一个新的问题(新的输入数据),可以用不同的角度去看待它,最终由各个专家,投票得到结果。
4. 多样性
4.1 误差-分歧分解
欲构建泛化能力强的集成,个体学习器应“好而不同”,其中,“误差-分歧分解”(error-ambiguity decomposition)是一个简单的理论分析方法。但该推导过程只适用于回归学习,难以直接推广到分类学习任务中。
4.2 多样性度量
多样性度量(diversity measure)是用于度量集成中个体分类器的多样性,即估算个体学习器的多样化程度。常用的多样性度量包括:
不合度量(disagreement measure)
相关系数(correlation coefficient)
Q-统计量(Q-statistics)
k-统计量(k-statistics)
4.3 多样性增强
在集成学习中需有效地生成多样性大的个体学习器。与简单地直接用初始数据训练出个体学习器相比,一般思路是在学习过程中引入随机性,常见的做法主要有,
- 数据样本扰动:数据样本扰动基于采样法。
- 输入属性扰动:随机子空间算法。
- 输出表示扰动:翻转法(随机改变一些训练样本的标记);输出调制法(将分类输出转化为回归输出后构建学习器)…
- 算法参数扰动:负相关法;单一学习器通常需要交叉验证等来确定参数值。
- 常见的“不稳定基学习器”:决策树、神经网络,训练样本稍加变化就会导致学习器有显著变动,数据样本扰动法对这样的“不稳定基学习器”很有效;
- 常见的“稳定基学习器”:线性学习器、支持向量机、朴素贝叶斯、k近邻学习器,对此类基学习器进行集成往往需要使用输入属性扰动等其他几种。
5. Bagging 与 Boosting 区别
Bagging,Boosting二者之间的区别
(1)样本选择上:
- Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
- Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
(2)样例权重:
- Bagging:使用均匀取样,每个样例的权重相等
- Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
(3)预测函数:
- Bagging:所有预测函数的权重相等。
- Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
(4)并行计算:
- Bagging:各个预测函数可以并行生成
- Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
参考资料
- 我爱机器学习』集成学习(一)模型融合与Bagging
- 机器学习技法 – 林轩田
- 《机器学习》 – 周志华
- 模型融合:bagging、Boosting、Blending、Stacking
关于Stacking方面还可以查阅:
- Stacking Learning在分类问题中的使用
- Kaggle机器学习之模型融合(stacking)心得