【深度学习】Transformer长大了,它的兄弟姐妹们呢?(含Transformers超细节知识点)...
最近复旦放出了一篇各种Transformer的变体的综述(重心放在对Transformer结构(模块级别和架构级别)改良模型的介绍),打算在空闲时间把这篇文章梳理一下:
知乎:https://zhuanlan.zhihu.com/p/379057424
arxiv:https://arxiv.org/abs/2106.04554
Part1背景
1Transformer的优点
可并行
弱归纳偏置,通用性强
特征抽取能力强
自编码上下文双向建模
2Transformer的缺点
self-attention 计算复杂度高,序列长度上升,复杂度指数级上升
弱归纳偏置增加了小数据集上过拟合的风险
3原生Transformer(Vanilla Transformer)
sequence-to-sequence 模型(encoder and a decoder)
堆叠 ???? 个相同的 blocks
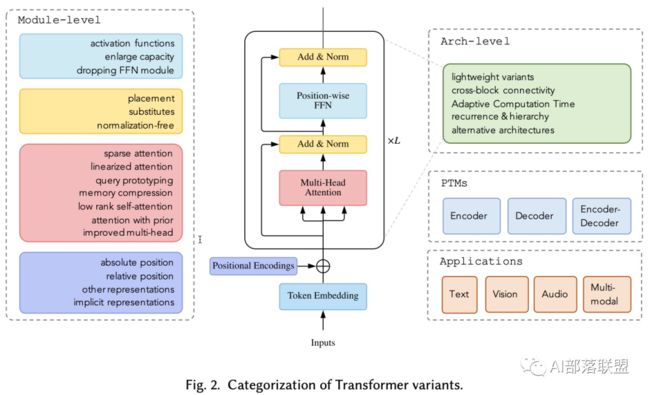
每个 encoder block 主要由多头自注意力模块(multi-head self-attention module)和位置相关全连接(position-wise feed-forward network (FFN))组成,构建的时候还有残差连接(residual connection)以及层归一化(Layer Normalization)。
与encoder相比,decoder在多头自注意模块和位置相关全连接之间额外插入了交叉注意模块。
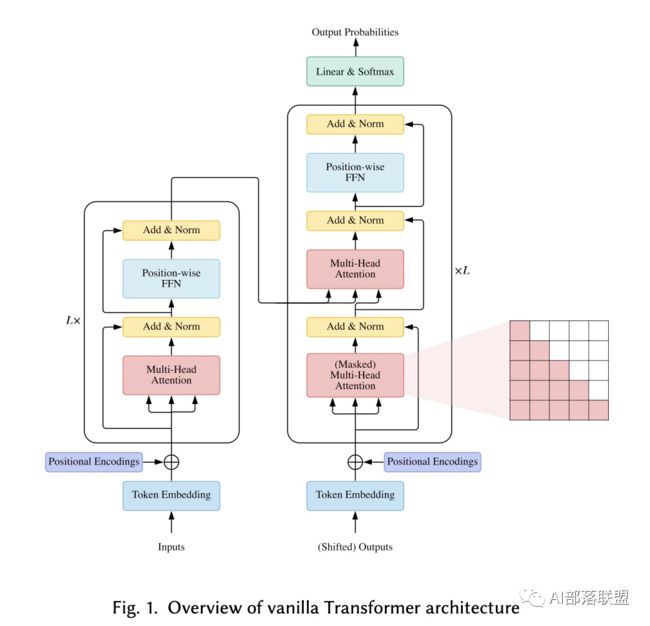
注意力模块(Attention Modules)
多头注意力层,核心点在于 Q/K/V 三个矩阵,其中 Q/K 矩阵生成权重矩阵(经由softmax),随后和V矩阵得到加权和。
这个过程重复了 n_heads 次,这个 n_heads 代表的就是头的数目,这里需要注意的是我们需要确保 hidden_size/n_heads 需要为一个整数,不然会报错。
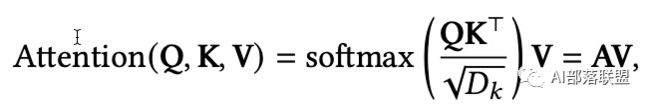

基于位置的全连接(Position-wise FFN)
注意:Transformer中的FFN全称是Position-wise Feed-Forward Networks,重点就是这个position-wise,区别于普通的全连接网络,这里FFN的输入是序列中每个位置上的元素,而不是整个序列,所以每个元素完全可以独立计算,最极端节省内存的做法是遍历序列,每次只取一个元素得到FFN的结果,但是这样做时间消耗太大,“分段”的含义就是做下折中,将序列分成 段,也就是 个子序列,每次读取一个子序列进行FFN计算,最后将 份的结果拼接。分段FFN只是一种计算上的技巧,计算结果和原始FFN完全一致,所以不会影响到模型效果,好处是不需要一次性将整个序列 读入内存,劣势当然是会增加额外的时间开销了。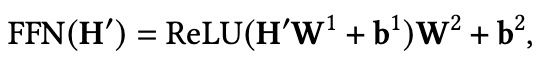
残差与归一化(Residual Connection and Normalization)
残差连接一般出现在比较深的模型中,可以使得信息前后向传播更加顺畅,缓解了梯度破碎问题。为什么这里使用 Layer Normalization,而不是BN,这里直白的回答就是,BN的效果差,所以不用。
位置编码(Position Encodings)
因为Transformer不引入RNN或CNN,所以它忽略了位置信息(尤其是对于encoder)。因此Transformer使用Position Encodings来建模token之间的顺序。
4使用方法(Usage)
Encoder-Decoder 因为具有encoder和decoder,所以可以用作Seq2Seq任务;
Encoder only 通常将Encoder作为文本的编码器,通常用于文本分类任务;
Decoder only 只使用decoder时,需要将encoder和decoder的交叉编码器删除,通常用作文本生成任务。
5模型分析(Model Analysis)
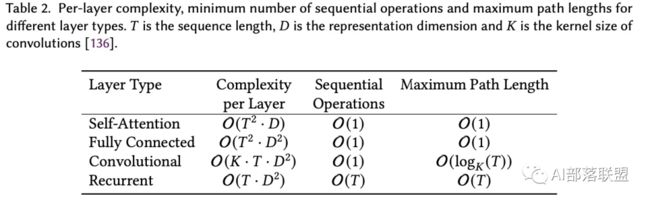
为了分析Tranformer的计算复杂度,本文分析了其主要的两个组件:self-attention和position-wise FFN。具体的对比如下表所示,本文假设隐藏层的维度为????,输入的序列长度为????。FFN的中间单元数量设置为4????,key和value的维度设置为????/???? 。
当输入数据的长度较短时, 隐藏层的维度????主导了self-attention和position-wise FFN的复杂度。此时Transformer的计算瓶颈在于FFN,但是随着序列长度的增加,序列长度????逐渐主导复杂度,此时Transformer的计算瓶颈在于self-attention。此外,自注意力的计算需要存储???? × ???? 的注意力分布矩阵,这使得Transformer的计算在长序列场景(例如,长文本文档和高分辨率图像的像素级建模)是不可行的。
6Transformer和其他网络的对比(Comparing Transformer to Other Network Types)
Self-Attention的分析(Analysis of Self-Attention)
本文将self-attention和其余几个神经网络模型进行了对比,总结出了以下几点Transformer的优点:
self-attention具有和FFN相同的最大路径长度,因此Transformer更适合长距离依赖的建模。但是相对于FNN,Transformer的参数的有效性更高且对于变长序列的处理更好。
由于卷积层的感受野有限,人们通常需要堆叠一个深的网络来拥有一个全局感受野。另一方面,恒定的最大路径长度允许self-attention建模恒定层数之间的长期依赖性。
恒定的顺序操作和最大路径长度使得self-attention比RNN更具并行性,在远程建模中表现更好。
注意:最大路径长度指的是从任何输入位置通过前向和后向信号的到达任意输出位置的最大长度。较短的句子长度意味着更好的学习长期依赖性的能力。
归纳偏置(In Terms of Inductive Bias)
归纳偏置其实可以理解为:从现实生活中观察到的现象中归纳出一定的规则(heuristics),然后对模型做一定的约束,从而可以起到“模型选择”的作用,即从假设空间中选择出更符合现实规则的模型。
在具体的深度学习模型中:CNN具有平移不变性和局部性的归纳偏置。类似地,RNN因为其马尔可夫结构具有时间不变性和局部性的归纳偏置。
而Transformer很少对数据的结构信息进行假设。这使得Transformer成为一个通用且灵活的体系结构。但是这样也有其对应的缺点。缺少结构归纳偏置使得Transformer容易对小规模数据过拟合。
另外一种和Transformer类似的模型则是Graph Neural Networks (GNNs),Transformer可以看作是一个定义在一个完全有向图(带环)上的GNN,其中每个输入都是GNN中的一个节点。Transformer和GNNs之间的关键区别在于Transformer没有引入关于输入数据结构的先验知识,Transformer中的消息传递过程完全依赖于文本的相似性度量。
Part2Transformer的分类(TAXONOMY OF TRANSFORMERS)
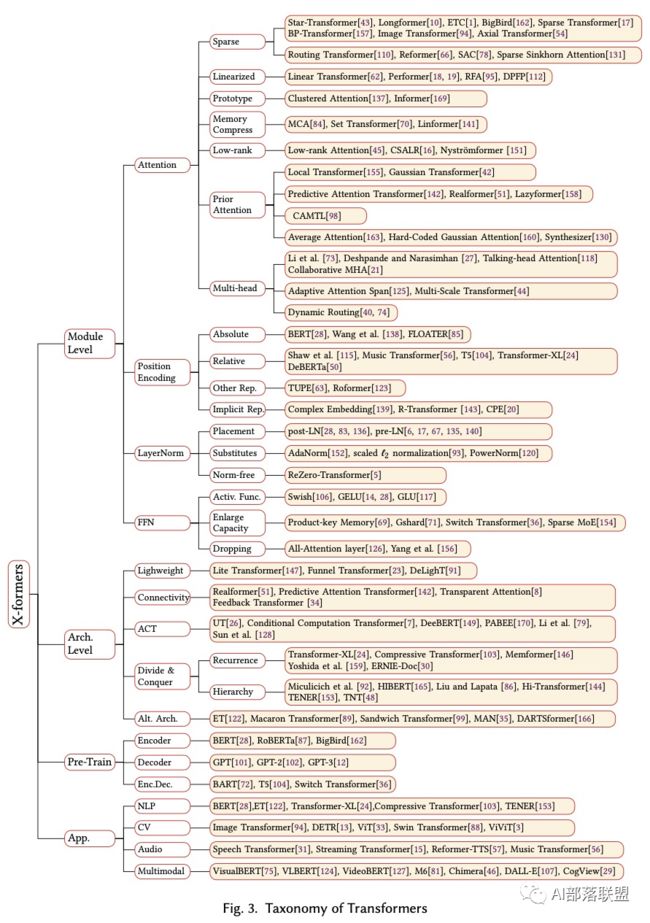
到目前为止,研究人员已经基于vanilla Transformer从三个角度提出了各种各样的模型:体系结构修改的类型;预训练方法;应用。
7注意力机制(Attention)
注意力模块是Transformer中的核心模块,实际应用时通常会遇到以下问题:
复杂度过高:上一节中提到了Transformer随着序列长度增加,复杂度指数上升的问题。序列长度变长的话,self-attention成为Transformer计算效率的瓶颈。
缺少结构先验:自注意力机制并没有引入任何的结构假设,甚至顺序信息都还要从训练数据中学习得到,因为未预训练过的Transformer可能会在小数据集上过拟合。
针对上述问题的改进主要可以分为以下几种:
稀疏注意力(Sparse Attention):采用稀疏注意力机制,将O(n)依赖降至线性,解决了BERT模型中的全注意力机制带来的序列长度二次依赖限制,同时兼顾更长的上下文。
线性化的注意力(Linearized Attention) :为了给计算复杂度降低到线性,使用核函数来简化Attention的计算过程,并且替换掉SoftMax。
Prototype and Memory Compression:这类方法减少了Q和KV内存对的数量,以减小注意力矩阵的大小。
Low-rank Self-Attention:这类工作抓住了自我注意力的low rank属性。
注意力先验(Attention with Prior):这一系列的研究旨在补充或取代具有先验的注意分布标准注意力机制。
改善多头自注意力机制:这一系列研究探索了不同可替代多头机制的结构。
8稀疏注意力(Sparse Attention)
在标准的Transformer中,每个token都需要和其他的所有token做运算,但是有研究人员观察到针对一个训练好的Transformer,其中的注意力矩阵通常非常稀疏。因此,通过结合结构偏差来限制每个Q关注的Q-K对的数量,可以降低计算复杂度。在该限制下,只需要根据预定义的模式计算Q-K对的相似度即可。
上述公式得到的结果是一个非归一化的矩阵,在具体的实现中,矩阵中的一般不会被存储。
从另一个角度来看,标准的注意力可以看作是一个完整的二部图,其中每个Q接收来自所有存储节点的信息并更新其表示。稀疏注意可以看作是一个稀疏图,其中删除了节点之间的一些连接。我们将确定稀疏连接的度量分为两类:基于位置的稀疏注意和基于内容的稀疏注意。
基于位置的稀疏注意力
在基于位置的稀疏注意力中,注意力矩阵根据一些预先定义的pattern进行限制。虽然这些稀疏模式有不同的形式,但本文发现其中一些可以分解为原子类型的稀疏pattern。本文首先确定一些原子类型的稀疏pattern,然后描述这些pattern是如何在一些现有的工作应用的。最后本文介绍了一些针对特定数据类型的扩展稀疏pattern。
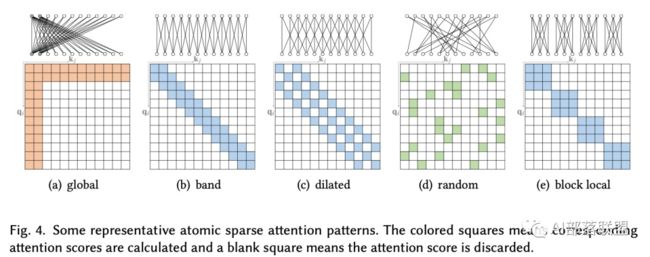
原子稀疏注意力(Atomic Sparse Attention)
主要有五种原子稀疏注意模式,如下图所示。
Global Attention. 为了缓解在稀疏注意中对长距离依赖性建模能力的退化,可以添加一些全局节点作为节点间信息传播的中心。这些全局节点可以attend到序列中的所有节点,并且整个序列也可以attend到这些全局节点,其中注意矩阵如图4(a)所示。
Band Attention. 又称之为滑动窗口注意力或局部注意力。由于大多数数据都具有很强的局部性,因此很自然地会限制每个Q去关注其邻居节点。这种稀疏模式被广泛采用的一类是Band Attention,其中注意矩阵如图4(b)所示。
Dilated Attention. 与扩张的CNN类似,通过使用具有间隙的扩张窗口,可以潜在地增加Band Attention的感受野,而不增加计算复杂度。其中注意矩阵如图4(c)所示。这可以很容易地扩展到跨越式的注意力机制,窗口大小不受限制,但???????? 需要设置为更大的值。
Random Attention. 为了增加非局部交互的能力,对每个Q随机抽取一些边,如图4(d)所示。这是基于随机图(Erdős–Rényi随机图)可以具有与完全图相似的谱性质,从而通过在随机图上的游走可以得到更加快速的mixing时间。
Block Local Attention. 这类注意力机制将输入序列分割成若干个互不重叠的查询块,每个查询块与一个本地存储块相关联。查询块中的所有Q只涉及相应内存块中的K。图4(e)展示了存储器块与其对应的查询块。
复合稀疏注意力(Compound Sparse Attention)
现有的稀疏注意力通常由以上原子模式中的一种以上组成。图5显示出了一些代表性的复合稀疏注意模式。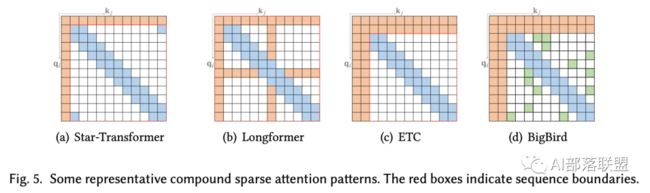
Star Transformer结合了Band Attention和Global Attention.。具体来看Star Transformer仅包括一个全局节点和一个宽度为3的Band Attention,其中任何一对非相邻节点通过一个共享的全局节点连接,相邻节点之间直接连接。这种稀疏模式可以在节点间形成星形图。
Longformer结合了Band Attention和internal global-node attention,选择做分类的[CLS]token以及问答任务中的所有的问题tokens作为全局节点。此外还用扩大的Dilated Attention代替上层的一些Band Attention头,以增加感受野而不增加计算量。
ETC(Extended Transformer Construction)作为和Longformer同时出现的工作,ETC结合了band attention和external global-node attention。ETC还使用了一种[MASK]机制,用于处理结构化输入和调整对比预测编码(CPC)以用于预训练。
除了band attention和external global-node attention之外,Big bird还使用额外的随机注意力来接近完全注意力。相应的理论分析表明,使用稀疏编码器和稀疏解码器可以模拟任何类型的图灵机,这同时解释了这些稀疏注意模型的有效性。
Sparse Transformer使用了一种因式分解的注意力机制,其中针对不同类型的数据设计了不同的稀疏模式。对于具有周期性结构的数据(例如图像),它使用了band attention和strided attention的组合。而对于没有周期结构的数据(如文本),则采用block local attention与global attention相结合的组合,全局节点来自输入序列中的固定位置。
扩展的稀疏注意力(Extended Sparse Attention)
除了上述模式之外,一些现有的研究还探索了特定数据类型的扩展稀疏模式。
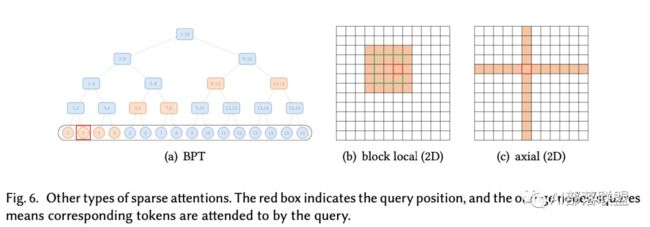
对于文本数据,BP Transformer构造了一个二叉树,其中所有标记都是叶节点,内部节点是包含许多标记的span节点。图中的边是这样构造的:每个叶节点都连接到它的邻居叶节点和更高级别的span节点,这些节点包含来自更长距离的token。这种方法可以看作是全局注意的一种扩展,其中全局节点是分层组织的,任何一对token都与二叉树中的路径相连接。图6(a)展示出了该方法的抽象视图。
对于视觉数据也有一些扩展。Image Transformer探索了两种类型的注意力模式:
按光栅扫描顺序展平图像像素,然后应用block local稀疏注意力;
2D block local注意力,其中查询块和存储块直接排列在2D板中,如图6(b)所示。作为视觉数据稀疏模式的另一个例子,Axial Transformer在图像的每个轴上应用独立的注意力模块。如图6(c)所示,每个注意模力块沿一个轴混合信息,同时保持沿另一个轴的信息独立。这可以理解为以光栅扫描水平和垂直展平的图像像素,然后分别使用图像宽度和高度的间隙来应用跨越式注意力。
基于内容的稀疏注意力
另一个方向的工作是基于输入内容创建稀疏图,即构造输入中的稀疏连接时是有条件的。
构造基于内容的稀疏图的简单方法是选择那些可能与给定Q具有较大相似性分数的K。为了有效地构造稀疏图,可以将其看做Maximum Inner Product Search (MIPS)问题,即在不计算所有点积项的情况下,通过一个查询Q来寻找与其具有最大点积的K。Routing Transformer使用了k-means聚类——对查询queries和keys在同一簇质心向量集合上进行聚类。每个查询Q只关注与其属于同一簇内的keys。在训练的时候,会使用分配的向量指数移动平均数除以簇的数量来更新每个簇的质心向量。
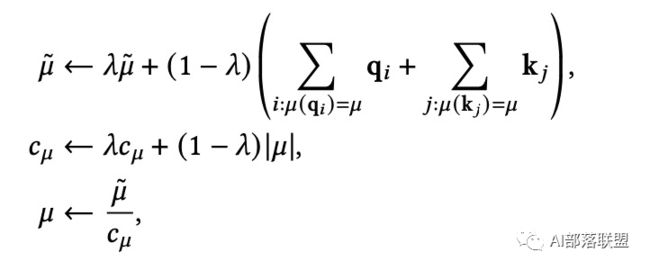
表示的是????这个簇中包含的向量的数量, 是一个可学习的超参数。
假设 表示第 个查询涉及的Key的索引集合,在Routing Transformer中的 表示为: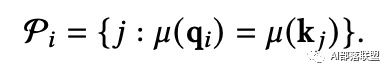
Reformer使用了局部敏感哈希(LSH)算法来为每一个query选择对应的K-V对,LSH注意允许每个token只关注同一散列桶中的token。其基本思想是使用LSH函数将Query和Key散列到多个bucket中,相似的项有很高的概率落在同一个bucket中。
具体来看,他们使用随机矩阵方法作为LSH的函数。假设 表示bucket的数量,给定随机矩阵 大小为 ,则LSH函数的计算公式为: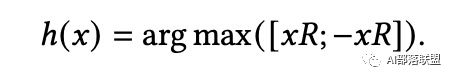
LSH允许Query只关注具有索引的K-V对: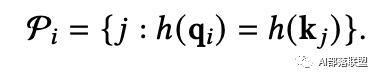
稀疏自适应连接(Sparse Adaptive Connection,SAC)将输入序列视为一个图,并学习构造注意力边,以使用自适应稀疏连接提高特定任务的性能。SAC使用LSTM边缘预测器来构造token之间的边。在没有遍的情况下,采用强化学习的方法训练边缘预测器。
Sparse Sinkhorn Attention(SSA)首先将查询Q和键K分成几个块,并为每个查询块分配一个键块。每个查询Q只允许关注分配给其相应键块中的键。键块的分配由排序网络控制,该网络是一个使用Sinkhorn归一化产生的双随机矩阵,该矩阵用作分配时的排列矩阵。SSA使用这种基于内容的block sparse attention以及上面中介绍的block local attention以增强模型的局部建模能力。
好了,本次的分享就是这些,剩余部分之后会继续解读。希望能对大家有帮助。
往期精彩回顾
适合初学者入门人工智能的路线及资料下载机器学习及深度学习笔记等资料打印机器学习在线手册深度学习笔记专辑《统计学习方法》的代码复现专辑
AI基础下载机器学习的数学基础专辑温州大学《机器学习课程》视频
本站qq群851320808,加入微信群请扫码: