如何理解线性判别分类器(LDA)?
线性判别分析(Linear discriminant analysis),简称为 LDA,是统计大拿罗纳德·艾尔默·费希尔爵士(英语:Sir Ronald Aylmer Fisher)在1936年提出的。

Sir Ronald Aylmer Fisher(1890--1962)
关于 LDA 网上介绍的很多,也写得很不错,本文尝试用一个新的视角来解读该算法,集思广益。
1 方差分析
费希尔设计了方差分析,可通过“组间方差大、组内方差小”来进行分类,比如可以分辨出下图中 组和
组和 、
、 组不是同一类(其中的细节可以参考文章“如何理解方差分析和F分布?”):
组不是同一类(其中的细节可以参考文章“如何理解方差分析和F分布?”):

这种思想运用到机器学习中就是本课要介绍的 LDA,下面来看看细节。
2 感知机
假设有六个二维的样本点![]() 。其中
。其中![]() 为正类,用
为正类,用![]() 表示;
表示;![]() 为负类,用
为负类,用![]() 表示:
表示:

通过感知机(这篇文章有介绍)进行分类的话,由于感知机算法具有一些不确定性(比如迭代次数不同、样本点输入的顺序不同),所以可能会得到像下面这样不同的决策边界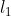 、
、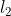 以及
以及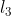 等:
等:

这些决策边界哪一条更好?不知道,除非可以获得更多的样本点。比如增加新的样本点![]() 、
、![]() ,那么就可以判断 可能是更好的决策边界:
,那么就可以判断 可能是更好的决策边界:

增加样本点是机器学习的万能方法,但如果没有办法增加样本点该怎么办呢?
3 先验假设
没有办法增加样本点时,可尝试提出一些先验假设,也就是提出一些对样本点的知识,举个具体的例子来进行说明吧。
比如有两类人,其中一类容易感染新冠病毒,另一类不容易感染。在这里就可以提出先验假设,假设这两类人分别服从各自的一维正态分布(正态分布比较常见,这么假设也算合理):

前者产生了 3 个正类![]() 样本点,后者产生 3 个负类
样本点,后者产生 3 个负类![]() 样本点:
样本点:

这两类人实际上是要通过“体重”和“年龄”这两种特征来描述,也就是说这 6 个样本点所在坐标向量是“体重”和“年龄”的线性组合,或者说该坐标向量是“体重”和“年龄”组成的二维平面中的向量:

由于测量误差、记录错误甚至某人今天吃得有点撑等原因,所以我们采集到的样本点会在该坐标向量附近,最终得到了文章开头提到的 6 个样本点:

上面的坐标向量、正态分布都是假设,所以在图中应该用虚线来表示。真正已知的只有 6 个样本点:

如果可以根据手上的 6 个样本点,复原出未知的坐标向量和正态分布,那么就可以判断哪一条决策边界是更好的。下面让我们一步步来,看看是怎么做的。
4 投影
首先是找坐标向量,其实也就是将这 6 个样本点放置到一条直线上去。这一步很容易做,通过投影就可以完成:

很显然,可以投影的直线有无数条:

哪一条是更好的呢?其实不同的投影对应了不同的正态分布:

所以找哪一条直线更好的问题就转为了哪一种正态分布更好。
5 理想的两个正态分布
先来思考下,我们理想的两个正态分布应该是什么样子的。下面的三种情况中,肯定情况 2 是最理想的,因为此时的两种正态分布没什么重叠,容易区分开来:

情况 1

情况 2

情况 3
假设正类服从的正态分布为![]() ,负类服从的正态分布为
,负类服从的正态分布为![]() ,下面就刚才的三种情况进一步分析下:
,下面就刚才的三种情况进一步分析下:
(1)情况 1,两个正态分布离得还是比较远的,但都太胖了,所以重叠较多。或者说虽然 和
和![]() 相差比较远,但
相差比较远,但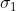 和
和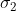 较大:
较大:

(2)情况 2,两个正态分布离得较远,同时都比较瘦,所以分离度比较好。或者说 和![]() 相差较远,同时 和 都较小:
相差较远,同时 和 都较小:

(3)情况 3,两个正态分布离得比较近,所以两者都较瘦,但依然重叠较多。或者说 和![]() 相差很小,虽然 和 都较小,但依然重叠较多。这里就不画图赘述了。
相差很小,虽然 和 都较小,但依然重叠较多。这里就不画图赘述了。
如果定义如下的代数式,将上述三种情况的 和
和 分别代入,那么容易知道,情况 2 得到的值是最大:
分别代入,那么容易知道,情况 2 得到的值是最大:
![]()
所以可以利用上述代数式来找出理想的两个正态分布。其中![]() 称为组间方差,
称为组间方差,![]() 称为组内方差,因此该式运用的原则就是费希尔在方差分析中提到的“组间方差大、组内方差小”。
称为组内方差,因此该式运用的原则就是费希尔在方差分析中提到的“组间方差大、组内方差小”。
6 问题的解决
根据上面的分析,可以知道在之前的问题中,左边的正态分布是更好的,也就是左边的直线更好:

但是在具体的计算时,因为不知道 和 ,所以计算过程需要一些调整。首先将这些样本点投影到某直线上后得到![]() :
:

然后算出投影点的样本均值:

准确的说,上面算出![]() 、
、![]() 的不是实数值,而是二维的点,是投影点的平均点:
的不是实数值,而是二维的点,是投影点的平均点:

然后计算投影点的样本方差:

然后用样本均值![]() 和样本方差
和样本方差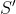 来替代 和 ,得到代数式:
来替代 和 ,得到代数式:
![]()
最后将样本点投影到所有可能的直线上,计算上述代数式,使得该代数式最大的直线,或者说正态分布就是我们要求的:

7 决策边界
找到想要的直线后,就可以给出决策边界了。该决策边界就是此时![]() 和
和![]() 的中垂线:
的中垂线:

最后总结下整个求解过程:

这里其实还有很多代数细节,以后会在别的文章中深入探讨。
8 小结
感知机是机器学习中最基本的算法,纯粹靠样本点来进行分类。如果增加关于样本点的知识,比如像本文一样就可以得到 LDA 算法。当然,如果增加不一样的知识,就会得到诸如逻辑回归、支持向量机等算法,这里就不再赘述了。