论文阅读 || 目标检测系列—— Mask R-CNN详解
论文链接:https://arxiv.org/abs/1703.06870
mask RCNN是He Kaiming2017的力作,其在进行目标检测的同时进行实例分割,取得了出色的效果,取得了COCO 2016比赛的冠军
图像分割的方式:语义分割、实例分割、全景分割。如下图所示

Mask RCNN沿用了Faster RCNN的思想。Mask RCNN = (ResNet-FPN) + (Fast RCNN) + (Mask)
其中的ResNet-FPN,可以换成其他的基础网络,论文中也做了相应的实验进行效果对比。
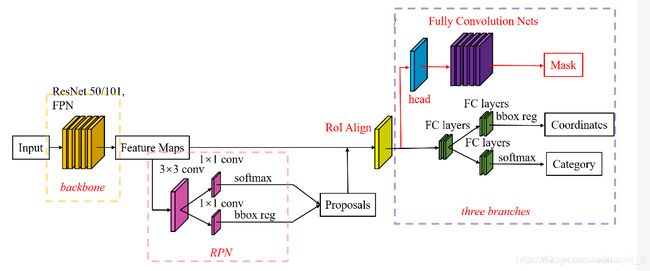
一、Faster RCNN
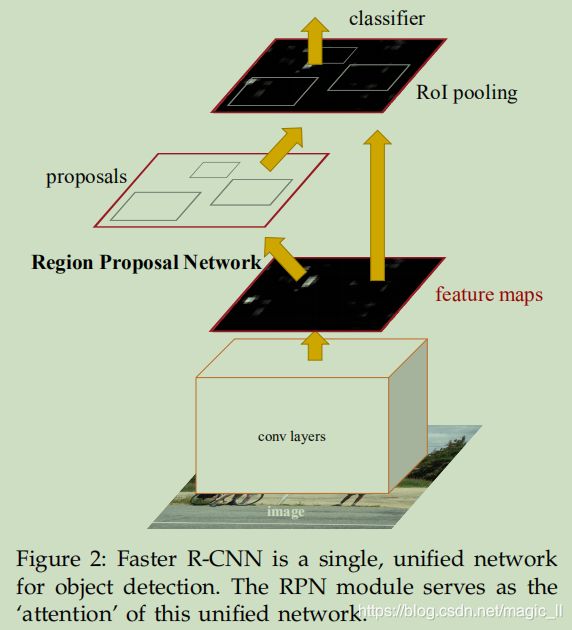
faster rcnn是两个阶段的目标检测算法:阶段一的Region Proposal、阶段二的bounding box 的回归和分类。
Fast RCNN使用CNN提取图像特征,然后使用region proposal network(RPN) 去提取出 region of interest(ROI),然后使用ROI pooling 将这些ROI全部变换成固定尺寸,再喂给全连接层进行Bounding Box回归和分类检测。(这里只做前向传播的简述)
二、ResNet-FPN
多尺度检测在目标检测中变得越来越重要,尤其是小目标的检测。Feature Pyramid Network(FPN)则是精心设计的多尺度检测办法。
FPN结构中包括自下而上、自上而下、横向连接三个部分,如下图所示。这种结构可以将各个层级的特征进行融合,将强语义信息和强空间信息的特征结合起来

FPN实际上是一种通用架构,可以结合各种架构网络使用(VGG、ResNet等)。Mask RCNN文章中使用了ResNet-FPN网络结构,如下图:
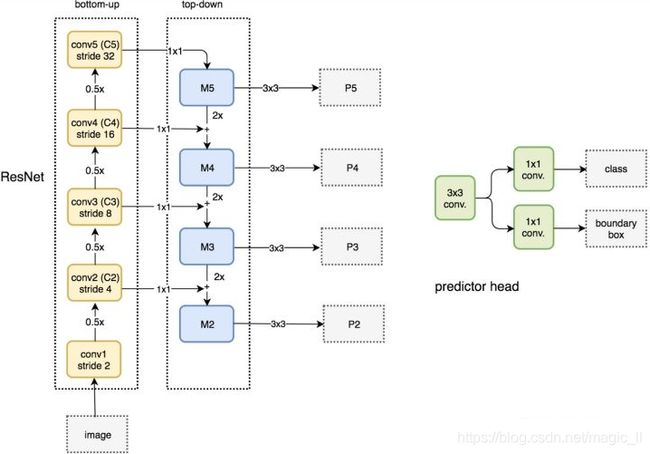
自下而上:传统的特征提取过程。将ResNet作为骨架网络,根据feature map的大小分为5个stage。stage2, stage3, stage4 stage5各自最后一层输出的特征图定义为C2,C3,C4,C5,他们相对于原始图片的stride为{4,8,16,32}。其中stage1没有使用是考虑到内存的原因
自上而下和横向连接
自上而下是从最高层开始进行上采样,这里上采样直接使用的是最邻近上采样,而不是反卷积操作,简单且减少了训练参数。
横向连接则是将上采样的结果和自下而上生成的相同大小的feature map进行融合。
具体操作:C2、C3、C4、C5中每一层经过一个conv1x1操作(1x1卷积用于降低通道数),无激活操作,输出通道全部设置为256,然后和上采样的feature map进行相加和操作。在融合之后在经过3x3的卷积核,对以融合特征进行处理,目的是消除上采样的混叠效应(aliasing effect)。
实际上,上图少绘制一个分支:M5经过步长为2的max pooling下采样得到P6,作者指出使用P6是想要得到更大的anchor尺度512x512。但P6是只用在RPN中来得到region proposal的,并不作为后续的Fast RCNN的输入。
总的来说,ResNet-FPN 作为RPN输入的feature map是[P2,P3,P4,P5,P6],而作为后续Fast RCNN的输入则是[P2,P3,P4,P5]
三、ResNet-FPN + Fast RCNN
ResNet-FPN之后产生了特征金字塔[P2,P3,P4,P5,P6],而并非只是一个feature map。特征金字塔[P2,P3,P4,P5]这些特征图经过RPN之后会产生很多的region proposal。那么问题来了,我们应该选择哪个feature map来切出这些ROI区域呢?
实际上,会选择最合适的尺度的feature map来切ROI。具体来说,通过一个公式来决定宽w和高h的ROI从哪个Pk来切:
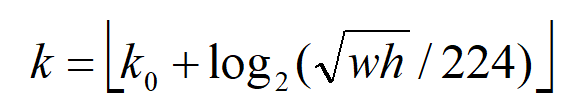
这里224表示预训练的ImageNet图片的大小,k0表示面积为w*h=224*224的ROI所应该在的层级。作者将k0设置为4,也就是说w*h=224*224的ROI应该从P4中切出来。假设ROI的scale小于224(例112*112),k=k0-1=4-1=3,这就意味着要从更高分辨率的P3中产生。也就是被切的feature map大小希望在28左右。另外,k值会做取整处理,防止结果不是整数。
这样做也合理。大尺度的ROI要从低分辨率的feature map上切,有利于检测大目标,小尺度的ROI要从高分辨率的feature map上切,有利于检测小目标。
四、ROI Align
mask rcnn中另外的重要改进:ROI Align。
Faster RCNN存在的问题:特征图像是不对准的,所以会影响检测精度。在Mask RCNN中提出的ROIAlign 的方法代替了ROIPooling,前者可以保留大致的空间位置。我们先介绍下两个知识:双线性插值、ROIpooling
1、双线性插值
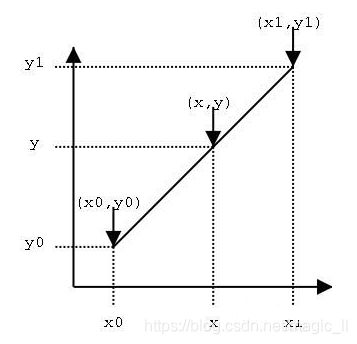
线性插值:已知数据(x0,y0)与(x1,y1),要计算[x0,x1]区间内某一位置x在直线上y值,就是按照x距离x0、x1的距离比例作为权重,计算出y值
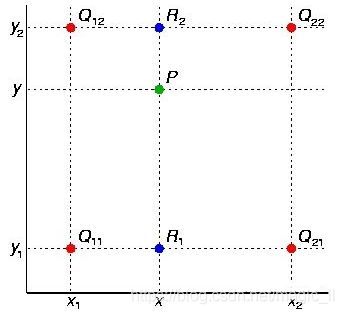
双线性插值:在两个方向上,以距离的比例作为权重,计算插值。如下图,根据Q12、Q22线性插值出R2,根据Q11、Q21线性插值出R1,然后根据R1、R2线性插值出P。
2. ROIPooling
以例子说明。假设有一个8x8大小的feature map,要在这个feature map上得到ROI,ROI的bbox为[x1,x2,y1,y2]=[0,3,7,8],并且进行ROIpooling到2x2大小的输出。
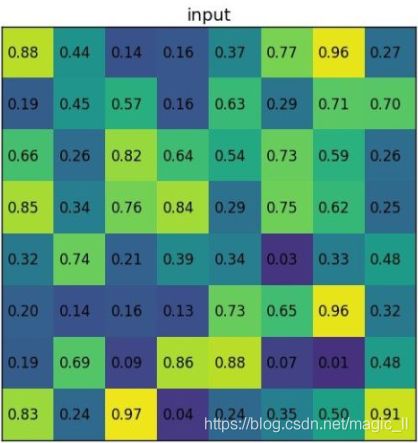
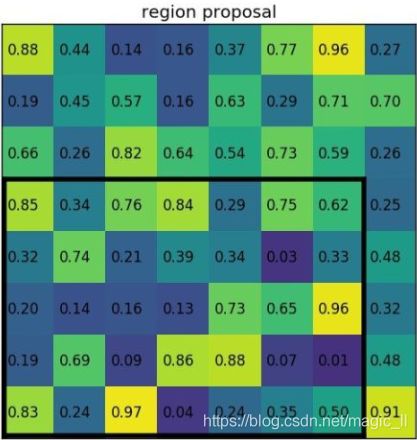

然后得到结果为
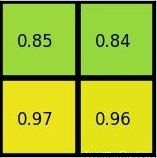
3. ROI ALign
在Faster RCNN中,有两次整数化的过程:
1. region proposal的xywh通常是小数,但是为了方便操作把它整数化。
2. 将整数化后的边界区域平均分成k*k个单元,对每一个单元的边界进行整数化
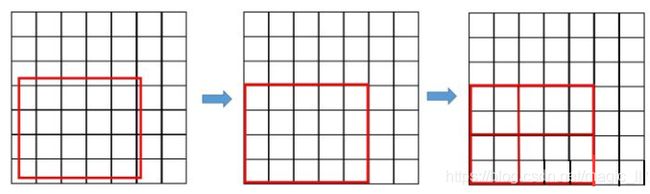
经过两次整数化,此时候选框已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测或者分割的准确度,在论文中,作者把它总结为“不匹配问题”(misalignment)
为了解决这个问题,ROI Align方法取消了整数化操作,保留了小数,使用双线性插值的方法获得坐标为浮点数的像素点上的图像数值。
例子:如下图,虚线部分表示feature map,实线表示ROI,这里将ROI切分为2x2的单元格。假定选取采样点数是4,我们首先将每个单元格子分成4个小方格(如红色线所示),每个小方格中心就是采样点,这些采样点的坐标通常是浮点数,所以对采样点像素进行双线性插值(如四个箭头所示),就可以得到该像素点的值了,然后对每个单元格内的4个采样点进行maxpooling,就可以得到最终的ROIAlign的结果
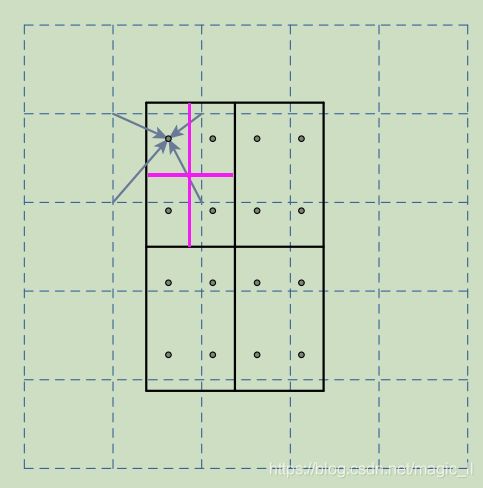
在相关实验中,作者发现将采样点设置为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,ROIAlign在遍历取样点的数量上没有ROIpooling那么多,但却可以获得更好的性能,这要归功于解决了misalignment的问题。
五、mask 及 损失
在RPN之后添加mask任务,得到最终的Mask RCNN。这样做将整个任务简化成milti-stage pipeline,解耦了多个任务的关系
定义多任务损失:其中,Lcls 和 Lbox与 faster rcnn的定义没有区别。需要具体说明的是Lmask。

假设一共有K个类别,mask分支针对每个RoI产生一个K*m*m的输出,即k个分辨率为m*m的二值掩码。依据任务预测类别分支预测的输出,仅将第i个类别的输出登记,用于计算。
- mask rcnn预测k个种类的m*m的二值掩码输出
- 依据种类预测分支,进行预测结果:当前ROI的物体的种类为第 i类
- 第 i个二值掩码的输出用于该ROI的损失

我们已知的FCN等实现语义分割,任务模块直接对每个像素进行分类,预测出属于k类中的哪一类,使用的是softmax。最终的到的是图像中目标的分割和分类。
我们可以把这个操作分为两步完成:任务模块1:预测图像中的目标属于哪一类。任务模块2:使用相应类别的提取掩码任务分支,进行图像分割,这样该任务模块中就会有k个掩码提取分支。一个掩码编码了一类输入对象的空间布局。对于预测的二值掩码,我们对每个像素点应用sigmoid函数,整体损失定义为平均二值交叉熵。
引入预测K个输出的机制,允许每个类都生成独立的掩码,避免类间竞争。这样做解耦了掩码和种类的预测。不同FCN的做法,在每个像素点上应用softmax函数,整体采用的多任务交叉熵,这样会导致类间竞争,最终导致分割效果差。
到这里再将Mask R-CNN和FCIS做个比较,首先两者的相同点是均继承了Faster R-CNN的RPN部分。不同点是对于FCIS,预测mask和分类是共享的参数。而Mask R-CNN则是各玩各的,两个任务各自有各自的可训练参数。对于这一点,Mask R-CNN论文里还专门作了比较,显示对于预测mask和分类如果使用共享的特征图对于某些重叠目标可能会出现问题。
六、网络架构的选择
为了证明ROI Align方法的普适性,我们构造了多种不同结构的Mask RCNN。具体:用于整个图像上的特征提取的下层卷积网络、用于检测框识别(分类和回归)和掩码预测的上层网络。
两种下层卷积网络:ResNet和ResNet-FPN。论文评估了深度为50和101层的ResNet和ResNeXt网络,使用ResNet的FasterRCNN从第四阶段的最终卷积层提取特征,称之为C4。例:使用ResNet-50的下层网络由ResNet-50-C4表示。论文还讨论了特征金字塔网络,也就是FPN。
两种下层卷积网络由各自对应的上层网络:
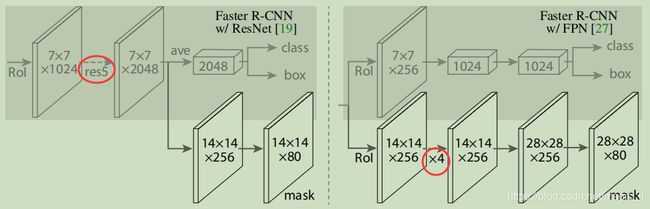
上图中,数字表示分辨率和通道数,箭头代表卷积、反卷积、全连接层。所有的卷积都是3*3的(除了输出层为1*1)。反卷积是2*2的,步进为2。
左边的ResNet-C4中,简单起见第一个箭头的操作,使用7*7,stride=1的“res5代替了14*14,stride=2的RoI。ResN的第五阶段。
右图的ResNet-FPN中,“x4”表示堆叠的4个连续的卷积
掩码分支是一个非常简单的结构。也许更复杂的设计有可能提高新能,但这不是这项工作的重点。
七、训练参数
训练阶段,
- Faster RCNN中,如果ROI与ground box的IoU>0.5,则ROI为positive;否则,ROI为negative。mask loss Lmask仅在positive ROIs 上定义,mask target是ROI与其对应的groundtruth mask的交集。
- 采用image-center训练,将图片的长宽较小的一边缩放到800个像素。
- 每个GPU的mini-batch=2,每张图片有N个采样ROIs(ResNet-C4的下层网络为64,FPN为512),positive 和 negative的比例为1:3
- 在8个GPU上训练,batchsize=2,160k迭代,learning_rate=0.02,每120k迭代减少10倍,weihgt_decay=0.0001,momentum=0.9
测试:
在测试时,C4下层网络中候选数量为300,FPN为1000,我们在这些候选上执行检测框预测分支,然后执行非极大值抑制。然后将掩码分支应用于评分最高100个检测框。尽管这些训练中使用的并行计算不同,但它可以加速推理并提高精度(使用更少,更准确的ROI)。掩码分支可以预测每个ROI的K个掩码,但是我们只使用第k个掩码,其中k是分类分支预测的类别。然后将m*m浮点数掩码输出的大小调整为ROI大小,并使用阈值0.5将其二值化
面试考点:
- RPN的作用和原理
- ROI align 和 ROI pooling的不同
八、实验
论文将Mask RCNN与已有技术进行比较,优于当时的最先进的模型。并进行了综合的消融实验。
消融实验:
有一点像控制变量的感觉。因为作者提出了一种方案,同时改变了多个条件/参数,他在接下去的消融实验中,会一一控制一个条件/参数不变,来看看结果,到底是哪个条件/参数对结果的影响更大

- 结构:表a显示了具有各种使用不同下层网络的MaskRCNN。它受益于更深层次的网络(50vs101)和高级设计,包括FPN和ResNeXt(我们使用64×4d64×4d的普通的ResNeXt)。但并不是所有的框架都会从更深层次的或高级的网络中自动获益
- 独立和非独立掩码:MaskRCNN解耦了掩码和类预测:由于现有的检测框分支预测类标签,所以我们为每个类生成一个掩码,而不会在类间产生竞争(通过像素级Sigmoid和二值化损失)。在表b中,将其与使用像素级Softmax和非独立损失的方法比较(常见于FCN)。这些方法将掩码和类预测的任务结合,导致了掩码AP(5.5个点)的严重损失。这表明,一旦目标被归类(通过检测框分支),就可以预测二值化掩码而不用担心类别,这样可以使模型更加容易训练。
- 类相关和类无关掩码:我们默认预测类相关的掩码,即每类一个m*m的掩码。但发现,这种方法与类别无关掩码的MaskRCNN(即预测单个m*m输出而不论是哪一类)几乎同效:对于ResNet-50-C4掩码AP为29.7,而对于类相关的对应的模型AP为30.3。 这进一步突出了该方法中的改进:解耦了分类和分割
- ROIAlign:表c显示了对我们提出的ROIAlign层的评估。对于这个实验,我们使用了下层网络为ResNet-500-C4,其步进为16。ROIAlign相对ROIPooling将AP提高了约3个点,在高IoU(AP75)结果中增益更过,ROIAlign对最大/平均池化不敏感,我们在文其余部分使用平均池化。
- 论文中,与采用双线性采样的MNC中提出的ROIWarp进行比较。其中,ROIWrap仍然四舍五入了ROI,与输入失去了对齐。从表格c中可以看出,ROIWarp和ROIPool的效果相近,都比ROIAlign相差多,这突出表明正确的对齐是关键。
- 另外,论文还是用了ResNet-50-C5下层网络评估了ROIAling,其进步更大,达到了32像素。我们使用的上层结构图是前文图片右边的结构,因为res5不使用。表d显示,ROIAlign将掩码AP提高了7.3个点,并将掩码的AP75提高了10.5个点。另外,使用步幅为32的C5特征(30.9 AP)比使用步幅为16的C4特征(30.3 AP)更加精准。ROIAlign在很大程度上解决了使用大步进特征检测和分割的长期挑战
- 最后,与结合ResNet-FPN一起使用,ROIAlign显示出了1.5个掩码AP和0.5个检测框AP的增益,FPN具有更加精细的多级步长。
- 掩码分支:分割是一个像素到像素的任务,我们使用FCN来利用掩码的空间布局。表e中,使用ResNet-50-FPN下层网络,结合上层网络,MLP(多层感知机)vs FCN。公平起见,FCN的上层网络的卷积没有被预训练(具体哪里??),使用FCN可以提供超过MLP2.1个点的AP增益。
目标检测结果
论文在COCO数据集上将MaskRCNN与其他最先进的目标检测方法对比(目标检测结果,即目标边界框AP)。使用ResNet-101-FPN的MaskRCNN优于当时最先进的模型。MaskRCNN超过的增益来自于使用ROIAlign(+1.0 APbb),多任务训练(+0.9 APbb)和 ResNeXt-101(+1.6 APbb)
速度
测试:我们训练一个ResNet-101-FPN模型,在RPN和Mask R-CNN阶段之间共享特征,遵循Faster R-CNN的四阶段训练2。该模型在Nvidia Tesla M40 GPU上处理每个图像需要195ms(加上15毫秒的CPU时间,用于将输出的大小调整到原始分辨率),并且达到了与非共享特征模型相同的掩码AP。我们还指出,ResNet-101-C4变体需要大约400ms,因为它的上层模型比较复杂(图3),所以我们不建议在实践中使用C4变体。
虽然Mask R-CNN很快,但我们注意到,我们的设计并没有针对速度进行优化,13可以实现更好的速度/精度平衡,例如,通过改变图像尺寸和候选数量,这超出了本文的范围。
训练:Mask R-CNN的训练也很快。在COCO trainval35k上使用ResNet-50-FPN进行训练,我们的同步8 GPU实现(每个批次耗时0.72秒,包含16个图像)需要32小时,而ResNet-101-FPN需要44小时。事实上,快速原型可以在不到一天的时间内在训练集上进行训练。我们希望这样快速的训练将会消除这一领域的重大障碍,并鼓励更多的人对这个具有挑战性的课题进行研究。
Mask R-CNN人体姿态估计 略
Cityscapes上的实验 略
有任何问题欢迎指正讨论。
参考链接:
https://alvinzhu.xyz/2017/10/07/mask-r-cnn/#fn:34