数据挖掘学习之路
前言
记录一下学习数据挖掘的历程
一、数据挖掘
从数据集合中提取人们感兴趣的知识,这些知识是隐含的、事先未知的、潜在的有用信息。提取出来的知识一般为概念、规则、规律、模式等形式。在大数据的背景之下,数据分析不需要具备概率分布的先验知识,限制条件更少,更为灵活高效。大数据已被应用于各个领域,包括宏观经济、金融、电力系统、医疗服务、电子商务以及社交网络等。
二、大数据分析与挖掘主要技术
主要分为如下几个步骤: 任务目标的确定
目标数据集的提取
数据预处理(数据清洗、数据转换、数据集成、数据约减等操作)
建立适当的数据分析与挖掘模型(如统计分析、分类和回归、聚类分析、关联规则挖掘、异常检测等)
模型的解释与评估
知识的应用
对数据的统计分析与特征描述(统计分析包括对数据分布、集中与发散程度的描述、主成分分析,数据之间的相关性分析等。特征描述的结果可以用多种方式进行展示,例如:散点图、饼状图、直方图、函数曲线、透视图等。)
关联规则挖掘和相关性分析:
分类和回归(分类例如:决策树、贝叶斯分类器、KNN分类器、组合分类算法等。回归是对数值型的函数进行建模,常用于数值预测。)
聚类分析(对未知类别标号的数据进行直接处理。聚类的目标是使聚类内数据的相似性最大,聚类间数据的相似性最小。)
异常检测或者离群点分析
三、数据特征分析:
数据集类型:
结构化数据(通常以文本文件储存,例如:鸢尾花分类的训练集)
半结构化数据(主要有XML文档和JSON数据)
非结构化数据(没有预定义的数据模型,例如:邮件、客户评价反馈、财务报表、计算机系统的各种日志等、音频、图像(医学影响、卫星遥感图像等)、视频(监控录像、电视节目等)。
数据属性的类型:
标称属性(类似于标签,其中的数字或者符号只是用来对物体进行识别和分类)
序数属性(不仅包含标称属性的全部特征,还反映对象之间的等级和顺序)
数值属性(包含区间标度属性和比率标度属性)。
数据的描述性特征:
集中趋势的描述:均值(算术平均数、加权平均数、几何平均数)、中位数、众数
极差、四分位数、方差、标准差
偏态系数、峰态系数
数据分布形态的度量:
数据的偏态分布及度量(偏态系数、样本偏态系数)
数据峰度及度量(衡量数据分布的平坦度)
数据偏度和峰度(用于估计数据分布与正态分布的差异)
数据分布特征的可视化:
箱型图(五数概括法)
正态分布
数据相关性分析:
散点图(直观判断相关性)
相关系数(协方差,反应两个属性在变化过程中是同方向变化,还是反方向变化)
四、数据预处理
数据清理
脏数据形成的原因:
不正确的数据:设备故障,人为输入错误,默认值提交,数据传输过程中产生的错误等。
不一致性:滥用缩写词,不同的惯用语,拼写变化,过时的编码,不同的计量单位等。
不完整数据:丢失值,信息收集不全,各种故障等。
重复记录:同一数据存储多次。
含有各种噪声:由误差造成的,也有可能是人为错误造成的。
数据清理处理的内容
- 缺失值填充
- 平滑噪声
- 识别和去除离群点
- 解决不一致性
缺失值识别
-
可利用pandas提供的方法:
print("含有空值的列数:",data.isnull().any(axis=0).sum()) print(data.isnull().any()) #.isnull().any() 用来判断列是否有缺失值
从糖尿病病人体检数据集入手
“糖尿病病人体检数据集”集包含了42个维度,用pandas、numpy、sklearn进行处理 维度例如:id,性别,年龄,体检日期,*天门冬氨酸氨基转换酶,*丙氨酸氨基转换酶,*碱性磷酸酶,*r-谷氨酰基转换酶,*总蛋白,白蛋白,*球蛋白,白球比例,甘油三酯,总胆固醇,高密度脂蛋白胆固醇....import pandas as pd
train_data = pd.read_csv('d_train_20180102.csv',encoding='gbk')
print(train_data.columns)
print(train_data.head)
print(train_data.isnull().sum())
处理缺失值的方法:
(1)删除法
import pandas as pd
diabetes_data = pd.read_csv('d_train_20180102.csv',encoding='gb2312')
diabetes_data.head()
#设定阀值
thresh_count = diabetes_data.shape[0]*0.7
#若某一列数据缺失的数量超过70%就会被删除
diabetes_data = diabetes_data.dropna(thresh=thresh_count, axis=1)
(2)估计法
人工填写空缺值(费时,当数据集很大、缺少很多值时,该方法行不通)
特殊值填充(使用一个全局常量填充空缺值:如:Unknown,NA,或∞)
使用属性的中心度量(数据分布是对称的,可以使用均值,而倾斜数据分布应该使用中位数)
使用最有可能值(用回归、贝叶斯、决策树、K近邻、EM等方法确定要填充的值,这类方法利用了数据间的关系来进行空值估计)
对数值型变量的缺失值,采用均值插补的方法来填充缺失值:
import pandas as pd
from sklearn.impute import SimpleImputer
from numpy import nan as NA
diabetes_data = pd.read_csv('糖尿病数据集_剩余维度数据.csv',encoding='gb2312')
diabetes_data.head()
#对数值型变量的缺失值,我们采用均值插补的方法来填充缺失值
imr = SimpleImputer(missing_values=NA, strategy='mean')
colume = ["*天门冬氨酸氨基转换酶", "*丙氨酸氨基转换酶", "*碱性磷酸酶", "*r-谷氨酰基转换酶", "*总蛋白", "白蛋白", "*球蛋白", "白球比例", "甘油三酯", "总胆固醇", "高密度脂蛋白胆固醇", "低密度脂蛋白胆固醇", "尿素", "肌酐", "尿酸", "白细胞计数", "红细胞计数", "血红蛋白", "红细胞压积", "红细胞平均体积", "红细胞平均血红蛋白量", "红细胞平均血红蛋白浓度", "红细胞体积分布宽度", "血小板计数", "血小板平均体积", "血小板体积分布宽度", "血小板比积", "中性粒细胞%", "淋巴细胞%", "单核细胞%", "嗜酸细胞%", "嗜碱细胞%" ,"血糖"]
#进行插补
diabetes_data[colume] = imr.fit_transform(diabetes_data[colume])
path_dest = "糖尿病数据集_插补后数据.csv"
diabetes_data.to_csv(path_dest, mode='a', encoding='gb2312')
还可填充固定值、填充均值、填充中位数、填充众数、填充上下条的数据、填充插值得到的数据、填充KNN数据、填充模型预测的值
案例:缺失值填充
一般填充法:
#coding=utf-8
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model.logistic import LogisticRegression
# 评测指标,计算F1 score
def countF1(train, predict):
count = 0 # 统计预测的正确的正样本数
for i in range(len(train)):
if predict[i] == 1 and train[i] == 1:
count += 1
pre = count * 1.0 / sum(predict) # 准确率
recall = count * 1.0 / sum(train) # 召回率
return 2 * pre * recall / (pre + recall)
train_data = pd.read_csv('糖尿病数据集_插补后数据.csv', encoding='gbk')
# 1000,85
filter_feature = ['id','白蛋白'] # 取预测值
features = []
for x in train_data.columns: # 取特征
if x not in filter_feature:
features.append(x)
# 缺失值填充
'''
train_data.fillna(0, inplace=True) # 填充 0
train_data.fillna(train_data.mean(),inplace=True) # 填充均值
train_data.fillna(train_data.median(),inplace=True) # 填充中位数
train_data.fillna(train_data.mode(),inplace=True) # 填充众数,该数据缺失太多众数出现为nan的情况
features_mode = {}
for f in features:
print f,':', list(train_data[f].dropna().mode().values)
features_mode[f] = list(train_data[f].dropna().mode().values)[0]
train_data.fillna(features_mode,inplace=True)
train_data.fillna(method='pad', inplace=True) # 填充前一条数据的值,但是前一条也不一定有值
train_data.fillna(0, inplace=True)
train_data.fillna(method='bfill', inplace=True) # 填充后一条数据的值,但是后一条也不一定有值
train_data.fillna(0, inplace=True)
for f in features: # 插值法填充
train_data[f] = train_data[f].interpolate()
train_data.dropna(inplace=True)
'''
train_data.fillna(0, inplace=True) # 填充 0
train_data_x = train_data[features]
train_data_y = train_data['白蛋白']
X_train, X_test, y_train, y_test = train_test_split(train_data_x, train_data_y, random_state=1) # 划分训练集、测试集
linreg = LogisticRegression()
linreg.fit(X_train, y_train) # 模型训练
y_pred = linreg.predict(X_train) # 模型预测
print ("训练集F1:",countF1(y_train.values, y_pred))
y_pred = linreg.predict(X_test) # 模型预测
print ("测试集F1:",countF1(y_test.values, y_pred))
KNN填充:
import numpy as np
import pandas as pd
from sklearn.cross_validation import train_test_split
from sklearn.linear_model.logistic import LogisticRegression
from fancyimpute import BiScaler, KNN, NuclearNormMinimization, SoftImpute # https://stackoverflow.com/questions/51695071/pip-install-ecos-error-microsoft-visual-c-14-0-is-required
def countF1(train, predict):
count = 0 # 统计预测的正确的正样本数
for i in range(len(train)):
if predict[i] == 1 and train[i] == 1:
count += 1
pre = count * 1.0 / sum(predict) # 准确率
recall = count * 1.0 / sum(train) # 召回率
return 2 * pre * recall / (pre + recall)
train_data = pd.read_csv('C:\\Users\\JingYi\\Desktop\\diabetes_prediction\\train_data.csv', encoding='gbk')
# 1000,85
filter_feature = ['id','label'] # 取预测值
features = []
for x in train_data.columns: # 取特征
if x not in filter_feature:
features.append(x)
train_data_x = train_data[features]
train_data_x = pd.DataFrame(KNN(k=6).fit_transform(train_data_x), columns=features)
train_data_y = train_data['label']
X_train, X_test, y_train, y_test = train_test_split(train_data_x, train_data_y, random_state=1) # 划分训练集、测试集
linreg = LogisticRegression()
linreg.fit(X_train, y_train) # 模型训练
y_pred = linreg.predict(X_train) # 模型预测
print ("训练集",countF1(y_train.values, y_pred))
y_pred = linreg.predict(X_test) # 模型预测
print ("测试集",countF1(y_test.values, y_pred))
例:以Logistic回归模型和F1score作为评测指标,对比各种不同缺失值填充方法。
在某些情况下,缺失值并不意味着错误!
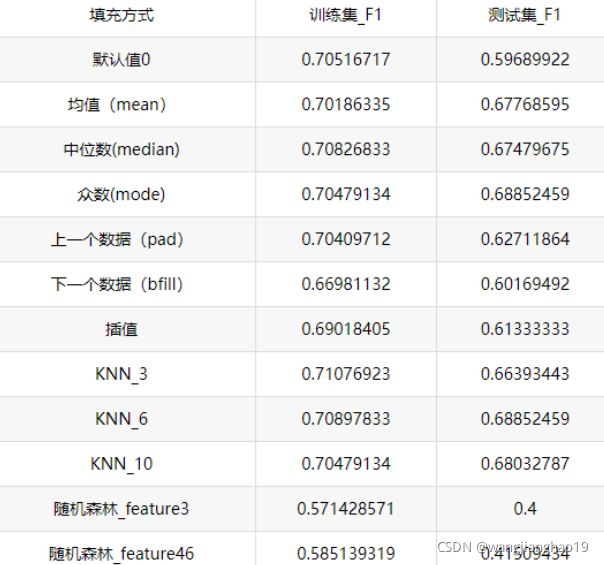
(3)不处理
- 补充处理只是将未知值补以我们的主观估计值,不一定完全符合客观事实
- 在对不完备信息进行补齐处理的同时,或多或少地改变了原始的信息系统
- 对缺失值不正确的填充往往将新的噪声引入数据中,使挖掘任务产生错误的结果
噪声处理
噪声:被测量的变量的随机误差或方差。
数据平滑技术,去掉噪声。(分箱、聚类、回归…)
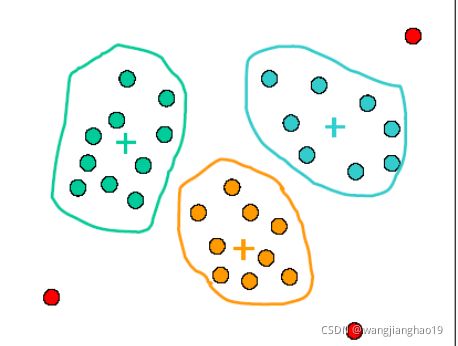
分箱方法平滑噪声

数据清洗路径
阶段1:去除/补全有缺失的数据
阶段2:去除/修改格式和内容错误的数据
阶段3:去除/修改逻辑错误的数据(包括去重、去除不合理值、修正矛盾的内容)
阶段4:去除不需要的数据
阶段5:关联性验证
数据变化、离散化与编码
1、零均值化(又叫中心化)将每一个属性的数据都减去这个属性的均值后,形成一个新数据集合,变换后各属性的数据之和与均值都为零。多个属性经过零均值化变换后,都以零均值分布,各属性的方差不变化,各属性间的协方差也不变化。
意义:数据中心化在回归分析中是取消由于量纲不同、自身变异或者数值相差较大所引起的误差。
原理:数据标准化:是指数值减去均值,再除以标准差。
缺点:假如原始数据并没有呈现高斯分布,标准化的数据分布效果并不好。
五、安装包问题:
引入包可能会报错,解决办法如下:
解决方案:
pip导入包问题
python安装fancyimpute遇见的问题总结
总结
接下来深入学习下回归填充、热卡填充、平滑噪声.