Re7:读论文 FLA/MLAC/FactLaw Learning to Predict Charges for Criminal Cases with Legal Basis
诸神缄默不语-个人CSDN博文目录
论文名称:Learning to Predict Charges for Criminal Cases with Legal Basis
论文ArXiv网址:https://arxiv.org/abs/1707.09168
ACL官方论文网址:https://aclanthology.org/D17-1289/
本文是2017年EMNLP论文,作者是北大的。一般来说这篇论文是新的法律判决预测论文的最早的baseline(除非要用SVM之类更老更经典的general-domain文本分类模型来做baseline)。
本文提出的模型事实上并没有给出官方的命名,但是在后续的论文中提及该模型作为baseline时,大多都用FLA1、MLAC2或FactLaw3作为简称。但是也都没说这是啥的简称啊!这标题里又没有F又没有M怎么会搞出来这种简称的啊!
本文关注罪名预测 (charge prediction) 任务,即给定案例的事实描述文本(或证据),预测该案例触犯了什么罪名(charge)。本文仅关注只有一个被告的情况,即将该任务视作multi-class multi-label分类任务。
同时,本文认为识别出案例对应的法条,有助于预测罪名,因此用统一框架联合建模罪名预测任务和法条抽取任务(本文中成为relevant article extraction)。用全局注意力按照词句的顺序分层表征事实,然后用事实来抽取一部分法条,并用事实来对这部分法条做attention,然后将事实表征和法条表征合并起来做罪名预测。抽取法条能为罪名预测结果提供法律依据 (legal basis),尤其在使用大陆法系的中国大陆。通过实验证明其也能直接提升罪名预测效果。
本文训练出的模型还能应用于其他表达风格的文本(泛化性):除专业性很强的法律文书外,也可以应用于专业性较弱的法律新闻报道中。
本文使用自建的中国刑法案例罪名预测数据集来进行实验,数据集和代码都没有公开。
文章目录
- 1. Background与Motivation(模型构造思路)
- 2. 模型介绍
-
- 2.1 注意力机制的优势
- 2.2 模型整体架构
- 2.3 Document Encoder
-
- 2.3.1 Bi-GRU Sequence Encoder
- 2.3.2 Attentive Sequence Encoder
- 2.4 使用法条
-
- 2.4.1 Top k Article Extractor
- 2.4.2 Article Encoder
- 2.4.3 Attentive Article Aggregator
- 2.5 输出
-
- 2.5.1 Supervised Article Attention
- 3. 实验
-
- 3.1 数据集
- 3.2 实验设置
- 3.3 主实验结果
- 3.4 模型分析
-
- 3.4.1 Case Study
- 3.4.2 Article Extraction Results
- 3.4.3 Performance on News Data
- 4. 代码复现
- 5. 其他本文撰写过程中使用的参考资料
1. Background与Motivation(模型构造思路)
本文认为,罪名预测有三个难点:①罪名易混淆。②多被告、多罪名的情况很复杂。③仅提供罪名很难令人说服,因此需要提供法条作为法律依据。
以前的模型有如下不足:严重依赖专家知识,仅使用相对简单的文本分类范式和浅文本分析,相关任务(如罪名预测和法条预测)被独立对待、导致它们无法互相提升。
2. 模型介绍
2.1 注意力机制的优势
Bi-GRU + two-stack attention mechanism:综合学习案例表征,无需显式的其他人工标注。
本文使用two-stack attention mechanism来捕获事实描述对法条的隐对应关系。
在事实侧,使用句子级别和文档级别的Bi-GRU模型来编码事实描述文本(参考文献:Neural machine translation by jointly learning to align and translate),注意力机制用来捕获词语和句子之间的关系,以捕获全局和细节信息。
在法条侧,给定事实描述表征后,用注意力机制来用multi-label范式选择与案例最相关的法条。
2.2 模型整体架构
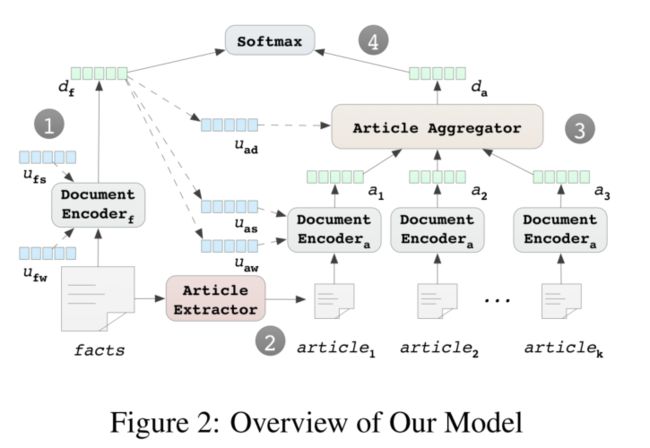
第一步:用document encoder嵌入输入事实描述,得到 d f \mathbf{d}_f df( u f w \mathbf{u}_{fw} ufw 和 u f s \mathbf{u}_{fs} ufs 是词级别和句子级别的context vectors,是做词或句子级别attention的,用于attentively选择重要词语和句子)。
第二步:同时,用article extractor通过输入事实描述抽取k个最相关的法条。
第三步:用另一个document encoder嵌入法条,将其加权聚合得到聚合法条表征 d a \mathbf{d}_a da(通过article aggregator来attentively选择支持性法条)。从 d f \mathbf{d}_f df 动态生成3个context u a w , u a s \mathbf{u}_{aw},\mathbf{u}_{as} uaw,uas 和 u a d \mathbf{u}_{ad} uad,用于document encoder和article aggregator生成attention值。
第四步:concat d f \mathbf{d}_f df 和 d a \mathbf{d}_a da,通过softmax分类器预测罪名分布。
2.3 Document Encoder
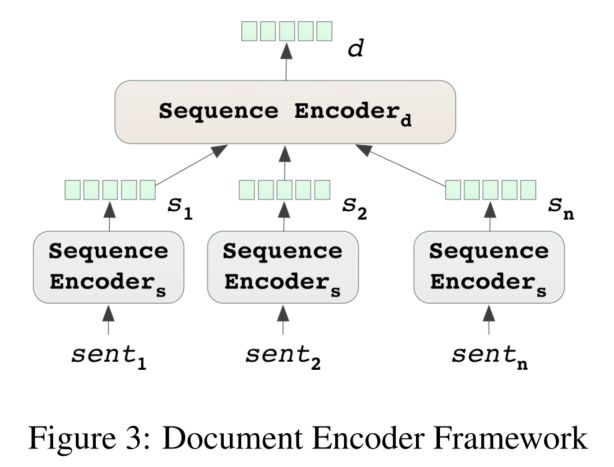
2.3.1 Bi-GRU Sequence Encoder
图中2个encoder用的都是Bi-GRU4。
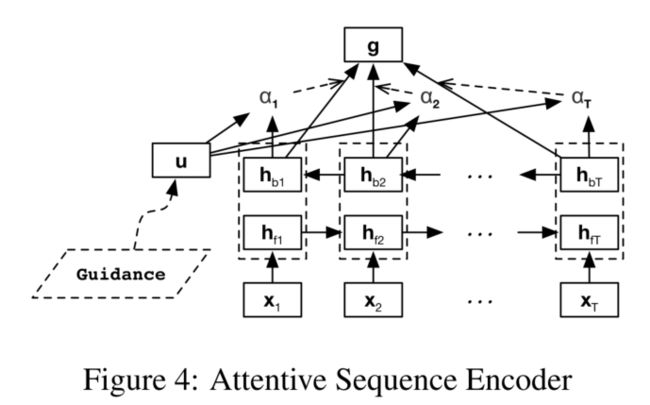
2.3.2 Attentive Sequence Encoder
直接使用Bi-GRU得到的双向GRU的向量在序列很长时难以捕获全部信息,使用平均值会使无用元素与重要元素被同等对待。参考5,本文使用context vector来attentively聚合元素,但除在嵌入事实时使用的全局context vector,在有额外guidance可用时动态生成context vector(就是指用事实对法条做attention那块)。
![]()

词级别和句子级别分别做attention。
参考文献:Document Modeling with Gated Recurrent Neural Network for Sentiment Classification和5
2.4 使用法条
由于法条太多,所以在法条上应用复杂模型太耗时,而且难以scale。
第一步:构建快且易scale的分类器来过滤大量不相关法条,并保留k个最相关的法条。
第二步:用神经网络来表征这k个法条,然后用article-side attention module来选取最相关的一些法条来做罪名预测。
2.4.1 Top k Article Extractor
将相关法条抽取任务视作multiple binary classifications任务,即为每个法条构建一个binary classifier,这样比较容易对新的法条建立新模型。
参考Predicting associated statutes for legal problems6的preliminary分类阶段,本文使用了基于词的SVM做分类器,速度快,在文本分类上表现效果好。(参考文献:Learning to Classify Text Using Support Vector Machines: Methods, Theory and Algorithms和Baselines and bigrams: Simple, good sentiment and topic classification)
使用BoW TF-IDF特征,卡方选择,线性核。
2.4.2 Article Encoder
使用与前文所述相同的ducoment encoder生成每个法条的表征,使用的是前述事实描述文本生成的context vector:
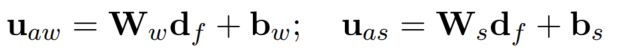
2.4.3 Attentive Article Aggregator
使用RNN(k个法条的顺序并不完全可靠,但是根据Matching Networks for One Shot Learning,无序情况下使用Bi-RNN来表征全局仍然有效)获取相关法条的共现倾向。
使用本博文2.3.2部分介绍过的attentive sequence encoder,attention还是用前文提及过的:
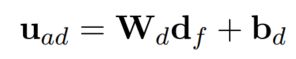
通过attentive sequence encoder生成的attention values可被视作每个法条对输入案例的相关性,可用于排序和过滤最相关的k个法条。
结果可视作罪名预测任务的法律基础。
2.5 输出
将concat向量(也可以仅使用事实侧或法条侧向量)通过2个连续的全连接层,然后用softmax分类器生成预测罪名分布。
用验证集决定阈值 τ \tau τ,输出概率高于 τ \tau τ的罪名视作正预测结果。
训练阶段的损失函数是交叉熵:
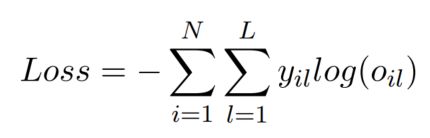
其中目标分布 y i y_i yi,正标签是 1 m i \frac{1}{m_i} mi1( m i m_i mi是案例 i i i的正标签数),负标签是0。
2.5.1 Supervised Article Attention
利用真实法条来在训练时监督法条attention:要求k个法条的article attention distribution模拟target article distribution(类似罪名分布的处理方式)
使用交叉熵:
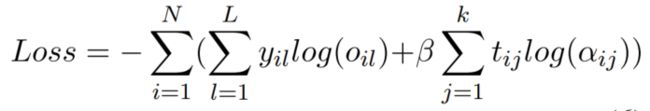
3. 实验
3.1 数据集
本文使用的数据集是直接从中国政府网站裁判文书网7爬取的公开法律文书,从2013年开始。用50000个文档作为训练集,5000个文档作为验证集,5000个文档作为测试集。为了保证每一罪名都有充分的训练数据,仅分类在训练集中出现超过80次的罪名,触犯其他罪名的文档作为negative data(这个negative data应该是指在训练过程中作为负标签,因为模型是将每个标签作为一个二分类任务嘛)。
本文使用简单的规则自动提取事实描述、相关法律和罪名,其中罪名部分是通过人工收集的罪名名单来识别的,法条部分则是通过正则表达式:第[、零〇一二两三四五六七八九十百千0-9]+条(之[一二两三四五六七八九十])?)来抽取的。
如图所示:

在事实描述部分出现的罪名被mask掉了(这种情况很少见)。
法条来自中国刑法。
最终的数据集包含50种罪名,321个法条,平均每个案例的事实描述文本长383个词,平均每个案例对应3.81个法条,3.56%的案例是多案例的。
罪名分布不平衡,最多的5个罪名涵盖了超过60%的案例。
由于将事实匹配到每个罪犯上的标注代价很高,所以本文仅考虑了单被告场景。
3.2 实验设置
分词和词性标注工具:HanLP
词向量:在裁判文书、法学论坛网页和百度百科上训练word2vec8词向量,含573353个词语,100维。
对每个词性标签随机初始化50维向量,与词向量concat,作为最终输入。
Bi-GRU的GRU的维度是75,输出层的2个全连接层维度分别是200和150,k是20, β \beta β是0.1, τ \tau τ是0.4。
优化器是SGD,学习率是0.1,batch size是8。
SVM用卡方选择选择最相关的200维特征。
3.3 主实验结果
出于分布不平衡的考虑,本文使用macro和micro两个层面的precision, recall和F1值。
比较基线:去掉article attention supervision(输出部分的那个),仅使用事实描述(类似5。但是多标签分类)/法条侧表征来实现罪名预测,和SVM。
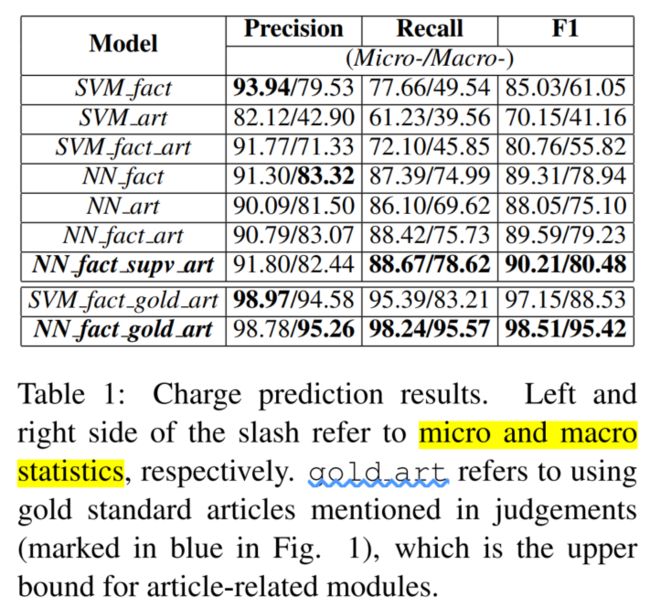
具体分析略,考虑抽取噪音……之类的。
3.4 模型分析
3.4.1 Case Study
罪名间存在star-like confusion patterns:一个罪名会被误分类为多种罪名。
3.4.2 Article Extraction Results
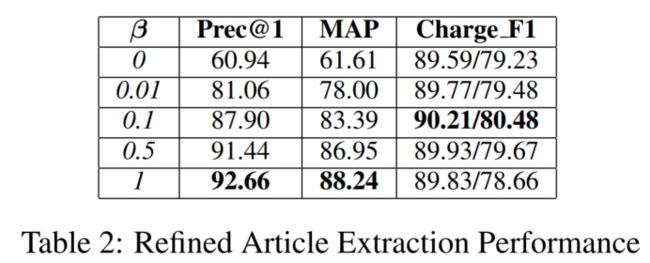
略。
3.4.3 Performance on News Data
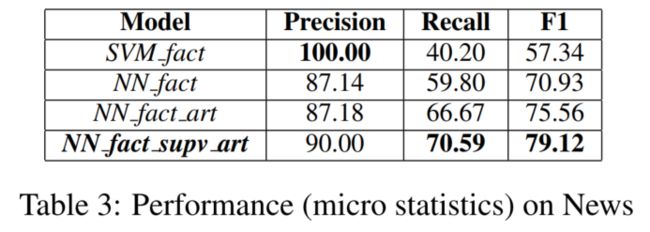
略。
4. 代码复现
等我服务器好了再说。
这个数据集非常肖似CAIL数据集,很多做CAIL数据集的也会复现这个模型作为baseline,等我服务器好了就在pytorch_ljp项目里复现一下这个模型。
5. 其他本文撰写过程中使用的参考资料
- 【Paper】Learning to Predict Charges for Criminal Cases with Legal Basis___盛夏光年__的博客-CSDN博客
- Learning to Predict Charges for Criminal Cases with Legal Basis - BAMTERCELBOO Blog
使用FLA命名的论文有:
Re6:读论文 LeSICiN: A Heterogeneous Graph-based Approach for Automatic Legal Statute Identification fro ↩︎使用MLAC命名的论文有:
Legal Judgment Prediction via Event Extraction with Constraints ↩︎使用FactLaw命名的论文有:Re23:读论文 How Does NLP Benefit Legal System: A Summary of Legal Artificial Intelligence ↩︎
Bi-GRU部分的参考文献:Neural Machine Translation by Jointly Learning to Align and Translate
GRU部分的参考文献:Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation ↩︎Hierarchical Attention Networks for Document Classification ↩︎ ↩︎ ↩︎
设计了一个易扩展的两阶段方法:首先用SVM做初步法条分类,然后用词级别特征和法条之间的共现依赖来重排。
本文也使用SVM来抽取k个法条。
可以明显看出跟本文的相似与不同之处。 ↩︎http://wenshu.court.gov.cn ↩︎
Distributed representations of words and phrases and their compositionality ↩︎