引言
Apache Calcite 是一个动态数据管理框架,其中包含了许多组件,例如 SQL 解析器、SQL 验证器、SQL 优化器、SQL 生成器等。因为 Calcite 的体系结构并不支持数据的存储和处理,所以 Calcite 天然具备了在多种计算引擎和存储格式之间作为“中介者”的能力。 前文《一条 SQL 的查询优化之旅》提到,SQL 的查询是从 SQL 解析和 SQL 验证开始的,所以本文将围绕这两个话题展开。
目标和收益
本文第一部分介绍如何基于 Calcite 实现一个简单的 SQL 解析器并扩展其语法, 并将外部数据库的 SQL 语法转换成 Calcite 内部的解析体系。第二部分将介绍 SQL 验证的流程和如何验证扩展的 SQL,如自定义函数等。
一、基于 Calcite 实现一个自定义 SQL 解析器
1.1 Calcite SQL 解析器介绍
Calcite 默认使用 JavaCC 生成 SQL 解析器,可以很方便的将其替换为 Antlr 作为代码生成器 。JavaCC 全称 Java Compiler Compiler,是一个开源的 Java 程序解析器生成器,生成的语法分析器采用递归下降语法解析,简称 LL(K)。主要通过一些模版文件生成语法解析程序(例如根据 .jj 文件或者 .jjt 等文件生产代码)。
Calcite 的解析体系是将 SQL 解析成抽象语法树, Calcite 中使用 SqlNode 这种数据结构表示语法树上的每个节点,例如 "select 1 + 1 = 2" 会将其拆分为多个 SqlNode。
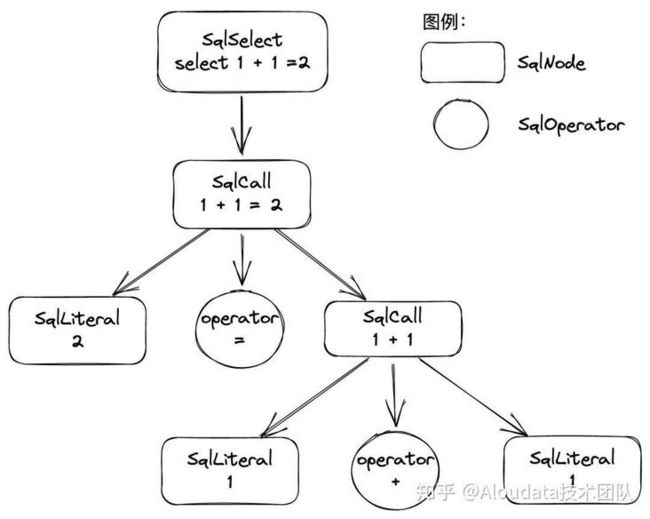
SqlNode 有几个重要的封装子类,SqlLiteral、SqlIdentifier 和 SqlCall。 SqlLiteral:封装常量,也叫字面量。SqlIdentifier:SQL 标识符,例如表名、字段名等。SqlCall:表示一种操作,SqlSelect、SqlAlter、SqlDDL 等都继承 SqlCall。
1.2 实现一个简单自定义 SQL Parser
Calcite 提供了一个默认的 SQL 语法解析器,默认支持的语法可以查看此文档:https://calcite.apache.org/docs/reference.html,除了默认语法外,Calcite 还提供了其他 SQL 语法的兼容,例如 STRICT_92、STRICT_99、STRICT_2003、MYSQL_5、ORACLE_12 等,这部分可参考 Calcite 源码 SqlConformanceEnum 类。
如果 Calcite 解析器并不能满足我们的需求,需要扩展语法操作怎么办呢?
第一种方法是直接修改 Calcite 源码,添加我们需要的语法实现。但这种方式显然对 Calcite 的侵入性太强,并不是最优的办法。
第二种方法是采用模版引擎来扩展 SQL 语法,相比第一种侵入性更小,达到了解耦的目的。
Calcite 支持使用 FreeMarker 模版引擎扩展语法,下图是 Calcite 源码中通过模版引擎扩展 SQL 语法的相关目录结构。

其中,templates 文件夹下的 Parser.jj 作为模版,includes 目录下是扩展语法文件,config.fmpp 作为整体的配置,包含定义解析器类名、导入扩展语法文件和自定义关键字等。
所以我们实现自定义 SQL Parser 的步骤为:
- 获取 Calcite 源码中的 Parser.jj 文件,将此文件作为模版用于后续扩展。
- 编写自定义 SQL 扩展语法文件和配置文件。
- 使用 JavaCC 编译。
1.2.1 获取 Calcite 源码中的 Parser.jj 文件
使用 Maven 插件 maven-dependency-plugin 直接从 Calcite 源码包中进行拷贝,将 Parser.jj 文件拷贝到项目构建目录下。
org.apache.maven.plugins
maven-dependency-plugin
unpack-parser-template
initialize
unpack
org.apache.calcite
calcite-core
1.31.0
jar
true
${project.build.directory}/
**/Parser.jj
false
可以使用 mvn initialize 进行命令测试,如果成功我们会在 target 目录下找到拷贝的语法模版文件。
1.2.2 自定义 SQL 语法
我们可以仿照 Calcite 在代码目录中创建 codegen 目录结构,新建一个 .ftl 文件, 下面以 Trino 的 CREATE MATERIALIZED VIEW 为例,演示如何在 Calcite 中新增这个语法:
/*为了演示方便 SQL语法有所简化*/
CREATE MATERIALIZED VIEW
[ IF NOT EXISTS ] view_name
AS query第一步,新增一种 SqlCall, 新建一个类继承 SqlCall,实现构造方法并重写 unparse(),unparse()方式是 SqlNode 的解析器,负责将 SqlNode 转换为 Sql。getOperator() 方法返回当前 SqlNode 的操作符类型,所有的操作符类型可以在 org.apache.calcite.sql.SqlKind 中找到,CREATE MATERIALIZED VIEW 显然是一种扩展的 DDL,应该返回 SqlKind.OTHER_DDL,getOperandList() 返回操作符列表,这里我们可以返回物化视图的名字和 AS 后面的语句,用于自定义 DDL 的校验。
public class CreateMaterializedView
extends SqlCall
{
public static final SqlSpecialOperator CREATE_MATERIALIZED_VIEW = new SqlSpecialOperator("CREATE_MATERIALIZED_VIEW", SqlKind.OTHER_DDL);
SqlIdentifier viewName;
boolean existenceCheck;
SqlSelect query;
public CreateMaterializedView(SqlParserPos pos, SqlIdentifier viewName, boolean existenceCheck, SqlSelect query)
{
super(pos);
this.viewName = viewName;
this.existenceCheck = existenceCheck;
this.query = query;
}
@Override
public SqlOperator getOperator()
{
return CREATE_MATERIALIZED_VIEW;
}
@Override
public List getOperandList()
{
List operands = new ArrayList<>();
operands.add(viewName);
operands.add(SqlLiteral.createBoolean(existenceCheck, SqlParserPos.ZERO));
operands.add(query);
return operands;
}
@Override
public void unparse(SqlWriter writer, int leftPrec, int rightPrec)
{
writer.keyword("CREATE MATERIALIZED VIEW");
if (existenceCheck) {
writer.keyword("IF NOT EXISTS");
}
viewName.unparse(writer, leftPrec, rightPrec);
writer.keyword("AS");
query.unparse(writer, leftPrec, rightPrec);
}
} 第二步,编写语法文件, 在 codegen/includes 目录下新建 parserImpls.ftl 文件。语法文件内容如下:
SqlNode SqlCreateMaterializedView() :
{
SqlParserPos pos;
SqlIdentifier viewName;
boolean existenceCheck = false;
SqlSelect query;
}
{
{ pos = getPos(); }
<#-- [] 代表里面的元素可能出现 -->
[ { existenceCheck = true; } ]
<#-- CompoundIdentifier() 为 Calcite 内置函数,
可以解析类似 catalog.schema.tableName 这样的全路径表示形式 -->
viewName = CompoundIdentifier()
<#-- SqlSelect() 为 Calcite 内置函数,解析一个 select sql -->
query = SqlSelect()
{
return new CreateMaterializedView(pos, viewName, existenceCheck, query);
}
} 第三步,配置 config.fmpp 文件, 在 codegen 目录下新建 config.fmpp 文件。定义解析器的包名和类型,声明新增的关键字和解析方法等。
data: {
parser: {
package: "com.aloudata.demo.parser.impl",
class: "DemoSqlParserImpl",
imports: [
"com.aloudata.tardis.parser.CreateMaterializedView.CreateType"
]
keywords: [
"IF",
"MATERIALIZED"
]
statementParserMethods: [
"SqlCreateMaterializedView()"
]
implementationFiles: [
"parserImpls.ftl"
]
}
}
freemarkerLinks: {
includes: includes/
}package 和 class 就是 JavaCC 生成的解析器的类名和包路径。imports 中需要导入语法文件中使用到的 Java 类,keywords 关键字只需包含 Calcite 原生不存在的即可,statementParserMethods 应包含解析的入口方法,implementationFiles 中为自定义语法文件名,freemarkerLinks.includes 为自定义语法文件相对路径。
1.2.3 JavaCC 编译
使用 FreeMarker 模版插件根据 config.fmpp 生成 parser.jj 文件,最后使用 JavaCC 编译插件生成最终的解析器代码。
- 配置 FreeMarker 插件
Maven 配置中
com.googlecode.fmpp-maven-plugin
fmpp-maven-plugin
1.0
src/main/codegen/config.fmpp
target/generated-sources/fmpp
${project.build.directory}/codegen/templates
org.freemarker
freemarker
2.3.28
generate-fmpp-sources
generate-sources
generate
- 配置 JavaCC 插件
org.codehaus.mojo
javacc-maven-plugin
2.6
javacc
generate-sources
javacc
${project.build.directory}/generated-sources/fmpp
**/*.jj
1
false
${project.build.directory}/generated-sources/javacc
- 测试
我们可以写一段简单的测试代码:
@Test
public void test() throws SqlParseException {
String sql = "CREATE MATERIALIZED VIEW IF NOT EXISTS "test"."demo"."materializationName" AS SELECT * FROM "system"";
SqlParser.Config myConfig = SqlParser.config()
.withQuoting(Quoting.DOUBLE_QUOTE)
.withQuotedCasing(Casing.UNCHANGED)
.withParserFactory(DemoSqlParserImpl.FACTORY);
SqlParser parser = SqlParser.create(sql, myConfig);
SqlNode sqlNode = parser.parseQuery();
assertTrue(sqlNode instanceof CreateMaterializedView);
System.out.println(sqlNode);
}输出:
![]()
1.3 原理
上文介绍时提到,JavaCC 生成的语法分析器采用递归下降(自顶向下)语法解析,简称 LL(K),第一个 L 代表从左到右扫描输入,第二个 L 代表每次都进行最左推导,K 表示每次向右探索 K 个终结符。JavaCC 默认生成 LL(1) 的解析器。
JavaCC 中的词法分析器会将语句拆分成一系列的子单元,在 JavaCC 中称为 token,语法分析器会拿着这个 token 串以 LL(1) 的方式进行匹配,看是否符合定义的语法结构。描述起来比较抽象,下面举个例子:
例如 Total = price + tax; 这个语句,JavaCC 会将整条语句拆分成以下5个 token。
![]()
1.3.1 自顶向下 LL(1) 分析基本流程
上下文无关文法是 LL(1) 的充要条件,上下文无关文法的形式定义比较晦涩(可以参考https://baike.baidu.com/item/上下文无关文法/2001908),可以简单理解为 A 可以直接推到出 aB (A → aB)是一个上下文无关文法,u A b 推导出 aB (u A b → aB)当 A 的前一个是 u,下一个是 b 的时候才能应用次规则,这样就是上下文有关文法。现在有一种语法:
S –> AB
A –> aA | ε // ε 代表一个空字符
B –> b |上面每一行,形如“A –> aA | ε”的式子称为产生式。产生式左边的符号称为“非终结符”,这个符号既可以出现在产生式的左边也可以出现在产生式的右边,位于产生式右边的 'a' 称为“终结符”,它意味着无法再产生新的符号,终结符只能出现在产生式右边。同时,上述产生式中有一个特别的非终结符 'S',这种语法的所有句子都以它为起点产生,这个符号被称为“起始符号(startsymbol) ”。
例如,要分析的句子为 aaab,我们把解析过程和中间句子整理成以下表格:首先从起始符号 S 开始展开到最终语句 aaab,要匹配 aaab 中左边第一个字符 a,S 只能推导为 AB,所以用 AB 替换 S。
| 中间句子 | 要匹配的语句 | 产生式 |
|---|---|---|
| S | a aab | S → AB |
| AB | a aab |
由于 A 是非终结符,下面要展开 A,A 有两种产生式 A → aA, A → ε,和要匹配的语句进行比较发现 A → aA 可以匹配第一个字符 a,以此类推前三个 'a' 都可以以这种方式匹配。展开过程如下:
| 中间句子 | 要匹配的语句 | 产生式 |
|---|---|---|
| S | a aab | S → AB |
| AB | a aab | A → aA |
| aAB | a a ab | A → aA |
| aaAB | aa a b | A → aA |
| aaaAB | aaa b |
最后一个 a 匹配结束后,发现只能应用产生式 A -> ε,否则就无法得到 aaab,应用此产生式后得到:
| 中间句子 | 要匹配的语句 | 产生式 |
|---|---|---|
| S | a aab | S → AB |
| AB | a aab | A → aA |
| aAB | a a ab | A → aA |
| aaAB | aa a b | A → aA |
| aaaAB | aaa b | A → ε |
| aaaB | aaa b | B → |
最后按照上面的原则尝试展开非终结符 B,最终得到 aaab,整个语句推导成功。
| 中间句子 | 要匹配的语句 | 产生式 |
|---|---|---|
| S | a aab | S → AB |
| AB | a aab | S → aA |
| aAB | a a ab | S → aA |
| aaAB | aa a b | S → aA |
| aaaAB | aaa b | S → ε |
| aaaB | aaa b | B → b |
| aaab | aaab | ACCEPT |
这是一个非常简单的语句推导过程,LL(1) 还会有其他更多的复杂情况与约束,感兴趣可以参考此书的第九章和第十章(http://pandolia.net/tinyc)
1.3.2 LL(1) 的优缺点
LL(1) 分析法的优点是构造方法较简单,且分析速度非常快,每读到第一个符号就可以预测出整个产生式。缺点则是对语法的限制太强,它要求同一个非终结符的不同产生式的首字符集合之间互不相交,否则我们就无法唯一确定一种语法。
不过,在 JavaCC 编译插件中或语法文件中可以使用 lookAhead 配置解析时向前探测的 token 数量,也就是修改 LL(K) 中的 K 值,来解决一些语法冲突问题。
- JavaCC 插件中配置
2
- 词法中使用 lookAhead
SqlNode SqlCreateMaterializedView() :
{
...
}
{
LOOKAHEAD(2)
...
}1.3.3 扩展
与 LL 分析法对应的还有 LR 分析法,和 LL 正好相反,LR 是从最终表达式向上折叠,直到跟产生式无法再匹配为止。 LR 分析法相比于 LL 来说在普适性方面占有绝对的优势,因为 LR 文法能够支持更多上下文无关文法,并且不需要考虑消除左递归的问题。
- 左递归问题
左递归:是指形如 A -> A u 这样的规则。
LL(1) 的分析法无法解决“左递归”问题,这是 LL 解析器的局限,因为一个含左递归的语法(如:A -> Aa | c)中,必然存在相交的现象。 Antlr4 中的 ALL 解析器解决了左递归问题,但是对于间接左递归仍然无能为力。并且在自顶向下分析法中,左递归的出现对性能的影响极大,因为出现左递归就意味着需要对匹配串进行回溯,而回溯分析一般都非常慢,所以应该尽量避免这种语法的出现。
总结
本文介绍了 Calcite SQL 解析模块以及语法扩展的方式,并对 LL(k) 分析法做了简单阐述,以 LL(1) 为例探究了整个分析过程。下一篇,我们将介绍Calcite SQL 的验证流程与原理,一起探究如何在 SQL 验证阶段进行语法的扩展。
钱可以带来快乐,玩技术也可以!最后,如果你对数据虚拟化、Calcite 原理技术、湖仓平台、SQL 优化器感兴趣的话,欢迎关注“Aloudata技术团队”公众号。
✎ 本文作者/ 淳译,Aloudata OLAP 引擎开发工程师,参与 Aloudata AIR Engine 的多个核心模块开发,目前负责 Aloudata 数据虚拟化引擎的 SQL 层、元数据和多源异构引擎集成等相关工作。