Hadoop实战演练:搜索数据分析----TopK计算(2)
林炳文Evankaka原创作品。转载请注明出处http://blog.csdn.net/evankaka
工程源码下载:https://github.com/appleappleapple/BigDataLearning/tree/master/Hadoop-Demo
这里接上文Hadoop实战演练:搜索数据分析----数据去重 (1)
本文要根据上面算出来的结果我们要计算TopK搜索词。要得到热搜永词,首先得到每个词的搜索次数。
记得在上文的输出数据源如下格式,这里要当前本次运算的输入源

1、WordCount。首先计算每个关键词出现的次数
package com.lin.keyword;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
* 功能概要:统计搜索词
*
* @author linbingwen
*/
public class KeyWordCount {
public static class Map extends Mapper {
private final static IntWritable one = new IntWritable(1);
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 将输入的纯文本文件的数据转化成String
String line = value.toString();
// 将输入的数据首先按行进行分割
StringTokenizer tokenizerArticle = new StringTokenizer(line, "\n");
// 分别对每一行进行处理
while (tokenizerArticle.hasMoreElements()) {
// 每行按空格划分
StringTokenizer tokenizerLine = new StringTokenizer(tokenizerArticle.nextToken());
String c1 = tokenizerLine.nextToken();//
String c2 = tokenizerLine.nextToken();// 关键词
Text newline = new Text(c2);
context.write(newline, one);
}
}
}
public static class Reduce extends Reducer {
private IntWritable result =new IntWritable();
// 实现reduce函数
@Override
public void reduce(Text key, Iterable values,Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable val:values){
count += val.get();
}
result.set(count);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//设置hadoop的机器、端口
conf.set("mapred.job.tracker", "10.75.201.125:9000");
//设置输入输出文件目录
String[] ioArgs = new String[] { "hdfs://hmaster:9000/clean_same_out", "hdfs://hmaster:9000/Key_out" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: ");
System.exit(2);
}
//设置一个job
Job job = Job.getInstance(conf, "key Word count");
job.setJarByClass(KeyWordCount.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(KeyWordCount.Map.class);
job.setCombinerClass(KeyWordCount.Reduce.class);
job.setReducerClass(KeyWordCount.Reduce.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
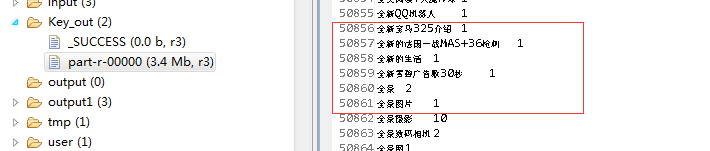
在wordCount上面输出的数据基础上来做运算
package com.lin.keyword;
import java.io.IOException;
import java.util.TreeMap;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
/**
*
* 功能概要:统计top 热搜词
*
* @author linbingwen
*/
public class TopK {
public static final int K = 100;
public static class KMap extends Mapper {
TreeMap map = new TreeMap();
@Override
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
if(line.trim().length() > 0 && line.indexOf("\t") != -1) {
String[] arr = line.split("\t", 2);
String name = arr[0];
Integer num = Integer.parseInt(arr[1]);
map.put(num, name);
if(map.size() > K) {
map.remove(map.firstKey());
}
}
}
@Override
protected void cleanup(Mapper.Context context) throws IOException, InterruptedException {
for(Integer num : map.keySet()) {
context.write(new IntWritable(num), new Text(map.get(num)));
}
}
}
public static class KReduce extends Reducer {
TreeMap map = new TreeMap();
@Override
public void reduce(IntWritable key, Iterable values, Context context) throws IOException, InterruptedException {
map.put(key.get(), values.iterator().next().toString());
if(map.size() > K) {
map.remove(map.firstKey());
}
}
@Override
protected void cleanup(Reducer.Context context) throws IOException, InterruptedException {
for(Integer num : map.keySet()) {
context.write(new IntWritable(num), new Text(map.get(num)));
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//设置hadoop的机器、端口
conf.set("mapred.job.tracker", "10.75.201.125:9000");
//设置输入输出文件目录
String[] ioArgs = new String[] { "hdfs://hmaster:9000/Key_out", "hdfs://hmaster:9000/top_out" };
String[] otherArgs = new GenericOptionsParser(conf, ioArgs).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: ");
System.exit(2);
}
//设置一个job
Job job = Job.getInstance(conf, "top K");
job.setJarByClass(TopK.class);
// 设置Map、Combine和Reduce处理类
job.setMapperClass(KMap.class);
job.setCombinerClass(KReduce.class);
job.setReducerClass(KReduce.class);
// 设置输出类型
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
// 将输入的数据集分割成小数据块splites,提供一个RecordReder的实现
job.setInputFormatClass(TextInputFormat.class);
// 提供一个RecordWriter的实现,负责数据输出
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入和输出目录
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
输出结果:这是从小到大的热搜索词,这里只统计了前100个
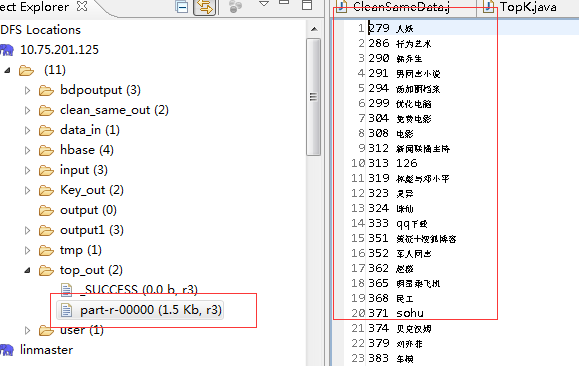

结果正确输出没问题