自动驾驶AI也能像真人司机一样有性格吗?
有没有想过,自动驾驶AI也可以像人类驾驶员一样,变得有自己的“喜笑怒骂”?
随着自动驾驶技术的不断进步,越来越多的自动驾驶车辆开始在实际道路中部署。然而人类的驾驶风格是有差异的,有礼貌谨慎的驾驶员,也有鲁莽大意的驾驶员,甚至是疲劳驾驶、酒驾的驾驶员,相比之下,无人驾驶的车辆驾驶风格相对单一,这会带来一系列问题:
1.自动驾驶车辆如何能够辨别出其他人类驾驶员的驾驶风格,以便进行更高效且安全的交互?
2.如何赋予自动驾驶车辆多样的驾驶风格,产生拟人的驾驶行为,以便融入人类驾驶环境中,不会让其他人类驾驶员感到怪异和难以适从?
在本文中,我们将介绍一种方法,使得无人车拥有人类一样的驾驶风格和心理活动。
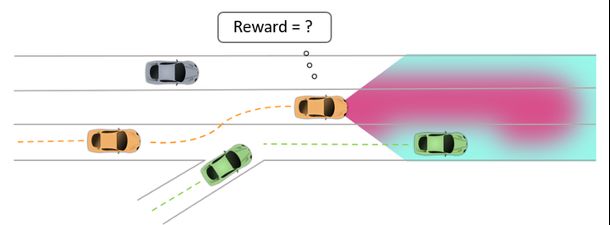
首先,我们需要简单介绍一下决策AI驾驶车辆的基本工作原理。通常,无人车通过Lidar,Camera,Radar等感知系统实时感知车辆外部环境(Perception)并自我定位(Localization),并基于当前或者历史状态信息,对其他道路参与者的未来意图以及轨迹进行预测(Prediction),随后根据工程师们设定或者从数据中学习出的奖励或优化机制来规划处一条安全,高效且舒适的路径(Planning)。在这种Optimization-Based的规划方法中,无人车的行为决策很大程度上取决于设定的奖励/优化机制。
在传统的方法中,无人车的优化目标通常包含无人车自身的安全,效率和舒适性,我们称之为自我型规划策略(egoism policy)。一般而言,这样的优化目标能够解释并产生大部分的驾驶行为。然而,在我们实际生活中,我们常常看到一些礼让,或者是鲁莽的驾驶行为。这些行为难以被传统的自我型规划策略解释。因此,从心理学出发,我们需要考虑人类的礼貌行为(courtesy policy),自信行为(confidence policy)。礼貌性行为,指的是人类在与人交互时,避免产生使他人改变计划,会有他人带来麻烦的行为。而自信行为,则指人类喜欢确定性的结果而不是不确定性的结果,因此会主动产生动作以减小不确定性。
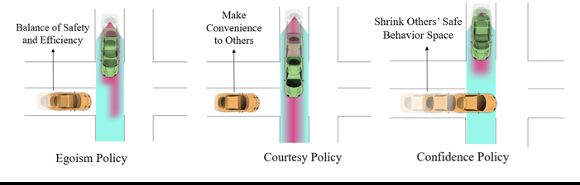
因此,为了捕捉人类的这些心理行为,本方法提出了一套“社会兼容型规划”(Socially-Compatible Policy):无人车的奖励/优化目标中,不仅仅包含自身的安全、高效和舒适性(egoism reward),还同时考虑了对其他人造成的不便性(courtesy reward),以及决策的自信程度(confidence reward)。最终的决策结果,是三者之间的一个平衡。这样的方案使得无人车可以:
1)产生多样的,拟人的驾驶风格
2)辨认出其他人类驾驶员的驾驶风格
3)针对人类驾驶员过往的驾驶风格,对其未来行为做出更准确的预测

下面,本文将以五个问题的方式展开解释“社会兼容型规划”:
1.如何描述车辆间的交互行为?
2.如何定义各项奖励函数?(egoism, courtesy, comfort)
3.“社会兼容型规划”可以产生多样的驾驶行为吗?
4.“社会兼容型规划”如何辨认出人类的驾驶风格与心理?
5.辨认出人类的驾驶风格后,对未来的轨迹预测有帮助吗?
1.如何描述车辆间的交互行为
车辆/人类之间的交互行为,往往被描述为博弈行为(game theory),双方都在优化各自的奖励函数。具体而言,本方法将其假设为Stackelberg博弈,即一辆车为领导者,主动做出决策,而另一辆车为跟随着,根据领导者的决策作出反应。
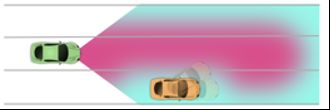
与此同时,人类的驾驶行为,往往是非理性的(irrationality)。即当人类在优化某一目标时,在各种因素导致下,往往难以做出最完美的选择,其行为往往是下图所示的一个概率分布。
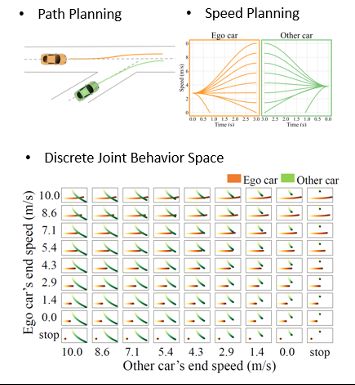
为描述两辆车行为的联合概率分布,本方法采用基于采样的规划方法(sample-based planning),其分为三步:
1)路径规划(path planning),根据两辆车的位置,车道信息,生成两辆车的未来路线
2)速度规划(speed planning),根据两辆车当前的速度,对其未来的速度曲线进行采样(speed profile sampling),并将其速度投影到路线上,得到未来轨迹
3)将两辆车的所有可能轨迹结合,得到两辆车的联合行为空间(Discrete Joint Behavior Space)。这样得到联合行为空间,包含了所有可能出现的驾驶情况,能够充分描述两车的交互行为
2.如何定义各项奖励函数(egoism, courtesy, comfort)
为产生多样的驾驶风格,本方法提出了“社会兼容”奖励函数,其囊括了egoism,courtesy,comfort三个奖励项,并用线性组合的形式描述三个奖励之间的权衡关系。
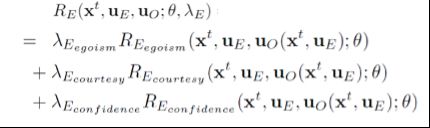
1)自我奖励(egoism reward)
在自我奖励中,车辆只考虑自身的安全,舒适以及高效性。因此本方法将自我奖励函数建模为这三个特征的线性组合,奖励函数中的参数可由工程师设计或使用逆强化学习(Inverse Reinforcement Learning)从数据中学出。
![]()
在计算自我奖励时,考虑到当本车做出一种决策时,他车可能会有多种概率不同的反应,每种反应会带来对应的奖励值。因此,本车能够得到的自我奖励,将是这样的反应分布的一个期望值:
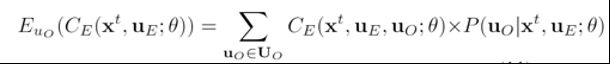
2)礼貌奖励(courtesy reward)
在礼貌奖励中,人类会避免改变他人最初的行为。因此,本方法将礼貌奖励项建模为,他人原始的行为分布以及受影响后的行为分布之间的差异。具体而言,他人原始的行为分布,可以通过对他人的未来行为进行预测(Prediction)得到。而他人受影响后的行为分布,可以通过对他人未来行为的条件预测(Conditional Prediction)得到。随后,本方法使用KL Divergence描述两个分布之间的差异,来计算得到礼貌奖励值。

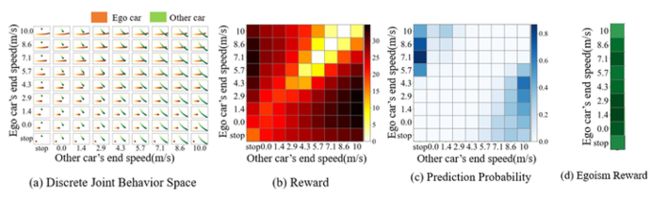
3)自信奖励(confidence reward)
在自信奖励中,人类会偏好于更确定性的结果。因此,其会主动做出动作以减少对方反应的不确定性。根据行为心理学中的研究,本方法使用差异模型(Difference Model),通过计算他车概率最大的两个决策之间的概率差,量化自信奖励。
到此,我们完成了“社会兼容”建立函数的建立。
3.“社会兼容型规划”可以产生多样的驾驶行为吗
本方法在环岛场景中对不同驾驶策略的行为进行了验证。下图中,橙色车辆为本车,绿色车辆为他车。
案例一:本车初始车位靠后
如下图所示,自我策略(egoism policy)将产生中等距离的交互;礼貌策略(egoism policy)下,本车将停住,不进入环岛,尽量不去影响他车;而自信策略下(confidence policy)下,本车将大幅加速,努力追上绿车,逼迫绿车也进行加速行为,以降低不确定性。

案例二:本车初始车位靠前
如下图所示,自我策略(egoism policy)将产生中等距离的交互;礼貌策略(egoism policy)下,本车进行加速,甩开他车,以避免对他车造成影响;而自信策略下(confidence policy)下,本车将大幅减速,对他车进行堵截,逼迫他车停车,以降低不确定性。

案例三:两车车位平行
如下图所示,自我策略(egoism policy)将产生中等距离的交互;礼貌策略(egoism policy)下,本车减速停车,避免对他车产生影响;而自信策略下(confidence policy)下,本车将适当加速,对他车进行堵截,以降低不确定性。
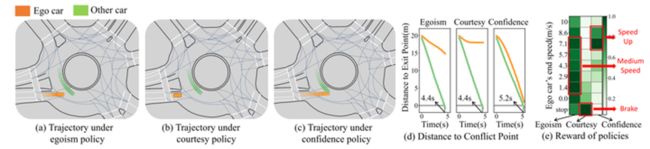
除了以上个体案例外,本方法还进行了219组交互实验,统计了relative distance与running time两个metric,以便得到对三种policy统计级别的理解。如下表所示,egoism policy产生了中等的交互距离与时间;courtesy policy产生了距离更远,更安全的交互,同时也使得交互更加高效;confidence policy的交互距离最近,最危险,同时也更容易产生交通堵塞,导致交互时间变长。

4.“社会兼容型规划”如何辨认出人类的驾驶风格与心理
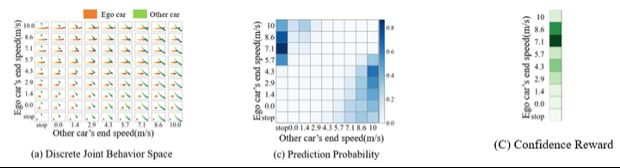
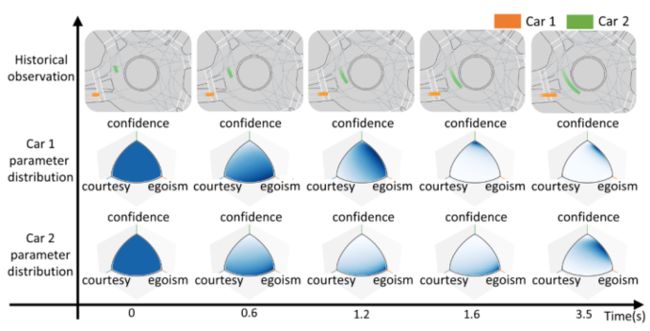
在日常生活中,我们会通过对其他驾驶员过去的驾驶行为,对他的驾驶风格进行推断。基于这个insight,本方法使用Bayesian inference算法,通过对驾驶员历史行为的观察,对“社会兼容”奖励函数中的权重进行推断。如下图所示,随着两车交互不断进行,我们得到了越来越丰富的观察,两辆车的参数估计逐渐收敛,完成了对驾驶风格的辨识。
此外,为得到统计规律,本方法对219组真实人类驾驶数据进行了参数估计,统计了两个metrics,以便对人类的驾驶行为得到更加深入的理解。
Metric 1:驾驶策略切换频率。这个指标用于衡量人类切换驾驶风格的频率。实验结果告诉我们,在大多数情况下,人类驾驶员在一次交互中切换驾驶风格的次数不会超过3次。基于这一观察,当我们在设计自动驾驶的驾驶风格时,我们不应使其过于频繁地切换驾驶风格;同时,在对人类驾驶行为进行预测时,同样不应该期待人类会过于频繁地切换。

Metric2:驾驶策略比重。这个指标用于衡量人类采取三种驾驶频率的比重。实验结果告诉我们,这样的驾驶比重与多种因素有关:
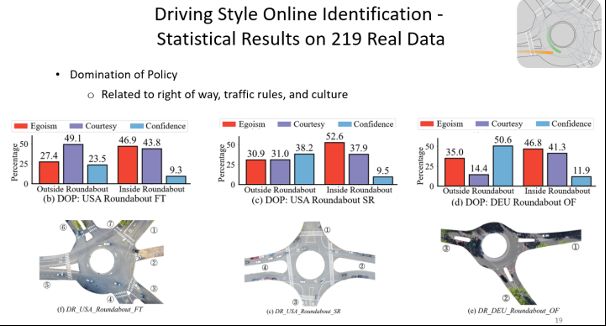
1)路权
当人们拥有不同级别的路权时,驾驶风格是不一样的。如上图(b),环岛内的驾驶员多采用egoism策略,而环岛外的驾驶员多采用courtesy策略
2)交通规则
交通规则同样会产生不一样的驾驶偏好。在上图(b)的环岛中设置了停车标识(stop sign),而上图(c)的环岛中设置了减速标识(yield sign),因此两个场景中环岛外的驾驶员的驾驶比重是不一样的
3)文化
不同国家拥有不一样的文化,会产生不同风格的行为。上图(b)和图(c)的环岛均设置了减速标识(yield sign),但图(b)的环岛位于美国,而图(c)的环岛位于德国,根据实验结果,我们能看出这两个国家的驾驶员风格也是不一样的
5.辨认出人类的驾驶风格后,对未来的轨迹预测有帮助吗
在219组真实人类数据中,辨认出人类的驾驶风格后,我们进一步用我们的“社会兼容规划”策略进行人类的轨迹预测。
如下图所示,相比起传统的仅使用egoism policy的预测方法,基于驾驶风格的行为预测将:对环岛外驾驶员的预测误差(MSE)降低了19%,而对环岛内驾驶员的预测误差(MSE)降低了3%。这样的差异是因为,如上一个问题的实验结果,环岛内的驾驶员大多仅仅采用egoism policy,而环岛外的驾驶员的驾驶风格是相对更加丰富的,因此对驾驶风格的辨识能够有效提升预测精度。

此外,对于courteous和confident driver而言,本论文的预测方法将更大幅度地提升预测精度(60%, 53%)。因此,虽然non-egoism policy相对而言不是那么高频,但一旦遇到了一名礼貌或者一名自信驾驶员,本论文的方法能够极大地提升预测精度。
参考文献
[1] Wang, Letian, Liting Sun, Wei Zhan, Masayoshi Tomizuka. "Socially-compatible behavior design of autonomous vehicles with verification on real human data."IEEE Robotics and Automation Letters and ICRA (2021).
