翻译“SIMD for C++ Developers”
SIMD for c++ developers
最近在学习SIMD的指令,但是并没有找到非常好的中文资料。在网络上偶然看到此文章《SIMD for c++ developers》,对Intel SIMD指令进行了整体介绍,工作之便,以作翻译分享。本人对SIMD尚不熟悉,因此翻译进行的比较缓慢,尚有部分内容并不完全理解,因此本文采用了中英文对照的方式,还请多多指正。
Introduction
…
Introduction to SIMD
…
Programming with SIMD
The main disadvantage of the technology is steep learning curve. It took me couple months to become somewhat familiar with the technology, and a year or so before I could say I’m comfortable using it. I had decades of prior experience programming classic C++, and years of prior experience programming GPUs. Didn’t help. CPU SIMD is very different from both of them.
这项技术的主要难度是陡峭的学习曲线。我花了数月时间入门,大约过了一年才敢说可以流畅地使用它。我有着数十年的c++编程经验,多年的GPU编程经验。然而这些都没有用,CPU的SIMD与这些完全不同。
First it takes time to wrap the head around the concept. That all CPUs are actually vector ones, and every time you’re writing float a = b + c; you’re wasting 75% to 87.5% of CPU time, because it could have added 4 or 8 numbers with slightly different instruction, spending exactly same time.
首先,我们需要时间去理解相关概念。现在所有的CPU实际上都支持向量操作,每次你编写的float a = b + c,你实际浪费了75%-85%的CPU时间。因为你使用一些其他指令在相同的时间同时计算4-8组数字的加法。
Then it takes much more time to get familiar with actual instructions. When I started learning the technology, I can remember few times when I spent hours trying to do something, come up with a solution that barely outperformed scalar version, only to find out later there’s that one special instruction which only takes a couple of them to do what I did in a page of code, improving performance by a factor of magnitude.
然后,我们需要花费更多的时间熟悉指令。在刚开始学习这项技术时,我花费数小时编写的代码发现与标量版本性能相差无几,直到后来使用了一些特殊的指令并仅用了少量代码后,性能得到了数量级的提升,这些事情屡见不鲜。
Another thing, the documentation is not great. I hope I have fixed it to some extent, but still, that official guide is only useful when you already know which intrinsics do you need. Most developers don’t know what modern SIMD is capable of. I’m writing this article hoping to fix it.
另外,文档并不友好。目前官方文档仍然只对熟悉指令的使用者有用,虽然我希望去完善它。但是多数开发者并不知道SIMD的用途。我写这篇文章也是希望可以改善这种情况。
Data Types
Most of the time you should be processing data in registers. Technically, many of these instructions can operate directly on memory, but it’s rarely a good idea to do so. The ideal pattern for SIMD code, load source data to registers, do as much as you can while it’s in registers, then store the results into memory. The best case is when you don’t have a result, or it’s very small value like bool or a single integer, there’re instructions to copy values from SIMD registers to general purpose ones.
多数情况,你应该使用寄存器处理数据。技术上讲,许多指令可以直接操作内存,但这并不是一个好主意。使用SIMD代码工作的理想模式是:加载数据到寄存器,尽可能在寄存器中处理这些数据,然后存回内存。最理想的情况是:不需要返回结果时,或者返回结果是一个很小的数比如bool或者单个integer时,再使用某些指令把数据从SIMD寄存器复制到通用寄存器。
In C++, the registers are exposed as variables of the 6 fundamental types. See the table on the right. In assembly code there’s no difference between registers of the same size, these types are just for C++ type checking.
在C++中,SIMD寄存器包括6种基本类型的变量。如右表格所示。相同大小的寄存器之间在汇编层面没有任何区别,类型仅是为了应付c++的类型检查。
| 16 bytes | 32 bytes | |
|---|---|---|
| 32-bit float | __m128 | __m256 |
| 640bit float | __m128d | __m256d |
| Integers | __m128i | __m256i |
The compiler assigns variables to registers automagically, but remember there’re only 16 registers underneath the compiler. Or just 8 if you’re building a 32-bit binary. If you define too many local variables, and write code with many dependencies preventing compiler from reusing registers, the compiler will evict some variables from registers to RAM on the stack. In some edge cases, this may ruin the performance. Profile your software, and review what the compiler did to your C++ code on the performance critical paths.
编译器自动分配变量到寄存器。但是编译器只能使用16个SIMD寄存器,对于编译32位文件则更是只有8个。如果你定义了过多局部变量,并且代码中之间依赖性较高,导致编译器无法重用寄存器,编译器只好将把部分变量从寄存器迁移到RAM上的栈区。对于一些极限情况,这会导致性能损失。测试软件性能时,请检查编译器如何处理关乎性能的那部分代码。
One caveat about these vector types, compilers define them as a structure or union with arrays inside. Technically you can access individual lanes of the vectors by using these arrays inside, the code compiles and works. The performance is not great, though. Compilers usually implement such code as a roundtrip from register to memory, and then back. Don’t treat SIMD vectors that way, use proper shuffle, insert or extract intrinsics instead.
对于这些向量的类型需要注意:编译器将这些向量定义为一个structure或者union,内部则是数组。技术上,你可以通过访问数组的方式获取向量中某一个lane,代码是可以正常编译并工作的,但是会影响性能。因为这通常会造成数据往返于内存和寄存器之间。因此不要用这种方式使用SIMD向量,使用合适的shuffle、insert或者extract的指令更为合适。
General Purpose Intrinsics
Casting Types
Assembly only knows about 2 vector data types, 16-bytes registers and 32-bytes ones. There’re no separate set of 16/32 byte registers, 16-byte ones are lower halves of the corresponding 32-bytes.
汇编只识别两种向量类型:16字节寄存器和32字节寄存器。16字节寄存器和32字节寄存器不是独立的,16字节寄存器是32字节寄存器的低16字节部分。
But they are different in C++, and there’re intrinsics to re-interpret them to different types. In the table below, rows correspond to source types, and columns represent destination type.
但是在C++中,两者是不同的,因此存在指令用来转换两种类型。如下表,行表示原始数据类型,列表示目标数据类型。
| __m128 | __m128d | __m128i | __m256 | __m256d | __m256i | |
|---|---|---|---|---|---|---|
| __m128 | = | _mm_castps_pd | _mm_castps_si128 | _mm256_castps12 | ||
| __m128d | _mm_castpd_ps | = | _mm_castpd_si128 | _mm256_castpd128_pd256 | ||
| __m128i | _mm_castsi128_ps | _mm_castsi128_pd | = | _mm256_castsi128_si256 | ||
| __m256 | _mm256_castps256_ps128 | = | _mm256_castps_pd | _mm256_castps_si256 | ||
| __m256d | _mm256_castpd256_pd128 | _mm256_castpd_ps | = | _mm256_castpd_si256 | ||
| __m256i | _mm256_castsi256_si128 | _mm256_castsi256_ps | _mm256_castsi256_pd | = |
All these intrinsics compile into no instructions, so they’re practically free performance wise. They don’t change bits in the registers, so 32-bit 1.0f float becomes 0x3f800000 in 32-bit lanes of the destination integer register. When casting 16-byte values into 32 bytes, the upper half is undefined.
所有这些指令不会编译成任何指令,因此不耗费任何性能。这些指令不改变寄存器中任何bit,因此32bit float 1.0f将cast为32bit integer 0x3f800000。当cast 16字节到32字节时,高字节部分是未定义的(undefined)。
Converting Types
There’re also instructions to do proper type conversion. They only support signed 32-bit integer lanes. _mm_cvtepi32_ps converts 4 integer 32-bit lanes into 32-bit floats, _mm_cvtepi32_pd converts first 2 integers into 64-bit floats, _mm256_cvtpd_epi32 converts 4 doubles into 4 integers, setting higher 4 lanes of the output to zero. When converting from floats to integer, these instructions use rounding mode specified in MXCSR control and status register. See _MM_SET_ROUNDING_MODE macro for how to change that mode. That value is a part of thread state, so the OS persists the value across context switches. (That feature may cause hard to find numerical errors when SIMD is used in a thread pool environment, such as OpenMP. For this reason, instead of changing MXCSR I prefer SSE 4.1 rounding intrinsics.)
有一些指令可以执行类型conversion。目前只支持有符号的32bit integer lanes。_mm_cvtepi32_ps convert 4个32bit interger lanes至32bit float。_mm_cvtepi32_pd convert 前两个integers至64bitfloat,_mm256_cvtpd_epi32 convert 4个double至interger,剩余的高4个lanes置为0。当从float convert至integer时,round采用MXCSR或status register中指定的模式。通过_MM_SET_ROUNDING_MODE宏可以修改round模式。That value is a part of thread state, so the OS persists the value across context switches。(这一特性可能导致在线程池环境下很难发现数值错误,比如OpenMP。因此,相对于更换MXCSR我更喜欢使用SSE4.1指令集中的round指令)
There’re other ones with extra ‘t’ in the name which ignore MXCSR and always use truncation towards zero, like _mm_cvttpd_epi32 and _mm_cvttps_epi32.
使用带有额外“t”字符的指令,可以忽略MXCSR,直接使用向下取整的方式,比如_mm_cvttpd_epi32和_mm_cvttps_epi32。
There’re also instructions to convert floats between 32- and 64-bit.
有一些指令可以转换32bit与64bit的floats。
Memory Access
There’re many ways to load data from memory into registers.
以下指令可以将数据从内存load到寄存器的。
-
All types support regular loads, like
_mm_load_si128or_mm256_load_ps. They require source address to be aligned by 16 or 32 bytes. They may crash otherwise but it’s not guaranteed, depends on compiler settings. -
支持所有类型的常规load,比如
_mm_load_si128和_mm256_load_ps。但是这些指令要求原始数据的地址是16bit或32bit aligned的,否则可能会因为编译器设置造成崩溃。 -
All types support unaligned loads, like
_mm_loadu_si128or_mm256_loadu_ps. They’re fine with unaligned pointers but aligned loads are faster. -
所有数据类型支持unaligned load,比如
_mm_loadu_si128和_mm256_loadu_ps。可以正常加载unaligned指针,但是使用aligned loads比unaligned更快。 -
__m128and__m128dtypes support a few extra. They support single-lane loads, to load just the first lane and set the rest of them to0.0, they are_mm_load_ssand_mm_load_sd. They support intrinsics to load them from memory in reverse order (requires aligned source address). -
__m128和__m128d支持一些额外的load方式。_mm_load_ss和_mm_load_sd支持single-lane load,即只load第一个lane,并设置其他lanes为0.0。对于aligned的数据,一些指令支持倒序load。 -
In AVX,
__m128,__m256and__m256dhave broadcast load instructions, to load single float or double value from RAM into all lanes of the destination variable. Also__m256and__m256dtypes have broadcast loads which read 16 bytes from RAM and duplicate the value in 2 halves of the destination register. -
在AVX指令集中有处理
__m128、__m256、__m256d的broadcast load指令,可以从内存中load一个float或者double到目标的所有lanes中。有些指令可以从内存中读取16字节到__m256或__m256d,然后复制到寄存器的另一半。 -
AVX 1 introduced masked load instructions, they load some lanes and zero out others.
-
AVX1指令集中引入了masked load 指令,可以只load一部分lanes,其他的置为0。
-
AVX 2 introduced gather load instruction, like
_mm_i32gather_ps, they take a base pointer, integer register with offsets, and also integer value to scale the offsets. Handy at times, unfortunately rather slow. -
AVX2指令集中加入了gather load指令,如
_mm_i32gather_ps,可以load原始指针、带偏移的interger、带缩放的interger。方便的同时,比较慢。 -
Finally, in many cases you don’t need to do anything special to load values. If your source data is aligned, you can just write code like
__m128i value = *pointer; and it’ll compile into an equivalent of regular load. -
最后,在很多情况,你在load时不需要做任何特殊的操作。如果你的数据是aligned,你可以直接写做
__m128i value = *pointer;编译器会将其编译为常规的加载方式。
Similarly, there’s many ways to store stuff: aligned, unaligned, single-lane, masked in AVX 1.
同样,在AVX1指令集中,针对aligned、unaligned、single-lane、masked有多种方式store。
Couple general notes on RAM access.
- On modern PCs, RAM delivers at least 8 bytes per load. If you have dual-channel RAM, it delivers 16 bytes. This makes it much faster to access memory in aligned 16- or 32-bytes blocks. If you look at the source code of a modern version of memcpy or memmove library routine, you’ll usually find a manually vectorized version which uses SSE 2 instructions to copy these bytes around. Similarly, when you need something transposed, it’s often much faster to load continuously in blocks of 16 or 32 bytes, then transpose in registers with shuffle instructions.
现代计算机,RAM每次load至少load 8字节。对于双通道内存,每次load 16字节。因此读取aligned的16或者32字节块是很快的。如果你查看memcpy或memmove函数在最新的源代码,你可以看到使用SSE2指令使用向量化指令复制字节。同样当你transpose时,load连续的16或32字节块到寄存器中,然后使用shuffle指令通常更快。
- Many instructions support memory source for one of the operands. When compiling for SSE-only targets, this requires aligned loads. When compiling for AVX targets, this works for both aligned and unaligned loads. Code like
_mm_add_ps( v, _mm_loadu_ps( ptr ) )only merges the load when compiling for AVX, while_mm_add_ps( v, _mm_load_ps( ptr ) )merges for all targets because the load is aligned (but might crash in runtime if the passed address is not actually amultiple of 16 bytes).
很多指令支持memory source for one of the operands。当只使用SSE指令集编译时,要求aligned load。当使用AVX指令集编译时,aligned或unaligned load均可。_mm_add_ps( v, _mm_loadu_ps( ptr ) )只当使用AVX指令集编译时,add才能运行。_mm_add_ps( v, _mm_load_ps( ptr ) )对于两个指令集add都可以运行是因为是数据是aligned的(但是如果运行时传入的并不是16字节aligned的,则会发生崩溃)。
- Most single-lane loads/store can only use lowest lane of destination/source register. If you’re implementing a reduction like sum or average, try to do so you have result in the first lane. The exceptions are
_mm256_insertf128_ps,_mm256_insertf128_pd,_mm256_inserti128_si256AVX instructions, they can load 16-byte vectors into higher half of the destination register with little to no performance penalty compared to regular 16-byte load.
多数single-lane的loads或store只支持操作寄存器的最低lane。如果你想要实现reduction比如sum或average,将结果存放在第一个lane。AVX指令 _mm256_insertf128_ps, _mm256_insertf128_pd, _mm256_inserti128_si256例外,这些指令load 16字节的向量到寄存器的高一半部分,而且相对常规的16字节load相比几乎没有性能损失。
- There’re instructions to load or store bypassing CPU caches,
_mm[256]_stream_something. Can be useful for cases like video processing, when you know you’re writing stuff that will only be loaded much later, after you’ve processed the complete frame, and probably by another CPU core (L1 and L2 caches are per-core, only L3 is shared).
有一些指令如_mm[256]_stream_something可以绕过CPU缓存 load store数据。在视频处理时会有用。when you know you’re writing stuff that will only be loaded much later, after you’ve processed the complete frame, and probably by another CPU core (L1 and L2 caches are per-core, only L3 is shared).
- Most current CPUs can do twice as many loads per cycle, compared to stores.
多数现代CPU每个cycle load速度是store的两倍。
Initializing Vector Registers
Initializing with Zeros
All the vector types have intrinsics like _mm_setzero_ps and _mm256_setzero_si256 to initialize a register with all zeros. It compiles into code like xorps xmm0, xmm0, xmm0. Zero initialization is very efficient because that XOR instruction has no dependencies, the CPU just renames a new register.(The hardware has much more than 16, it’s just 16 names in assembly. The hardware has thousands of them, the pipeline is deep and filled with in-flight instructions who need different versions of same logical registers.)
所有类型向量都有对应的初始化为0的指令,比如_mm_setzero_ps和_mm256_setzero_si256将寄存器全部初始化为0。代码编写的形式如xorps xmm0, xmm0, xmm0。初始化为0是很快的因为不依赖于XOR指令,CPU只需要rename一个新的寄存器(硬件超过16个寄存器,只不过有16个名称。硬件实际上有上千个,流水线很深,包括很多动态指令,这些指令需要多个版本的相同逻辑的寄存器)。
Initializing with Values
CPUs can’t initialize registers with constants apart from 0, but compilers pretend they can, and expose intrinsics like _mm[256]_set_something to initialize lanes with different values, and _mm[256]_set1_something to initialize all lanes with the same value. If the arguments are compile time constants, they usually compile into read-only data in the compiled binary. Compilers emit the complete 16/32 bytes value, and they make sure it’s aligned. if the arguments aren’t known at compile time, the compilers will do something else reasonable, e.g. if the register is mostly 0 and you only setting one lane they’ll probably emit _mm_insert_something instruction. If the values come from variables, the compiler may emit shuffles, or scalar stores followed by vector load.
CPU不能将寄存器初始化除了0以外的常量,但是编译器假装CPU可以。_mm[256]_set_something可以将lanes初始化不同的值,_mm[256]_set1_something可以初始化全部lanes为一个值。如果变量是编译期常量,该变量将编译为二进制文件的read-only data区域。编译器编译出完整的16/32bytes数值,因此保证数据是aligned。如果变量在编译期是未知的,编译器会做一些合理性动作,比如寄存器只有一个lane不是0,编译器会使用使用_mm_insert_something 指令。如果值从变量中拷贝而来,编译器会在load之后使用shuffles、scalar stores等。
For all their _mm[256]_set_something intrinsics, Intel screwed up the order. To make a register with integer values [ 1, 2, 3, 4 ], you have to write either _mm_set_epi32( 4, 3, 2, 1 ) or _mm_setr_epi32( 1, 2, 3, 4 )。
对于所有_mm[256]_set_something指令,Intel有一些特殊要求。当往寄存器中存入[ 1, 2, 3, 4 ]时,你需要使用_mm_set_epi32( 4, 3, 2, 1 )或者_mm_setr_epi32( 1, 2, 3, 4 )。
Bitwise Instructions
Both floats and integers have a fairly complete set of bitwise instructions. All of them have AND, OR, XOR, and ANDNOT instructions. If you need bitwise NOT, the fastest way is probably XOR with all ones. Example for 16-byte values:
floats和interger都有几乎完整的bitwise指令,包括AND,OR,XOR和ANDNOT。如果你需要bitwise NOT,最快的方式是与全1做XOR,比如对于16字节的数据:
__m128i bitwiseNot( __m128i x ) {
const __m128i zero = _mm_setzero_si128();
const __m128i one = _mm_cmpeq_epi32( zero, zero );
return _mm_xor_si128( x, one );
}
Whenever you need a register value with all bits set to 1, it’s often a good idea to do what I did here, setzero then compare zeroes with zeroes.
当你需要全1的寄存器,最好的方式如上所示,setzero然后0与0做比较。
Floating Point Instructions
Arithmetic
Most of them are available in all-lane versions, and single lane version which only compute single lane result, and copy the rest of the lanes from the first arguments.
指令集支持针对all-lane的多数arithmetic,也有只计算single-lane的指令,这些指令只计算一个lane然后从第一个参数复制其他lanes。
Traditional
All 4 basic operations are implemented, add, subtract, multiply, divide. Square root instruction is also there, even for 64-bit floats.
所有的四则运算都有对应实现,包括add、subtract、multiply、divide。square root指令也是支持的,甚至对于64-bit floats的所有计算。
Unorthodox
The CPU has minimum and maximum instructions. More often than not, modern compilers compile standard library functions std::min / std::max into _mm_min_ss / _mm_max_sd.
CPU有minimum和maximum指令。而且很多现代编译器会将标准库的std::min / std::max转化为_mm_min_ss / _mm_max_sd
For 32-bit floats, CPUs implement faster approximate versions of 1 x \frac{1}{x} x1and 1 x \frac{1}{\sqrt{x}} x1They are _mm_rcp_ps and _mm_rsqrt_ps, respectively.(I use them very rarely. On old CPUs like Pentium 3, it took 56 CPU cycles to compute non-approximated square root, and 48 cycles to divide vectors. Faster approximations made a lot of sense back then. However, modern CPUs like Skylake or Ryzen do that in 12-14 cycles, little profit from these faster approximations.) For both of them the documentation says “maximum relative error for this approximation is less than 1.5*2^-12”, translates to 3.6621 × 10−4 maximum relative error.
对32bit float, CPU对于 1 x \frac{1}{x} x1和 1 x \frac{1}{\sqrt{x}} x1有近似的快速实现,分别对应_mm_rcp_ps与_mm_rsqrt_ps指令(我很少使用,在老的CPU比如Pentium 3中,无近似的计算square root需要56个cycles,divide是48个cycle,在当时,更快的逼近法很有意义,然而现代CPU比如Skylake或者Ryzen使用无近似计算需要12-14cycles,因此从这些更快的近似中获益甚微)。文档中提到:“两个指令近似的最大相对误差不超过1.5*2^-12”,换算为3.6621 × 10−4最大相对误差。
SSE 3 has horizontal add and subtract instructions, like _mm_hadd_ps, which takes two registers with [a, b, c, d] and [e, f, g, h] and returns [a+b, c+d, e+f, g+h]. The performance is not great, though.
SSE3指令集中包含有水平方向的add和subtract指令,比如_mm_hadd_ps。加载[a, b, c, d]和[e, f, g, h],返回[a+b, c+d, e+f, g+h]。但是性能一般。
SSE 3 also has a couple of instructions which alternatively add and subtract values. _mm_addsub_pstakes two registers with [a, b, c, d] and [e, f, g, h] and returns [a-e, b+f, c-g, d+h]. _mm_addsub_pd does similar thing for double lanes. Handy for multiplying complex numbers and other things.
SSE3指令集中一对指令分别实现了交替add和subtract。_mm_addsub_ps加载[a, b, c, d]和[e, f, g, h] 返回[a-e, b+f, c-g, d+h]。_mm_addsub_pd对两个double lanes做相似操作。这对于复数的乘法等操作十分方便。
SSE 4.1 includes dot product instruction, which take 2 vector registers and also 8-bit constant. It uses higher 4 bits of the constant to compute dot product of some lanes of the inputs, then lower 4 bits of the constant to broadcast the result.
SSE4.1指令集中包含了dot product指令,加载2个向量寄存器和一个8bit的常量。使用这个常量的高4bits决定计算哪些lanes参与dot product,使用这个常量的低4bit决定broadcast(具体使用如下)。
For instance, when SSE 4.1 is enabled, XMVector3Dot library function compiles into single instruction, this one: _mm_dp_ps( a, b, 0b01111111 ) The bits in the constant mean “compute dot product of the first 3 lanes ignoring what’s in the highest ones, and broadcast the resulting scalar value into all 4 lanes of the output register”. The lanes for which the store bit is zero will be set to 0.0f.
比如,当使用SSE4.1指令集时,XMVector3Dot库将上述运算编译至指令_mm_dp_ps( a, b, 0b01111111 ),常量参数表示:计算除了最高位lane外的其他三个lanes的dot product,然后将计算得到的标量结果broadcast到输出寄存器的所有4个lanes。常量中低四位被置为0的bit其对应的lanes将被置为0.0f。
SSE 4.1 has introduced rounding instructions for both sizes of floats. For 32-bit floats, the all-lanes version is exposed in C++ as _mm_round_ps, _mm_ceil_ps, and _mm_floor_ps intrinsics. For AVX, Intel neglected to implement proper ceil/round intrinsics, they only exposed _mm256_round_ps and _mm256_round_pd which take extra integer constant specifying rounding mode. Use _MM_FROUND_NINT constant to round to nearest integer(More specifically, processors do bankers’ rounding: when the fraction is exactly 0.5, the output will be nearest even number. This way 0.5 is rounded to 0, while 1.5 becomes 2), _MM_FROUND_FLOOR to round towards negative infinity, _MM_FROUND_CEIL to round towards positive infinity, or _MM_FROUND_TRUNC to round towards zero.
SSE4.1指令集为32/64bits的floats引入了rounding指令。c++中处理32bit floats、all-lanes版本的指令为_mm_round_ps、_mm_ceil_ps和_mm_floor_ps。在AVX中,Intel不区分ceil/round指令,只有_mm256_round_ps和_mm256_round_pd,使用一个interger常量指定rounding模式。_MM_FROUND_NINT表示round到最近的interger(更具体地说,处理器使用branker rounding模式, 当小数部分恰好是0.5时,结果更靠近偶数,使用这种rounding,0.5将round为0,1.5将round为2),_MM_FROUND_FLOOR表示round到负无穷. _MM_FROUND_CEIL表示round到正无穷,_MM_FROUND_TRUNC表示round到0。
Missing
Unlike NEON, there’s no SSE instructions for unary minus or absolute value. The fastest way is bitwise tricks, specifically _mm_xor_ps( x, _mm_set1_ps( -0.0f ) ) for unary minus, _mm_andnot_ps( _mm_set1_ps( -0.0f ), x ) for absolute value. The reason these tricks work, -0.0f float value only has the sign bit set, the rest of the bits are 0, so _mm_xor_ps flips the sign and _mm_andnot_ps clears the sign bit making the value non-negative.
与NEON不同,SSE指令集中没有unary minus或absolute value对应的指令。最快的方法是使用bitwise,_mm_xor_ps( x, _mm_set1_ps( -0.0f ) )表示unary minus。_mm_andnot_ps( _mm_set1_ps( -0.0f ), x ) 表示absolute value。该方法的奥妙在于:-0.0f float只把符号位设为1,其他bits设为0,因此_mm_xor_ps反转了sign,_mm_andnot_ps将符号位置零使结果非负。
There’s no logarithm nor exponent, and no trigonometry either. Intel’s documentation says otherwise, because Intel were writing their documentation for their C++ compiler, which implements them in its standard library. You can fall back to scalar code, or better search the web for the implementation. It’s not terribly complex, e.g. trigonometric functions are usually implemented as high-degree minmax polynomial approximation. For single-precision floats you can use XMVectorSin/XMVectorCos/etc. from DirectXMath, for FP64 use the coefficients from GeometricTools.
没有实现logarithm、exponent和trigonometry的指令。Intel文档中有是因为文档本身是为Intel自家编译器编写的,因此Intel在自己的c++编译器的标准库中集成了这些指令。你可以使用标量代码,或者在网络上找到更好的实现。这并不复杂,比如trigonometric函数经常使用高阶极大极小多项式逼近来实现。对于单精度floats可以使用DirectXMath中的XMVectorSin/XMVectorCos。对于FP64可以使用中的GeometricTools[https://github.com/davideberly/GeometricTools/blob/GTE-version-5.9/GTE/Mathematics/SinEstimate.h]。
Comparisons
There’re all-lanes versions of equality comparison and the rest of them, <, >, ≤, ≥, ≠. These versions return another float register, that’s either all zeros 0.0f, or all ones. A float with all ones is a NAN.
对于<, >, ≤, ≥, ≠等equality comparison,有处理all-lanes的指令。结果返回另一个数值为全零0.0f或者全1的float向量寄存器。全1的float表示NAN。
You can send the result from SIMD to a general-purpose CPU register with _mm_movemask_ps, _mm_movemask_pd or the corresponding AVX 1 equivalents. These instructions gather most significant bits of each float/double lane (that bit happen to be the sign bit, by the way), pack these bits into a scalar, and copy to a general-purpose CPU register. The following code prints 15:
你可以将_mm_movemask_ps、_mm_movemask_pd或者AVX1指令集中近似的指令将结果从向量寄存器传递给通用寄存器。这些指令gather每一个float/double lane的最高有效位(通常是符号位),将结果传递给一个通用寄存器。如下代码将输出15:
const __m128 zero = _mm_setzero_ps();
const __m128 eq = _mm_cmpeq_ps( zero, zero );
const int mask = _mm_movemask_ps( eq );
printf( "%i\n", mask );
The 0 == 0 comparison is true for all 4 lanes of __m128, the eq variable has all 128 bits set to 1, then _mm_movemask_ps gathers and returns sign bits of all 4 float lanes. 0b1111 becomes 15 in decimal.
对于__m128的所有四个lanes comparison 0 == 0的结果是true,变量eq的所有128bits均为1,_mm_movemask_psgather 4个float lanes的符号位,结果为0b1111,十进制表示为15。
Another thing you can do with comparison results, use them as arguments to bitwise instructions to combine lanes somehow. Or pass them into blendv_something. Or cast to integer vectors and do something else entirely.
另一个使用comparison结果的情景是,将结果作为bitwise指令的参数来combine lanes,或传给blendv_something,或者cast为interger等等。
Also, both 32- and 64-bit floats have instructions to compare just the lowest lanes of 2 registers, and return the comparison result as bits in the flags register accessible to general-purpose instructions:
一些指令可以只compare 32/64bit lanes寄存器的lowest lane,将comparison结果以flags register返回给通用寄存器。
// Compare the first lane for `x > 0.0f`
bool isFirstLanePositive( __m128 x )
{
return (bool)_mm_comigt_ss( x, _mm_setzero_ps() );
}
For AVX, Intel only specified two comparison intrinsics, _mm256_cmp_ps and _mm256_cmp_pd. To compare 32-byte vectors, you need to supply an integer constant for the comparison predicate, such as _CMP_EQ_OQ or other from that header. See this stackoverflow answer for more info on predicates.
对于AVX,Intel只提供了两种comparison指令,_mm256_cmp_ps和_mm256_cmp_pd。为了compare 32字节的vectors,你需要设置一个integer常量作为comparison谓词。比如_CMP_EQ_OQ等。可以在stackoverflow找到更多相关的谓词。
Shuffles
These are instructions which reorder lanes. They are probably the most complicated topic about the subject. Here’s an example code which transposes a 4x4 matrix. To me it looks a bit scary, despite I understand pretty well what that code does.
以下介绍reorder lanes的指令。这可能是本文最复杂的主题。点击示例代码链接,该段代码用于transpose一个4×4矩阵。可能有些可怕,不过我很清楚这段代码的作用。
We’ll start with shuffle instructions processing 32-bit float lanes in 16-byte registers. On the images below, the left boxes represent what’s on input, the right one what’s on output. The A B C D values are lanes in these registers, the first one is on top.
我们使用16字节寄存器处理32bit float lanes的例子来介绍shuffle指令。如下图,左边空表示输入,右边表示输出。A B C D表示寄存器中的lanes。
Fixed Function Shuffles
_mm_movehl_ps |
SSE 1 | Move the upper 2 single-precision (32-bit) floating-point elements from “b” to the lower 2 elements of “dst”, and copy the upper 2 elements from “a” to the upper 2 elements of “dst”. | 将“b”中高两个32bit float复制到“dst”的低两个lanes,将“a”的高两个32bit float复制到“dst”的高两个lanes |  |
_mm_movelh_ps |
SSE 1 | Move the lower 2 single-precision (32-bit) floating-point elements from “b” to the upper 2 elements of “dst”, and copy the lower 2 elements from “a” to the lower 2 elements of “dst”. | 将“b”中低两个32bit float复制到“dst”的高两个lanes,将“a”的低两个32bit float复制到“dst”的低两个lanes | 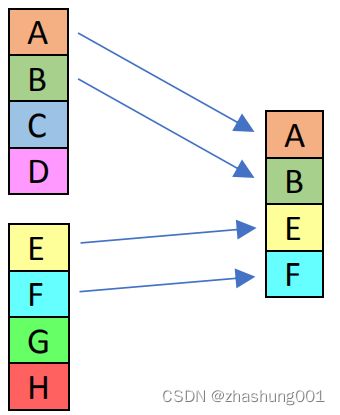 |
_mm_unpacklo_ps |
SSE 1 | Unpack and interleave single-precision (32-bit) floating-point elements from the low half of “a” and “b”, and store the results in"dst". | Unpack并interleave“a”和“b”的低一半32bit lanes,然后存储到dst中 | 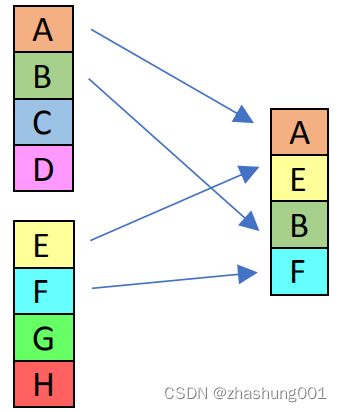 |
_mm_unpackhi_ps |
SSE 1 | Unpack and interleave single-precision (32-bit) floating-point elements from the high half “a” and “b”, and store the results in “dst”. | Unpack并interleave“a”和“b”的高一半32bit lanes,然后存储到dst中 | 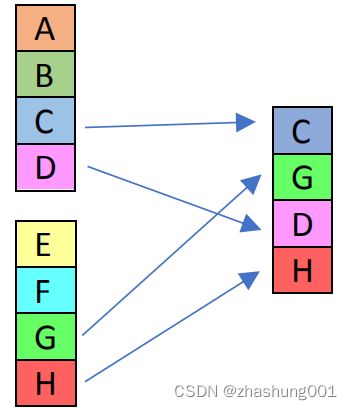 |
_mm_movehdup_ps |
SSE 3 | Duplicate odd-indexed single-precision (32-bit) floating-point elements from “a”, and store the results in “dst”. | deplicate “a”中的奇数坐标的32bit lanes至“dst” |  |
_mm_moveldup_ps |
SSE 3 | Duplicate even-indexed single-precision (32-bit) floating-point elements from “a”, and store the results in “dst”. | deplicate “a”中的偶数坐标的32bit lanes至“dst” | 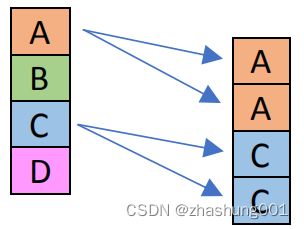 |
_mm_broadcastss_ps |
AVX 2 | Broadcast the low single-precision (32-bit) floating-point element from “a” to all elements of “dst”. | broadcast最低32bit float至“dst” |  |
Variable Compile Time Shuffles
These instructions include the shuffle constant. This means you can’t change that constant dynamically, it has to be a compile-time constant, like C++ constexpr or a template argument. The following C++ code fails to compile:
这些shuffle指令包含一个常量参数。这意味着你无法动态的改变该常量,它是一个编译期常量,类似c++ constexpr或者template参数。以下C++代码将无法完成编译。
const __m128 zero = _mm_setzero_ps();
return _mm_shuffle_ps( zero, zero, rand() );
VC++ says “error C2057: expected constant expression”.
VC++提示“error C2057: expected constant expression”。
In the pictures below, blue arrows show what has been selected by the control value used for the illustration. Dashed gray arrows show what could have been selected by different control constant.
在下图中,使用蓝色箭头表示使用当前的常量参数的结果。灰色虚线箭头显示选择其他可能的常量参数时的结果。
_mm_shuffle_ps |
SSE 1 | Shuffle single-precision (32-bit) floating-point elements. On the image on the right, the control constant was 10 01 10 00 = 0x98. The first 2 lanes come from the first argument, second 2 lanes from the second one. If you want to permute a single vector, pass it into both arguments. | shuffle 32bit floats。在右侧图像中,负责控制的常量是10 01 10 00 = 0x98。该常量表示前两个lanes来自第一个参数,后面两个lanes来自第二个参数,如果你想premute一个向量,则将这个向量传给全部两个参数 | 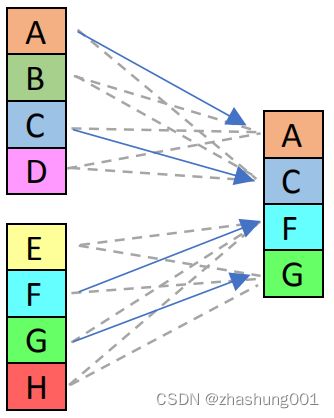 |
_mm_blend_ps |
SSE 4.1 | Blend packed single-precision (32-bit) floating-point elements from “a” and “b” using control mask. On the illustration on the right, the control was 1, it’s 0b0001 in binary, so only the first lane was taken from the second argument. | 使用控制码blend a和b两个32bit floats。如右侧所示,控制码为1时,二进制下为0b0001,表示只有输出结果的第一个lane来自第二个参数。 | 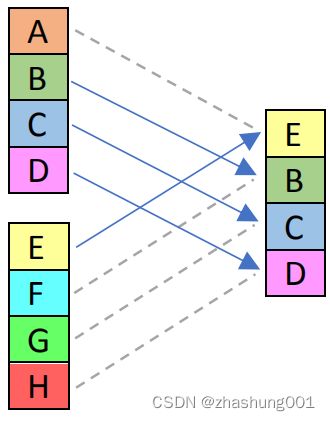 |
_mm_insert_ps |
SSE 4.1 | Insert single float lane, and optionally zero out some lanes.The image on the right shows what happens when the control value is 0b01100001 = 0x61: the source index is 1. that’s why the F value is being inserted, the destination index is 2 so that value is inserted into lane #2, and the lowest 4 bits are 0001 so the output lane #0 is zeroedout.You can abuse this instruction to selectively zero out some lanes without inserting: pass same register in both arguments, and e.g. 0b00001001 control value to zero out lanes #0 and #3.The equivalent is _mm_blend_ps with _mm_setzero_ps second argument, but that’s 2 instructions instead of one. |
insert一个32bit float lane,并将部分lanes置零。右边的图像显示了当控制码是0b01100001 = 0x61时的结果:控制码中source index(控制码中的前两个bit)是1因此F被插入,destination index(控制码中的第3、4bit)是2因此插入至lane #2,控制码剩下的低位4个bit是0001,因此输出的lane#0被置零。你可以使用这个指令将输出结果的部分lanes置零而不插入:将同一个寄存器传给两个参数,设置控制码为0b00001001则将输出lanes的#0和#3置零。这等同于使用:_mm_blend_ps,其中第二个参数设为_mm_setzero_ps。 |
 |
mm_permute_ps |
AVX 1 | An equivalent of _mm_shuffle_ps with the same value in both arguments. Machine code of _mm_shuffle_ps is 1 byte shorter. |
在同输入下与_mm_shuffle_ps一致的,只不过_mm_shuffle_ps的控制码短一个字节 |
I’m too lazy to draw similar block diagrams for __m128d, __m256, and __m256d shuffles. Fortunately, Intel was lazy as well. The 64-bit float versions are very similar to 32-bit floats. The shuffle constants have only half of the bits for 64-bit floats, the idea is the same.
__m128d, __m256和 __m256d 对应的shuffles是相似的。针对64bit float和32bit float的shuffles是十分相似的。对于64bit float shuffle的控制常量参数只需要一半。
As for the 32-byte AVX versions, the corresponding AVX instructions only shuffle/permute within 16-bit halves of the register. Here’s from documentation of _mm256_shuffle_ps: Shuffle single-precision (32-bit) floating-point elements in “a” within 128-bit lanes.
对于AVX指令集中32byte的shuffles,对应的AVX指令只能shuffle/permute within 16-bit halves of the register。_mm256_shuffle_ps文档中写道:“a”中的一个32bit float只能在128bit lanes中shuffle。
However, there’re also some new AVX2 shuffle instruction which can cross 16-byte lanes.
然而AVX2指令集中的的shuffle指令支持在全部32byte lanes之间shuffle。
_mm256_broadcastss_ps broadcasts the lowest lane into all 8 destination ones. Same applies to _mm256_broadcastsd_pd, it broadcasts a 64-bit float into all laned of the output.
_mm256_broadcastss_ps broadcast最低lane到全部8个lanes。_mm256_broadcastsd_pd类似,broadcast 64bit float到全部lanes。
_mm256_permute2f128_ps, _mm256_permute2f128_pd, _mm256_permute2x128_si256 shuffle 16-byte lanes from two 32-byte registers, it can also selectively zero out 16-byte lanes.
_mm256_permute2f128_ps, _mm256_permute2f128_pd, _mm256_permute2x128_si256 shuffle两个32字节寄存器的16字节 lanes,也可以选择性的将结果的16字节lanes置零。
_mm256_permute4x64_pd and _mm256_permute4x64_epi64 permute 8-byte lanes within 32-byte registers.
_mm256_permute4x64_pd and _mm256_permute4x64_epi64 permute一个32字节寄存器的所有8字节lanes。
Variable Run Time Shuffles
SSE 4.1 introduced _mm_blendv_ps instruction. It takes 3 arguments, uses sign bit of the mask to select lanes from A or B.
SSE4.1指令集中引入了_mm_blendv_ps 指令。它有三个参数,根据mask中的各lanes的符号位从A或者B中的lanes选择。
No version of SSE has float shuffling instructions controllable in runtime. The closest one is _mm_shuffle_epi8 from SSSE3, see the corresponding section under integer instructions. If you really need that, you can cast registers to integer type, use _mm_shuffle_epi8, then cast back(But beware of bypass delays between integer and floating-point domains. On some old CPUs the latency can be up to 2 cycles. For more info, see section 13.6 “Using vector instructions with other types of data than they are intended for” of “Optimizing subroutines in assembly language” article.).
在SSE指令集中没有运行时的float shuffing指令。比较接近的是SSSE3中的_mm_shuffle_epi8,见下面介绍integer指令的章节。如果你确实需要,你可以先cast到integer,使用_mm_shuffle_epi8再转换回来(需要注意转换integer与float之间的bypass delays。在一些老CPU里面需要2个cycles。更多信息,请查看 “Optimizing subroutines in assembly language”的13.6节“Using vector instructions with other types of data than they are intended for”)。
AVX 1 finally introduced one, _mm_permutevar_ps. It takes 2 arguments, float register with source values, and integer vector register with source indices. It treats integer register as 32-bit lanes, uses lower 2 bits of each integer lane to select source value from the float input vector.
在AVX1中引入了_mm_permutevar_ps,该函数需要两个参数,float寄存器表示数据的数值,integer向量寄存器表示数据的索引。这些interger寄存器是32bit lanes的,使用每个32bit integer lane的lower 2 bit来表示从float向量的哪个value选择。
_mm256_permutevar8x32_ps from AVX 2 can move data across the complete 32-byte register.
AVX2中的_mm256_permutevar8x32_ps可以move数据跨越寄存器全部32字节。
Fused Multiply-Add
When processors vendors brag about how many FLOPs they can do per cycle, almost universally, they count FLOPs of their FMA instructions.
当处理器供应商吹牛每cycle多少FLOPs时,多数情况,他们使用FMA指令计算FLOPs。
FMA instructions take 3 arguments, each being either 32- or 64-bit floating point numbers, a, b and c, and compute ( a ⋅ b ) + c ( a · b ) + c (a⋅b)+c. For marketing reasons, that single operation counts as 2 FLOPs.
FMA指令需要3个参数a、b、c,每一个参数是32或64bit的float,然后计算 ( a ⋅ b ) + c ( a · b ) + c (a⋅b)+c。因为市场原因,这一个操作会被记为2FLOIPs。
Modern CPUs implement 8-wide FMA for 32-bit floats, _mm256_fmadd_ps intrinsic in C++, and 4-wide FMA for 64-bit floats, _mm256_fmadd_pd intrinsics. There’re versions which subtract instead of adding, flip sign of the product before adding. There’re even versions which alternately add or subtract, computing ( a ⋅ b ) + c ( a · b ) + c (a⋅b)+c for even lanes ( a ⋅ b ) − c ( a · b ) − c (a⋅b)−c for odd ones, or doing the opposite. It was probably added for complex numbers multiplication.
现代CPU添加_mm256_fmadd_ps指令实现32bit float的8-wide FMA,_mm256_fmadd_pd指令实现64bit floats的4-wide FMA。另外一些指令在add之前,flip乘法结果的符号位,即表示subtract。有的指令在even lanes计算 ( a ⋅ b ) + c ( a · b ) + c (a⋅b)+c,在odd lanes计算 ( a ⋅ b ) − c ( a · b ) − c (a⋅b)−c,或者相反。这大概是为了复数multiplication添加的。
There’re versions twice as narrow operating on 16-byte registers, 4-wide 32-bit floats FMA, and 2-wide 64-bit floats FMA.
有一些指令可以用在16字节寄存器,如针对4wide 32bit floats 或2wide 64bit floats的FMA。
These instructions process the same SIMD registers, __m128, __m128d, __m256 or __m256d C++ types.Besides performance, FMA is also more precise. These instructions only round the value once, after they have computed both the product and the sum. The intermediate value has twice as many bits.
这些指令处理同一个SIMD寄存器不区分数据类型,对于C++来说__m128、__m128d、__m256、__m256d类型都是一样的。除了性能优秀,FMA计算同样精确。这些指令只在计算为product和sum之后取一次round,对于中间计算值的计算通常使用两倍bit。
The support for these instructions is wide but not universal. Both Intel and AMD support the compatible version of FMA, called FMA 3, in their CPUs released since 2012-2013. See hardware support section for more info.
对于这些FMA指令的支持是很广的但并不普及。从2012-2013年起,Intel和AMD都支持兼容版本的FMA,称为FMA3。请参阅硬件支持部分获得更多信息。
Another caveat, the latency of FMA is not great, 4-5 CPU cycles on modern CPUs. If you’re computing dot product or similar, have an inner loop which updates the accumulator, the loop will throttle to 4-5 cycles per iteration due to data dependency chain. To resolve, unroll the loop by a small factor like 4, use 4 independent accumulators, and sum them after the loop. This way each iteration of the loop handles 4 vectors independently, and the code should saturate the throughput instead of stalling on latency. See this stackoverflow answer for the sample code which computes dot product of two FP32 vectors.
另外警告,FMA的latency不佳,现代CPU需要4-5个cycles。如果你是计算dot product时,需要循环更新accumulator,由于data dependency chain,循坏的每次迭代将增加到4-5个cycles。为了解决这个问题,使用一个小的因子比如4展开循环,使用4个单独的accumulators,在循环完之后求和。这样,每次迭代处理4个vector,这样的代码可以使throughput饱和而不是因为latency而停滞。参照stackoverflow中计算两个FP32 float的product的回答中的代码样例。
Interger Instructions
Arithmetic
Traditional
Additions and subtractions are totally fine and do what you would expect, e.g. _mm_add_epi32 adds 32-bit lanes of two integer registers.
addition和subtractions如你所愿是完全没有问题的。比如_mm_add_epi32使两个寄存器的32bit lanes相加。
Moreover, for 8 and 16 bits, there’re saturated versions of them, which don’t overflow but instead stick to minimum or maximum values. For example, _mm_adds_epi8( _mm_set1_epi8( 100 ), _mm_set1_epi8( 100 ) ) will return a vector with all 8-bit lanes set to +127, because the sum is 200 but maximum value for signed bytes is +127. Here’s more in-depth articleon saturation arithmetic.
进一步,指令集支持对于8、16bit integers的saturated的运算,即不会发生溢出而是固定在最大或最小值。比如,_mm_adds_epi8( _mm_set1_epi8( 100 ), _mm_set1_epi8( 100 ) )将返回一个全部8bit lanes为+127的向量,因为虽然和是200但是对于一个8bit有符号字节的最大值是+127,这里提供更多关于saturation计算的文章 。
There’s no integer divide instruction. Intel has integer divide implemented in the standard library of their proprietary compiler. If you’re dividing by a compile-time constant that’s the same for all lanes, you can write a function which divides same sized scalar by that constant, compile with https://godbolt.org/ and port to SIMD. For example, here’s what it compiled when asked to divide uint16_t scalar by 11, and here’s how to translate that assembly into SIMD intrinsics:
没有integer divide指令。Intel在自己编译器的标准库中有integer divide的实现。如果对所有lanes divide一个编译期常量。你可以自己写一个函数,divide与单个lane大小的常量,使用https://godbolt.org/编译,导出到SIMD。例如,对于大小是uint16_t的lane divide 11,如下是对应的SIMD指令。
// Divide uint16_t lanes by 11, all 8 of them in just two SSE 2 instructions.
__m128i div_by_11_epu16( __m128i x )
{
x = _mm_mulhi_epu16( x, _mm_set1_epi16( (short)47663 ) );
return _mm_srli_epi16( x, 3 );
}
Multiplication is tricky as well. _mm_mul_epi32 takes 2 values [a, b, c, d] [e, f, g, h], ignores half of the values, and returns register with 2 64-bit values [ a * e, c * g ]. The normal version is _mm_mullo_epi32. Oh, and both are SSE 4.1. If you only have SSE 2, you’ll need workarounds.
multiplication也是很棘手的。_mm_mul_epi32忽略[a, b, c, d]和[e, f, g, h]的一半数值,返回由两个64bit数值的[ a * e, c * g ]寄存器。不忽略的指令是_mm_mullo_epi32,两个指令都在SSE 4.1指令集中。如果你只使用SSE2指令集,需要适当变通。
Unorthodox
For most lane sizes there’re integer minimum and maximum instructions, e.g. _mm_max_epu8 (SSE 2) is maximum for uint8_t lanes, _mm_min_epi32 (SSE 4.1) is minimum for 32-bit integer lanes.
对大多数大小的integer都有对应的minimum和maximun指令。比如SSE2指令集中的_mm_max_epu8计算uint8_t lanes的maximum,SSE4.1指令集中的_mm_min_epi32计算32bit interger lanes的最小值。
SSSE 3 has absolute value instructions for signed integers. It also has horizontal addition and subtraction instructions, e.g. _mm_hsub_epi32 takes [a, b, c, d] and [e, f, g, h] and returns [a-b, c-d, e-f, g-h]. For signed int16 lanes, saturated version of horizontal addition and subtraction is also available.
SSSE3指令集中对于signed integers有absolute value指令。也有horizontal addition和subractions指令,比如_mm_hsub_epi32输入[a, b, c, d]和[e, f, g, h],返回[a-b, c-d, e-f, g-h]。对于signed int16 lanes,horizontal addition 和 subtraction 有对应的saturated版本的指令。
For uint8_t and uint16_t lanes, SSE 2 has instructions to compute average of two inputs.
对于uint8_t和uint16_t lanes,在SSE2指令集中有计算两个输入向量的average的指令。
The weirdest of them is probably _mm_sad_epu8 (SSE2) / _mm256_sad_epu8 (AVX2). The single instruction, which can run once per cycle on Intel Skylake, is an equivalent of the following code:
有点不可思议的是SSE2指令集中的_mm_sad_epu8和AVX2指令集中的_mm256_sad_epu8。每个指令在Intel Skylake上每次运行只需要1个cycle,与以下代码等效。
array avx2_sad_epu8( array a, array b )
{
array result;
for( int i = 0; i < 4; i++ )
{
uint16_t totalAbsDiff = 0;
for( int j = 0; j < 8; j++ )
{
const uint8_t va = a[ i * 8 + j ];
const uint8_t vb = b[ i * 8 + j ];
const int absDiff = abs( (int)va - (int)vb );
totalAbsDiff += (uint16_t)absDiff;
}
result[ i ] = totalAbsDiff;
}
return result;
}
I think it was added for video encoders. Apparently, they treat AVX 2 register as a block of 8×4 grayscale 8-bit pixels, and want to estimate compression errors. That instruction computes sum of errors over each row of the block. I’ve used it couple times for things unrelated to video codecs, it’s the fastest ways to compute sum of bytes: use zero vector for the second argument of _mm_sad_epu8, then _mm_add_epi64 to accumulate.
我想这是为视频编码设计的。很显然,设计者将AVX2寄存器视为8*4大小的8bit像素区域,然后计算compression errors。这个指令计算每行error的和。我已经多次将其用于视频编解码以外的事情。这是最快的方式计算所有字节和,将_mm_sad_epu8的第二个参数设为0,然后使用_mm_add_epi64累加。
Comparisons
Only all-lane versions are implemented. The results are similar to float comparisons, they set complete lane to all zeroes or all ones. For example, _mm_cmpgt_epi8 sets 8-bit lanes of the output to either 0 or 0xFF, depending on whether the corresponding signed 8-bit values are greater or not。
comparisons只有all-lane版本的指令。结果与float comparision相似,将结果lane的所有bit设为全0或者全1。比如,_mm_cmpgt_epi8根据对应signed 8bit数值的比较结果,将结果对应的8-bit lane设为0或者0xFF。
Protip: a signed integer with all bits set is equal to -1. A useful pattern to count matching numbers is integer subtract after the comparison:
将所有lanes的signed integer的所有bit设为1相当于-1。在comparison后接一个subtract,可以统计符合match数量。
const __m128i cmp = _mm_cmpgt_epi32( val, threshold ); // Compare val > threshold
acc = _mm_sub_epi32( acc, cmp ); // Increment accumulator where comparison was true
Be ware of integer overflows though. Rarely important for counting 32-bit matches (they only overflow after 4G of vectors = 64GB of data when using SSE2), but critical for 8 and 16-bit ones. One approach to deal with that, a nested loop where the inner one consumes small batch of values which guarantees to not overflow the accumulators, and outer loop which up-casts to wider integer lanes.
注意integer的溢出。当32bit大小的integer来累加时并不重要(使用SSE2指令集时,当在4G个vector=64GB后才会发生溢出),但是使用8或者16bit的integer来说就很危险了。一种处理办法是使用nested loop,在内层循环中计算部分数值,保证accumulator不发生溢出,在外层循环中up-cast到更宽的integer lanes。
There’re no unsigned integer comparison instructions. If you need them, here’s an example how to implement manually, on top of signed integer comparison.
没有针对unsigned interger的comparison指令。如果你需要,如下例展示了如何手动实现。
// Compare uint16_t lanes for a > b
__m128i cmpgt_epu16( __m128i a, __m128i b )
{
const __m128i highBit = _mm_set1_epi16( (short)0x8000 );
a = _mm_xor_si128( a, highBit );
b = _mm_xor_si128( b, highBit );
return _mm_cmpgt_epi16( a, b );
}
To compare integer lanes for a <= b, a good way (two fast instructions) is this: min( a, b ) == a. The move mask instruction is only implemented for 8-bit lanes. If you want results of 32-bit integer comparison in a general-purpose register, 1 bit per lane, one workaround is cast __m128i into __m128 and use _mm_movemask_ps. Similar for 64-bit lanes, cast into __m128d and use _mm_movemask_pd.
对于integer lanes 比较 a<=b,一个好的方式是min( a, b ) == a(由两个很快的指令组成)。move mask指令只有8bit lanes版本。如果你想将32bit integer的比较结果放在通用寄存器中,每个bit表示一个lane的结果。可以将__m128i cast __m128然后使用_mm_movemask_ps。同样对于64bit lanes,cast __m128d然后使用_mm_movemask_pd。
Shifts
Whole Register Shift
It can only shift by whole number of bytes.
The whole register shifts are _mm_srli_si128 and _mm_slli_si128 in SSE 2. AVX 2 equivalents like _mm256_slli_si256 independently shift 16-byte lanes, so the bytes that would have been shifted across 16-byte halves of the register become zeros. If you want to shift the entire 32-byte AVX register, you gonna need a workaround, see this stackoverflow answer.
SSE2指令集中整体shift寄存器的指令有_mm_srli_si128和_mm_slli_si128。在AVX2中的相近指令是_mm256_slli_si256,可以分别shift两个16byte lanes,shift空出的bit被填充为0。如果你想shift整个32byte的寄存器,可以看stackoverflow的答案。
SSSE3 has _mm_alignr_epi8 instruction. Takes 16 bytes in one register, 16 bytes in another one, concatenates them into 32-bit temporary result, shifts that one right by whole number of bytes, and keep the lowest 16 bytes.
SSSE3指令集的_mm_alignr_epi8指令,传入两个16字节寄存器,concatenate为一个32bit的临时变量然后整体shift,最后保留低1字节。
Individual Lanes Shift
SSE 2 has instructions which encode shift amount in the opcodes, and versions which take it from the lowest lane of another vector register. The shift amount is the count of bits to shift, it’s applied to all lanes. Right shift instructions come in two versions, one shifting in zero bits, another shifting in sign bits. _mm_srli_epi16( x, 4 ) will transform 0x8015 value into 0x0801, while _mm_srai_epi16( x, 4 ) will transform 0x8015 into 0xF801. They likely did it due to the lack of integer division: _mm_srai_epi16( x, 4 ) is an equivalent of x/16 for signed int16_t lanes.
SSE2中的指令可以将位移量编码为opcodes,或者从另一个寄存器中将最低lane作为opcodes。shift的数量等于bits的个数,并应用在所有lanes上。右shift指令有两个版本,一个使用0(填充空余bit)另一个使用1(填充空余bit)。_mm_srli_epi16( x, 4 )会将0x8015修改为0x0801,_mm_srai_epi16( x, 4 )会将0x8015修改为0xF801。这样做的原因大概是缺少integer division指令。_mm_srai_epi16( x, 4 )等同于对int16_t lanes执行x/16。
Variable Shifts
AVX2 introduced instructions which shift each lane by different amount taken from another vector. The intrinsics are _mm_sllv_epi32, _mm_srlv_epi32, _mm_sllv_epi64, _mm_srlv_epi64, and corresponding 32-bytes versions with _mm256_ prefix. Here’s an example which also uses the rest of the integer shifts.
AVX2指令集中,可以对每个lane shift不同的位数。这些指令是 _mm_sllv_epi32, _mm_srlv_epi32, _mm_sllv_epi64, _mm_srlv_epi64,还有对应前缀是_mm256_的针对32字节的版本。这是一个使用integer shift的例子。
Pack and Unpack
Unlike floats, the same data types, __m128i and __m256i, can contain arbitrary count of lanes. Different instructions view them as 8-, 16-, 32-, or 64-bit lanes, either signed or unsigned. There’re many instructions to pack and unpack these lanes.
不同于floats,__m128i和__m256i有很多种lanes。不同的指令处理8-、16-、32-或者64-bit的lanes,还包括有符号和无符号。以下是一些pack或unpack的指令。
Unpack instructions come in 2 versions. unpacklo_something unpacks and interleaves values from the low half of the two registers. For example, _mm_unpacklo_epi32 takes 2 values, [a,b,c,d] and [e,f,g,h], and returns [a,e,b,f]; _mm_unpackhi_epi32 takes 2 values, [a,b,c,d] and [e,f,g,h], and returns [c,g,d,h]. One obvious application, if you supply zero for the second argument, these instructions will convert unsigned integer lanes to wider ones, e.g. 8-bit lanes into 16-bit ones, with twice as few lanes per register.
unpack指令有两个版本,unpacklo_something可以unpacks并interleaves两个寄存器的低一半数值。比如_mm_unpacklo_epi32输入[a,b,c,d]和[e,f,g,h]输出[a,e,b,f];_mm_unpackhi_epi32输入[a,b,c,d]和[e,f,g,h]输出[c,g,d,h]。一个明显的应用是,如果你将第二个参数设为0,这些指令可以将无符号integer lanes convert为更宽的lanes。8bit lanes convert到16bit lanes,自然lanes的数量也相应减半。
The opposite instructions, for packing lanes, come in 2 versions, for signed and unsigned integers. All of them use saturation when packing the values. If you don’t want the saturation, bitwise AND with a constant like _mm_set1_epi16( 0xFF ) or _mm_set1_epi32( 0xFFFF )(Or you can build the magic numbers in code. It takes 3 cycles, setzero, cmpeq_epi32, unpacklo_epi8/unpacklo_epi16. In some cases, can be measurably faster than a RAM load to fetch the constant.), and unsigned saturation won’t engage.
与unpack相反的packing指令包括对有符号和无符号共两个版本。两者全部使用saturation。如果你不想使用saturation。与常量_mm_set1_epi16( 0xFF )或者_mm_set1_epi32( 0xFFFF )bitwise AND(或者使用setzero, cmpeq_epi32, unpacklo_epi8/unpacklo_epi16,花费3个cycles,有些情况,比同RAM中load常量更快),但是对无符号的saturation无效。
_mm_packs_epi16 takes 2 registers, assumes they contain 16-bit signed integer lanes, packs each lane into 8-bit signed integer using saturation (values that are greater than +127 are clipped to +127, values that are less than -128 are clipped to -128), and returns a value with all 16 values._mm_packus_epi16 does the same but it assumes the input data contains 16-bit unsigned integer lanes, that one packs each lane into 8-bit unsigned integer using saturation (values that are greater than 255 are clipped to 255), and returns a value with all 16 values.
_mm_packs_epi16将两个16bit有符号integer lanes的寄存器,pack每一个lanes为8bit有符号的integer,并且使用saturation(也就是说大于+127的值截取为+127,小于-128的截取为-128),然后返回共16个值的向量。_mm_packus_epi16将两个16bit无符号integer lanes的寄存器,pack每一个lane为8bit无符号integer,并且使用saturation(也就是说大于255的将截取为255),然后返回共16个值的向量。
Before AVX2, unpacking with zeroes was the best way to convert unsigned integers to wider size. AVX2 introduced proper instructions for that, e.g. _mm256_cvtepu8_epi32 takes 8 lowest bytes of the source, and converts these bytes into a vector with 8 32-bit numbers. These instructions can even load source data directly from memory.
在AVX2指令集之前,与0做unpack是最好的方式来convert无符号integer到更大的宽度。AVX2指令集中引入了更合适的指令,比如_mm256_cvtepu8_epi32将原数据的8个最低的字节convert为8个32bit的数值,这些指令甚至可以直接从内存load数据。
Shuffles
Besides pack and unpack, there’re instructions to shuffle integer lanes
_mm_shuffle_epi32 |
SSE 2 | Shuffle 32-bit integer lanes.The picture on the right is for the shuffle constant 0b00001101 which is 0x0D in hexadecimal. | shuffle 32bit integer lanes,右侧的图像对应shuffle常量为0b00001101,或者十六进制的0x0D。 | 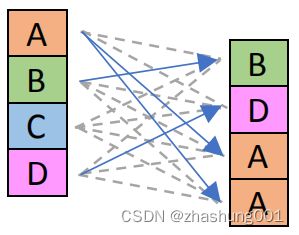 |
_mm_shufflelo_epi16 |
SSE 2 | Shuffles lower 4 of the 16-bit integer lanes. The upper 64 bit is copied from source do destination. The picture on the right is for shuffle constant 0x0D. | shuffle低4个16bit integer lanes,高64bit将原数据复制到目标,右侧图像对应shuffle常量为0x0D。 | 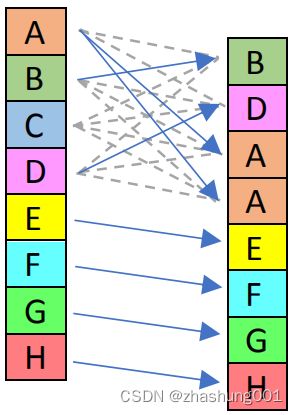 |
_mm_shufflehi_epi16 |
SSE 2 | Similar to the above, copies the lower 4 lanes, and shuffles the higher 4 lanes into the higher lanes of the result. | 与上述指令相似,复制低4个lanes,然后shuffle高4个lanes。 | |
_mm_insert_epi16 |
SSE 2 | Insert a 16-bit integer value. Unlike the floating-point inserts, the integer to insert V comes from a general-purpose register. If you have it in another vector register, you may want to do something else, like a shift followed by blend. The index where to insert is encoded into the instruction. On the picture to the right, that index was 6. | insert一个16bit integer,与float的insert不同, insert的数据V来自通用寄存器。如果你想insert另一个向量寄存器,你可以使用其他指令,比如shift加blend。insert指令需要输入索引。右侧图像标识索引为6。 |  |
_mm_insert_epi8, _mm_insert_epi32, _mm_insert_epi64 |
SSE 4.1 | Similar to the above but inserts 8-, 32- or 64-bit lanes. | 与上述指令相似,不过插入的integer换成8bit、32bit、64bit。 | |
_mm_shuffle_epi8 |
SSSE 3 | Shuffle 8-bit lanes, taking shuffle indices from another vector register. See the separate section of this article for more information. | shuffle 8bit lanes,shuffle索引来自另一个向量寄存器。 | |
_mm_blend_epi16 |
SSE 4.1 | Blend 16-bit lanes. The blend bit mask is encoded into the instruction. On the illustration to the right, that constant was 0b10111000 = 0xB8 | blend 16bit lanes,blend mask为另一个常量,右侧图像对应的常量是0b10111000 = 0xB8 |  |
_mm_blend_epi32 |
AVX 2 | Similar to the above, but blends 32-bit lanes instead of 16-bit ones, and marginally faster. | 与上述指令相似,不过blend对象换成了32bit lanes,并且性能更快 | |
_mm_blendv_epi8 |
SSE 4.1 | Blends 8-bit lanes, but unlike the rest of them, blending bit mask is not encoded in the instruction, it comes from another, third input register. The instruction uses highest bit of each 8-bit lane to select each lane of the result from either of the two first input registers. | blend 8bit lanes,但是与其他blend不同,blend mask不是常量而是另一个向量寄存器,指令通过使用该向量寄存器的每个8bit lane的最高bit来决定从哪个输入的寄存器中选择。 | |
_mm256_permutevar8x32_epi32 |
AVX 2 | A rare instruction which can permute values across 128-bit lanes, and the permite constants are not encoded in the instruction. | 一个不常见的指令可以permute整个256bit,permute常量是另一个向量 | |
_mm_broadcastb_epi8, _mm_broadcastw_epi16, _mm_broadcastd_epi32, _mm_broadcastq_epi64 |
AVX 2 | Broadcast the lowest lane to the rest of them. The picture to the right is for _mm_broadcastd_epi32 instruction. |
broadcast最低lane到其他lanes,右侧图像表表示_mm_broadcastd_epi32的结果。 |
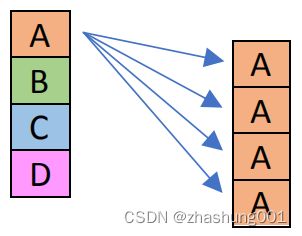 |
_mm_shuffle_epi8
This instruction is a part of SSSE 3 set, and it deserves a dedicated section in this article. It’s the only SSE instruction that implements runtime-variable shuffles. Unlike the rest of the shuffles, this one takes shuffle values from a vector register. Here’s a C++ equivalent of that instruction:
这条指令在SSSE3指令集中,并值得用一个单独的章节来介绍。这是在SSE指令集中唯一的运行时shuffles,与其他的shuffles不同,它从另一个向量寄存器中读取shuffle的值,下面是这个指令等价的C++代码。
array shuffle_epi8( array a, array b )
{
array result;
for( int i = 0; i < 16; i++ )
{
const uint8_t mask = b[ i ];
if( 0 != ( mask & 0x80 ) )
result[ i ] = 0;
else
result[ i ] = a[ mask & 0xF ];
}
return result;
}
Only unlike the above C++ code with the loop, _mm_shuffle_epi8 has 1 cycle latency, and the throughput is even better, the computer I’m using to write this article can run 2 or them per clock. Can be quite useful in practice. Here’s one example which uses the first argument as a lookup table, and the second one as indices to lookup, to compute Hamming weight of integers. In some cases, that version can be faster than dedicated POPCNT instruction implemented in modern CPUs for counting these bits. Here’s another, this one uses it for the intended purpose, to move bytes around.
与上述C++代码中使用的循环不同,_mm_shuffle_epi8的latency只需要1cycle,throughput甚至更好,笔者当前的电脑一个clock可以运行两次。因此在实践中很有用。这个例子中,第一个参数作为查找表,第二个作为要使用查找表的索引,来计算integer的Hamming weight。在现代计算机中,当想要计数时,有些时候这个版本比使用专用的POPCNT指令的实现还要快。另一个例子,在这个例子中使用这个指令根据预设来move字节。
The AVX2 equivalent, _mm256_shuffle_epi8, shuffles within 128-bit lanes, applying the same algorithm onto both 128-bit pieces, using the corresponding piece of the second argument for shuffle control values.
同样在AVX2指令集中对应_mm256_shuffle_epi8,将整个256bit的分为两半,分别使用相同的shuffle规则,使用第二个参数来控制shuffle。
Miscellaneous Vector Instructions
There’re intrinsics to copy the lowest lane from vector register into general purpose one, such as _mm_cvtsi128_si32, _mm_cvtsi128_si64. And the other way too, _mm_cvtsi32_si128, _mm_cvtsi64x_si128, they zero out the unused higher lanes.
_mm_cvtsi128_si32、_mm_cvtsi128_si64可以复制向量寄存器的最低lane到通用寄存器。_mm_cvtsi32_si128、_mm_cvtsi64x_si128将通用寄存器复制到向量寄存器的最低lane,其他未使用的高位lane置为0。
Similar ones are available for both floats types, _mm_cvtss_f32, but only 1 way, from vector register to normal C++ floats. For the other way, to convert scalar floats into SIMD registers, I usually use _mm_set_ps or _mm_set1_ps. Scalar floats are often already in SIMD registers, compilers need to do very little work, maybe nothing at all, maybe a shuffle.
对于32bit和64bit的float各有一种类似的指令,可以将向量寄存器转化为标量float。对于c++的float类型只有一个指令_mm_cvtss_f32。将标量float转化为SIMD向量,笔者经常使用_mm_set_ps或_mm_set1_ps,标量float经常已经在SIMD寄存器中了,编译器仅需要很少的工作令,比如shuffle,甚至不做任何处理。
_mm_extract_epi16 (SSE 2) extracts any of the 16-bit lanes (index encoded in the instruction) and returns the value in general purpose register. _mm_extract_epi8, _mm_extract_epi32, _mm_extract_epi64, _mm_extract_ps (all SSE 4.1) do the same for other lane sizes. The interesting quirk about _mm_extract_ps, it can return 32-bit float in a general-purpose integer register like eax.
SSE2指令集中的_mm_extract_epi16提取任意一个16bit lane(将索引传给指令),然后将值返回通用寄存器。SSE4.1指令集中的_mm_extract_epi8, _mm_extract_epi32, _mm_extract_epi64, _mm_extract_ps是针对不同大小的lanes的变种。_mm_extract_ps比较奇特,返回32bit float至通用integer寄存器比如eax。
Another useful SSE 4.1 instruction is ptest. It takes 2 vector registers, computes bitwise ( a & b )and sets one flag if each and every bit of the result is 0. It also computes ( ( ~a ) & b ), and sets another flag if that value is exactly 0 on all bits. These flags are readable by general-purpose CPU instructions. It’s exposed in C++ as multiple intrinsics, _mm_testz_si128, _mm_testnzc_si128, _mm_test_all_zeros, _mm_test_all_ones, etc.
SSE4.1指令集中的另一个有用指令是ptest,比如_mm_testz_si128, _mm_testnzc_si128, _mm_test_all_zeros, _mm_test_all_ones。输入两个向量寄存器,计算bitwise(a & b),如果结果的每一个bit为0输出1。计算( ( ~a ) & b ),当结果的每一个bit为0是输出1。这个结果对于通用的CPU指令是可读的。在C++中一个指令由多个单独指令组成。
SSSE 3 has a few unusual integer instructions. _mm_mulhrs_epi16 does something like this to signed int16_t lanes: return (int16_t)( ( (int)a * (int)b + 0x4000 ) >> 15 ) I have used it to apply volume to 16-bit PCM audio. _mm_sign_something multiplies signed lanes by signs of corresponding lane in the second argument, either -1, 0 or +1. _mm_maddubs_epi16 does an equivalent of the following C++ code:
SSE3中有一些不常见的指令。_mm_mulhrs_epi16对16bit有符号lanes做如下操作:(int16_t)( ( (int)a * (int)b + 0x4000 ) >> 15 ),我曾经使用这个指令用于volume 16bit的PCM音频。_mm_sign_something对每一个lane multiply第二个参数对应lane的符号位,比如-1、0、1。_mm_maddubs_epi16等价于如下c++代码。
array mad_bs( array a, array b )
{
array result;
for( int i = 0; i < 16; i += 2 )
{
const int p1 = (int16_t)a[ i ] * (int16_t)b[ i ];
const int p2 = (int16_t)a[ i + 1 ] * (int16_t)b[ i + 1 ];
int sum = p1 + p2;
sum = std::max( sum, -32768 );
sum = std::min( sum, +32767 );
result[ i / 2 ] = (int16_t)sum;
}
return result;
}
Besides integer and floating-point math, modern CPUs can do other things with these vector registers. Hardware AES and SHA cryptographic algorithms are implemented on top of them. Intel implemented some strange string-handling instructions in SSE 4.2. This article covers general-purpose programming with focus on numerical computations, they aren’t covered here.
除了integer或者float数学计算,现代CPU可以做一些其他事情。可以使用这些指令实现硬件级别的AES和SHA加密算法。Intel实现了一些奇怪的字符串处理命令在SSE4.2中,本文主要聚焦于数值计算的通用编程,因此不包括这些内容。
Random Tips and Tricks
First and foremost, it doesn’t matter how fast you crunch your numbers if the source data isscattered all over the address space. RAM access is very expensive these days, a cache miss can cost 100-300 cycles. Caches are faster than that but still slow, L3 cache takes 40-50 cycles to load, L2 cache around 10 cycles, even L1 cache is noticeably slower to access than registers. Keep your data structures SIMD-friendly. Prefer std::vector or equivalents like CAtlArray or eastl::vector over the rest of the containers. When you read them sequentially, prefetcher part of the CPU normally hides RAM latency even for very large vectors which don’t fit in caches. If your data is sparse, you can organize it as a sparse collection of small dense blocks, where each block is at least 1 SIMD register in size. If you have to traverse a linked list or a graph while computing something for each node, sometimes _mm_prefetch intrinsic helps.
首先也是最重要的,如果数据分散在整个地址空间,那么计算速度再快也是没有意义的。当下RAM的访问代价很高,一次cache miss会损失100-300cycle。Cache比RAM相对更快一些但仍然很慢。L3 cache需要花费40-50cycle来load,L2需大约10 cycle,甚至L1 cache的访问速度也比寄存器明显要慢。保持你的数据结构对SIMD友好。比如std::vector或者类似CAtlArray或者eastl::vector而不是其他容器。当你顺序读取这些数据时,CPU的prefetcher将节省RAM latency即使是一个cache容不下的向量。如果你的数据是离散的,你可以将这些数据汇总为小的稠密块组成的离散集合,保证每一个块的大小至少跟一个SIMD向量大小一样。如果你要遍历链表或图来计算每一个节点。有时_mm_prefetch指令会有用。
For optimal performance, RAM access needs to be aligned(More specifically, the memory access should not cross cache line boundary. Cache line size is 64 bytes and they are aligned by 64. When SIMD vectors are aligned properly (by 16 bytes for SSE, or by 32 bytes for AVX vectors), a memory access is guaranteed to only touch a single cache line.). If you have std::vector<__m128> the standard library should align automatically, but sometimes you want aligned vectors of floats or types like DirectX::SimpleMath::Vector3 which don’t have sufficient natural alignment. For these cases, you can use custom allocator, tested on Windows and Linux.
为了获取最佳性能,RAM需要aligned(更具体地说,内存读取不应该超越cache line boundary。cache line大小为64字节,而且是以64字节aligned。当SIMD向量正确aligned时,SSE向量是16字节aligned,AVX向量是32字节aligned,一次内存访问应该保证只touch一个cache line)。对于std::vector<__m128>标准库将自动align,但如果你想align float向量或者天然不是alignement的DirectX::SimpleMath::Vector3,你可以在Windows或Linux上自定义allocator。
When you’re dealing with pairs of 32-bit float numbers (like FP32 vectors in 2D), you can load/store both scalars with a single instruction intended for FP64 numbers. You only need type casting for the pointer, and _mm_castps_pd / _mm_castpd_psintrinsics for casting vectors. Similarly, you can abuse FP64 shuffles/broadcasts to move pairs of FP32 values in these vectors. Old CPUs have latency penalty for passing vectors between integer and float parts of CPU cores, but that’s irrelevant because FP32 and FP64 are both floats.
当你处理一对32bit float(比如二维FP32向量)时,你可将两个标量视为一个FP64并使用对应的指令来load/store。你只需要cast指针,使用_mm_castps_pd或者_mm_castpd_ps指令cast。类似,你可以使用针对FP64的shuffles/broadcasts来整体移动一对FP32对。在一些老旧的CPU核心中,将向量在integer和float之间传递会产生latency惩罚。但在FP32和FP64之间是没有的。
There’re good vectorized libraries for C++: Eigen, DirectXMath, couple of others. Learn what they can do and don’t reinvent wheels. They have quite complex stuff already implemented there. If you enjoy looking at scary things, look at the source code of SSE version of XMVector3TransformCoordStream library routine.
优秀的向量化C++运算库有Eigen、DirectXMath等。学习如何使用而不是重复造轮子。它们已经实现了一些相当复杂的计算。如果你想学习,可以看XMVector3TransformCoordStream库SSE版本实现的源代码。
When you’re implementing complex SIMD algorithms, sometimes it’s a good idea to create C++ classes. If you have a class with a couple of __m128 fields, create it on the stack, and never create references nor pointers to it, VC++ compiler normally puts these fields in SIMD registers. This way there’s no class anywhere in machine code, no RAM loads or stores, and the performance is good. There’s still a class in C++, when done right, it makes code easier to work with and reason about.Same often applies to small std::array-s of SIMD vectors, or C arrays.
当你想要实现一个复杂的SIMD算法,有的时候创建一个c++类是个不错的方法。如果类中有多个__m128变量,然后在栈上创建对象,不要创建这个对象的引用或者指针。VC++编译器会把这些变量放在SIMD寄存器中。这种实现最终在机器码上是没有类的,因此无需loads或者stores,性能很好。虽然在C++代码中仍是一个类,因此处理得当时,会让代码更容易使用。同样这个规则适用于SIMD向量的std::array和C数组。
Don’t write static const __m128 x = something(); inside functions or methods. In modern C++ that construction is guaranteed to be thread safe. To support the language standard, a compiler has to emit some boilerplate code, which gonna have locks and branches. Instead, you can place that value in a global variable so they’re initialized before main() starts to run, or for DLLs before LoadLibrary of your DLL returns. Or you can place that value in a local non-static const variable.
不要在函数或类方法中写static const __m128 x = something();在现代C++中这段代码要求线程安全。因此为了符合语言规范,编译器会生成一些包含locks和branches的boilerplate代码。你可以将该值放在一个全局变量中,这样就可以在main()函数执行之前初始化,或者对于DLLs在LoadLibrary返回之前初始化。或者你可以将该值放在一个局部非static常量中。
_mm_shuffle_ps and _mm_shuffle_epi32, _MM_SHUFFLE.
_MM_SHUFFLE表示使用_mm_shuffle_ps或_mm_shuffle_epi32来shuffle常量。
When compiling for 32-bit, all the general-purpose registers are 32-bit as well. SIMD intrinsics which move 64-bit integers between SIMD registers and general-purpose ones are not available on the platform. To work around, use load/store, or fetch two 32-bit values with separate instructions.
当编译环境是32bit时,所有的通用寄存器也是32bit的。SIMD指令中在两个SIMD寄存器之间move 64bit integer的指令的不可用的。为了解决这个问题,可以将64bit数值视为两个32bit的值,并使用单独的load、store、fetch指令。
If you use VC++, spam __forceinline on performance-critical SIMD functions which are called from hot loops. Code often contains magic numbers, also variables which don’t change across iterations. Unlike scalar code, SIMD magic numbers often come from memory, not from the instruction stream. When compiler is told to __forceinline, it can load these SIMD constants once, and keep them in vector registers across iterations. Unless they are evicted to RAM due to registers shortage. Without inlining, the code will be reloading these constants in consuming functions. I’ve observed 20% performance improvement after adding __forceinline keywords everywhere. Apparently, VC++ inlining heuristics are tuned for scalar code, and fail for code with SIMD intrinsics.
当你使用VC++时,在循环中的关键性能的SIMD函数前添加__forceinline,代码中经常会包括奇怪数字,以及不会随迭代变化的变量。与标量版本的代码不同,奇怪的数字产生于内存,而不是从SIMD指令流。当编译器被告知__forceinline时,在迭代时编译器将load这些SIMD常量至向量寄存器,并保持在向量寄存器中。除非当向量寄存器不足时,将load至RAM。当取消inlining时,编译器将reload这些常数在comsuming function。在所有位置添加__forceinline,我获得了20%的性能提升。显然,VC++ 对标量代码优化了inlining指令,但是对SIMD指令则没有优化。
Unfortunately, this means you probably can’t use C++ lambdas on hot paths, as there’s no way to mark lambda’s operator() with __forceinline. You’ll have to write custom classes instead, class methods and operators support __forceinline just fine. If you’re using gcc or clang to compile your code, they’re better with inlining but forcing may still help sometimes, you can define __forceinline as a macro:
很不幸,这意味着你不能在关键位置使用c++ lambda,而且不能将为lambda的 operator()添加__forceinline.你必须使用一个类来代替,类成员函数和类运算发重载支持__forceinline。如果你使用gcc或clang来编译代码,使用inlining效果不错,强制inlining可能仍然有用,你可以将__forceinline定义为一个宏:
#define __forceinline inline __attribute__((always_inline))
If you’re implementing dynamic dispatch to switch implementation of some vector routines based on supported instruction set, apply __vectorcall convention to the function pointers or virtual class methods. Such functions pass arguments and return value in vector registers. Can be measurable difference for 32-bit binaries. The default 64-bit convention ain’t that bad, you probably won’t get much profit for your 64-bit builds.
如果你想实现动态切换不同的指令集的向量例程,请对函数指针或虚类成员函数使用__vectorcall。这些函数使用向量寄存器输入输出参数。对于32bit的参数会有可见的不同,但是对于默认的64bit convention可能不会获得太多提升。
Agner Fog has resources for SIMD programming on his web site. The “Optimizing subroutines in assembly language” is extremely useful, also timings tables. He also has a vector class library with Apache license. I don’t like wrapper classes approach: sometimes compilers emit suboptimal code due to these classes, many available instructions are missing from the wrappers, vectorized integer math often treats vectors as having different lanes count on every line of code so you’ll have to cast them a lot. But parts like floating point exponent, logarithm and trigonometry are good.
Agner Fog在他的个人网站有SIMD编程资源。"Optimizing subroutines in assembly language"也非常有用,还有计时表。他个人也有一个向量类库,该库支持Apache证书。我不喜欢将算法打包为类:因为编译器可能因为类的缘故影响优化,封装类的过程可能会放弃使用一些可用的指令。对于向量化的integer数学,同一个向量在不同代码中可能会视为不同的lanes来处理,因此你必须经常的cast。但是对于float来说,exponent、logarithm、trigonometry是很方便的。
Speaking of timing tables, this web site is an awesome source of performance-related data for individual instructions: https://www.uops.info/table.html
说到计时表,以下的网站提供了不错的单独指令的相关性能数据资源https://www.uops.info/table.html。