从零开始的ARIMA实验
从零开始的ARIMA实验
文章目录
- 从零开始的****ARIMA实验****
- **0.** 数据集:
- 1. 前期准备
- 2. 数据预处理
-
-
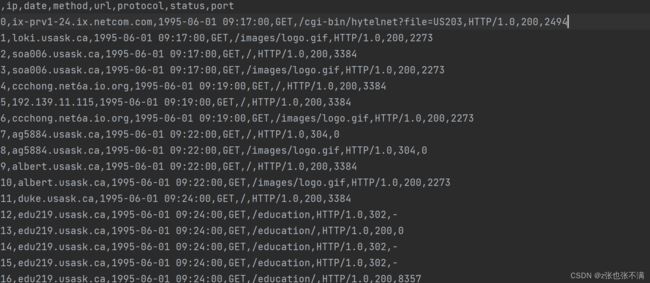
- 处理前的格式
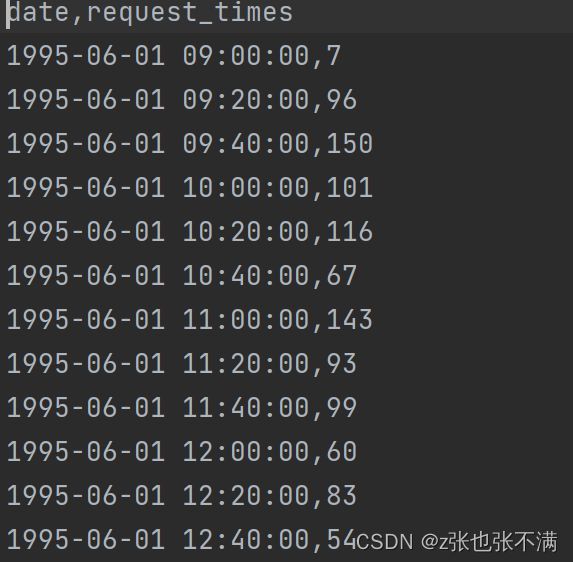
- 处理后的csv文件
- 单变量预测负载请求的数据,后面的预测请求次数以这个数据集为主
-
- 3. 数据集的差分
- 4. 数据的平稳性检验
- 5. 时间序列定阶
- 6.模型的训练
- 7. 程序运行代码
- Reference
Arima预测结果不好,无法预测峰值的情况且该实验仅能在样本内预测,样本外模型无法预测
0. 数据集:
- NASA-HTTP
- SASK-HTTP
- ClarkNet
- Calgary
- ali-trace
- google-trace
1. 前期准备
#导入数据包
import itertools
import pandas as pd
import os
import numpy as np
import statsmodels.api as sm #时间序列
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import mean_squared_error
import json
import re
from datetime import datetime
import calendar
from tqdm import tqdm
2. 数据预处理
# 清洗数据与划分数据集
# accesslog数据日志转换为pandas可正常读取的数据格式
"""
accesslog2dataframe : 读取日志文件处理成pandas可读取的规则的数据结构
src:accesslog日志所在路径
dst:输出的数据所在路径
pattern:正则表达式规则
TimePattern:时间截取的正则表达式的规则
"""
def accessLog2dataframe(src,dst,pattern,TimePattern):
result = {} #存放处理后的结果集合
i = 0 # 用来遍历每行的数据
k = 0 # 用来记录错误数据
log_data = open(src, 'r', errors="ignore")
for line in tqdm(log_data) :
line = line.strip('\n') # 删除换行符号
match = re.match(pattern=pattern, string=line) #正则表达式提取数据
if match != None:
data = {} # 解析当前行内字符串的数据
data['ip'] = match.group(1)
time = match.group(2)
time = re.match(pattern=TimePattern, string=time)
year = time.group(3)
month = list(calendar.month_abbr).index(time.group(2))
day = time.group(1)
hour = time.group(4)
min = time.group(5)
t = datetime(int(year), month, int(day), int(hour), int(min))
time = t.strftime("%Y/%m/%d %H:%M")
data['date'] = time
data['method'] = match.group(3)
data['url'] = match.group(4)
data['protocol'] = match.group(5)
data['status'] = match.group(6)
data['port'] = match.group(7)
result[i] = data
i += 1
else:
k += 1
continue
j = json.dumps(result)
data = pd.read_json(j, orient='index')
data.to_csv(dst)
print("errors data have %d colums"%(k))
return data
"""
PredDataSetsProcessionTimeCounts:设置数据移动窗口的大小和设置数据格式,index为date类型
"""
def PredDataSetsProcessionTimeCounts(SrcFilePath,windowsSize,DstFilePath):
data = pd.read_csv(SrcFilePath, index_col='date')
data['request_times'] = 1
data = data.drop(labels=['Unnamed: 0','ip', 'method', 'url', 'protocol', 'status', 'port'], axis=1)
# Time_data = data.set_index('date')
data.index = pd.to_datetime(data.index)
Time_data = data.resample(windowsSize).sum()
Time_data.to_csv(DstFilePath)
return Time_data
# 调用代码
pattern = '^(.*)\s\-\s\-\s\[(.*)\]\s"(.*)\s(.*)\s(.*)"\s(.*)\s(.*)$'
TimePattern = '(.*)/(.*)/(.*):(.*):(.*):(.*)\s-[0-9]*'
src = "../datasets/Calgary/access_log"
dst = "../datasets/SASK-HTTP/UofS_access_log.csv"
file = "../datasets/SASK-HTTP/UofS_access_log_time.csv"
# data = accessLog2dataframe(src,dst,pattern,TimePattern)
Time_data = PredDataSetsProcessionTimeCounts(dst,'20min',file)
"""
因为跨目录使用相对路径没有办法实现,
故使用此函数来实现调用
dataSource(String) :
using pycharm right click file to Copy Path from Source root
"""
def getDataPath(dataSource):
PROJECT_ROOT = os.path.dirname(os.path.realpath(__file__))
path = os.path.join(PROJECT_ROOT,dataSource)
return path
"""
数据集分割,没有随机打乱
data : dataframe
trainSetSize : float
testSetSize : float
example :
train_sets , test_sets = dataset_split(data,0.9,0.1)
"""
def dataset_split(data,trainSetSize,testSetSize):
TotalSize = data.shape[0]
n_train = int(TotalSize*trainSetSize)+1
n_test = TotalSize - n_train
train_sets = data.iloc[:n_train]
test_sets = data.iloc[n_train+1:TotalSize]
return train_sets,test_sets
"""
数据基本处理:
均值填充空值
data : 数据源
pandas类型
"""
def dataProcessing(data):
data = data.fillna(data.mean())
return data
处理前的格式

处理后的csv文件
单变量预测负载请求的数据,后面的预测请求次数以这个数据集为主
3. 数据集的差分
这里不要将差分的数据集直接进行fillna,填充后会导致数据无法通过验证方法,NA值放着就可以了
# 差分法
def rollin_diff(timeseries):
diff_1 = timeseries.diff(1)
diff_2 = diff_1.diff(1)
diff_3 = diff_2.diff(1)
diff_1.plot(color = 'red' ,title = 'diff_1',figsize=(10,4))
diff_2.plot(color = 'blue' ,title = 'diff_2',figsize=(10,4))
plt.show()
# 平滑法
rollmean = timeseries.rolling(window=4,center= False).mean() # 滚动窗口平均
rollstd = timeseries.rolling(window=4,center=False).std() # 滚动标准差
rollmean.plot(color = 'yellow',title='Rolling Mean',figsize=(10,4))
rollstd.plot(color = 'black',title='Rolling Std',figsize=(10,4))
plt.show()
return diff_1,diff_2,diff_3,rollmean,rollstd
4. 数据的平稳性检验
#---------------平稳性检验-----------------------#
def ADF(timeseries,value_name):
adf_data = np.array(timeseries[value_name])
adftest = sm.tsa.adfuller(adf_data,autolag='AIC')
adftest
# (-5.50784309927251, 2.00308271713338e-06, 17, 630, {'1%': -3.4407724517110783, '5%': -2.866138605582151, '10%': -2.569218982111363}, 5759.084798363101)
if adftest[0] < adftest[4]['1%'] and adftest[1] < 10**(-8):
print("序列平稳")
return True
else :
print("非平稳序列")
return False
#---------------------随机性检验-----------------------#
def RandTest(timeseries):
random_test = sm.stats.diagnostic.acorr_ljungbox(timeseries,lags=1)
if random_test.iloc[0,1] < 0.05:
print("非随机性序列")
return False
else:
print("随机性序列,即白噪声序列")
return True
5. 时间序列定阶
这里最好的其实是使用热度图来做,我电脑性能不好,仅仅能使用AIC和BIC来定阶,这里我的AIC=BIC=HQIC=(4,3),效果还是比较可以
#--------------时间序列定阶-------------------------------#
def Acf_Pacf(timeseries):
sm.graphics.tsa.plot_acf(timeseries,lags=20)
plt.show()
sm.graphics.tsa.plot_pacf(timeseries,lags=20)
plt.show()
#------------信息准则定阶-------------------------#
def detetminante_order_AIC(timeseries):
AIC = sm.tsa.arma_order_select_ic(timeseries,\
max_ar=6,max_ma=4,ic='aic')['aic_min_order']
#BIC
BIC = sm.tsa.arma_order_select_ic(timeseries,max_ar=6,\
max_ma=4,ic='bic')['bic_min_order']
#HQIC
HQIC = sm.tsa.arma_order_select_ic(timeseries,max_ar=6,\
max_ma=4,ic='hqic')['hqic_min_order']
print('the AIC is{},\nthe BIC is{}\n the HQIC is{}'.format(AIC,BIC,HQIC))
return AIC,BIC,HQIC
#-----------------循环遍历 热度图定阶-------------------------#
def heatmap_AIC(diff_2,max):
# 设置遍历循环的初始条件,以热力图的形式展示,原理同AIC,BIC,HQIC定阶
p_min = 0
q_min = 0
p_max = max
q_max = max
d_min = 0
d_max = max
# 创建Dataframe,以BIC准则
results_aic = pd.DataFrame(index=['AR{}'.format(i) for i in range(p_min, p_max + 1)], \
columns=['MA{}'.format(i) for i in range(q_min, q_max + 1)])
# itertools.product 返回p,q中的元素的笛卡尔积的元组
for p, d, q in tqdm(itertools.product(range(p_min, p_max + 1), \
range(d_min, d_max + 1), range(q_min, q_max + 1))):
if p == 0 and q == 0:
results_aic.loc['AR{}'.format(p), 'MA{}'.format(q)] = np.nan
continue
try:
model = sm.tsa.ARIMA(diff_2, order=(p, d, q))
results = model.fit()
# 返回不同pq下的model的BIC值
results_aic.loc['AR{}'.format(p), 'MA{}'.format(q)] = results.aic
except:
continue
results_aic = results_aic[results_aic.columns].astype(float)
# print(results_bic)
fig, ax = plt.subplots(figsize=(10, 8))
ax = sns.heatmap(results_aic,
# mask=results_aic.isnull(),
ax=ax,
annot=True, # 将数字显示在热力图上
fmt='.2f',
)
ax.set_title('AIC')
plt.show()
return results_aic
6.模型的训练
# ------------------------- 模型训练----------------------------------#
def model_train(timeseries,order):
model = sm.tsa.ARIMA(timeseries,order=order).fit()
model.summary()
print("模型检验,样本内均方差")
in_sample_pred = model.predict()
mean_squared_error(timeseries,in_sample_pred)
print("残差检验")
sm.graphics.qqplot(model.resid, line='q', fit=True,label='残差检验')
plt.show()
print("白噪声检验 = ",sm.stats.durbin_watson(model.resid))
return model
模型参数如图所示,第一次实验,效果并不是很好,样本内预测还可以,样本外预测一塌糊涂
# SARIMAX Results
# ==============================================================================
# Dep. Variable: request_times No. Observations: 15380
# Model: ARIMA(4, 2, 3) Log Likelihood -80661.579
# Date: Wed, 27 Apr 2022 AIC 161339.158
# Time: 16:17:24 BIC 161400.284
# Sample: 06-01-1995 HQIC 161359.414
# - 12-31-1995
# Covariance Type: opg
# ==============================================================================
# coef std err z P>|z| [0.025 0.975]
# ------------------------------------------------------------------------------
# ar.L1 -2.0032 0.007 -274.210 0.000 -2.018 -1.989
# ar.L2 -1.7084 0.015 -111.878 0.000 -1.738 -1.678
# ar.L3 -1.0471 0.016 -66.375 0.000 -1.078 -1.016
# ar.L4 -0.3421 0.008 -44.600 0.000 -0.357 -0.327
# ma.L1 -0.9986 0.018 -56.766 0.000 -1.033 -0.964
# ma.L2 -1.0000 0.032 -31.198 0.000 -1.063 -0.937
# ma.L3 0.9986 0.018 55.119 0.000 0.963 1.034
# sigma2 3055.4384 57.927 52.747 0.000 2941.904 3168.972
# ===================================================================================
# Ljung-Box (L1) (Q): 261.03 Jarque-Bera (JB): 53709.38
# Prob(Q): 0.00 Prob(JB): 0.00
# Heteroskedasticity (H): 3.80 Skew: -0.27
# Prob(H) (two-sided):
7. 程序运行代码
# 读取数据 处理数据集
data = pd.read_csv(getDataPath("datasets/SASK-HTTP/UofS_access_log_time.csv"), index_col='date',
parse_dates=['date'])
data.index.freq = data.index.inferred_freq
train_sets, test_sets = dataset_split(data, 0.9, 0.1)
# 平滑与差分 稳定序列 这里使用2阶差分数据
diff_1,diff_2,diff_3,rollmean,rollstd = rollin_diff(train_sets)
# ADF检验与随机白噪声检验
adf_test = ADF(diff_2.fillna(0),'request_times')
rand_test = RandTest(diff_2)
# Arima定阶 三选一即可
# 1 ACF PACF
# 2 AIC BIC HQIC准则
# 3 热度图定阶
diff_2 = diff_2.fillna(0)
Acf_Pacf(diff_2)
model = model_train(diff_2,(4,2,3))
model.summary()
pred = model.predict(start=train_sets.index[0],end=train_sets.index[train_sets.size-1])
plt.plot(diff_2.index,diff_2['request_times'],label='diff_2',color = 'red')
plt.plot(diff_2.index,pred,label='pred',color = 'green')
plt.show()
Reference
- https://blog.csdn.net/foneone/article/details/90141213 大部分代码参考与这个博客
- https://blog.csdn.net/weixin_43178406/article/details/98480427
- https://blog.csdn.net/weixin_41988628/article/details/83149849